1.需求:经验+3 2.分析:封号机制是什么? 3.当弹出验证码框时如何操作? 关于键盘输入:如果要控制其他程序,建议把opt.headless改为True,光标在哪就在哪敲字 1.大量水贴有风险
背景:
1.需求分析:
2.源码展示:
from lxml import etree from selenium import webdriver import time import random from pynput.keyboard import Controller chrome_driver=r"C:Program Files (x86)GoogleChromechromedriver.exe" header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36"} count_num = 0 count_page = 0 host = "https://tieba.baidu.com" reply_list = [ "经验加三!", "哈哈,不懂", "卧槽!牛批", "我过去就是一个滑稽#(滑稽)", "/手动滑稽#(滑稽)", "#(滑稽)","#(滑稽)", "秀我那瓜子了哈哈", "哈哈", "不懂撒", "这是什么","gkd", "???", "不知道说什么#(滑稽)", "你知道的,我只想水一波经验#(滑稽)", "经验加三,告辞!!#(滑稽)", "#(滑稽)" ] keyboard = Controller() # 控制键对象 opt = webdriver.ChromeOptions() opt.headless = False # 是否隐藏浏览器 True为隐藏 browser = webdriver.Chrome(executable_path=chrome_driver, options=opt) def browser_of(host_idx, idx): global host global count_num global reply_list print("本章:"+ host_idx, end=" --- ") browser.get(host_idx) re = browser.page_source html = etree.HTML(re) urls = html.xpath('//div[@class="threadlist_title pull_left j_th_tit "]/a/@href') time.sleep(5) # 给扫描时间 print("扫描有{}个贴,准备开始水!".format(len(urls))) j = 0 for url in urls: url = host + url print(url) browser.get(url) try: browser.find_element_by_id("ueditor_replace").click() # 鼠标点击 time.sleep(2) input_box = browser.find_element_by_id("ueditor_replace") list_len = len(reply_list) ran_idx = random.randint(0, list_len) if opt.headless: # 判断浏览器是否显示状态,显示就逐个打印 time.sleep(4) input_box.send_keys(reply_list[ran_idx] + "经验+3!") time.sleep(4) else: input_box.send_keys(reply_list[ran_idx]) # ---------------每句后面增加经典回复------------------ keyboard.press("e") time.sleep(1) keyboard.press("x") time.sleep(1) keyboard.press("p") time.sleep(1) keyboard.press("e") time.sleep(1) keyboard.press("r") time.sleep(1) keyboard.press("i") time.sleep(1) keyboard.press("e") time.sleep(1) keyboard.press("n") time.sleep(1) keyboard.press("c") time.sleep(1) keyboard.press("e") #----------------------------------------- j += 1 count_num += 1 print('{0} - 第{1}页 第{2}条 回复成功:经验+3!'.format(count_num, idx, j)) browser.find_element_by_css_selector(".ui_btn.ui_btn_m.j_submit.poster_submit").click() except Exception as e: print(e) print('fail') time.sleep(10) return True def get_to_next_page(host_idx): global count_page count_page += 1 print("本页为 = "+host_idx) browser.get(host_idx) re = browser.page_source # 获取网页源码 html = etree.HTML(re) next_url = html.xpath('//div[@id="frs_list_pager"]/a/@href')[-2] # 获取下一页链接 print("下一页 = "+next_url) # "file://tieba.baidu.com/f?kw=%E6%BB%91%E7%A8%BD&ie=utf-8&pn=50" if browser_of(host_idx, count_page): # 执行完成 get_to_next_page("https:" + next_url) browser.close() if __name__ == '__main__': host_idx = "https://tieba.baidu.com/f?kw=%E6%BB%91%E7%A8%BD&ie=utf-8&pn=0" # 放置贴吧内第一页url get_to_next_page(host_idx) 3.源码说明:
把opt.headless改为True又扫描登录不到,哈哈,可以自行查找selenium 保存账号和密码的操作4.运行结果:
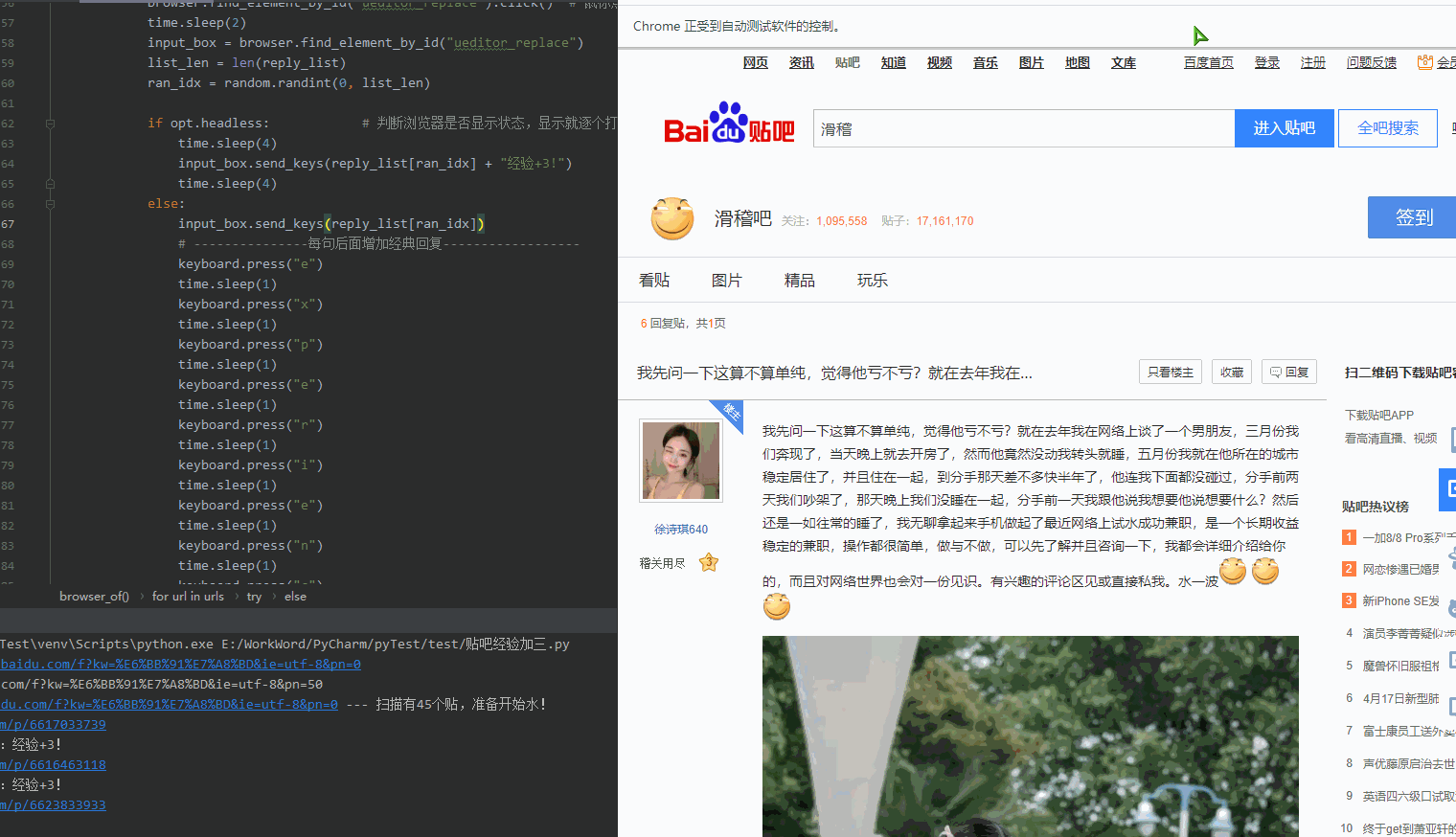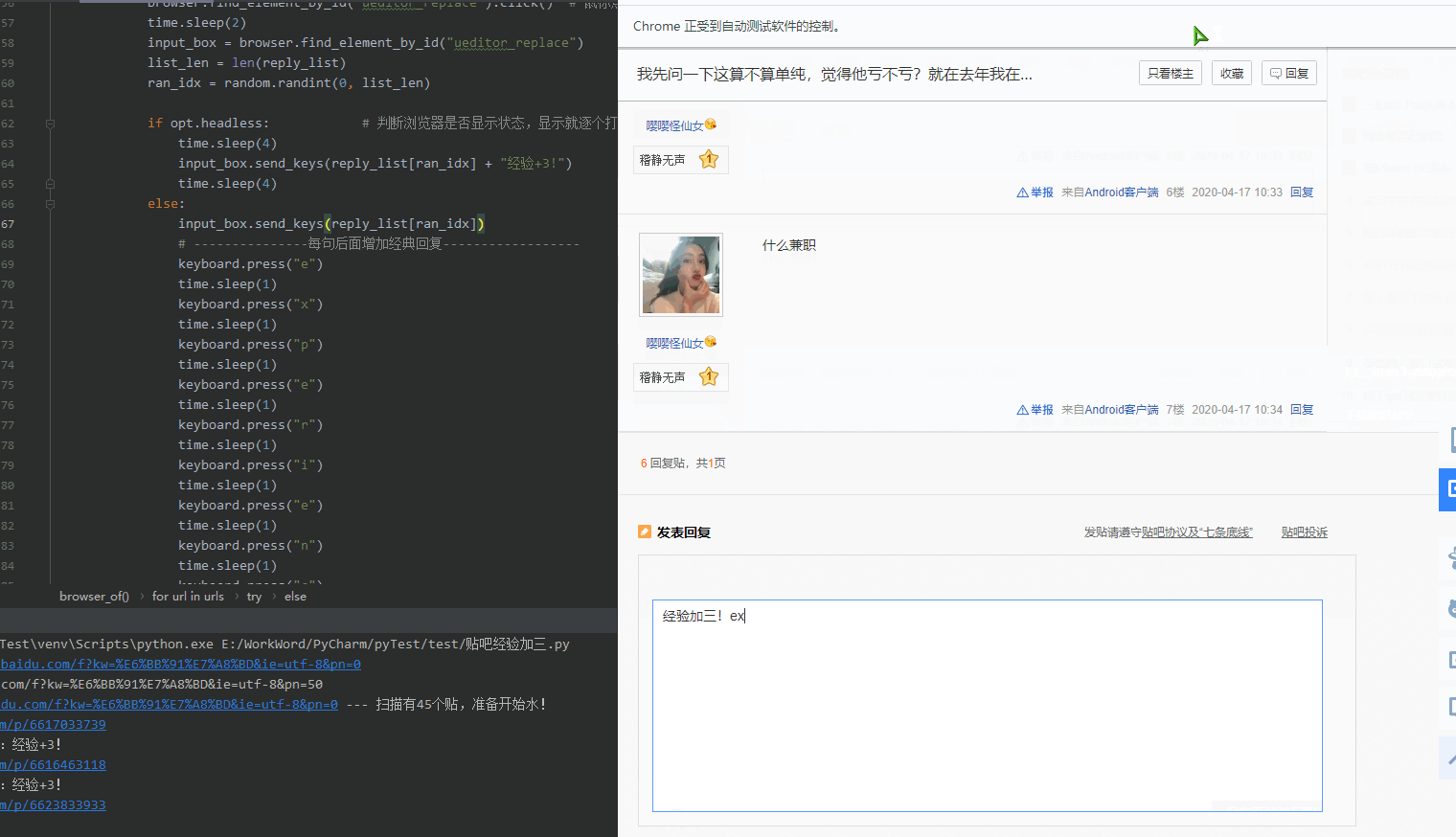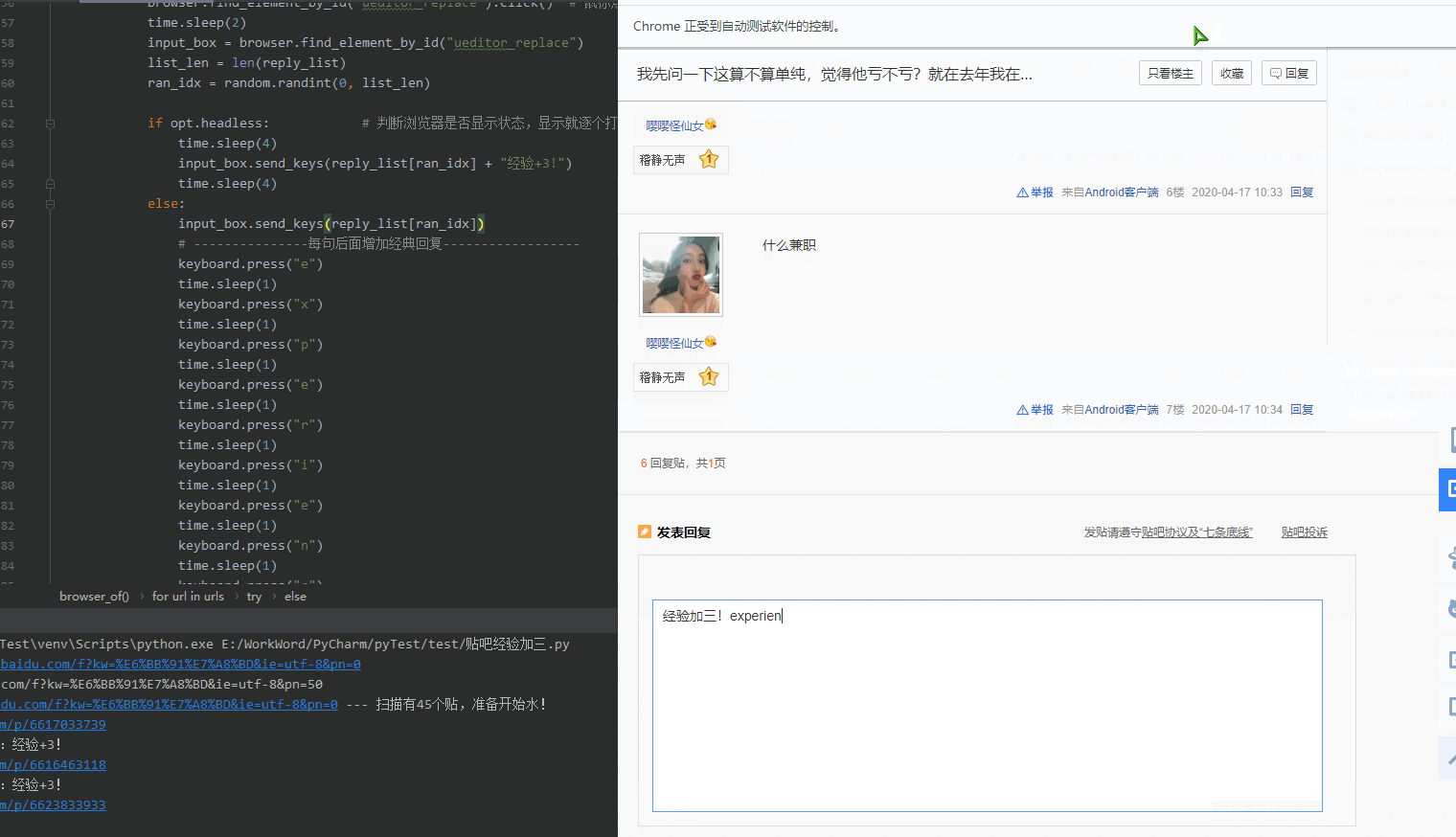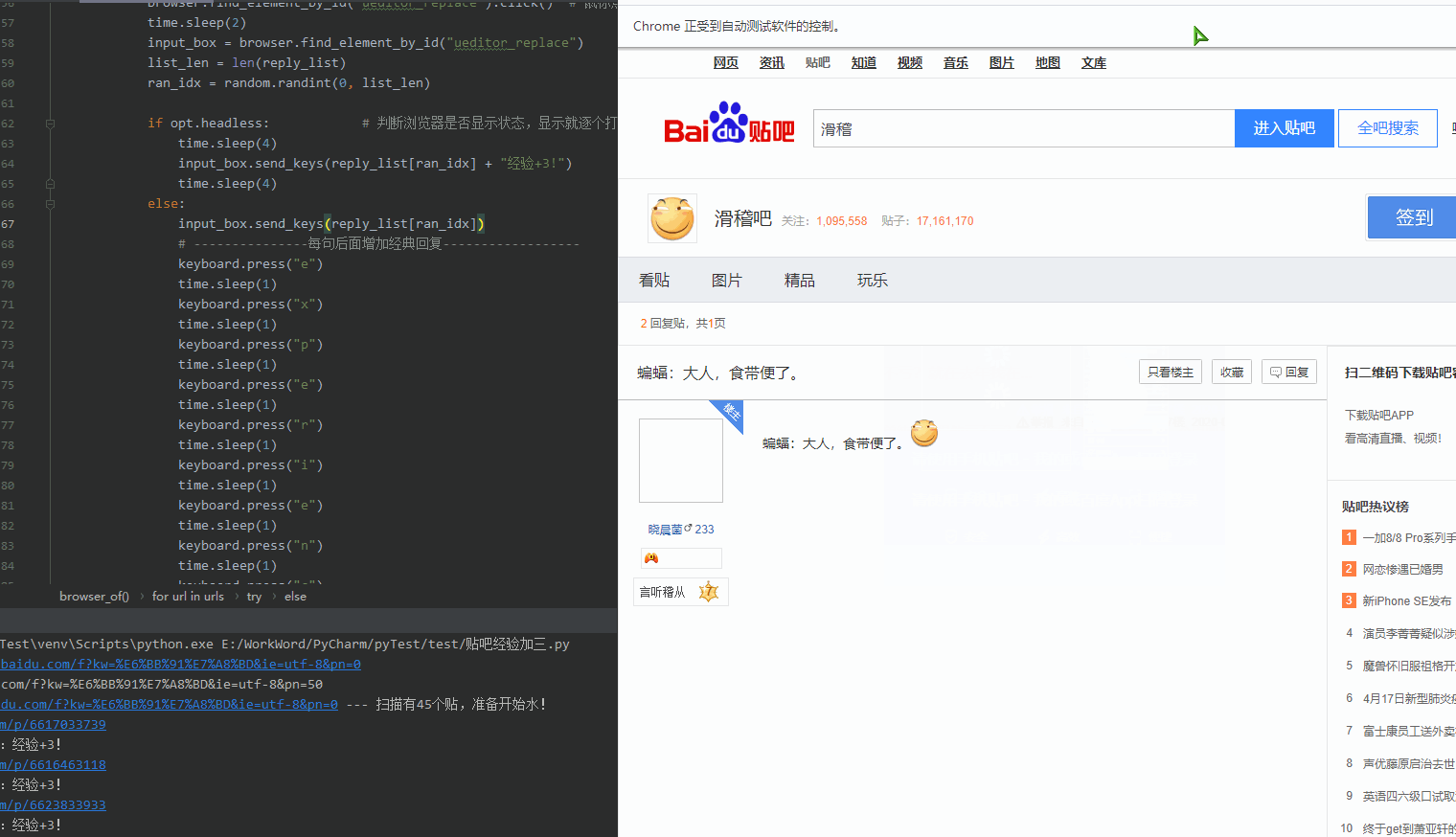
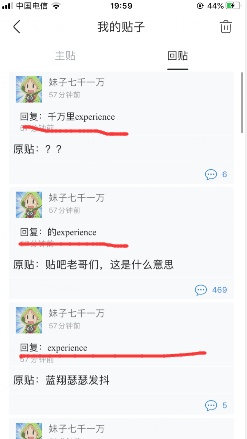
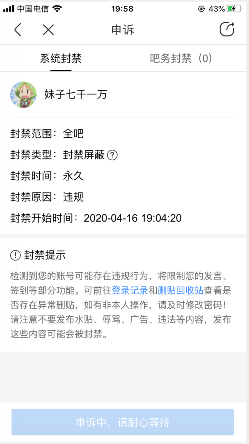
5.关于:
2.记得要登录沃
3.转载请说明出处!!!
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)

