因为需要一些二手房数据,菜鸟开启了爬虫之路!不过需要注意的是,在爬取数据时,要遵守《中华人民共和国网络安全法》以及《规范互联网信息服务市场秩序若干规定》等相关法律规定(毕竟我们要做一个知法懂法的好公民,不能违法!)。
完整源代码请点击这里是我!
首先需要了解一下爬虫机制、python的基本语法、爬虫框架(scrapy等)、爬虫常用的一些库、网页解析工具(正则表达式、XPath等)、反爬虫机制,进阶后可能还要多线程、多进程爬取、以及一些特殊网页的爬取(登录问题、动态网页等)等等… …作为菜鸟的我,只为了能够快速获取数据,有些内容也没有深层次的理解,如果大家对于爬虫非常感兴趣,也可以专门去学一学相对应的内容。这里简单说一下我的理解:我所理解的爬虫过程就是模拟浏览器发送请求,然后下载网页代码,只提取有用的信息,最后放入数据库或者文件中。
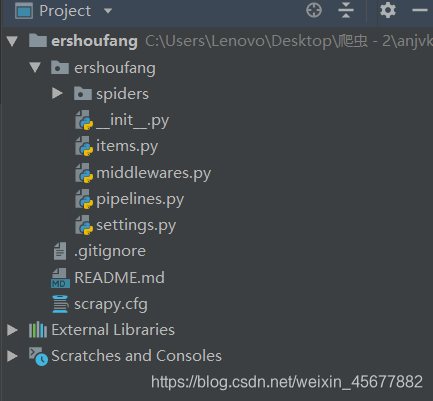
在安装好爬虫需要的一些库(scrapy)等以后,就可以找爬虫框架或者github上下载的爬虫代码,如下图所示,是爬虫目录的结构,这里包括了:
spiders文件夹 #放置关于爬虫部分的内容
_init_.py #项目初始化文件
items.py #数据容器文件
middlewares.py #中间件
pipelines.py #管道文件
settings.py #项目的设置文件
scrapy.cfg #项目运行的配置文件
首先先看spiders文件夹里的ershoufang.py文件 ,这里的逻辑是这样的,以我爬取的安居客长春二手房为例:
——>先点进安居客首页
——>点击二手房、房源

——>进入了二手房页面点击南关(因为我是需要分区的房屋信息,所以我是点进去每个区来爬取的),这里需要注意上方的网址,这也是我们最开始的初始网址,简单观察可以发现后面的数字是从p1-50的,代表着页数,nanguan代表着这个区

——>接下来网页向下翻就是每个我们需要爬取的链接入口
——>点进去就是每一个房源信息了。

知道了这个逻辑,代码就好理解了,我们上代码!!!
class ershoufangSpider(scrapy.Spider): name = "ershoufang" allowed_domains = ['anjuke.com'] # 生成起始网址 start_urls = [] for i in range(1,51): start_urls.append('https://heb.anjuke.com/sale/hulan/p%d/#filtersort'%i) # 采集每个房屋网址链接 def parse(self,response): # item = ErshoufangItem() selector = Selector(response) #url = Selector(respone) urls =selector.xpath(".//ul[@class='houselist-mod houselist-mod-new']/li") for url in urls: detail_url = url.xpath(".//div[@class='house-title']/a/@href").extract()[0] # item["url"] = detail_url yield scrapy.Request(detail_url,callback = self.parse_item) # yield item # 采集每个链接里面的房屋信息 def parse_item(self,response): item = ErshoufangItem() houses = response.xpath(".//div[@class='wrapper-lf']") # for house in houses: # houseLoc 房屋位置,houseInfo 房屋具体信息(几室几厅等),Community 社区信息(绿化率等) # propertyCosts 物业费,totalPrice 房屋总价格 if houses: item['houseLoc'] = houses.xpath(".//p[@class='loc-text']/a/text()").extract(), # item['houseEncode'] = house.xpath(".//h4/span[@class='house-encode']/text()").extract() item['houseInfo'] = houses.xpath(".//div[@class='houseInfo-content']/text()").extract() item['Community'] = houses.xpath(".//div[@class='commap-info-intro']/p/text()").extract() item['propertyCosts'] = houses.xpath(".//div[@class='commap-info-intro no-border-rg']/p/text()").extract() item['totalPrice'] = houses.xpath(".//span[@class='light info-tag']/em/text()").extract()这里应用了XPath来采取信息(应用re正则会是一种更好的选择,但是本人比较菜,在用爬虫时觉得XPath很好理解)。我们来说一下XPath,这里简单举一个例子,以房屋信息里面的housuInfo为例,对应如下图部分。先将鼠标放在房屋信息附近,点击右键,在点击检查,找到网页源码中对应要采集的信息部分(红色圈中的内容)填进XPath里,具体也可以再详细了解。


还有一个比较难的问题,就是历史价格的爬取,历史价格的数据不在网页源代码中,而是通过ajax加载的,按下图可以找到历史价格存储的网址,这里也需要解析网址(比如长春,网址中就是cc,后面都是一样的,直到commid=后面的数字是不一样的)。我们先提取后面的数字,然后再输入一个headers来模拟网址请求,防止被识别出来,然后获取历史数据。
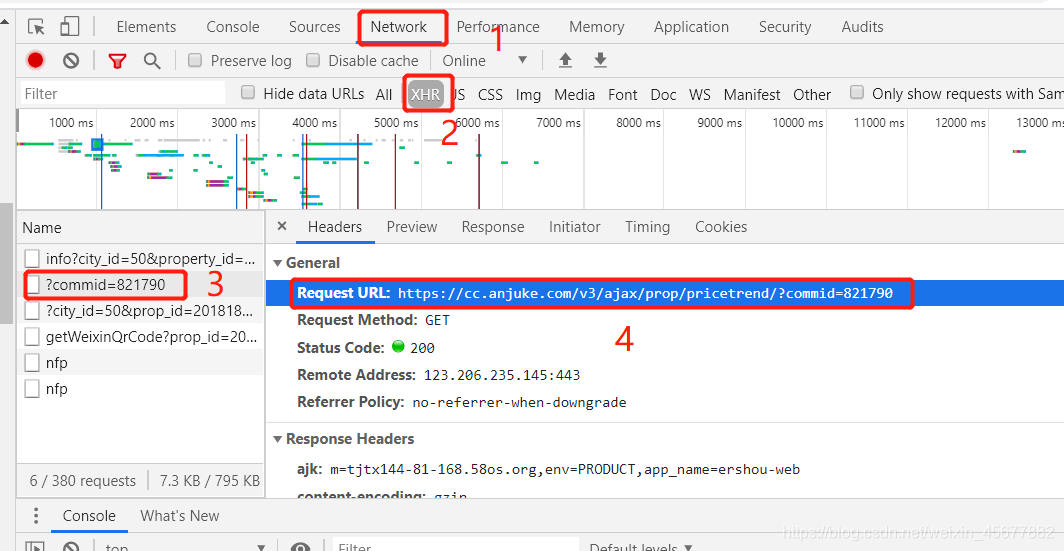
# 采集房屋历史单价 house_comid = response.xpath('/html').re(r'comid=.*?&') if house_comid: comid = house_comid[0].split('=')[-1][:-1] house_price_url = 'https://cc.anjuke.com/v3/ajax/prop/pricetrend/?commid=' + comid # 这里cc对应的是城市,记得要与起始网址的城市保持一致 headers = { 'accept': 'application/json, text/javascript, */*; q=0.01', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36', "x-requested-with": 'XMLHttpRequest' } response = requests.get(house_price_url, headers=headers) item['houseHistoryPrice'] = response.json().get('community')这个文件代码如下:
class ErshoufangItem(scrapy.Item): # define the fields for your item here like: houseLoc = scrapy.Field() # houseEncode = scrapy.Field() houseInfo = scrapy.Field() propertyCosts = scrapy.Field() Community = scrapy.Field() totalPrice = scrapy.Field() houseHistoryPrice = scrapy.Field() # url = scrapy.Field() pass可以看到我们在爬虫中应用到了哪些item,这里就定义哪些。
简单说一下我用的反反爬虫策略:
1. 比较简单的是添加随机的user-agent头(网络上也有很多)
def process_request(self, request, spider): ua = random.choice(self.user_agent_list) if ua: # print ua, '-----------------yyyyyyyyyyyyyyyyyyyyyyyyy' request.headers.setdefault('User-Agent', ua) # the default user_agent_list composes chrome,I E,firefox,Mozilla,opera,netscape # for more user agent strings,you can find it in https://www.useragentstring.com/pages/useragentstring.php user_agent_list = [ 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1', 'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1', 'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11', 'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)', 'Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0', "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/535.24", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36" ]2. 设置延迟时间,也就是别那么快获取信息
num=[55,60,50,48] DOWNLOAD_DELAY = random.choice(num)注意:安居客的反爬虫太厉害了,如果在没有代理Ip的情况下,建议不要把延迟速度调的太快,太快会封ip,或者出新验证的频率过高,影响爬虫。
3. 变换ip(可以找一些ip代理来变换)
# """ 阿布云代理配置""" proxy_server = "https://http-cla.abuyun.com:9030" proxy_user = "..." proxy_pass = "..." proxy_auth = "Basic " + base64.urlsafe_b64encode(bytes((proxy_user + ":" + proxy_pass), "ascii")).decode("utf8") """ 启用限速设置 """ # 如果没有设置延迟,也可以这里设置 AUTOTHROTTLE_ENABLED = True AUTOTHROTTLE_START_DELAY = 0.5 # 初始下载延迟 DOWNLOAD_DELAY = 0.2 # 每次请求间隔时间 class ABYProxyMiddleware(object): """ 阿布云代理中间件 """ def process_request(self, request, spider): request.meta["proxy"] = proxy_server request.headers["Proxy-Authorization"] = proxy_auth我用的是阿布云代理经典版,可以买按小时计算的,1元/时,我爬的数据不多,按小时来买就足够了,不是广告!!!!
如果需要可以看看别的代理~
执行指令:
scrapy crawl ershoufang -o file_name.csv
运行结果如下如 :
完整源代码请点击这里是我!
本人也是初学者,而且时间紧任务重,有些内容讲述也许存在问题或者不准确的情况,欢迎大家批评指正,相互学习!
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)

