四小时学python爬虫爬取信息系列(第一天)(全是干货) 1.安装requests库(可以在电脑python,我是进入anaconda我建的虚拟环境) anaconda虚拟环境法流程: 电脑python流程:直接cmd,输入下面命令,可能会提示你升级pip ,可以升级 2.验证安装,爬取csdn的主页验证一下(直接在命令行python或者在python idle进行输入) 3.r=requests.get(url) 解析:先构造一个请求向服务器资源的Request对象,return一个包含资源的Response对象。 返回的Response对象有五种常用属性 csdn的页面r.encoding return ‘UTF-8’ ,再试一试r.apparent_encoding return ‘utf-8’, Requests库的异常 实例测试,还是爬csdn主页 效果截图: 4.Requests库,基于HTTP协议,超文本传输协议“请求与响应”模式的无状态的应用层协议,我个人觉得就像qt中signal和slot一样。HTTP:connect(&my,SIGNAL(request()),&Internrt_server,SLOT(return_Response())); 5.详解Requests库 6.在爬取信息的同时要遵守网络的Robots协议,例如csdn的Robots协议如下 https://www.csdn.net/robots.txt 7.知道了Robots协议,我们开始爬 1)先爬一下京东里其中一个小米10的手机 然后京东的服务器返回如下,其中第一个网址,我点开发现是登陆界面,可能京东不让这种小爬虫爬,要登录,我换一个网站。 2)爬亚马逊(用cmd然后python再爬) 第一次访问被亚马逊识别出我是python爬虫,咱们就修改一下访问的头 整理一下 3)百度关键词的提交 整理: 输出: 点开返回的网址会发现,百度的安全验证 转到正面以后会进入如下图所示 4)爬取图片(直接运行会爬到一张狼的图片,存储到root下,存储名字为图片在网站上的原名) 5)查询ip地址归属(‘0,0,0,0’为IP地址,自己可以改一下试一下) 收工,第二天继续更新,,,,有用的话请您点个赞吧。
conda activate py36 //进入我的py36环境 pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple //安装requests库 #如果需要升级pip输入:python -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple //安装requests库 import requests r = requests.get("https://www.csdn.net/") r.status_code #返回状态为200,证明访问成功,返回值非200则失败 #输入:type(r) #return <class 'requests.models.Response'> #检测返回值类型, #如果输入:r.headers 则return页面头信息 r.encoding='utf-8' r.text #抓取成功,显示如下图(我在cmd操作的) 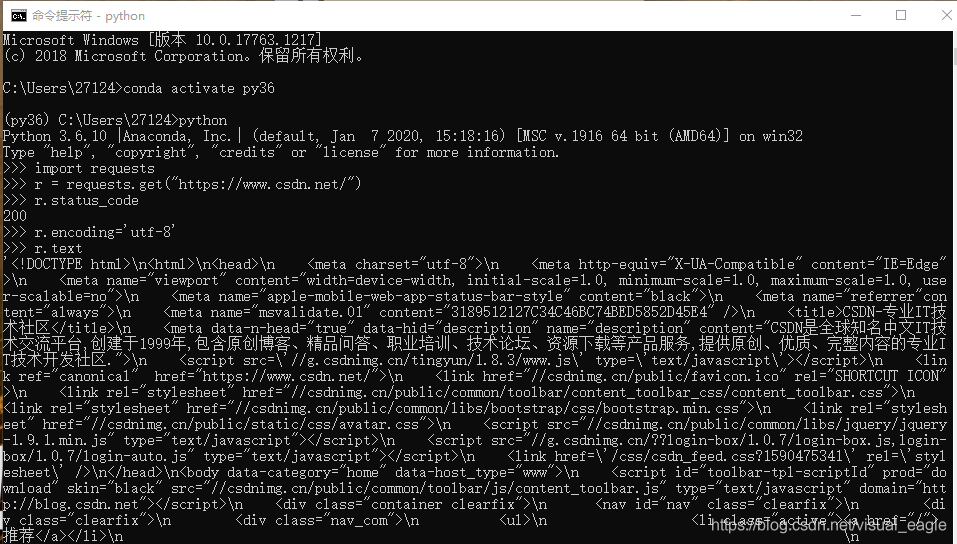
request.get(url,params=None,**kwargs) #url:网页链接 #params:链接中的额外参数,可选字典或字节流格式 #**kwargs:12个控制访问的参数 r.status_code #HTTP请求的访问状态,只有200是成功 r.text #HTTP响应的内容,就是网页页面 r.encoding #HTTP header中猜测响应内容编码方式 r.apparent_encoding #从内容中分析出的响应内容编码方式,备选的编码方式 r.content #HTTP响应内容的二进制形式 #测试一下 import requests r=requests.get("https://www.csdn.net/") r.status_code r.encoding r.apparent_encoding #在r.encoding不能正确得到编码时就用r.apparent_encoding requests.ConnectionErroe #网络连接错误 requests.HTTPError #HTTP错误 requests.URLRequired #URL错误 requests.TooManyRedirects #超过最大重定向次数,产生重定义定向异常 requests.ConnectTimeout #连接远程服务器超时 requests.Timeout #请求URL超时产生异常 import requests def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() #200则正常,非200返回requsets.HTTPError r.encoding=r.apparent_encoding return r.text except: return "Error!!!" if __name__ == "__main__": url = "https://www.csdn.net/" print( getHTMLText(url) ) 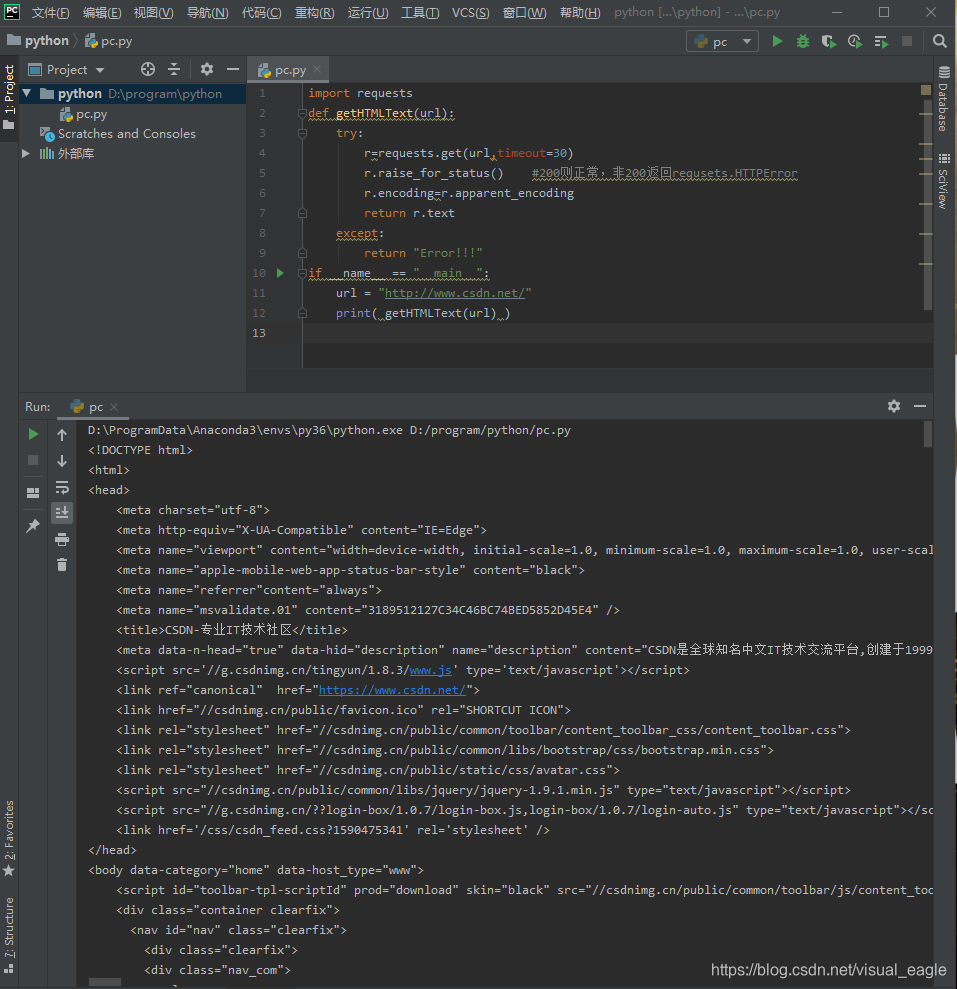
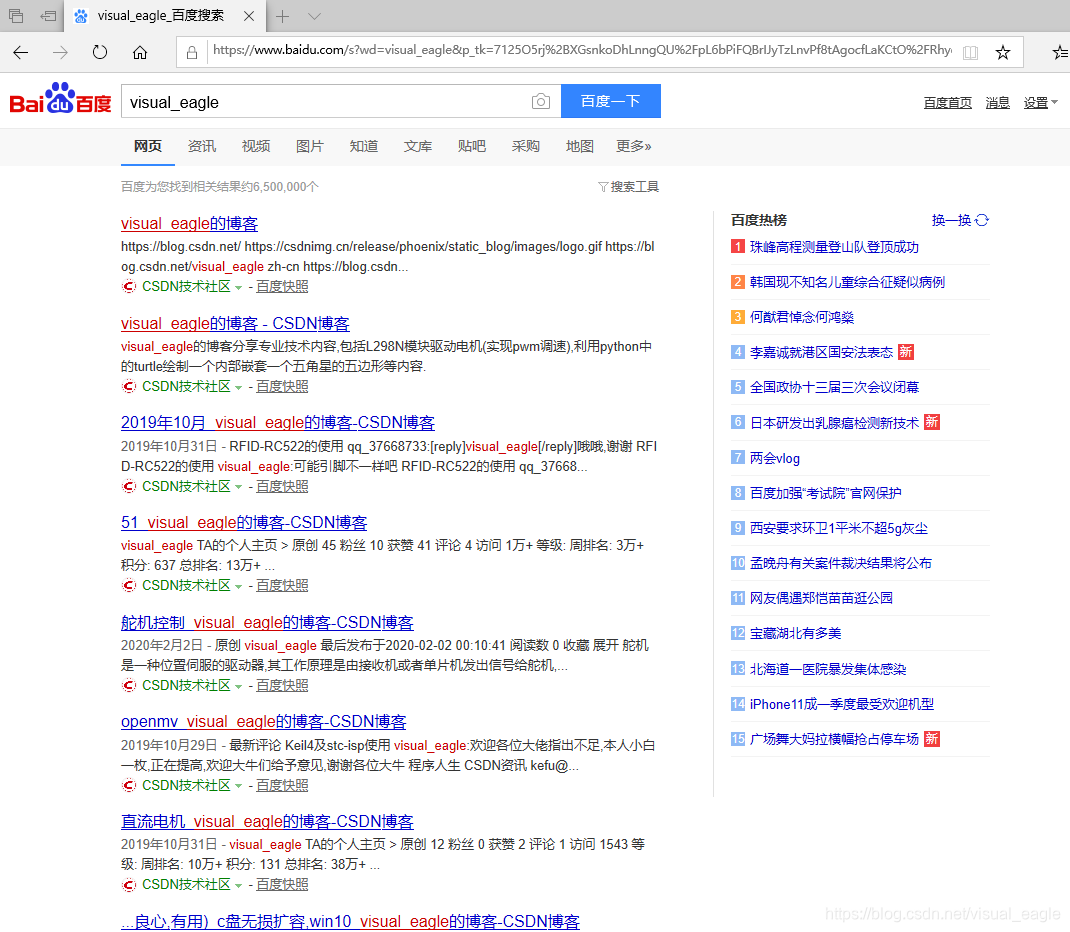
#URL格式: https://host[:port][path] # host:IP地址 #port:端口号,不写默认80 #path:路径 #HTTP协议对资源操作 CET #请求获取URL位置资源 HEAD #获取资源头部信息 POST #请求x向URL位置的资源后附加新的数据 PUT #请求向URL位置存储一个资源,覆盖原URL位置的资源 PATCH #请求局部更新URL位置的资源,即改变该处外部资源的部分内容 DELETE #请求删除URL位置存储资源 #关系图解: # GET HEAD # my <———————————— server # URL # my ————————————> server # PUT POST PATCH DELETE #Requests库常用 requests.request() #构造一个请求 requests.get() #get HTML网页 requests.head() #get HTML网页头信息 requests.post() #向HTML网页提交POST请求 requests.put() #向HTML网页提交PUT请求 requests.patch() #向HTML网页提交局部修改请求 requests.delete() #向HTML网页提交删除请求 1.requests.request(method,url,**kwargs) #构造一个请求,method对应get,head,post,put等七种,url对应网络链接,**kwargs 13个控制访问参数 method: r=requests.request('GET',url,**kwargs) r=requests.request('HEAD',url,**kwargs) r=requests.request('POST',url,**kwargs) r=requests.request('PUT',url,**kwargs) r=requests.request('PATCH',url,**kwargs) r=requests.request('DELETE',url,**kwargs) r=requests.request('OPTIONS',url,**kwargs) **kwargs: 1)params #字典或字节序列,作为参数增加到url中 >>>kv={'key1':'value1','key2':'value2'} >>>r=requests.request('GET','https://python123.io/ws',params=kv) >>>print(r.url) #输出:https://python123.io/ws?key1=value1&key2=value2 2)data:字典、字节序列或文件对象,作为Request的内容 >>>kv={'key1':'value1','key2':'value2'} >>>r=requests.request('POST','https://python123.io/ws',data=kv) >>>body='主体内容' >>>r=requests.request('POST','https://python123.io/ws',data=body) 3)json:JSON格式数据 >>>kv={'key1':'value1'} >>>r=requests.request('POST','https://python123.io/ws',json=kv) 4)heders:字典,HTTP定制头 >>>h={'user-agent':'Chrome/10'} >>>r=requests.request('POST','https://python123.io/ws',headers=h) 5)cookies:字典或CookieJar 6)auth:元组,支持HTTP认证功能 7)files:字典类型,传输文件 >>>f={'file':open('data.xls','rb')} >>>r=requests.request('POST','https://python123.io/ws',files=f) 8)timeout:设定的超时单位,s为单位 >>>r=requests.request('GET','https://www.csdn.net/',timeout=10) 9)proxies:字典类型,设定访问代理服务器,可以增加登录认证,可以隐藏用户原IP,防止对爬虫的逆追踪 >>>pxs={'http':'https://user:pass@10.11.12.1:1234' 'https':'https://10.11.12.1:1234'} >>>r=requests.request('GET','https://www.csdn.net/',proxies=pxs) 10)allow_redirects:True/False,默认为True,重定向开关 11)stream:True/False,默认为True,获取内容立即下载的开关 12)verify:True/False,默认为True,认证SSL证书的开关 13)cert:保存本地SSL证书路径 2.requests.get(url,params=None,**kwargs) #url:网页链接 #params:url中的额外参数,字典或字节流格式,可选 #**kwargs:12个控制访问的参数,除了params 3.requests.head(url,**kwargs) #url:网页链接 #**kwargs:13个控制访问的参数 4.requests.post(url,data=None,json=None,**kwargs) #url:网页链接 #data:字典、字节序列或文件,Request的内容 #json:JSON格式的数据,Request的内容 #**kwargs:11个控制访问的参数,除了data和json 5.requests.put(url,data=None,**kwargs) #url:网页链接 #data:字典、字节序列或文件,Request的内容 #**kwargs:12个控制访问的参数,除了data 6.requests.patch(url,data=None,**kwargs) #url:网页链接 #data:字典、字节序列或文件,Request的内容 #**kwargs:12个控制访问的参数,除了data 7.requests.delete(url,**kwargs) #url:网页链接 #**kwargs:13个控制访问的参数 User-agent: * Disallow: /scripts Disallow: /public Disallow: /css/ Disallow: /images/ Disallow: /content/ Disallow: /ui/ Disallow: /js/ Disallow: /scripts/ Disallow: /article_preview.html* Disallow: /tag/ Disallow: /*?* Disallow: /link/ Sitemap: https://www.csdn.net/article/sitemap.txt #解读:*:所有 /:更目录 Disallow:不允许爬取的 import requests url="https://item.jd.com/12843872.html" try: r=requests.get(url) r.raise_for_status() r.encoding=r.apparent_encoding print(r.text[:1000]) except: print("爬取失败") <script>window.location.href='https://passport.jd.com/uc/login?ReturnUrl=https://item.jd.com/12843872.html'</script> >>> import requests >>> r=requests.get("https://www.amazon.cn/dp/B081W297S2/ref=sr_1_1?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&keywords=%E9%9B%A8%E4%BC%9E&qid=1590566477&sr=8-1") >>> r.status_code #return 503 >>> r.encoding #return 'ISO-8859-1' r>>> .encoding=r.apparent_encoding >>> r.text #会出现一堆英文,大致意思就是亚马逊提示你访问遇到错误 >>> r.request.headers #输出头部,会发现被识别了,我是python爬虫 {'User-Agent': 'python-requests/2.23.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} >>> kv={'user-agent':'Mozilla/5.0'} #模拟浏览器 >>> url="https://www.amazon.cn/dp/B081W297S2/ref=sr_1_1?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&keywords=%E9%9B%A8%E4%BC%9E&qid=1590566477&sr=8-1" >>> r=requests.get(url,headers=kv) >>> r.status_code #return 200 访问成功了! >>> r.request.headers #验证返回 {'user-agent': 'Mozilla/5.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} >>>r.text #爬到了 import requests url="https://www.amazon.cn/dp/B081W297S2/ref=sr_1_1?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&keywords=%E9%9B%A8%E4%BC%9E&qid=1590566477&sr=8-1" try: kv = {'user-agent': 'Mozilla/5.0'} r=requests.get(url,headers=kv) r.raise_for_status() r.encoding=r.apparent_encoding print(r.text[:1000]) except: print("爬取失败") #百度关键词接口: https://www.baidu.com/s?wd=keyword import requests kv={'wd':'visual_eagle'} r=requests.get("https://www.baidu.com/s",params=kv) r.status_code #return 200,访问成功 r.request.url #return 'https://wappass.baidu.com/static/captcha/tuxing.html? #&ak=c27bbc89afca0463650ac9bde68ebe06&backurl=https%3A%2F%2Fwww.baidu.com%2Fs%3Fwd%3Dvisual_eagle&l#ogid=9103391829453353255&signature=939422699e3799bc3e948e343ea5dfa3×tamp=1590568918' len(r.text) #return 1519,也就是1k多的信息 import requests keyword="visual_eagle" url="https://www.baidu.com/s" try: kv = {'wd': keyword} r=requests.get(url,params=kv) print(r.request.url) r.raise_for_status() print(len(r.text)) except: print("爬取失败") https://wappass.baidu.com/static/captcha/tuxing.html?&ak=c27bbc89afca0463650ac9bde68ebe06&backurl=https%3A%2F%2Fwww.baidu.com%2Fs%3Fwd%3Dvisual_eagle&logid=6903876124859043345&signature=43015c36a586cbce79bfa0ed51610283×tamp=1590569408 1519 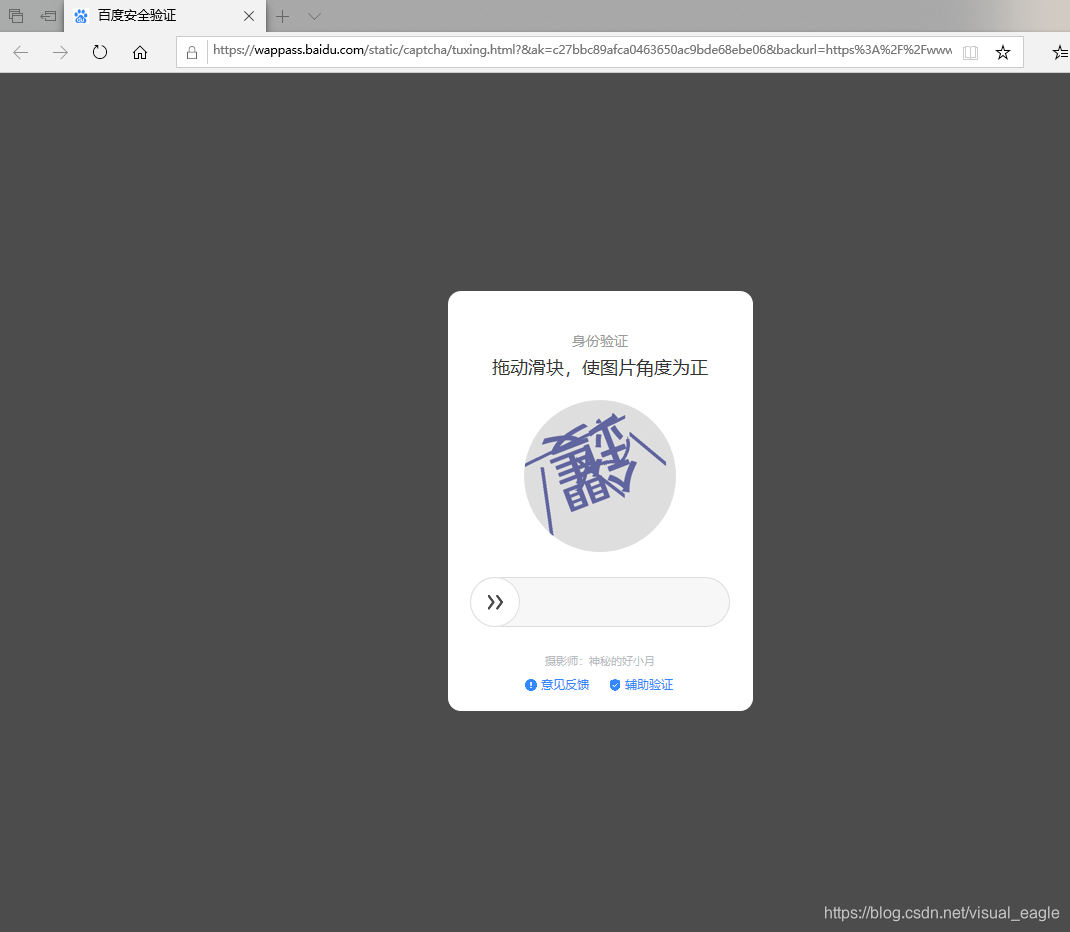
import requests import os url="https://image.nationalgeographic.com.cn/2017/0211/20170211061910157.jpg" root="D://image//test//" path=root+url.split('/')[-1] try: if not os.path.exists(root): os.mkdir(root) if not os.path.exists(path): r=requests.get(url) with open(path,'wb') as f: f.write(r.content) f.close() print("文件保存成功") else: print("文件已存在") except: print("爬取失败") import requests url="https://m.ip138.com/ip.asp?ip=" try: r=requests.get(url+'0.0.0.0') r.raise_for_status() r.encoding=r.apparent_encoding print(r.text[-500:]) except: print("爬取失败")
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 4880
4880