Apache Spark的出现让普通人也具备了大数据及实时数据分析能力。鉴于此,本文通过动手实战操作演示带领大家快速地入门学习Spark。本文是Apache Spark入门系列教程(共四部分)的第一部分。 全文共包括四个部分:
本篇讲解的便是第一部分
关于全部摘要和提纲部分,请登录我们的网站 Apache Spark QuickStart for real-time data-analytics进行访问。
在网站上你可以找到更多这方面的文章和教程,例如: Java Reactive Microservice Training, Microservices Architecture | Consul Service Discovery and Health For Microservices Architecture Tutorial。还有更多的其它内容,感兴趣的可以去查看。
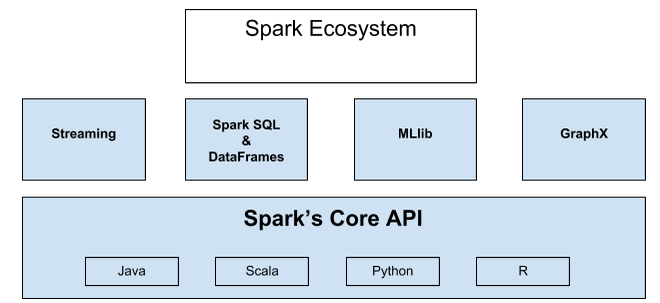
Apache Spark是一个正在快速成长的开源集群计算系统,正在快速的成长。Apache Spark生态系统中的包和框架日益丰富,使得Spark能够进行高级数据分析。Apache Spark的快速成功得益于它的强大功能和易于使用性。相比于传统的MapReduce大数据分析,Spark效率更高、运行时速度更快。Apache Spark 提供了内存中的分布式计算能力,具有Java、 Scala、Python、R四种编程语言的API编程接口。Spark生态系统如下图所示:

整个生态系统构建在Spark内核引擎之上,内核使得Spark具备快速的内存计算能力,也使得其API支持Java、Scala,、Python、R四种编程语言。Streaming具备实时流数据的处理能力。Spark SQL使得用户使用他们最擅长的语言查询结构化数据,DataFrame位于Spark SQL的核心,DataFrame将数据保存为行的集合,对应行中的各列都被命名,通过使用DataFrame,可以非常方便地查询、绘制和过滤数据。MLlib为Spark中的机器学习框架。Graphx为图计算框架,提供结构化数据的图计算能力。以上便是整个生态系统的概况。

大家对Apache Spark如此感兴趣的原因是它使得普通的开发具备Hadoop的数据处理能力。较之于Hadoop,Spark的集群配置比Hadoop集群的配置更简单,运行速度更快且更容易编程。Spark使得大多数的开发人员具备了大数据和实时数据分析能力。鉴于此,鉴于此,本文通过动手实战操作演示带领大家快速地入门学习Apache Spark。
动手实验Apache Spark的最好方式是使用交互式Shell命令行,Spark目前有Python Shell和Scala Shell两种交互式命令行。
可以从 这里下载Apache Spark,下载时选择最近预编译好的版本以便能够立即运行shell。
目前最新的Apache Spark版本是1.5.0,发布时间是2015年9月9日。
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
cd spark-1.5.0-bin-hadoop2.4 ./bin/pyspark
在本节中不会使用Python Shell进行演示。
Scala交互式命令行由于运行在JVM上,能够使用java库。
cd spark-1.5.0-bin-hadoop2.4 ./bin/spark-shell
执行完上述命令行,你可以看到下列输出:
Welcome to ____ __ / __/__ ___ _____/ /__ _/ // _ // _ `/ __/ '_/ /___/ .__//_,_/_/ /_//_/ version 1.5.0 /_/ Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_25) Type in expressions to have them evaluated. Type :help for more information. 15/08/24 21:58:29 INFO SparkContext: Running Spark version 1.5.0
下面是一些简单的练习以便帮助使用shell。也许你现在不能理解我们做的是什么,但在后面我们会对此进行详细分析。在Scala Shell中,执行下列操作:
val textFile = sc.textFile("README.md")
textFile.first() res3: String = # Apache Spark
对textFile RDD中的数据进行过滤操作,返回所有包含“Spark”关键字的行,操作完成后会返回一个新的RDD,操作完成后可以对返回的RDD的行进行计数
筛选出包括Spark关键字的RDD然后进行行计数
val linesWithSpark = textFile.filter(line => line.contains("Spark")) linesWithSpark.count() res10: Long = 19
要找出RDD linesWithSpark单词出现最多的行,可以使用下列操作。使用map方法,将RDD中的各行映射成一个数,然后再使用reduce方法找出包含单词数最多的行。
找出RDD textFile 中包含单词数最多的行
textFile.map(line => line.split(" ").size) .reduce((a, b) => if (a > b) a else b) res11: Int = 14
返回结果表明第14行单词数最多。
也可以引入其它java包,例如 Math.max()方法,因为map和reduce方法接受scala函数字面量作为参数。
在scala shell中引入Java方法
import java.lang.Math textFile.map(line => line.split(" ").size) .reduce((a, b) => Math.max(a, b)) res12: Int = 14
我们可以很容易地将数据缓存到内存当中。
将RDD linesWithSpark 缓存,然后进行行计数
linesWithSpark.cache() res13: linesWithSpark.type = MapPartitionsRDD[8] at filter at <console>:23 linesWithSpark.count() res15: Long = 19
上面简要地给大家演示的了如何使用Spark交互式命令行。
Spark在集群中可以并行地执行任务,并行度由Spark中的主要组件之一——RDD决定。弹性分布式数据集(Resilient distributed data, RDD)是一种数据表示方式,RDD中的数据被分区存储在集群中(碎片化的数据存储方式),正是由于数据的分区存储使得任务可以并行执行。分区数量越多,并行越高。下图给出了RDD的表示:

想像每列均为一个分区(partition ),你可以非常方便地将分区数据分配给集群中的各个节点。
为创建RDD,可以从外部存储中读取数据,例如从Cassandra、Amazon简单存储服务(Amazon Simple Storage Service)、HDFS或其它Hadoop支持的输入数据格式中读取。也可以通过读取文件、数组或JSON格式的数据来创建RDD。另一方面,如果对于应用来说,数据是本地化的,此时你仅需要使用parallelize方法便可以将Spark的特性作用于相应数据,并通过Apache Spark集群对数据进行并行化分析。为验证这一点,我们使用Scala Spark Shell进行演示:
通过单词列表集合创建RDD thingsRDD
cd spark-1.5.0-bin-hadoop2.4 ./bin/pyspark
0计算RDD thingsRDD 中单的个数
cd spark-1.5.0-bin-hadoop2.4 ./bin/pyspark
1运行Spark时,需要创建Spark Context。使用Spark Shell交互式命令行时,Spark Context会自动创建。当调用Spark Context 对象的parallelize 方法后,我们会得到一个经过分区的RDD,这些数据将被分发到集群的各个节点上。
对RDD,既可以进行数据转换,也可以对进行action操作。这意味着使用transformation可以改变数据格式、进行数据查询或数据过滤操作等,使用action操作,可以触发数据的改变、抽取数据、收集数据甚至进行计数。
例如,我们可以使用Spark中的文本文件README.md创建一个RDD textFile,文件中包含了若干文本行,将该文本文件读入RDD textFile时,其中的文本行数据将被分区以便能够分发到集群中并被并行化操作。
根据README.md文件创建RDD textFile
cd spark-1.5.0-bin-hadoop2.4 ./bin/pyspark
2行计数
cd spark-1.5.0-bin-hadoop2.4 ./bin/pyspark
3
README.md 文件中有98行数据。
得到的结果如下图所示:

然后,我们可以将所有包含Spark关键字的行筛选出来,完成操作后会生成一个新的RDDlinesWithSpark:
创建一个过滤后的RDD linesWithSpark
cd spark-1.5.0-bin-hadoop2.4 ./bin/pyspark
4
在前一幅图中,我们给出了 textFile RDD的表示,下面的图为RDD linesWithSpark的表示:

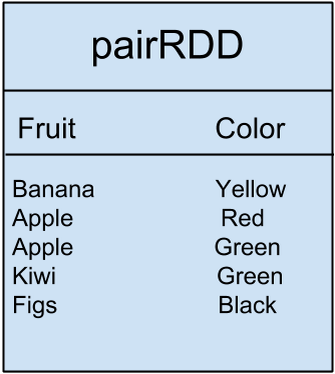
值得注意的是,Spark还存在键值对RDD(Pair RDD),这种RDD的数据格式为键/值对数据(key/value paired data)。例如下表中的数据,它表示水果与颜色的对应关系:

对表中的数据使用groupByKey()转换操作将得到下列结果:
groupByKey() 转换操作
cd spark-1.5.0-bin-hadoop2.4 ./bin/pyspark
5
该转换操作只将键为Apple,值为Red和Green的数据进行了分组。这些是到目前为止给出的转换操作例子。
当得到一个经过过滤操作后的RDD,可以collect/materialize相应的数据并使其流向应用程序,这是action操作的例子。经过此操作后, RDD中所有数据将消失,但我们仍然可以在RDD的数据上进行某些操作,因为它们仍然在内存当中。
Collect 或 materializelinesWithSpark RDD中的数据
cd spark-1.5.0-bin-hadoop2.4 ./bin/pyspark
6
值得一提的是每次进行Spark action操作时,例如count() action操作,Spark将重新启动所有的转换操作,计算将运行到最后一个转换操作,然后count操作返回计算结果,这种运行方式速度会较慢。为解决该问题和提高程序运行速度,可以将RDD的数据缓存到内存当中,这种方式的话,当你反复运行action操作时,能够避免每次计算都从头开始,直接从缓存到内存中的RDD得到相应的结果。
缓存RDDlinesWithSpark
cd spark-1.5.0-bin-hadoop2.4 ./bin/pyspark
7
如果你想将RDD linesWithSpark从缓存中清除,可以使用unpersist()方法。
cd spark-1.5.0-bin-hadoop2.4 ./bin/pyspark
8
如果不手动删除的话,在内存空间紧张的情况下,Spark会采用最近最久未使用(least recently used logic,LRU)调度算法删除缓存在内存中最久的RDD。
下面总结一下Spark从开始到结果的运行过程:
下面给出的是RDD的部分转换操作清单:
下面给出的是RDD的部分action操作清单:
关于RDD所有的操作清单和描述,可以参考 Spark documentation
本文介绍了Apache Spark,一个正在快速成长、开源的集群计算系统。我们给大家展示了部分能够进行高级数据分析的Apache Spark库和框架。对 Apache Spark为什么会如此成功的原因进行了简要分析,具体表现为 Apache Spark的强大功能和易用性。给大家演示了 Apache Spark提供的内存、分布式计算环境,并演示了其易用性及易掌握性。
在本系列教程的第二部分,我们对Spark进行更深入的介绍。
相关链接:
原文地址: Introduction to Big Data Analytics w/ Apache Spark Pt. 1(译者/牛亚真 审校/朱正贵 责编/仲浩)
译者简介:牛亚真,本科,2010年毕业于西南大学计算机与信息科学学院信息管理与信息系统专业;研究生,2013年毕业于中国科学院大学文献情报中心情报学专业,计算机信息处理与检索方向。
第九届中国大数据技术大会将于2015年12月10-12日在北京隆重举办。在主会之外,会议还设立了16大分论坛,包含数据库、深度学习、推荐系统、安全等6大技术论坛,金融、制造业、交通旅游、互联网、医疗健康、教育等7大应用论坛和3大热点议题论坛,票价折扣中预购从速。
本文为ImapBox编译整理,未经允许不得转载,如需转载请联系market#csdn.net(#换成@)
本网页所有文字内容由 imapbox邮箱云存储,邮箱网盘, iurlBox网页地址收藏管理器 下载并得到。
ImapBox 邮箱网盘 工具地址: https://www.imapbox.com/download/ImapBox.5.5.1_Build20141205_CHS_Bit32.exe
PC6下载站地址:PC6下载站分流下载
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox 网页视频 工具地址: https://www.imapbox.com/download/ImovieBox4.7.0_Build20141115_CHS.exe
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}