1.深度学习发展迅猛的原因 (1)数据规模的加大,比较著名的就是imageNet (2)算力:GPU+深度学习芯片使计算机算力大大的提高,使得我们搭建深的网络结构提供了可能 (3)算法:在分类,检测,分割等领域深度学习取得了非常大的进展 2.常见的深度学习模型 (1)卷积神经网(CNN):解决图像,语音数据 (2)循环神经网(RNN):解决序列上的任务,文本数据 (3)自动编码机(Autoencoder) (4)Restricted Boltzmann Machines(RBM,受限波尔兹曼机) (5)深度信念网络(DBN,Deep Belief Network) 3.什么是卷积神经网 以卷积结构为主,搭建起来的深度网络 .将图片作为网络的输入(图片一般为[n,h,w,c]的数据矩阵),自动提取特征(参数优化的过程,前向运算的结果可以认为是一个特征向量,这个向量是多维的),并且对图片的变形(如平移,比例缩放,倾斜)等具有高度不变性(对人脸图片缩放旋转经过网络依然判断为人脸,这组参数也是我们需要学到的参数)。 上图是一副 卷积神经网络的结构图,输入是一副车辆图像,目的是对这张图像进行分类,分类之前我们会经过一个卷积神经网,通过卷积神经网进行特征提取,最终的输出为预测的结果,这里是一个五维的向量,我们可以将这五维的向量作为当前这辆车的特征向量,是这辆车在这五个类别的概率,图像属于概率值最高的类别,这样我们就完成了对这辆车的分类。 4.卷积神经网的重要组成单元 (1)卷积层 卷积:对图像和滤波矩阵做内积(逐个元素相乘再求和)的操作,滤波矩阵我们称为卷积核,我们可以将卷积理解为滤波器,我们可以通过滤波器对图像进行降噪,去掉高频信息,保留低频信息或者去掉低频信息,保留高频信息等。在图像降噪中,我们可以采用均值滤波器来去掉图像中的一些噪声,这里我们定义一个[1/3,1/3,1/3]这样的均值滤波器,对图像从左到右,从上到下进行扫描,扫描时我们每次从图像上取1*3同滤波器大小一样的窗口,我们用这个窗口与我们的滤波器做内积操作,实际上就是对窗口的像素点求均值,同样的,我们也可以用滤波器边缘提取,比如我们想要提取图像在水平方向上的梯度(水平方向上的纹理),如何进行图像梯度的运算,实际上就是对图像数据进行差分。不同的卷积核参数就意为着我们在利用卷积对图像进行运算的时候,我们就会提取出不同的特征,也就是说每一种卷积对应一种特征。 当我们步长为1时,会发现得出的特征图与原图大小不一致,当窗口滑动是不会超出原图的边界,所以得出的特征图会比原图小,如果想让特征图和原图大小保持一致,我们可以再原图上下左右都补一行0(zero padding),补0比原来没有添0 的情况下进行卷积,从左到右,从上到下都多赚了2次卷积,这样卷积层输出的特征图(feature map)仍然和输入图片的大小一致。好处:我们可以得到更多的特征信息,也可以控制卷积层输出的特征图的大小。在实际运算时,我们会将图像转化成矢量运算,直接通过矩阵相乘得到卷积结果。 (2)卷积中重要参数 .卷积核:最常用为2D卷积核(w*h),w*h所对应的是权值项,另外我们还有一个偏置项,常用卷积核:1*1,3*3,5*5,7*7。奇数的卷积核有中心点,可以找到与原始图像对应的点即保护位置信息。 .权值共享与局部连接:卷积运算作用在局部,局部区域我们理解为局部感受野,当我们的卷积核大小为3*3,那我们局部感受野就为3*3,feature map使用同一个卷积核运算后得到一种特征,每一个局部区域所对应的卷积核的参数的权值是相同的(权值共享),多种特征采用多个卷积核。具体是多少种卷积核,取决于num out(即输出的通道数量)。输入层和输出层是局部连接。全连接是隐藏层的点与输出层的节点都有连接关系的。局部连接降低了参数量。采用权值共享,我们的参数量只与卷积核相关。参数量越少,意味着我们的模型不容易过拟合。 .感受野:卷积核的大小就对应着感受野的大小,卷积核越大,包含的信息就越多,可能学到的信息就越多,但不意味着卷积核越大,最终的结果不一定好,因为卷积核越大,参数量越大,计算量越大。采用小的卷积核实现大的感受野:卷积核堆加。2个3*3对应1个5*5,3个3*3对应一个7*7。对于n*n的图像,采用3*3的卷积核,输出的图像为(n-2)*(n-2).采用5*5的卷积核,输出的图像为(n-4)*(n-4)。好处参数量降低了。通过网络加深,我们在层与层之间,插入一些非线性的层,使我们网络非线性的表达能力更加的强,我们网络在描述一个事物的表达能力更强。 .如何计算卷积参数量:(k_w*k_h*in_channel+1)*out_channel。(k_w*k_h:卷积核的大小,in_channel:输入层的通道数,1:偏置项) .如何计算卷积的计算量(算法的效率):In_w*In_h*(k_w*k_h*in_channel+1)*out_channel .步长(stride):采样的间隔,即卷积核移动的格子,设置不同的步长,输出的feature map的大小不同,输出的大小:(N-F)/stride+1(F为卷积核大小),步长与参数量无关,但对计算量会变化。输出的特征图大小越小,计算量就越小。 .pad:对特征图的周围进行填充,确保feature map整数倍变化,对尺度相关的任务尤为重要。例如:F=3->zero pad with1;f=5->zero pad with 2;F=7->zero pad with 3;参数量不变,计算量增加。 (3)卷积的定义和使用(tensorflow) 采用tf.nn.conv2d(),我们需要自己定义权值项和偏置项(内容和shape)以及初始化的方法,在使用卷积的时候,我们将输入的数据,卷积核的参数,strides和padding的参数作为参数,得到的结果单独的和偏置项相加。 采用slim.conv2d定义卷积层会更加的方便,参数是输入的数据,输出的通道的数量,卷积核的大小。 (4)池化:对输入的特征图进行压缩,使特征图变小,简化网络计算复杂度,进行特征压缩,提取主要特征,增大感受野。有两种方式:Max pooling,Avg pooling。Max pooling是指滑动窗口(跟卷积层的的差不多),取窗口内的最大值为输出值,如果是Avg pooling则取窗口内的平均值,移动窗口的步长为2,则feature map大小减半。池化层是无参的,即反向传播是不会对池化层进行优化的。 (5)激活函数:增加网络的非线性,进而提升网络的表达能力。当输入小于0时,单层的感知机是没有相应的,当输入大于0时,神经元输出为1,即当输入大于0这个节点才会被激活,所以这个函数称为激活函数,但是这个函数不可导,不能使用梯度下降进行优化 Sigmoid激活函数 特点:输入等于0时输出为0.5,输出最大值为1,最小值趋于0,将输出压缩在(0-1)的范围(可以表达概率),缺点:当输入负无穷或正无穷时,激活函数的导数为0,参数会长时间得不到更新,造成梯度离散,输出不是以0为中心。 Tanh激活函数(在RNN循环神经网络中用的比较多,输出的范围(-1,1)) ReLu激活函数(Rectified Linear Unit)深度学习用的最多的激活函数 输入小于0时不响应,大于0时线性的相应。当输入小于0时梯度为0,输入大于0时梯度为1,正数时不存在梯度饱和,但输入不能使用负数。因此做向后传播时,梯度计算非常方便,对搜索最优解减少梯度离散和梯度爆炸的情况 (6)BatchNorm层:通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布。流程: 首先对于一个小批量数据(mini-batch )进行均值的求解,再进行方差的计算,利用均值和方差对样本进行规范化,利用规范化 的结果计算输出,输出乘以尺度与偏移量得到最终结果。 原因:对于输入的数据,我们不进行规范化的话,我们在训练的过程中每一层的数据分布是一直在变化的,这对于我们网络的收敛非常不利的。 优点:(1)减少了参数的人为选择,可以取消Dropout和L2正则项参数,或者采取更小的L2正则项约束参数 (2)减少了对学习率的要求,收敛速度会变快 (3)可以不再使用局部响应归一化,BN本身就是归一化网络(局部响应归一化——AlexNet) (4)破坏原来的数据分布(数据加入了噪声),一定程度上缓解过拟合 使用: 使用时,训练时定义training=True,测试时,training=False,并且配合get_cellection来对参数进行更新。 (7)全连接层:连接所有的特征,将输出值送到分类器(如softmax分类器),将网络的输出变成一个向量,可以采用卷积(卷积核大小为1*1)代替全连接层,全连接层是尺度敏感的,配合使用Dropout层。我们需要定义全连接层输出的个数,节点的个数是全连接层的超参数,完成线性变换的过程得到一个向量,我们可以赋予向量不同的涵义,如果我们将结果定义为类别的概率分布,我们的网络就可以完成分类的任务。全连接层也可以完成特征提取。 (8)Dropout层:在训练过程中,随机的丢掉一部分输入,将某些参数置0,此时丢弃部分对应的参数不会更新,解决过拟合问题,取平均的作用,减少神经元之间的依赖,因为我们每次都随机的去掉一些节点。 (9)loss层:损失函数:用来评估模型的预测值和真实值的不一致程度。常见:交叉熵损失,softmax loss等 损失层定义了使用的损失函数,通过最小化损失来驱动网络的训练。网络的损失通过前向操作计算,网络参数相对于损失函数的梯度则通过反向操作计算。 分类任务损失:交叉熵损失 回归任务损失:L1损失,L2损失 (10)交叉熵损失:源于逻辑回归似然(已知结果反推原因),非负性,保证真实输出与期望输出接近时,损失为0,二分类损失函数定义式为: a是真实输出的结果,y是实际标签,a=0.5时,C最大。 熵:对信息量化的概念,定义了事件不确定程度,不确定越大,熵越大。 实现: 对于softmax loss,它用的标签是one-hot编码的。而sparse的标签不需要编码。在使用交叉熵损失函数时,我们得到的结果不需要经过softmax,直接输入到损失函数就好。 (11)L1,L2,Smooth L1损失: Smooth L1是L1和L2的变形,用于Faster RCNN,SSD等网络计算损失。 L1在0那里不可导,L2在0处可导。









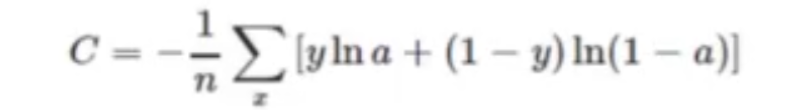


本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)

