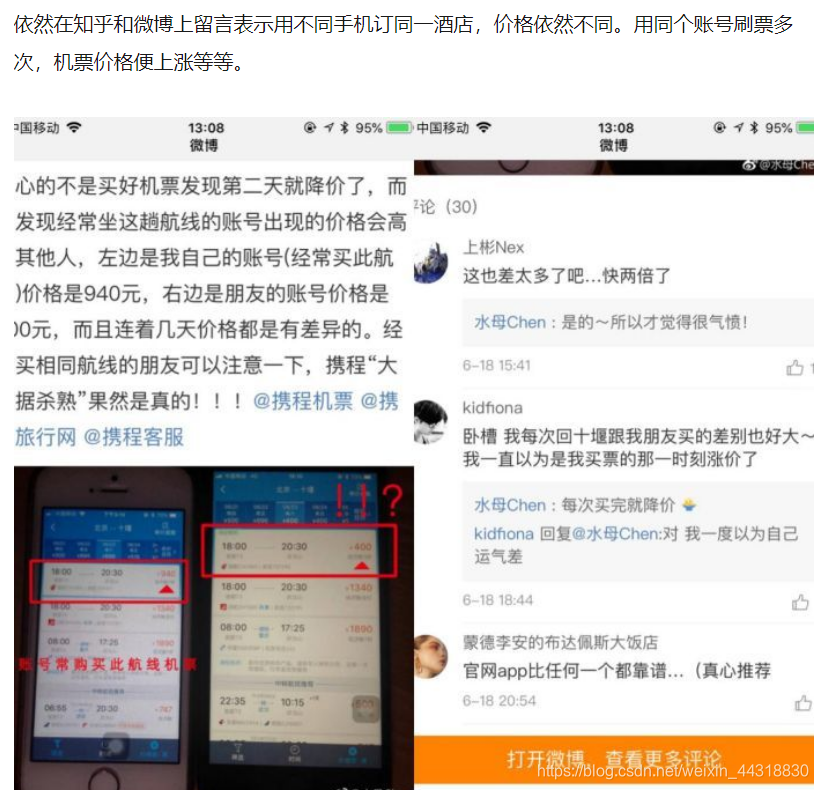
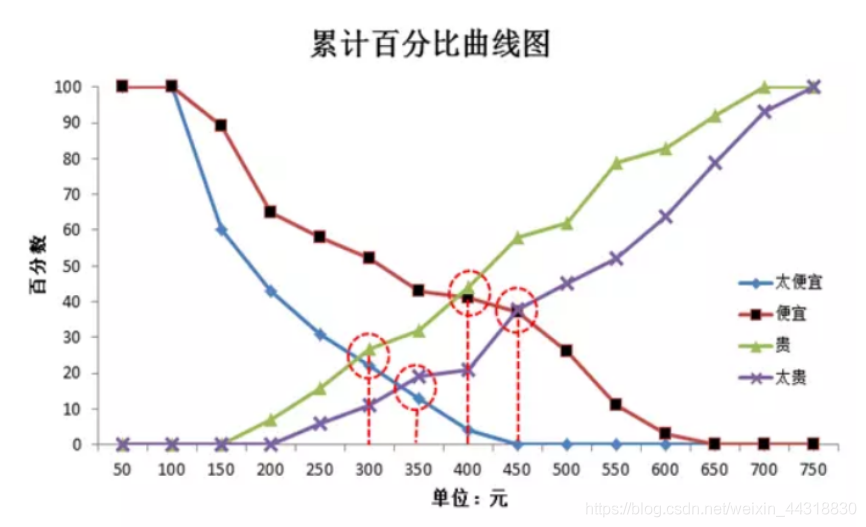
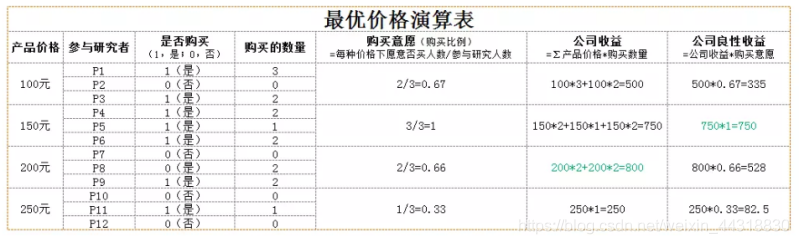
写在前面: 博主是一名软件工程系大数据应用开发专业大二的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白, 不知不觉,这已经是关于挖掘型标签开发的第三篇博客了。前面两篇已经为大家分别介绍了基于RFE和RFM模型的标签开发过程。感兴趣的朋友可以待到文末,乘坐博客直通车直达,一饱眼福。 本篇博客,我们来学习的是关于另一种模型——价格敏感度模型 在正式讲之前,我们先来看几篇关于大数据杀熟的报道。 【https://www.sohu.com/a/240094402_374686】 【https://www.qianjia.com/zhike/html/2019-10/11_13453.html】 【https://cloud.tencent.com/developer/article/1450512】 以第一篇报道为例,相信大家对于各行各业无良商家们的大数据杀熟手段都或多或少有所了解。 尤其是一些购票,订酒店的软件,针对不同的客户群体,相同的服务会给出不同的价格,让人着实气愤! 不久前,北京市消费者协会发布了“大数据杀熟”问题调查结果。结论显示被人们普遍认为存在的“大数据杀熟”现象,在实际体验调查中问题并不明显,由于其存在的复杂性和隐蔽性,维权举证存在困难。 “大数据只是一种手段和工具,‘杀熟’归根到底是企业的一种运营手段。”一业内人士解释道。众所周知,新用户的粘性比较低,对价格更为敏感,如果平台希望能够将其很好的留存,成为忠实用户,就会提供更多的优惠措施来留住他。相反,老用户则是平台的忠实用户,对于平台的信任度高,所以也就不会再有货比三家的操作了。 作为一名技术人,我们虽然干预不到商家们的交易,但是我们可以摸清这里面所涉及到的”套路”。这里面涉及到了一种价格敏感度模型,也就是我们下面要讲的 PSM(Price Sensitivity Measurement)模型是在70年代由Van Westendrop所创建,其目的在于衡量目标用户对不同价格的满意及接受程度,了解其认为合适的产品价格,从而得到产品价格的可接受范围。PSM的定价是从消费者接受程度的角度来进行的,既考虑了消费者的主观意愿,又兼顾了企业追求最大利益的需求。此外,其价格测试过程完全基于所取购买对象的自然反应,没有涉及到任何竞争对手的信息。虽然缺少竞品信息是PSM的缺陷所在,由于每个网络游戏均自成一个虚拟的社会体系,一般来说,其中每个道具或服务的销售均没有竞品(除非开发组自己开发了类似的道具或服务,产生了内部竞争),从这个角度来说,PSM模型比较适合用于网游中的道具或服务的定价。此外,该模型简洁明了,操作简单,使用非常方便。 第一步:通过定性研究,设计出能够涵盖产品可能的价格区间的价格梯度表。该步骤通常对某一产品或服务追问被访者4个问题,并据此获得价格梯度表。梯度表的价格范围要涵盖所有可能的价格点,最低和最高价格一般要求低于或高出可能的市场价格的三倍以上。 第二步:取一定数量有代表性的样本,被访者在价格梯度表上做出四项选择:有点低但可以接受的价格,太低而不会接受的价格,有点高但可以接受的价格,太高而不会接受的价格。 第三步:对所获得的样本数据绘制累计百分比曲线图,四条曲线的交点得出产品的合适价格区间以及最优定价点和次优定价点。 如下图, 对“便宜”和“太便宜”向下累计百分数(因为价格越低消费者越觉得便宜,即认为某价格便宜的消费者也会认为低于此价格的价格便宜),“贵”和“太贵”向上累计百分数(因为价格越高消费者越觉得贵,即认为某价格贵的消费者也会认为高于此价格的价格贵),能够得到四条累计百分比曲线。 “太便宜”和“贵”的交点意味着此价格能够让最多的人觉得“不会便宜到影响购买意愿,即使可能有点贵也是能够接受的”,“便宜”和“太贵”的交点意味着此价格能够让最多的人觉得“不会贵到不能接受,还是挺划算的”,因此这两个交点分别为价格区间的下限和上限。低于前者,消费者会因为担心“过于大众不能体现优越感,或会给游戏带来不好影响(如游戏平衡性)”而不愿购买;高于后者,消费者会认为价钱太高而不能接受。 一般来说,“太便宜”和“太贵”的交点作为最优价格点,因为在此处觉得“不过于便宜也不过于昂贵”的消费者最多。但是也有人认为“便宜”和“贵”的交点是最优价格,因为该交点取得了“划算,肯定会买”及“贵,但能接受”的平衡点,是能让最多消费者满意的价格。 第一:只考虑到了消费者的接受率,忽视了消费者的购买能力,即只追求最大的目标人群数。但事实上,即使消费者觉得价格合理,受限于购买力等因素,也无法购买。 第二:研究中消费者可能出于各种因素(比如让价格更低能让自己收益,出于面子问题而抬高自己能接受的价格等)有意或无意地抬高或压低其接受的价格。由于消费者知道虚拟世界中的产品(道具或服务)没有成本,其压低价格的可能性较高。 第三:没有考虑价格变化导致的购买意愿(销量)变化。 第一:为了避免购买力的影响, 问卷或访谈研究中要强调“定这个价格,以自己目前的情况是否会购买”,而非仅仅去客观判断该产品值多少钱。 第二:为了解决玩家抬高或压低价格的问题,可以增大样本量,预期随机误差可以相互抵消。 第三:仅仅从曲线获得最优价格,受到玩家压低或抬高价格的影响较大。由于该误差可能是系统误差,对此,可以用所获得的价格区间设计不同的价格方案,然后设计组间实验设计,每个参与研究的消费者只接触其中一种或几种价格方案,并对该价格方案下是否购买及购买数量做出决策,通过计算那种价格方案下玩家消费金钱量最高来分析出最佳价格方案。如下表。 第四:通过前一条中提到的组间实验设计,可以计算出不同价格下玩家购买意愿的变化,从而得知价格调整会对整体收益带来的影响。此外,价格接受比例还可以作为消费者对某价格满意度的指标,用于计算某价格下企业该产品的良性收益。 注意,我们的上述对策部分基于统计学和实验心理学理论,部分基于我们工作中的实践,欢迎大家讨论和优化。 首先我们在web页面,先添加上我们本次需要给用户开发的标签和标签值。 我们如果要实现根据不同的人给出不同的价格,那么如何才能确定用户的价格敏感度( 这里有一个公式: psm = 优惠订单占比 + 平均优惠金额占比 + 优惠总金额占比 是不是刚看有点懵,我们再来细化一下。 优惠订单占比 = 优惠次数/总购买次数 平均优惠金额占比 = 平均优惠金额/平均应收金额 平均优惠金额=优惠总金额/优惠总次数 平均应收金额 = 应收总金额 /订单总次数 优惠总金额占比 = 优惠总金额/应收总金额 优惠次数 前三个数据,我们可以提供统计型函数计算得出, 而 应收总金额= 优惠金额 + 成交金额 这一点我们明确了之后,就可以很好的上手代码了。 算上这次,博主已经是第三次开发挖掘型标签了。所以就不单独把每一步具体实现的业务拿出来慢慢叙述了。更多的细节已经每步实现的效果已经用注释的方式贴在代码中了,有兴趣尝试的朋友,或者想要借鉴结果的朋友可以一睹代码究竟。 代码已经为大家展示完了,如果是有编程功底和大数据基础的朋友,理解起来一定不会感到困难。而看不懂的朋友也不用担心,因为其背后具体的逻辑,博主已经将其说明的很清楚了。如果对代码过程中,有任何疑惑,不明白的地方,欢迎与我联系。 程序运行完了,我们来检验一下结果。 打开我们的Hbase数据库, 大数据是“双刃剑”,要想用好,离不开政府的管控。有业内人士表示,我国适用价格歧视的法律主要有价格法和反垄断法。但是,这两部法律与基于大数据分析的网络时代商业不够匹配。互联网行业很多头部企业,也具有天然垄断性。显然,面对出现的新问题,我们有理由拿出新举措,完善监管方式,并推动形成相应的制度建设。 本篇博客的内容到这里就结束了,对前面两篇挖掘型算法标签开发感兴趣的朋友可以👇 基于RFE模型的挖掘型标签开发 如果以上过程中出现了任何的纰漏错误,烦请大佬们指正😅 受益的朋友或对大数据技术感兴趣的伙伴记得关注支持一波🙏 希望我们都能在学习的道路上越走越远😉
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:https://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!PSM的挖掘型标签开发过程。有意思的是,这个模型牵扯出了一个发生在我们身边,却鲜有人去探讨的问题——大数据杀熟…

PSM模型引入
大数据杀熟

PSM…PSM模型在网游中的运用
PSM模型实施具体步骤


PSM模型的缺陷及解决
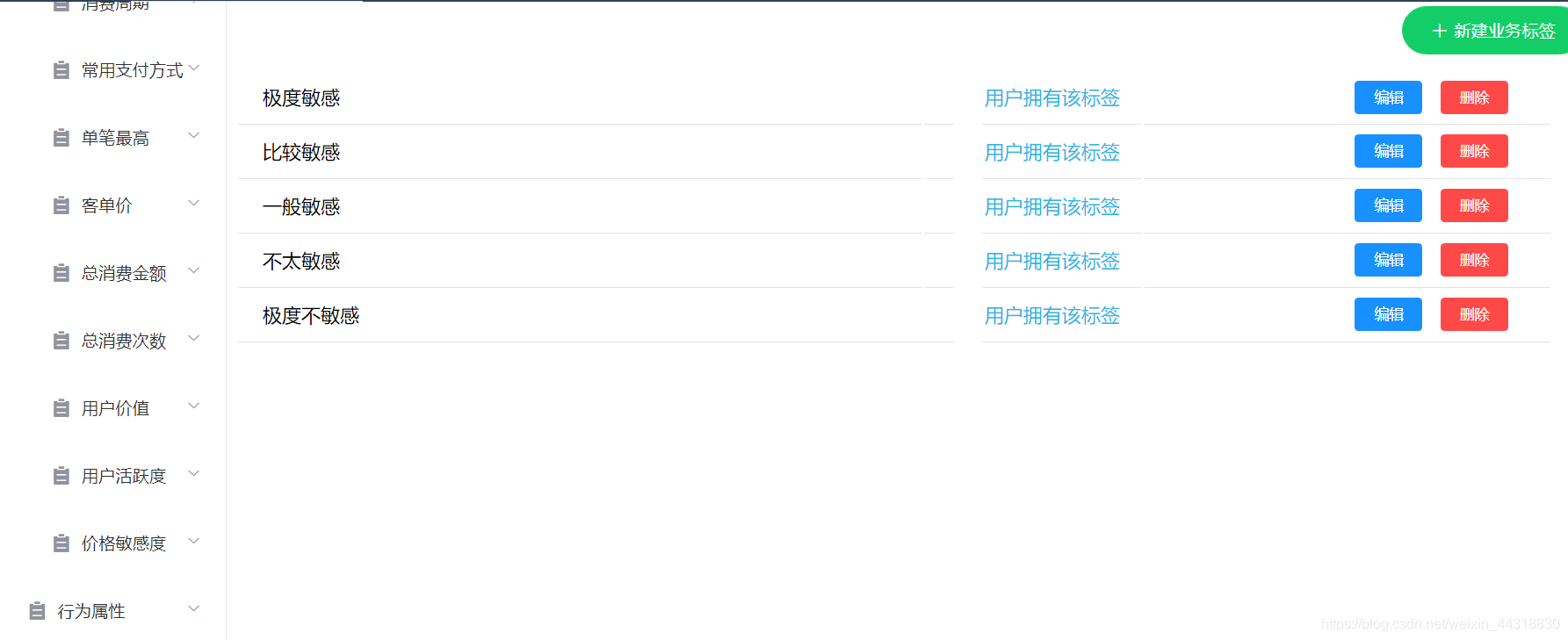
以上都是基于大量理论后得出的结果,下面我们来结合用户画像的项目,来“模拟”商家给不同价格敏感度的用户打上不同标签的过程。用户画像
查看数据库
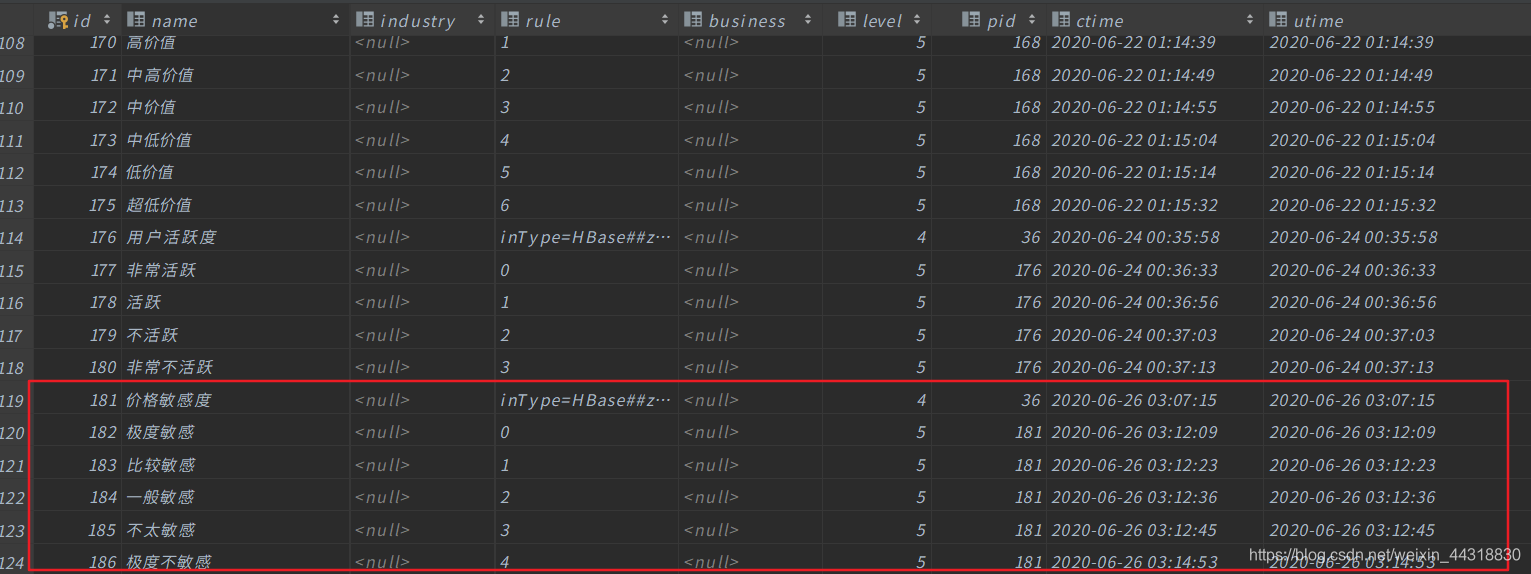
现在有了数据,我们本该就可以直接上手代码了。但为了简便开发,避免重复的步骤,我们先来分析一下业务需求。业务分析
PSM)?

综上所述,我们可以将计算PSM的目标进一步变成计算以下四个数据,只要将它们计算出来,PSM就迎刃而解。
总购买次数
优惠总金额
应收总金额

业务代码
import com.czxy.base.BaseModel import org.apache.spark.ml.clustering.{KMeans, KMeansModel} import org.apache.spark.ml.feature.VectorAssembler import org.apache.spark.sql._ import org.apache.spark.sql.expressions.UserDefinedFunction import scala.collection.immutable /* * @Author: Alice菌 * @Date: 2020/6/26 11:17 * @Description: 基于PSM模型,对用户的价格敏感度进行挖掘 */ object PSMModel extends BaseModel { override def setAppName: String = "PSMModel" override def setFourTagId: String = "181" override def getNewTag(spark: SparkSession, fiveTagDF: DataFrame, hbaseDF: DataFrame): DataFrame = { // 五级标签的数据 fiveTagDF.show() //+---+----+ //| id|rule| //+---+----+ //|182| 1| //|183| 2| //|184| 3| //|185| 4| //|186| 5| //+---+----+ // HBase的数据 hbaseDF.show() //+---------+--------------------+-----------+---------------+ //| memberId| orderSn|orderAmount|couponCodeValue| //+---------+--------------------+-----------+---------------+ //| 13823431|gome_792756751164275| 2479.45| 0.00| //| 4035167|jd_14090106121770839| 2449.00| 0.00| //| 4035291|jd_14090112394810659| 1099.42| 0.00| //| 4035041|amazon_7877495617...| 1999.00| 0.00| // tdonr 优惠订单占比(优惠订单数 / 订单总数) // adar 平均优惠金额占比(平均优惠金额 / 平均每单应收金额) // tdar 优惠金额占比(优惠总金额 / 订单总金额) //psm = 优惠订单占比 + 平均优惠金额占比 + 优惠总金额占比 //只需要求取下面的字段,即可获取到最终的结果 //优惠次数 //总购买次数 //优惠总金额 //应收总金额 = 优惠金额+成交金额 // 引入隐式转换 import spark.implicits._ //引入java 和scala相互转换 import scala.collection.JavaConverters._ //引入sparkSQL的内置函数 import org.apache.spark.sql.functions._ // 优惠次数 var preferentialCount:String = "preferential" // 订单总数 var orderCount:String = "orderCount" // 总优惠金额 var couponCodeValue:String = "couponCodeValue" // 应收总金额 var totalValue:String = "totalValue" // 优惠次数 var getPreferentialCount:Column= count( when(col("couponCodeValue") !== 0.00,1) ) as preferentialCount // 总购买次数 val getOrderCount: Column = count("orderSn") as orderCount // 优惠总金额 var getCouponCodeValue:Column= sum("couponCodeValue") as couponCodeValue // 应收总金额 var getTotalValue: Column = (sum("orderAmount") + sum("couponCodeValue") ) as totalValue // 特征单词 val featureStr: String = "feature" // 向量 val predictStr: String = "predict" // 分类 // 进行查询 val getPSMDF01: DataFrame = hbaseDF.groupBy("memberId") .agg(getPreferentialCount, getOrderCount, getCouponCodeValue,getTotalValue) //展示结果 getPSMDF01.show(5) //+---------+------------+-----------+---------------+------------------+ //| memberId|preferential|orderAmount|couponCodeValue| totalValue| //+---------+------------+-----------+---------------+------------------+ //| 4033473| 3| 142| 500.0|252430.91999999998| //| 13822725| 4| 116| 800.0| 180098.34| //| 13823681| 1| 108| 200.0|169946.09999999998| //|138230919| 3| 125| 600.0|240661.56999999998| //| 13823083| 3| 132| 600.0| 234124.17| //+---------+------------+-----------+---------------+------------------+ // 先设置上我们常用的单词 // 优惠订单占比 var preferentiaOrderlPro:String = "preferentiaOrderlPro" // 平均优惠金额占比 var avgPreferentialPro:String = "avgPreferentialPro" // 优惠金额占比 val preferentialMoneyPro: String = "preferentialMoneyPro" /* 获取到想要的字段结果 */ // 优惠订单占比(优惠订单数 / 订单总数) val getPSMDF02: DataFrame = getPSMDF01.select(col("memberId"),col("preferential") / col("orderCount") as preferentiaOrderlPro, // 平均优惠金额占比(平均优惠金额 / 平均每单应收金额) (col("couponCodeValue") / col("preferential")) / (col("totalValue") / col("orderCount")) as avgPreferentialPro, // 优惠金额占比(优惠总金额 / 订单总金额) col("couponCodeValue") / col("totalValue") as preferentialMoneyPro) getPSMDF02.show() //+---------+--------------------+-------------------+--------------------+ //| memberId|preferentiaOrderlPro| avgPreferentialPro|preferentialMoneyPro| //+---------+--------------------+-------------------+--------------------+ //| 4033473| 0.02112676056338028|0.09375502282631092|0.001980739918865724| //| 13822725|0.034482758620689655| 0.1288185110423561| 0.00444201762215021| //| 13823681|0.009259259259259259|0.12709912142732316|0.001176843716919...| //|138230919| 0.024|0.10388031624658645|0.002493127589918075| //| 13823083|0.022727272727272728|0.11276067737901643|0.002562742667704919| //| 13823431| 0.01639344262295082|0.13461458465166434|0.002206796469699...| //| 4034923|0.009259259259259259|0.12882071966768546|0.001192784441367458| //| 4033575| 0.032|0.07938713328518321|0.002540388265125...| //| 13822841| 0.0| null| 0.0| val getPSMDF03: DataFrame = getPSMDF02.select(col("memberId"),col("preferentiaOrderlPro"),col("avgPreferentialPro"),col("preferentialMoneyPro"),(col("preferentiaOrderlPro")+col("avgPreferentialPro")+col("preferentialMoneyPro")) as "PSM" ).filter('PSM isNotNull) getPSMDF03.show() //+---------+--------------------+-------------------+--------------------+-------------------+ //| memberId|preferentiaOrderlPro| avgPreferentialPro|preferentialMoneyPro| PSM| //+---------+--------------------+-------------------+--------------------+-------------------+ //| 4033473| 0.02112676056338028|0.09375502282631092|0.001980739918865724|0.11686252330855693| //| 13822725|0.034482758620689655| 0.1288185110423561| 0.00444201762215021|0.16774328728519597| //| 13823681|0.009259259259259259|0.12709912142732316|0.001176843716919...|0.13753522440350205| //|138230919| 0.024|0.10388031624658645|0.002493127589918075| 0.1303734438365045| //| 13823083|0.022727272727272728|0.11276067737901643|0.002562742667704919| 0.1380506927739941| // 为了方便K-Means计算,我们将数据转换成向量 val PSMFeature: DataFrame = new VectorAssembler() .setInputCols(Array("PSM")) .setOutputCol(featureStr) .transform(getPSMDF03) PSMFeature.show() //+---------+--------------------+--------------------+--------------------+-------------------+--------------------+ //| memberId|preferentiaOrderlPro| avgPreferentialPro|preferentialMoneyPro| PSM| feature| //+---------+--------------------+--------------------+--------------------+-------------------+--------------------+ //| 4033473| 0.02112676056338028| 0.09375502282631092|0.001980739918865724|0.11686252330855693|[0.11686252330855...| //| 13822725|0.034482758620689655| 0.1288185110423561| 0.00444201762215021|0.16774328728519597|[0.16774328728519...| //| 13823681|0.009259259259259259| 0.12709912142732316|0.001176843716919...|0.13753522440350205|[0.13753522440350...| //|138230919| 0.024| 0.10388031624658645|0.002493127589918075| 0.1303734438365045|[0.1303734438365045]| //| 13823083|0.022727272727272728| 0.11276067737901643|0.002562742667704919| 0.1380506927739941|[0.1380506927739941]| //| 13823431| 0.01639344262295082| 0.13461458465166434|0.002206796469699...|0.15321482374431458|[0.15321482374431...| //| 4034923|0.009259259259259259| 0.12882071966768546|0.001192784441367458|0.13927276336831218|[0.13927276336831...| //| 4033575| 0.032| 0.07938713328518321|0.002540388265125...|0.11392752155030907|[0.11392752155030...| //| 13823153|0.045112781954887216| 0.10559805877421218|0.004763822200340399|0.15547466292943982|[0.15547466292943...| // 利用KMeans算法,进行数据的分类 val KMeansModel: KMeansModel = new KMeans() .setK(5) // 设置4类 .setMaxIter(5) // 迭代计算5次 .setFeaturesCol(featureStr) // 设置特征数据 .setPredictionCol(predictStr) // 计算完毕后的标签结果 .fit(PSMFeature) // 将其转换成DF val KMeansModelDF: DataFrame = KMeansModel.transform(PSMFeature) KMeansModelDF.show() //+---------+--------------------+--------------------+--------------------+-------------------+--------------------+-------+ //| memberId|preferentiaOrderlPro| avgPreferentialPro|preferentialMoneyPro| PSM| feature|predict| //+---------+--------------------+--------------------+--------------------+-------------------+--------------------+-------+ //| 4033473| 0.02112676056338028| 0.09375502282631092|0.001980739918865724|0.11686252330855693|[0.11686252330855...| 4| //| 13822725|0.034482758620689655| 0.1288185110423561| 0.00444201762215021|0.16774328728519597|[0.16774328728519...| 4| //| 13823681|0.009259259259259259| 0.12709912142732316|0.001176843716919...|0.13753522440350205|[0.13753522440350...| 4| //|138230919| 0.024| 0.10388031624658645|0.002493127589918075| 0.1303734438365045|[0.1303734438365045]| 4| //| 13823083|0.022727272727272728| 0.11276067737901643|0.002562742667704919| 0.1380506927739941|[0.1380506927739941]| 4| //| 13823431| 0.01639344262295082| 0.13461458465166434|0.002206796469699...|0.15321482374431458|[0.15321482374431...| 4| //| 4034923|0.009259259259259259| 0.12882071966768546|0.001192784441367458|0.13927276336831218|[0.13927276336831...| 4| //| 4033575| 0.032| 0.07938713328518321|0.002540388265125...|0.11392752155030907|[0.11392752155030...| 4| // 计算用户的价值 val clusterCentersSum: immutable.IndexedSeq[(Int, Double)] = for(i <- KMeansModel.clusterCenters.indices) yield (i,KMeansModel.clusterCenters(i).toArray.sum) val clusterCentersSumSort: immutable.IndexedSeq[(Int, Double)] = clusterCentersSum.sortBy(_._2).reverse clusterCentersSumSort.foreach(println) //(3,0.5563226557645843) //(1,0.31754213552513205) //(2,0.21020766974136296) //(4,0.131618637271183) //(0,0.08361272609460167) // 获取到每种分类以及其对应的索引 val clusterCenterIndex: immutable.IndexedSeq[(Int, Int)] = for(a <- clusterCentersSumSort.indices) yield (clusterCentersSumSort(a)._1,a) clusterCenterIndex.foreach(println) //(3,0) //(1,1) //(2,2) //(4,3) //(0,4) // 类别的价值从高到低,角标依次展示 // 将其转换成DF val clusterCenterIndexDF: DataFrame = clusterCenterIndex.toDF(predictStr,"index") clusterCenterIndexDF.show() //+-------+-----+ //|predict|index| //+-------+-----+ //| 3| 0| //| 1| 1| //| 2| 2| //| 4| 3| //| 0| 4| //+-------+-----+ val JoinDF: DataFrame = fiveTagDF.join(clusterCenterIndexDF,fiveTagDF.col("rule") === clusterCenterIndexDF.col("index")) JoinDF.show() //+---+----+-------+-----+ //| id|rule|predict|index| //+---+----+-------+-----+ //|182| 0| 3| 0| //|183| 1| 1| 1| //|184| 2| 2| 2| //|185| 3| 4| 3| //|186| 4| 0| 4| //+---+----+-------+-----+ val JoinDFS: DataFrame = JoinDF.select(predictStr,"id") //fiveTageList val fiveTageMap: Map[String, String] = JoinDFS.as[(String,String)].collect().toMap // 获得数据标签(udf) // 需要自定义UDF函数 val getRFMTags: UserDefinedFunction = udf((featureOut: String) => { fiveTageMap.get(featureOut) }) val PriceSensitiveTag: DataFrame = KMeansModelDF.select('memberId .as("userId"),getRFMTags('predict).as("tagsId")) PriceSensitiveTag.show() //+---------+------+ //| userId|tagsId| //+---------+------+ //| 4033473| 185| //| 13822725| 185| //| 13823681| 185| //|138230919| 185| PriceSensitiveTag } def main(args: Array[String]): Unit = { exec() } } 
检验成功
scan "test",{LIMIT => 10}查看我们存放用户标签信息的test数据库中的10条信息。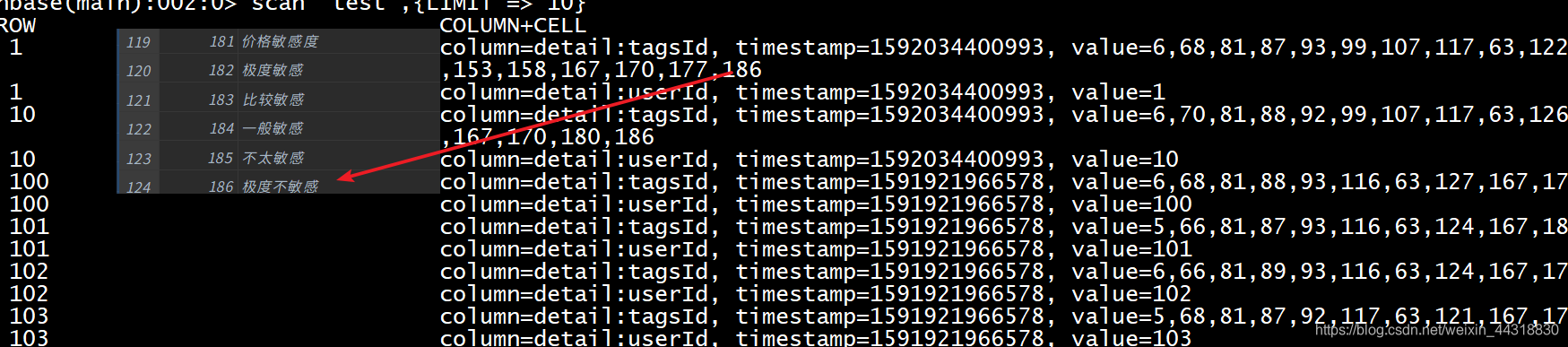
我们可以看到,已成功将用户的价格敏感度标签打入到了标签系统的数据库。换做实际企业的业务场景中,要对不同的用户采用不同的价格策略就可以从这里”下手”…

结语
基于RFM模型的挖掘型标签开发

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 859
859