arpa库是用于读取arpa数据文件的python包,由于涉及领域很小,截至本文发布,笔者尚未搜索到有关详尽的教程,因此初次接触arpa数据文件后,没有意识到数据格式问题,单纯通过统计分析得到了一些规律特征,希望能转为常见的csv格式数据文件方便使用,直到发现该包后解析源码得到了简洁的用法,供遇到同样问题朋友以参考。 arpa数据文件是典型的用于存储n-grams模型参数的文件,比较容易获得的由English Gigaword语料库训练得到的n-grams模型可以从中获得https://www.keithv.com/software/giga/(链接中提供了12种不同参数组合下的预训练模型) 其形式大致如下所示(以3-grams为最高阶的arpa文件示例)👇 如下示例: 数据的每一行的数据一般通过制表符 t 分隔,低阶数据部分(3-grams为最高阶的情况下,1-grams与2-grams即为低阶数据部分)每行有三个元素,左边的是该短语出现的概率,右边为该短语的 backoff 概率(具体解释可以参考下文相关公式),中间则为短语(即一元短语或二元短语);最高阶数据部分每行只有两个元素,即缺少一个 backoff 概率。注意文件中记录的概率都是实际概率的常用对数值(10为底); 简单验证可以发现一阶数据1-grams部分所有概率值之和为1,二阶数据与三阶数据由于本身省略了(或是训练时并没有出现过)一些短语(如截图中1-grams有5000条,由此可以算出2-grams数据应当有25000000条,实际上截图中只有3107927条),因此每个组的概率和都普遍小于1,不过也无妨,大部分情况下n-grams模型是比较概率大小而概率值本身并无太大意义,直接使用即可。 以最高阶为3-grams的短语(wd1,wd2,wd3)概率计算为例: 即如果3-grams数据部分出现了(wd1,wd2,wd3),则直接使用它的概率即可;如果数据中没有出现过(wd1,wd2,wd3)这个短语的话,但是找到了(wd1,wd2)这个短语,以(wd1,wd2)的 backoff 概率乘以短语(wd2,wd3)的概率即可;若都找不到就以的(wd2,wd3)概率作为(wd1,wd2,wd3)的概率处理。 至于降到2-grams的情况后,仍然类比3-grams的情况,如果找不到该二元短语,就用第一个单词的 backoff 概率和第二个单词的概率相乘即可。 依次可以类推到更高阶的 arpa 数据使用,数据每增加一阶,数据规模都会增加几百乃至上千上万倍。 当然这些都不太重要,协助理解,代码使用上并不会用到这么复杂的公式。 安装arpa库直接使用常规命令即可,包很小,很快,源码也便于阅读。 阅读源码可以发现arpa库主要用于导入、编辑、导出arpa文件及计算短语及语句的概率。笔者主要就后者做阐述。 首先类似常见的json库以及pickle库,arpa库提供了三种读取文件的方式👇 其参数分别为文件,文件路径,文件字符串内容👆 读取得到的变量a是一个list,里面包含了得到的模型,一般来说一个文件只有一个模型,所以这个list 的长度为1👇 模型的属性了解即可,如下所示👇 重点是对短语概率的预测和语句概率的预测,源码中封装了五种方法👇 事实上arpa数据文件的读取相当耗时,链接中包含的12个数据文件,最小的lm_giga_5k_nvp_2gram.arpa仅73M就需要20秒读入,最大的lm_giga_64k_vp_3gram.apra则需要10分钟才能完成载入846M的数据文件,这个速度远远超过同规模的csv数据文件大小。笔者试着将读入的模型变量以pickle形式保存到外部文件,以节约读入处理时间,但是这个变量的大小普遍是文件大小的6倍以上,实在过于夸张。不过好在预测时速度很快,瓶颈只是在内存上。 简单测试就可以发现通顺的语句概率确实要远大于不通顺的语句概率,笔者在GEC模型中将其作为后处理部分微调使用,在模型输出编辑操作后,对于存在多元选择的编辑操作可以使用n-grams模型进行投票选择,以确保校正的精确性。
arpa 数据文件格式
data ngram 1=<1-gram总数量> ngram 1=<2-gram总数量> ngram 1=<3-gram总数量> 1-grams: ... ... 2-grams: ... ... 3-grams: ... ... end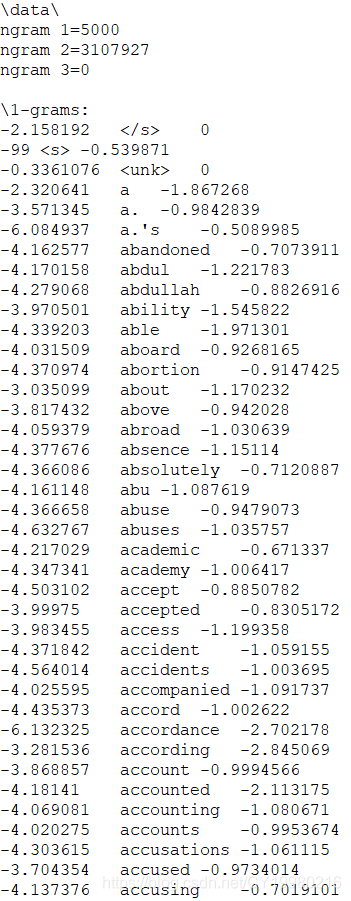
arpa 数据使用方式
p(wd3|wd1,wd2)= if(trigram exists) p_3(wd1,wd2,wd3) else if(bigram w1,w2 exists) bo_wt_2(w1,w2)*p(wd3|wd2) else p(wd3|w2) p(wd2|wd1)= if(bigram exists) p_2(wd1,wd2) else bo_wt_1(wd1)*p_1(wd2)arpa 数据代码操作
pip install arpa
import arpa # 读取arpa数据文件 a = arpa.load(open(arpapath,"r")) a = arpa.loadf(arpapath) a = arpa.loads(arpastring)
import arpa # 获取模型 model = a[0]
# 模型属性 model.vocabulary() # 词汇表, 即1-grams部分的所有短语(单词) model.counts() # 各阶数据部分的规模, 如数据文件头部所示 model.order() # arpa数据的最高阶
# 模型预测 model.log_p("he is") # 短语概率(对数值) model.log_p_raw("he is") # 原始的短语概率(一般不用,可以理解为绝对概率) model.log_s("I love you .") # 语句概率(对数值) model.p("he is") # 短语概率(实际值) model.s("I love you .") # 语句概率(实际值)
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)
