Binwalk是用于搜索给定二进制镜像文件以获取嵌入的文件和代码的工具。 具体来说,它被设计用于识别嵌入固件镜像内的文件和代码。 Binwalk使用libmagic库,因此它与Unix文件实用程序创建的魔数签名兼容。 Binwalk还包括一个自定义魔数签名文件,其中包含常见的诸如压缩/存档文件,固件头,Linux内核,引导加载程序,文件系统等的固件映像中常见文件的改进魔数签名。
Binwalk工具使用
binwalk工具说明
binwalk工具的使用帮助
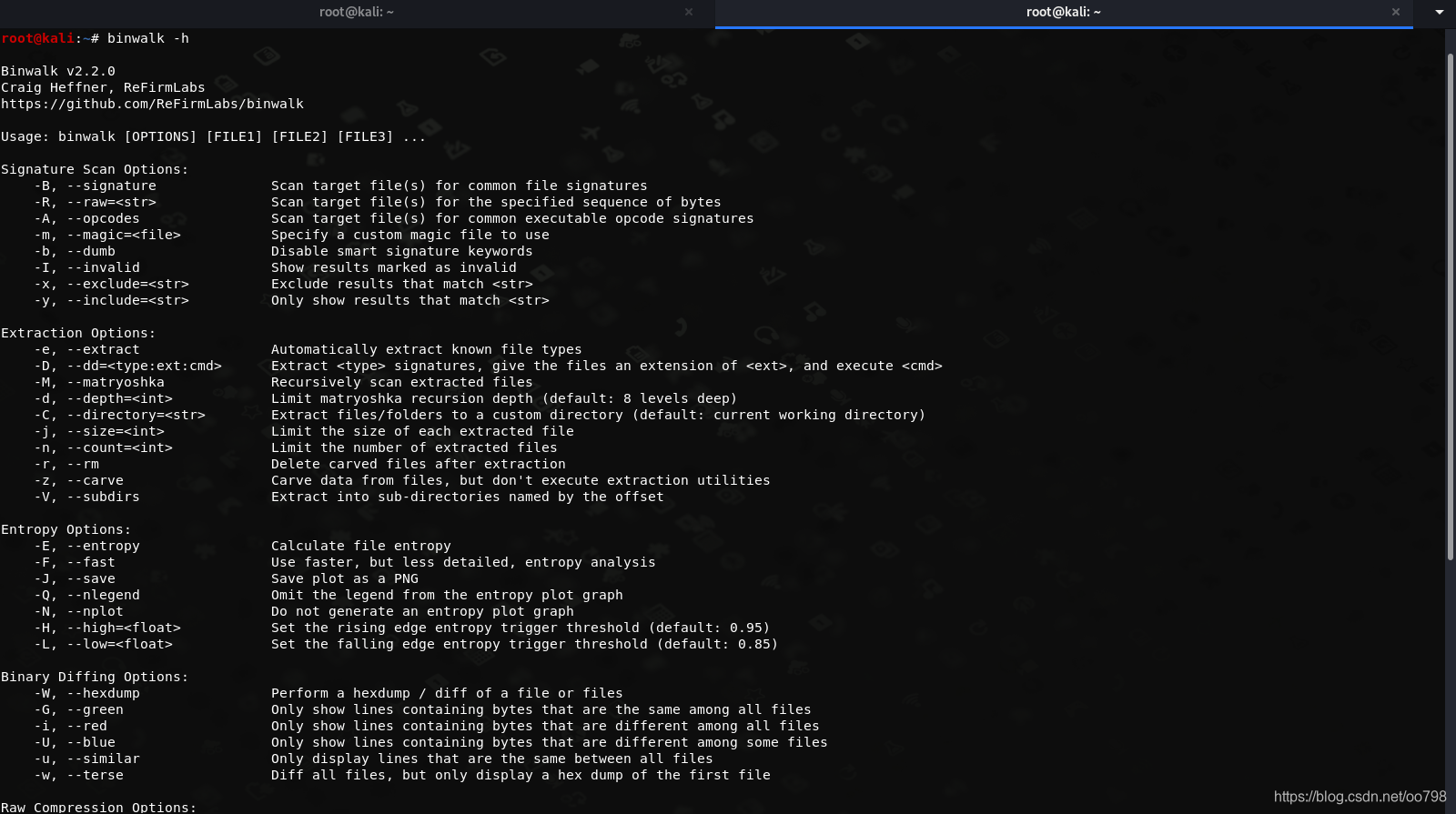
这里我给大家做了翻译 Signature Scan Options: 签名扫描选项: -B, --signature Scan target file(s) for common file signatures -B,——签名扫描目标文件的常见文件签名 -R, --raw=<str> Scan target file(s) for the specified sequence of bytes -R,——raw=<str>扫描指定字节序列的目标文件 -A, --opcodes Scan target file(s) for common executable opcode signatures 扫描目标文件,寻找通用的可执行操作码签名 -m, --magic=<file> Specify a custom magic file to use -m,——magic=<file>指定要使用的自定义magic文件 -b, --dumb Disable smart signature keywords -b,——哑禁用智能签名关键字 -I, --invalid Show results marked as invalid -I,——invalid显示标记为无效的结果 -x, --exclude=<str> Exclude results that match <str> -x,——exclude=<str>排除匹配<str>的结果 -y, --include=<str> Only show results that match <str> -y,——include=<str>只显示匹配<str>的结果 Extraction Options: 提取选项: -e, --extract Automatically extract known file types 自动提取已知的文件类型 -D, --dd=<type:ext:cmd> Extract <type> signatures, give the files an extension of <ext>, and execute <cmd> -D,——dd=<type:ext:cmd>提取<type>签名,给文件一个扩展名<ext>,并执行<cmd> -M, --matryoshka Recursively scan extracted files 递归扫描提取的文件 -d, --depth=<int> Limit matryoshka recursion depth (default: 8 levels deep) -d,——depth=<int> Limit苦参递归深度(默认:8层深度) -C, --directory=<str> Extract files/folders to a custom directory (default: current working directory) -C,——directory=<str>解压文件/文件夹到自定义目录(默认:当前工作目录) -j, --size=<int> Limit the size of each extracted file -j,——size=<int>限制每个提取文件的大小 -n, --count=<int> Limit the number of extracted files -n,——count=<int>限制提取文件的数量 -r, --rm Delete carved files after extraction -r,——rm删除雕刻后的文件提取 -z, --carve Carve data from files, but don't execute extraction utilities 从文件中切割数据,但不执行提取实用程序 -V, --subdirs Extract into sub-directories named by the offset subdirs提取到由偏移量命名的子目录中 Entropy Options: 熵的选择: -E, --entropy Calculate file entropy 计算文件熵 -F, --fast Use faster, but less detailed, entropy analysis -F,——快速使用更快,但不太详细的熵分析 -J, --save Save plot as a PNG -J,——保存保存情节为一个PNG -Q, --nlegend Omit the legend from the entropy plot graph -Q,——nlegend省略掉熵图中的图例 -N, --nplot Do not generate an entropy plot graph 不生成熵图 -H, --high=<float> Set the rising edge entropy trigger threshold (default: 0.95) -H,——high=<float>设置上升边熵触发阈值(默认值:0.95) -L, --low=<float> Set the falling edge entropy trigger threshold (default: 0.85) -L,——low=<float>设置跌落边缘熵触发阈值(默认值:0.85) Binary Diffing Options: 二进制dif选项: -W, --hexdump Perform a hexdump / diff of a file or files -W,——hexdump执行一个或多个文件的hexdump / diff -G, --green Only show lines containing bytes that are the same among all files -G,——绿色只显示包含在所有文件中相同的字节的行 -i, --red Only show lines containing bytes that are different among all files -i,——红色只显示包含在所有文件中不同的字节的行 -U, --blue Only show lines containing bytes that are different among some files -U,——蓝色只显示包含不同于某些文件的字节的行 -u, --similar Only display lines that are the same between all files -u——只显示在所有文件之间相同的行 -w, --terse Diff all files, but only display a hex dump of the first file -w,——简写Diff所有文件,但只显示第一个文件的十六进制转储 Raw Compression Options: 原始压缩选项: -X, --deflate Scan for raw deflate compression streams -X,——放气扫描原始放气压缩流 -Z, --lzma Scan for raw LZMA compression streams -Z,——lzma扫描原始lzma压缩流 -P, --partial Perform a superficial, but faster, scan 执行一个表面的,但更快的扫描 -S, --stop Stop after the first result 在第一个结果之后停止 General Options: 一般选择: -l, --length=<int> Number of bytes to scan -l,——length=<int>要扫描的字节数 -o, --offset=<int> Start scan at this file offset -o,——offset=<int>开始扫描这个文件的偏移量 -O, --base=<int> Add a base address to all printed offsets 向所有打印的偏移量添加一个基址 -K, --block=<int> Set file block size -K,——block=<int> Set file block size -g, --swap=<int> Reverse every n bytes before scanning -g,——swap=<int>在扫描前每n个字节反转一次 -f, --log=<file> Log results to file -f,——log=<file> log results to file -c, --csv Log results to file in CSV format -c,——csv日志结果文件在csv格式 -t, --term Format output to fit the terminal window -t,——term格式输出,以适合终端窗口 -q, --quiet Suppress output to stdout -q,——安静抑制输出到标准输出 -v, --verbose Enable verbose output 启用详细输出 -h, --help Show help output -h,——帮助显示帮助输出 -a, --finclude=<str> Only scan files whose names match this regex -a,——finclude=<str>只扫描名称与此正则表达式匹配的文件 -p, --fexclude=<str> Do not scan files whose names match this regex -p,——fexclude=<str>不扫描名称与此正则表达式匹配的文件 -s, --status=<int> Enable the status server on the specified port -s,——status=<int>启用指定端口上的状态服务器
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (169)
官方软件产品操作指南 (169)









