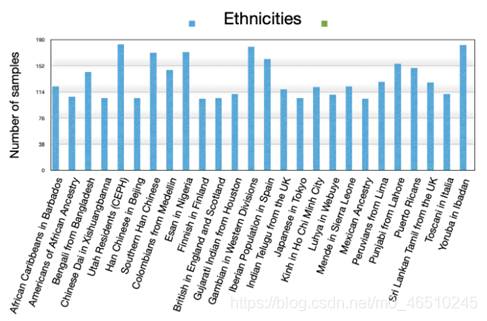
我最近进行了有关基因序列的研究工作。我想到的主要问题是:“哪一种最简单的神经网络能与遗传数据最匹配”。经过大量文献回顾,我发现与该主题相关的最接地气却非常有趣的工作是在Yoshua Bengio 教授的实验室中进行的。这篇论文的题目是:“饮食网络:脂肪基因组学的瘦参数”,它的主要目标是将基因序列划分为26个种族。我从那篇论文中得到了灵感,在这里我想解释一下建立神经网络来解决这类问题的基本原理。要阅读这篇博客,不需要生物学方面的背景知识;为了直接进入计算部分,我将尝试覆盖大部分必要的部分。 我们目前正面临艰难时刻:SARS-CoV-2病毒使我们对大自然的强大力量束手无策。通过学习新工具,获得有关基因组的数据直觉,并探索哪种机器学习方法可以最佳地概括该数据,我希望我们能够团结一致,为美好的明天做出改变,或者至少使用神经网络做一些除了娱乐自己以外,可以拯救我们的生命和地球的事情。 为什么我发现遗传学如此吸引人? 你的基因不仅揭示你的信息,而且还揭示出祖先的基因组历史,通过这么多年保存下来的显性基因。换句话说,它是你家族的生物进化编码,而且根据达尔文的进化论,所有的有机生物(植物、动物等)都有相同的基因组原理。 让我们浏览其他类型的数据,例如图像和句子,以了解遗传数据的独特性。一方面,图像是具有相邻关系的二维数据(或三维体),句子是由非监督方式训练的具有句子层次性质的一维向量。另一方面,遗传序列是至少成千上万个值的一维向量(序列),在邻居之间没有明确定义的关系,并且没有具有预先训练的模型集。因此,在图像处理中非常流行的高斯平滑滤波在这里没用,并且视觉中的所有预训练模型(*ImageNet,VGG,ResNet *…)和自然语言处理(*Word2Vec,Glove,BERT *…)都被淘汰出局。 为什么这是一个挑战 想想一个包含数千个遗传样本的数据库。您需要找到一种方法,该方法它能很好地概括成千上万个组合的输入数据(准确性超过90%)。在这里使用神经网络可能是一个很好的工具,因为它利用了全连接层的功能,而这种方式在其他”经典”算法(例如PCA,SVM和决策树)中是缺少的,而这些算法无法单独管理数据。构建最简单的网络体系结构需要成功地预测第一层的权值,这将为您留下数千万个自由参数。降维(以避免过多的自由参数)是解决这个问题的一种方法,我们将在本博客后面讨论它。 为了弄清这个问题,同时也不妨碍这个论坛的主要目的,我在这里仅提出本博客所需要的生物学部分的高级观点。不用说,我们非常欢迎您进一步探讨这些生物学主题中的任何一个。 什么是遗传序列? 一个DNA分子是由四种碱基组成的序列,这些碱基由A、C、G、t的字母表示:序列的特定部分(即使位于较远的地方)与表现型相关。例如,最近的一项研究:”一种可能起源于蝙蝠的新型冠状病毒引发的肺炎暴发”表明ACE2基因可能是SARS-CoV-2病毒的宿主受体(表现型)。有趣的是,仅凭你的DNA就能获得多少有价值的信息(罪犯检测、匹配大麻品种、营养和个性化药物)。 什么是SNP基因型? 如今,我们比以往任何时候都更接近于实现几乎完整的人类基因组序列。然而,我们还远远没有涵盖全部。单核苷酸多态性SNPs是基因组序列中特定的基因型位点,一般以RS[数字]表示。不同的种群有不同的序列不变量,但在家族内部可能是相同的(因此亚洲人看起来与欧洲人不同)。对SNP序列的分析将是本博客其余部分的重点。 方法 我将介绍两种主要的网络架构(以及另一种网络,它的参数经过了改进,从而克服了机器学习中的一些主要问题)以及一些技术技巧… 数据 相对于其他数据类型,医疗数据集很难找到,主要是由于隐私限制。针对此,”千人基因组计划”取得了重大突破,公布了一个包含3450个人类DNA样本的公共数据集,每个样本包含全球26种族的315000个snp。下一幅图显示了来自1000个基因组数据的直方图,描绘了每个种群(种族)的个体频率。 1000个基因组人口分布(种族) 降维 如上所述,减少模型中的自由参数是很必要的 结构 我们比较了两个主要网络。这两个网络都包含两个完全连接的隐藏层,后跟一个softmax层,但是第二个网络包含辅助网络,该辅助网络可预测判别网络的自由参数。所述辅助网络以嵌入矩阵为输入,并返回判别网络的权重(图1)。 图1:两种区分模型,无(上)和有辅助网络(下) 可以在图2中看到该体系结构的详细说明:批处理规范层,然后在每个全连接层之前接一个dropout层。 我从头开始编写了整个代码,可以在名为” 人类基因组 ” 的公共GitHub存储库中找到它。以下是我发现与该论坛最相关的一些一般要点。 1.管理数据结构 为了获得客观的结果,我们生成五个分支,每个实验一个分支,计算最后的统计变量。 我们将3.5K样本分为训练(60%),验证(20%)和测试(20%)。像往常一样,我们随机打乱数据并标准化值: 2.数据降维 生成嵌入矩阵的过程分为两个步骤:第一步生成每个类的基因型直方图,bincount()第二步对该直方图进行归一化。结果是维数减少了大约十个数量级。 3.连接网络 这就是我们连接网络的方式:在区分模型的第一个隐藏层中,我们使用辅助网络(即嵌入层)的输出来初始化其3000万权重。 4. 训练循环 根据我们的小批量工作来扩大工作范围。 函数:loss_fn 我强烈建议使用 early stopping,这样做的理由是根据验证损失自动确定何时停止训练并保存最佳的最后模型结果。 以下是一些我认为有用(免费)的好工具: 神经网络库 我必须提到使用Pytorch作为最佳神经网络库的好处,根据我的经验,与许多其他方法相比,它在许多方面都是最佳的。 云端训练 您将受益于在云端训练模型并节省时间。 结果 我回顾了数据科学家在分析结果时遇到的一些已知困难,并发现有必要与你这些困难,以便为开发此类网络的动态行为提供可靠的证据。在研究你们的网络的性能时,我发现以下是主要的特征: 让我们从损失函数开始:这是网络性能的”面包和黄油”,loss在epoch中呈指数级下降。同时,模型的通用性较好,使验证损失保持在训练损失的范围内。原因很简单:模型在训练时而不是验证时,返回一个更高的损失值,如果您遇到这样的情况,你的模型可能是过度拟合的。过拟合的解决方案可以是以下一种或多种:第一种是降低隐藏层单元或去除层以减少自由参数的数量。如前所述,我们的辅助网络可以解决这个问题。其他可能的解决方案是增加Dropout值或规范化。Mazid 测试精度是在每种体系结构中计算的。似乎克服过度拟合或减少自由参数的数量并不能保证更高的准确性。图4显示了三种体系结构的测试精度:令人惊讶的是,尽管存在过度拟合问题(在没有辅助网络的情况下更高),但精度更高。 测试不同批次大小的性能可能会很有趣,Kevin 图6清楚地显示了在训练时间上使用不同批次大小的行为,两种体系结构都具有相同的效果:批次大小越大,统计上的效率就越高,但不能保证泛化。阅读文章:”Train 图6:不同批次大小的总训练时间 请注意,根据训练时间更改架构的效果(图7)。具有1500万个免费参数的培训时间明显少于辅助网络。 我还将改进的模型的性能与决策树方法进行了比较,特别是在数据科学领域中常用的”the 讨论区 哪个是最好的模型?(最重要的问题) 我描述了两个主要网络:具有和不具有辅助网络以及具有改进参数的附加网络。参数预测网络的好处是,当输入的维数很高时,如遗传序列中那样,它将大大减少模型第一层中自由参数的数量。我展示了如何更改基本网络的参数在过拟合方面如何更好地泛化。我在公开的1000个基因组数据集上验证了这些网络的方法,从而解决了基于SNP数据的祖先预测任务。这项工作证明了神经网络模型解决样本数量与其高维数不匹配的任务方面的潜力。 鉴于血统预测任务中获得的高精度,我相信神经网络技术可以改善遗传数据分析中的标准实践。我希望这些技术将使我们能够应对更具挑战性的遗传关联研究。 附录 使用决策树的结果 除了我强调的神经网络方法外,我还要提及我在Gradient Boosting Decision 作者Miri Trope deephub翻译组 gkkkkkk

DNA双螺旋(已对齐)合并神经网络(黄色)动机
直觉
生物学背景
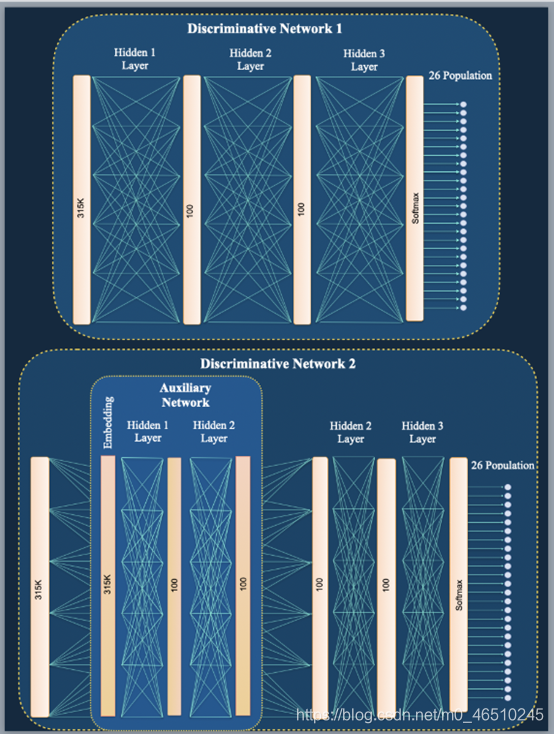
(在我们的例子中,我们要处理大约3000万个参数)。为了达到这个目的,所提出的方法是在判别网络的基础上使用另一个辅助网络,该网络的输入是每个类的直方图(一个以无监督方式计算的嵌入矩阵)。该网络的输出初始化了判别网络第一层的权值。嵌入矩阵为每个种群的归一化基因型直方图,大小为SNPs
X
[4×26],其中4为4个基因型,26为类(种群)数。这种嵌入矩阵的实现如下所述。我的解决方案是通过减少隐藏单元层的数量(参见架构部分),我称这种新架构为改进的模型,它的好处之一是克服了过拟合,稍后的结果部分将对此进行讨论。

实现


(y, yhat)返回输入y和目标
中每个元素之间的均方误差(L2范数平方)。因为我们要计算损失,所以我们需要将该值乘以批次大小,然后汇总每个minibatch的所有返回值。

最后,每个epoch包含最后一节的累计值。因此,为了获得损失,我们需要除以该循环中的minibatch数量。构架
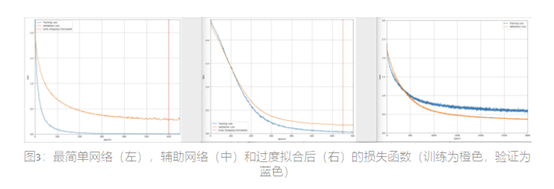
Osseni在他的博客中解释了不同类型的正则化——方法和实现。图3是处理过拟合问题之前(左侧)和之后(右侧)的简化版的损失函数。我的解决方案是降低隐藏单元的大小(从100到50个单元)和增加第一层的dropout值(从0.5到0.8)的组合。辅助网络可能解决了大量自由参数的问题,但正如您所看到的,它仍然是过拟合的。

Shen在他的博客中研究了批次大小对训练动态的影响。根据总训练时间,可能由于数据多样性,批次大小与训练时间成反比(图6)。出于同样的原因,损失与批量大小成正比(图5)。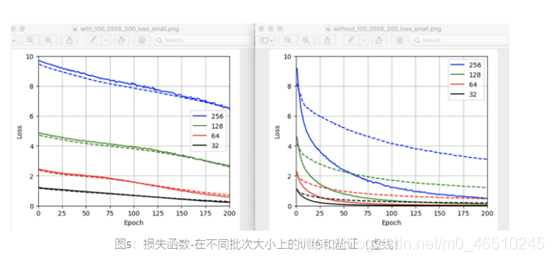
longer, generalize better: closing the generalization gap in large batch
training of neural
networks”以了解更多有关泛化现象和提高泛化性能的方法,同时在使用大批量训练时时保持训练时间不变。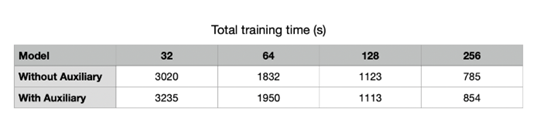
图7:三种架构的eopch(批处理大小:64)
Light Gradient Boosting
Machine”。但是,在误分类错误方面,性能超出了我们的限制.(有关更多详细信息,请参见附录)。
Tree上的经验结果。可以在LightGBM GitHub中找到实现。该算法的参数为: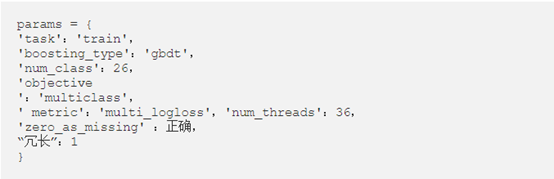
结果表明,决策树的分类误差更高,这说明了其原因超出了博客的范围。

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










