在Java1.4之前的早起版本中,Java对I/O的支持并不完善,开发人员在开发高性能I/O程序的时候,会面临一些巨大的挑战和困难,主要问题如下: 在Java支持异步I/O之前的很长一段时间,高性能服务端开发领域一直被C和C++长期占据,作为Java开发者就很不服气,毕竟Java“天下第一”,所以Sun公司的大佬们就对IO进行了一步步的升级。 同步:用户线程发起IO请求后需要等待内核IO操作完成之后才能继续执行,应用程序需要直接参与IO读写操作。简单来说就是当线程发送了一个请求,在没有得到结果之前,这个线程不能做任何事情。 异步:用户线程发起IO请求之后继续执行其他操作,内核IO操作完成之后会通知线程IO或调用线程注册的回调函数,应用程序将所有的IO读写操作交给操作系统,它只需要等待结果通知。简单来说就是当线程发送了一个请求,不再去傻傻的等待结果,操作系统处理完之后再将结果通知给线程。 阻塞:IO操作完成之前,线程会被挂起,只有在得到返回结果或者抛出异常之后才会返回。 非阻塞:IO操作被调用之后立即得到一个返回状态,不能马上得到结果,线程不会被挂起,会立即返回。 用户空间:常规进程所在区域。 JVM 就是常规进程,驻守于用户空间。用户空间是非特权区域:比如,在该区域执行的代码就不能直接访问硬件设备。 linux的内核将所有外部设备都看作一个文件来操作,对一个文件的读写操作会调用内核提供的系统命令,返回一个file descriptor(fd,文件描述符)。而对一个Socket(套接字)的读写也会有响应的描述符,成为socket descriptor(socketfd,socket描述符),描述符就是一个数字,它指向内核中的一个结构体(文件路径、数据区等一些数据)。 kernel代表操作系统内核 5中I/O模型对比图: 其实前四种I/O模型都是同步I/O操作,他们的区别在于第一阶段,而他们的第二阶段是一样的:在数据从内核拷贝到应用缓冲区期间(用户空间),进程阻塞于recvfrom调用。 有人可能会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。但是,当kernel中数据准备好的时候,recvfrom会将数据从 kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。 BIO(Block IO)是Java1.4之前唯一的IO逻辑,在客户端通过socket向服务端传输数据,服务端监听端口。由于传统IO读数据的时候如果数据没有传达,IO会一直等待输入传入,所以当有新的请求过来的时候,会一直处于等待状态,直到上一个请求处理完成,才会再创建一个新的线程去处理这个请求,从而导致每一个链接都对应着服务器的一个线程。 模型图 B-1 分析:首先由模型图可以很明显的看出,一个客户端连接请求的处理,是由一个单向的闭合区间锁构成的。只有当第一个客户端的请求处理完成并且返回之后,第二个客户端的请求才可以连接到服务端。代码中可以看到标有两个阻塞点,一个是客户端与服务端建立连接的时候,一个是读取客户端发送数据的时候。大家可以用telnet去测试一下连接服务端,会发现两个问题:第一是当Client1与服务端连接成功之后,Client2是无法连接服务端的;第二是当Client1正在内核中进行数据处理的时候,Client2也是无法连接服务端的(你单身20年手速的话可以试试)。 思考:虽然通过这种方式可以完成客户端与服务端的通信,但是一次只能处理一个客户端请求啊。那么想想有多个客户端请求该如何解决呢? 解决方案:利用多线程,每当有一个客户端与服务端建立连接的时候,就创建一个线程专门为这个连接服务,这样第一个客户端请求就不会影响第二个客户端请求了。那么就由此方案对BIO进行升级。 模型图 B-2 处理客户端连接的类 处理读写数据的类(真正的开发中在这里处理业务逻辑,这里只进行一个简单的字符串处理) 服务端代码 C-2 分析:首先对模型图进行分析,每当一个客户端与服务端连接之后,都会去创建一个新的线程去处理这个连接,第一个客户端连接与第二个客户端连接是两个不同的线程,互不影响、互补干涉。代码部分在处理客户端连接方面是一样的,唯一的不同点就是在客户端与服务端建立连接的时候进行了new Thread,为这个连接单独创建了一个线程。 思考:这样做多客户端是可以做到同时连接服务端了,那么不妨问一下自己,现在这个IO还是阻塞的吗?答案当然是肯定的!它依然是阻塞的。这是有人可能会产生疑问了,为什么Client1与Client2都互不影响了,为什么还是阻塞的呢?阻塞的是什么呢?这里我要强调一点,虽然客户端连接服务端那一步是不阻塞了,但是在IO处理读写操作那里依然是阻塞的,这是由流(Stream)的特性就是阻塞的,这里只是用多线程去规避了IO的阻塞而已,并没有真的让IO不阻塞了,只是站在全局角度(所有客户端连接)来看IO是非阻塞的,也理解为是多线程实现了BIO的一个伪的非阻塞。 设想如果现在有10000个客户端要进行连接,那是不是要创建10000个线程呢?答案是肯定的!那么再思考一下这样做有什么弊端的?因为连接和线程是一一对应的,在高并发的情况下,会创建很多很多的线程,这样会极其浪费CPU的资源(CPU会对线程进行频繁的上下文切换从而让你感觉多个线程是“同时执行的”),甚至会导致服务器宕机。 解决方案:创建一个线程池,让所有客户端的连接都“共享”一个线程池,当一个客户端连接处理完之后,再将这个连接对应的线程还给线程池,从而服务端不再针对每个client都创建一个新的线程,而是维护一个线程池。 模型图 B-3 分析:首先由模型图可以看出,每有一个客户端与服务端建立连接的时候,都会为该连接分配一个线程池中的线程。线程池的工作原理是,内部维护了一系列线程,接受到一个任务时,会找出一个当前空闲的线程来处理这个任务,这个任务处理完成之后,再将这个线程返回到池子中。因为需要不断的检查一个client是否有新的请求,也就是调用其read方法,而这个方法是阻塞的,意味着,一旦调用了这个方法,如果没有读取到数据,那么这个线程就会一直block在那里,一直等到有数据,等到有了数据的时候,处理完成,立即由需要进行下一次判断,这个client有没有再次发送请求,如果没有,又block住了,因此可以认为,线程基本上是用一个少一个,因为对于一个client如果没有断开连接,就相当于这个任务没有处理完,任务没有处理完,线程永远不会返回到池子中,直到这个client断开连接。 思考:这样做确实是避免了CPU资源浪费的问题,那么大家思考一下这样做存在什么问题?用了线程池,意味着线程池中维护的线程数,也就是server端支持最多有多少个client来连接,这个数量设大了不行设小了也不行。如果线程池大小设置为100,此时并发有500个客户端连接,那么有400个连接就会进入等待队列,没有分配到线程的连接会等待很长的时间,可能会超时。其实不论多线程还是线程池,虽然在表面上解决了阻塞的问题,还是不可避免的出现了线程的浪费,因为只要有一个客户端与服务端建立连接就会对应一个线程去处理,如果这个线程只是做了一个客户端的连接操作,而没有去做IO操作,那么这个线程就分配的毫无意义,完全是浪费。基于这种思考,我们为什么不想办法去减少创建线程的数量呢?换句话说也就是减少线程执行任务的数量。比如做一个判断,只有该请求做IO读写操作的时候才去给他分配线程。 解决方案:每当客户端与服务端建立连接时,将这个连接和连接当时的状态(是否连接、是否可读、是否可写等)保存到一个容器中,比如Set,然后再设置一个迭代器不断的去轮询这个Set,判断连接的状态,如果是可读或者可写,就分配一个线程为它工作。 这时候你可能觉得太麻烦了吧!没错!博主也觉得太麻烦啦!因为这是在Java1.4之前IO埋下的“坑”,JDK官网肯定也意识到了这些问题,所以Sun公司在Java1.4版本推出了一个叫NIO的东西,它在java.io这个包下面,为什么不在java.io包下面进行改进呢?可能Sun公司觉得IO包已经比较“完善”了吧!那么接下来我们一起看看,官方设计NIO的思想是否跟我们前面的设想一样呢? NIO(Non-Block IO)是Java1.4以及以上版本提供的新的API,所以也叫作New IO。为所有的原始类型(boolean类型除外)提供缓存支持的数据容器,使用它可以提供非阻塞式的高伸缩性网络。与BIO中Socket类和ServerSocket类相对应,NIO也提供了SocketChannel和ServerSocketChannel两种不同的套接字通道实现。这两种新增的通道都只是阻塞和非阻塞两种模式。 在NIO中需要掌握的几个核心对象:缓冲区(Buffer)、选择器(Selector)、通道(Channel)。 缓冲区是包在一个对象内的基本数据元素数组。 Buffer 类相比一个简单数组的优点 是它将关于数据的数据内容和信息包含在一个单一的对象中。 Buffer 类以及它专有的子类定义了 一个用于处理数据缓冲区的 API。一个Buffer对象是固定数量的数据的容器。其作用是一个存储器,或者分段运输区,在这里数据可被存储并在之后用于检索。 Buffer类的七种基本数据类型的缓冲区实现也都是抽象的,这些类没有一种能够直接实例化。 运行后查看结果: 新的缓冲区是由分配(allocate)或包装(wrap)操作创建的。allocate操作创建一个缓冲区对象并分配一个私有的空间来储存容量大小的数据元素。wrap操作创建一个缓冲区对象但是不分配任何空间来储存数据元素。它使用您所提供的数组作为存储空间来储存缓冲区中的数据元素。 存储操作是通过get和put操作进行的,get 和 put 可以是相对的或者是绝对的。在前面的程序列表中,相对方案是不带有索引参数的函数。当相对函数被调用时,位置在返回时前进一。如果位置前进过多,相对运算就会抛 出 异 常 。 对 于 put() , 如 果 运 算 会 导 致 位 置 超 出 上 界 , 就 会 抛 出BufferOverflowException 异常。对于 get(),如果位置不小于上界,就会抛出BufferUnderflowException 异常。绝对存取不会影响缓冲区的位置属性,但是如果您所提供的索引超出范围(负数或不小于上界),也将抛出 IndexOutOfBoundsException 异常。 Buffer类定义的所有缓冲区都具有的四个属性,它们一起合作完成对缓冲区内部状态的变化跟踪 标记( Mark):一个备忘位置。调用 mark( )来设定 mark = postion。调用 reset( )设定 position = mark。标记在设定前是未定义的(undefined)。 位置( Position):指定下一个将要被写入或者读取的元素索引,它的值由 get()/put()方法自动更新,在新创建一个 Buffer 对象 时,position 被初始化为 0。 上界( Limit):指定还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入数据(在从通道读入缓冲区时)。 容量( Capacity):指定了可以存储在缓冲区中的最大数据容量,实际上,它指定了底层数组的大小,或者至少是指定了准许我 们使用的底层数组的容量。 这四个属性中后面三个比较重要,如果我们创建一个新的容量大小为 10 的 ByteBuffer 对象,在初始化的时候,position 设置为 0,limit 和 capacity 被设置为 10,capacity 的值不会再发生变化,而其它两个个将会随着使用而变化。接下来我们用代码来验证一下这四个值的变化情况: 输出结果: 创建缓冲区并初始化大小: 在该示例中,分配了一个容量大小为 10 的缓冲区,并在其中放入了数据 0-9,而在该缓冲区基础之上又创建了一个子缓冲区,并改变子缓冲区中的内容,从最后输出的结果来看,只有子缓冲区“可见的”那部分数据发生了变化,并且说明子缓冲区与原缓冲区是数据共享的,输出结果如下所示: 运行结果如下: 小科普:直接缓冲区时 I/O 的最佳选择,但可能比创建非直接缓冲区要花费更高的成本。直接缓冲区使用的内存是通过调用本地操作系统方面的代码分配的,绕过了标准 JVM 堆栈。建立和销毁直接缓冲区会明显比具有堆栈的缓冲区更加破费,这取决于主操作系统以及 JVM 实现。直接缓冲区的内存区域不受无用存储单元收集支配,因为它们位于标准 JVM 堆栈之外。使用直接缓冲区或非直接缓冲区的性能权衡会因JVM,操作系统,以及代码设计而产生巨大差异。 回想一下文章前面讲解UNIX 五种IO模型中的读取数据的过程,读取数据总是需要通过内核空间传递到用户空间,而往外写数据总是要通过用户空间到内核空间。JVM堆栈属于用户空间。 而我们这里提到的直接缓冲区,就是内核空间的内存。内核空间的内存在java中是通过Unsafe这个类来调用的。 Netty(一个异步、事件驱动的用来做高性能、高可靠性的网络应用框架,对NIO进行了封装)中所提到的零拷贝(通常是指计算机在网络上发送文件时,不需要将文件内容拷贝到用户空间而直接在内核空间中传输到网络的方式),无非就是使用了这里的直接缓冲区。没有什么神奇的。 选择器提供了询问通道是否已经准备好执行每个 I/0 操作的能力,这使得多元 I/O 成为可能,就绪选择和多元执行使得单线程能够有效率地同时管理多个 I/O 通道(channels)。 为什么需要选择器? 传统的 Server/Client 模式会基于 TPR(Thread per Request),服务器会为每个客户端请求建立一个线程,由该线程单独负责处理 一个客户请求。这种模式带来的一个问题就是线程数量的剧增,大量的线程会增大服务器的开销。大多数的实现为了避免这个问题, 都采用了线程池模型,并设置线程池线程的最大数量,这又带来了新的问题,如果线程池中有 200 个线程,而有 200 个用户都在 进行大文件下载,会导致第201个用户的请求无法及时处理,即便第201个用户只想请求一个几KB大小的页面。传统的 Server/Client 模式如下图所示: NIO 中非阻塞 I/O 采用了基于 Reactor 模式的工作方式,I/O 调用不会被阻塞,相反是注册感兴趣的特定 I/O 事件,如可读数据到 达,新的套接字连接等等,在发生特定事件时,系统再通知我们。NIO 中实现非阻塞 I/O 的核心对象就是 Selector,Selector 就是 注册各种 I/O 事件地方,而且当那些事件发生时,就是这个对象告诉我们所发生的事件,如下图所示: 使用 NIO 中非阻塞 I/O 编写服务器处理程序,大体上可以分为下面三个步骤: 选择器(Selector)如何创建? 如何将通道(Channel)注册到选择器(Selector)上? register( )方法接受一个 Selector 对象作为参数,以及一个名为ops 的整数参数。第二个参数表示所关心的通道操作,返回值是一个SelectionKey。 选择器(Selector)API 并发性,选择器对象是线程安全的吗? 可以看到选择键的集合是HashSet类型,HashSet是线程不安全。所以选择器对象是线程安全的,但它们包含的键集合不是。 在多线程的场景中,如果您需要对任何一个键的集合进行更改,不管是直接更改还是其他操作带来的副作用,您都需要首先以相同的顺序,在同一对象上进行同步。锁的过程是非常重要的。如果竞争的线程没有以相同的顺序请求锁,就将会有死锁的潜在隐患。如果您可以确保否其他线程不会同时访问选择器,那么就不必要进行同步了。Selector 类的 close( )方法与 select( )方法的同步方式是一样的,因此也有一直阻塞的可能性。在选择过程还在进行的过程中,所有对 close( )的调用都会被阻塞,直到选择过程结束,或者执行选择的线程进入睡眠。在后面的情况下,执行选择的线程将会在执行关闭的线程获得锁是立即被唤醒,并关闭选择器 。 通道(Channel)可以理解为数据传输的管道。通道与流不同的是,流只是在一个方向上移动(一个流必须是InputStream或者OutputStream的子类),而通道可以用于读、写或者同时用于读写。当然了所有数据都通过 Buffer 对象来处理。我们永远不会将字节直接写入通道中,相反是将数据写入包含一个或者多个字节的缓冲区。同样不会直接从通道中读取字节,而是将数据从通 道读入缓冲区,再从缓冲区获取这个字节。 在 NIO 中,提供了多种通道对象,而所有的通道对象都实现了 Channel 接口。它们之间的继承关系如下图所示: 任何时候读取数据,都不是直接从通道读取,而是从通道读取到缓冲区。所以使用 NIO 读取数据可 以分为下面三个步骤: 下面是一个简单的使用 NIO 从文件中读取数据的例子: 下面是一个简单的使用 NIO 向文件中写入数据的例子: 关系图: 由上面的示例我们大概可以总结出NIO是怎么解决掉线程的瓶颈并处理海量连接的: NIO由原来的阻塞读写(占用线程)变成了单线程轮询事件,找到可以进行读写的网络描述符进行读写。除了事件的轮询是阻塞的(没有可干的事情必须要阻塞),剩余的I/O操作都是纯CPU操作,没有必要开启多线程。 并且由于线程的节约,连接数大的时候因为线程切换带来的问题也随之解决,进而为处理海量连接提供了可能。 单线程处理I/O的效率确实非常高,没有线程切换,只是拼命的读、写、选择事件。但现在的服务器,一般都是多核处理器,如果能够利用多核心进行I/O,无疑对效率会有更大的提高。 仔细分析一下我们需要的线程,其实主要包括以下几种: Java的Selector对于Linux系统来说,有一个致命限制:同一个channel的select不能被并发的调用。因此,如果有多个I/O线程,必须保证:一个socket只能属于一个IoThread,而一个IoThread可以管理多个socket。 另外连接的处理和读写的处理通常可以选择分开,这样对于海量连接的注册和读写就可以分发。虽然read()和write()是比较高效无阻塞的函数,但毕竟会占用CPU,如果面对更高的并发则无能为力。 下面是我理解的 Java NIO 反应堆(单Reactor多线程模型)的工作原理图: 一般情况下,I/O 复用机制需要事件分发器(event dispatcher)。 事件分发器的作用,即将那些读写事件源分发给各读写事件的处理者,就像送快递的在楼下喊: 谁谁谁的快递到了, 快来拿吧!开发人员在开始的时候需要在分发器那里注册感兴趣的事件,并提供相应的处理者(event handler),或者是回调函数;事件分发器在适当的时候,会将请求的事件分发给这些handler或者回调函数。 涉及到事件分发器的两种模式称为:Reactor和Proactor。 Reactor模式是基于同步I/O的,而Proactor模式是和异步I/O相关的。在Reactor模式中,事件分发器等待某个事件或者可应用或个操作的状态发生(比如文件描述符可读写,或者是socket可读写),事件分发器就把这个事件传给事先注册的事件处理函数或者回调函数,由后者来做实际的读写操作。 而在Proactor模式中,事件处理者(或者代由事件分发器发起)直接发起一个异步读写操作(相当于请求),而实际的工作是由操作系统来完成的。发起时,需要提供的参数包括用于存放读到数据的缓存区、读的数据大小或用于存放外发数据的缓存区,以及这个请求完后的回调函数等信息。事件分发器得知了这个请求,它默默等待这个请求的完成,然后转发完成事件给相应的事件处理者或者回调。举例来说,在Windows上事件处理者投递了一个异步IO操作(称为overlapped技术),事件分发器等IO Complete事件完成。这种异步模式的典型实现是基于操作系统底层异步API的,所以我们可称之为“系统级别”的或者“真正意义上”的异步,因为具体的读写是由操作系统代劳的。 在Reactor中实现读 在Proactor中实现读: 可以看出,两个模式的相同点,都是对某个I/O事件的事件通知(即告诉某个模块,这个I/O操作可以进行或已经完成)。在结构上,两者也有相同点,事件分发器负责提交IO操作(异步)、查询设备是否可操作(同步),然后当条件满足时,就回调handler;不同点在于,异步情况下(Proactor),当回调handler时,表示I/O操作已经完成;同步情况下(Reactor),回调handler时,表示I/O设备可以进行某个操作(can read 或 can write)。 使用NIO != 高性能,当连接数<1000,并发程度不高或者局域网环境下NIO并没有显著的性能优势。NIO并没有完全屏蔽平台差异,它仍然是基于各个操作系统的I/O系统实现的,差异仍然存在。使用NIO做网络编程构建事件驱动模型并不容易,陷阱重重。所以推荐大家使用成熟的NIO框架,如Netty,MINA等。解决了很多NIO的陷阱,并屏蔽了操作系统的差异,有较好的性能和编程模型。 Java1.7中新增了一些与文件(网络)I/O相关的一些api。这些API被称为NIO.2,或称为AIO(Asynchronous I/O)。AIO最大的一个特性就是异步能力,这种能力对socket与文件I/O都起作用。AIO其实是一种在读写操作结束之前允许进行其他操作的I/O处理。AIO是对JDK1.4中提出的同步非阻塞I/O(NIO)的进一步增强。 Java1.7主要增加了三个新的异步通道和一个用户处理器接口: “真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,事件循环将文件句柄的状态事件通知给用户线程, 由用户线程自行读取数据、处理数据。而在异步IO模型中,当用户线程收到通知时,数据已经被内核读取完毕,并放 在了用户线程指定的缓冲区内,内核在IO完成后通知用户线程直接使用即可。异步IO模型使用了Proactor设计模式实 现了这一机制,如下图所示: 服务端代码: 客户端代码: 执行结果: 服务端: 洋洋洒洒三万六千多字,与小伙伴们一同在网络IO演进之路上走了一遭。整个网络编程体系还是比较庞大的,本文也只是描述了冰山一角,希望能给各位看官一点小小收获。博主能力有限,只是一个在互联网摸爬滚打立志要从一个Code Farmer进化为Senior Architec的小菜鸟,也只能理解到这个层面,未来路还长,大家一起努力、进步!
前言
说起IO,很多人对它应该都有所耳闻,可能很多人对IO都有着一种既熟悉又陌生的感觉,因为IO这一块内容还是比较广泛杂乱的,整个IO的体系也是十分庞大。那么IO到底是个什么东西呢?IO 是主存和外部设备 ( 硬盘、终端和网络等 ) 拷贝数据的过程。 IO 是操作系统的底层功能实现,底层通过 I/O 指令进行完成。Java中的IO主要分为文件IO和网络IO两大类,本文博主就与大家一同去网络IO的演进之路上走一遭,看看网络IO到底是如何一步步进化升级的。
正文
先讲个小故事,体会一下IO为何需要进化升级。
必须知道的几个概念
同步(Synchronization)和异步(Asynchronous)
实例:A调用B,B在接到A的调用后,会立即执行要做的事。A的本次调用可以得到结果。
实例:A调用B,B在接到A的调用后,不保证会立即执行要做的事,但是保证会去做,B在做好了之后会通知A。A的本次调用得不到结果,但是B执行完之后会通知A。同步与异步是对应于调用者与被调用者,它们是线程之间的关系,两个线程之间要么是同步的,要么是异步的。同步操作时,调用者需要等待被调用者返回结果,才会进行下一步操作,而异步则相反,调用者不需要等待被调用者返回调用,即可进行下一步操作,被调用者通常依靠事件、回调等机制来通知调用者结果。
阻塞(Block)和非阻塞(Non-Block)
实例:A调用B,A在发出调用后,要一直等待,等着B返回结果。
实例:A调用B,A在发出调用后,不需要等待,可以去做自己的事情。阻塞与非阻塞是线程在访问数据的时候,数据是否准备就绪的一种处理方式,也是线程的一种状态。阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回, 非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
区别(这里是重点哦,这几个概念很容易混淆)
同步与异步用来描述两个线程之间的关系(被调用方),是线程的一个过程。阻塞与非阻塞用来描述一个线程内的一种处理方式(调用方),是线程的一个状态。同步不一定阻塞,异步也不一定非阻塞。没有必然关系。!!!
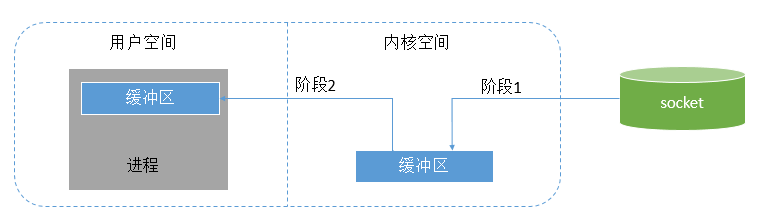
用户空间和内核空间
内核空间:操作系统所在区域。内核代码有特别的权力:它能与设备控制器通讯,控制着用户区域进程的运行状态等。最重要的是,所有 I/O 都直接(如这里所述)或间接通过内核空间。
关系:当进程请求 I/O 操作的时候,它执行一个系统调用将控制权移交给内核。C/C++程序员所熟知的底层函数 open( )、 read( )、 write( )和 close( )要做的无非就是建立和执行适当的系统调用。当内核以这种方式被调用,它随即采取任何必要步骤,找到进程所需数据,并把数据传送到用户空间内的指定缓冲区。内核试图对数据进行高速缓存或预读取,因此进程所需数据可能已经在内核空间里了。如果是这样,该数据只需简单地拷贝出来即可。如果数据不在内核空间,则进程被挂起,内核着手把数据读进内存。
Linux网络I/O模型简介
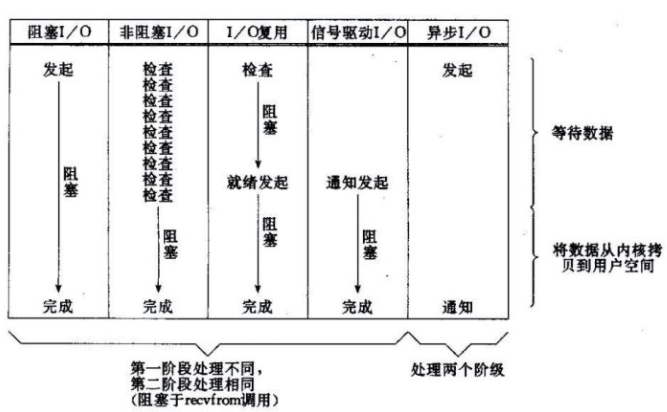
根据UNIX网络编程对I/O模型的分类,UNIX提供了5中I/O模型,分别如下:
recvfrom是一个C语言函数
函数原型:ssize_t recvfrom(int sockfd,void *buf,size_t len,unsigned int flags,
struct sockaddr *from,socket_t *fromlen);
返回值说明:
成功则返回实际接收到的字符数,失败返回-1,错误原因会存于errno 中。
参数说明:
s: socket描述符;
buf: UDP数据报缓存区(包含所接收的数据);
flags: 调用操作方式(一般设置为0)。
from: 指向发送数据的客户端地址信息的结构体(sockaddr_in需类型转换);
fromlen: 指针,指向from结构体长度值。
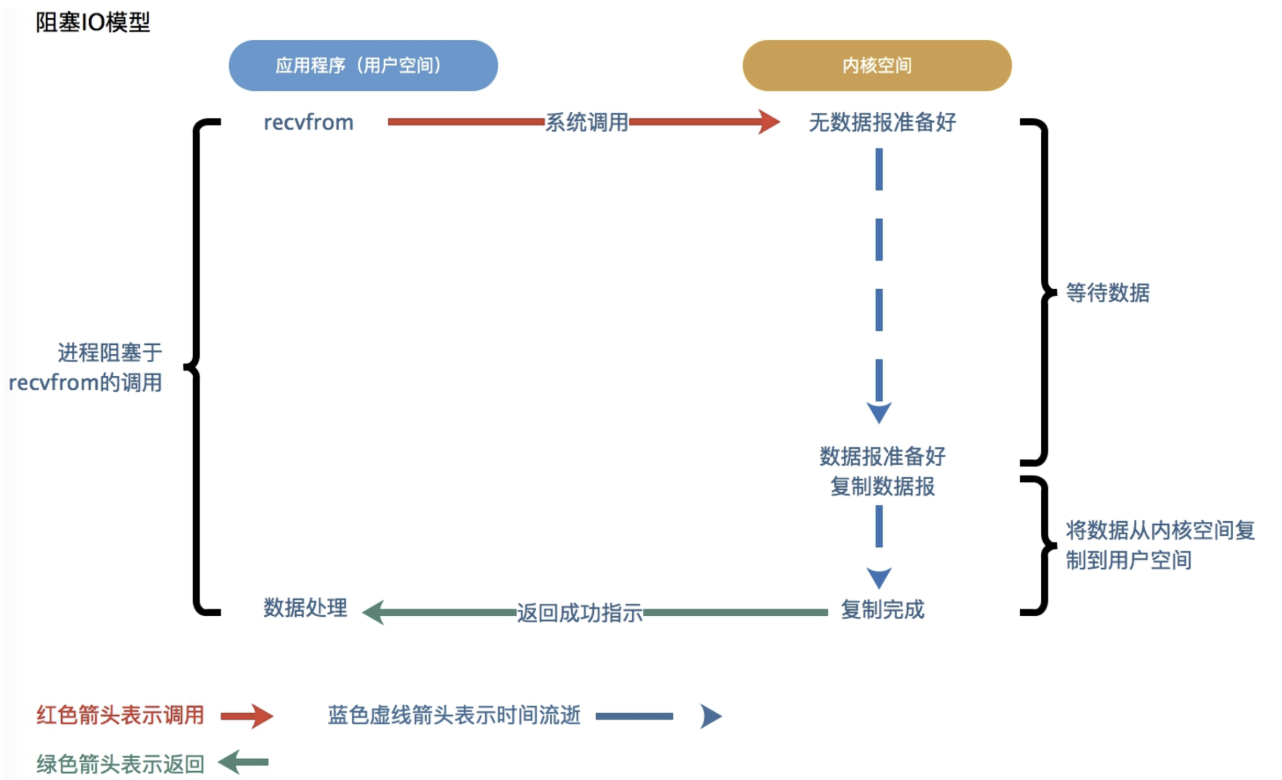
最常用的I/O模型就是阻塞I/O模型,缺省情况下,所有文件操作都是阻塞的。在进程空间中调用recvfrom函数,其系统调用直到数据包到达且被复制到应用进程的缓冲区当中或者发生异常时才返回,在此期间会一直等待,进程从调用recvfrom函数开始直到返回的整个时间段内都是被阻塞的,因此被称为I/O阻塞模型。
解释:当用户线程发出IO请求后,内核会去查看数据是否准备就绪,如果没有准备就绪就会等待数据就绪,此时用户线程就会处于阻塞状态,用户线程交出CPU。当数据就绪后,内核会将数据拷贝到用户线程并返回结果给用户线程,用户线程此时才能解除阻塞(block)状态。
特点:IO执行的两个阶段都被阻塞了。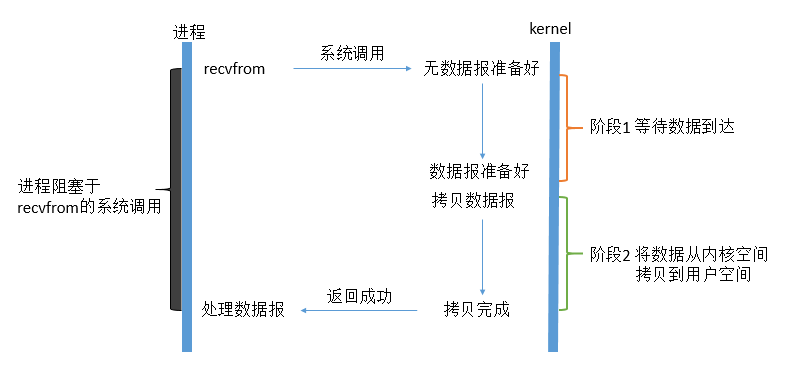
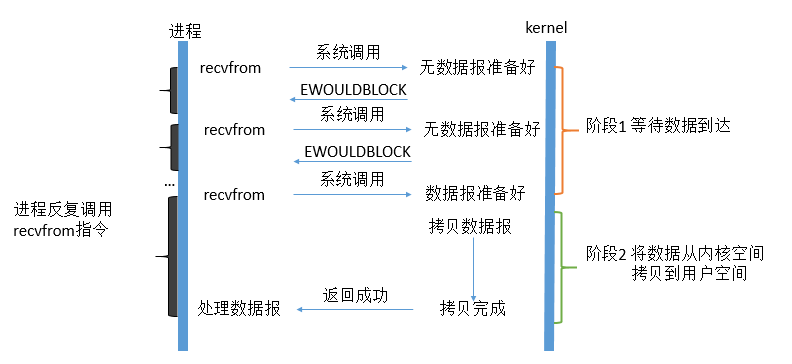
recvfrom从应用层到内核的时候,如果缓冲区没有数据,就直接返回一个EWOULDBLOCK错误,一般都对非阻塞I/O模型进行轮询检查这个状态,看内核中是不是有数据到来。
解释:当用户线程发起一个read操作之后,并不需要等待,而是立即得到一个结果。如果结果是一个error,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦内核中的数据准备好了,并且又再次受到用户线程的read操作请求,那么它会立即将数据拷贝到用户线程然后返回。在非阻塞IO模型中,用户线程需要不断询问内核数据是否准备就绪,也就是说非阻塞IO不会交出CPU,而是会一直占用CPU。
特点:用户进程第一个阶段不是阻塞的,需要不断的主动询问kernel数据好了没有;第二个阶段依然总是阻塞的。
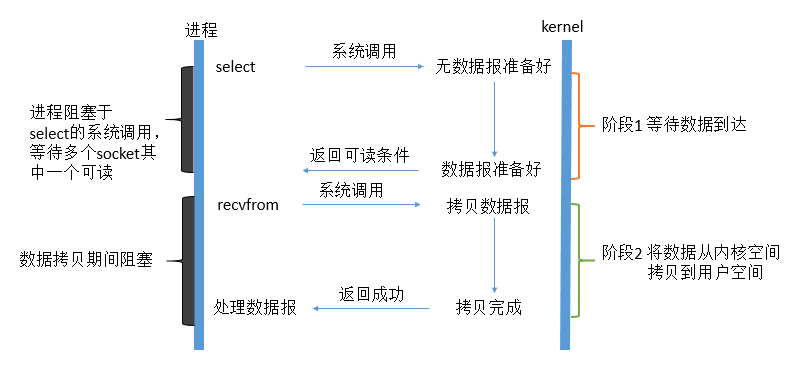
Linux提供了select/poll,进程通过将一个或多个fd(文件描述符)传递个select或poll调用,阻塞在select操作上,这样select/poll可以帮我们检测多个fd是否处于就绪状态。select/poll是顺序扫描fd是否就绪,而且支持的fd数量有限,因此它的使用受到了一定的限制。Linux还提供了一个epoll系统调用,epoll使用基于事件驱动方式替代顺序扫描,因此性能更高,当有fd就绪时,立即调用rollback。
解释:在多路复用IO模型中,会有一个线程不断的去轮询多个socket的状态,只有当socket真正有读写时间的时候,才真正调用实际的IO读写操作。因为在多路复用IO模型中,只需要一个线程就可以管理多个socket,系统不需要创建新的进程或者线程,也不需要维护这些进程或者线程,并且只有在真正有socket读写事件进行的时候,才会使用IO资源,所以它大大减少了CPU的资源占用。
特点:IO复用同非阻塞IO本质一样,不过利用了新的select系统调用,由内核来负责本来是请求进程该做的轮询操作。看似比非阻塞IO还多了一个系统调用开销,不过因为可以支持多路IO,才算提高了效率。多路复用IO比较适合连接数比较多的情况。
首先开启套接口信号驱动I/O功能,并通过系统调用sigaction执行一个信号处理函数(此系统调用立即返回,进程继续工作,它是非阻塞的)。当数据准备就绪时,就为该进程生成一个SIGIO信号,通过信号回调通知应用程序调用recvfrom函数读取数据,并通知主循环函数处理数据。
解释:在信号驱动IO模型中,当用户线程发起一个IO请求操作,会给对应的socket注册一个信号函数,然后用户线程会继续执行,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用IO读写操作来进行实际的IO请求操作。
特点:当数据准备就绪时,内核会对用户线程进行通知,用户线程会收到一个信号,然后开始调用IO函数进行读写操作。
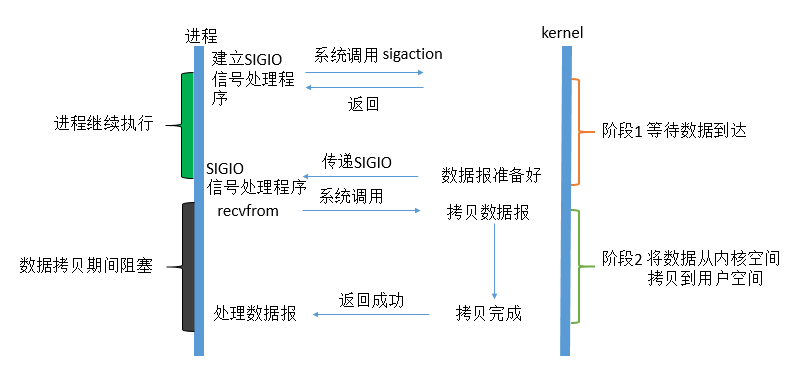
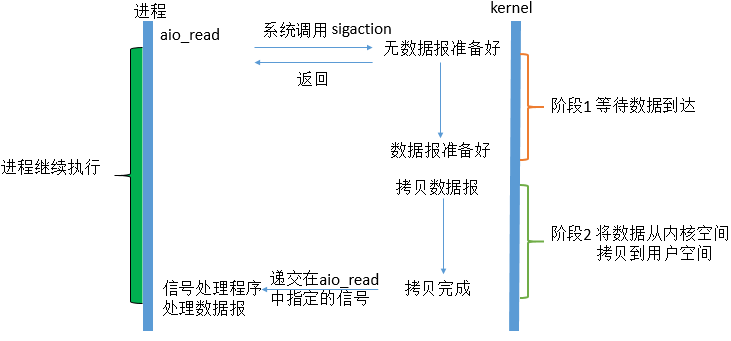
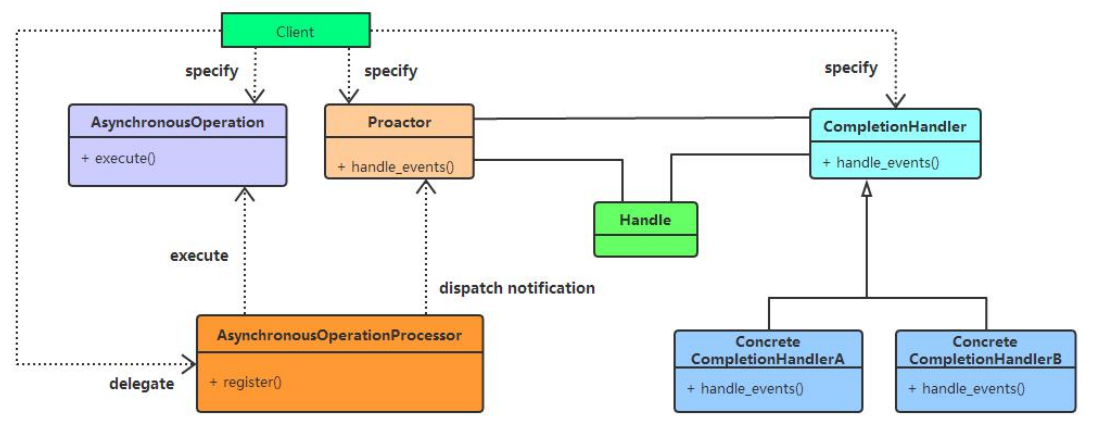
告知内核启动某个操作,并让内核在整个操作完成之后(包括将数据从内核拷贝到用户线程的缓冲区中)通知我们。
解释:异步IO模型是比较理想的IO模型,在异步IO模型中,当用户线程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从内核的角度,当它受到一个asynchronous read之后,它会立刻返回,说明read请求已经成功发起了,因此不会对用户线程产生任何block。然后,内核会等待数据准备完成,然后将数据拷贝到用户线程,当这一切都完成之后,内核会给用户线程发送一个信号,告诉它read操作完成了。也就说用户线程完全不需要实际的整个IO操作是如何进行的,只需要先发起一个请求,当接收内核返回的成功信号时表示IO操作已经完成,可以直接去使用数据了。
特点:IO操作的两个阶段都不会阻塞用户线程,这两个阶段都是由内核自动完成,然后发送一个信号通知用户线程操作已完成,不需要再在用户线程中调用IO函数进行实际的读写操作。
总结
BIO演进之路
BIO简介
BIO初级形态(单线程模式)
服务端代码 C-1//同步阻塞IO模型---BIO服务端(单线程模式) public class BIOServer { public static void main(String[] args) { try { //创建服务端监听特定端口的ServerSocket(获取端口对应的客户端的连接对象) ServerSocket serverSocket = new ServerSocket(8888); System.out.println("BIOServer has started,listening on port:" + serverSocket.getLocalSocketAddress()); //循环监听客户端的连接请求---处理多个客户端的连接请求 while (true){ //创建一个客户端在服务端的引用,accept()是阻塞方法,等待客户端连接 //如果第一个客户端未断开,第二个客户端的连接会一直阻塞在这里,直到第一个客户端断开连接 //******阻塞点****** Socket clientSocket = serverSocket.accept(); System.out.println("Connection from:" + clientSocket.getRemoteSocketAddress()); System.out.println("Data waiting......"); //创建输入流读取客户端发送的数据 //******阻塞点****** InputStream is = clientSocket.getInputStream(); //将数据包装到Scanner中 Scanner clientInput = new Scanner(is); String serverResponse; //服务端---客户端循环交互 while (true){ //等待客户端输入 String clientScannerData = clientInput.nextLine(); if ("quit".equals(clientScannerData)){ serverResponse = "BIOServer has been disconnected" + ".n"; //给客户端做出响应,将响应信息写出 clientSocket.getOutputStream().write(serverResponse.getBytes()); //与服务端断开连接 break; } System.out.println("Client data:" + clientScannerData + "---Client address: " + clientSocket.getRemoteSocketAddress()); serverResponse = "The data you sent:" + clientScannerData + " BIOServer has been received" + ".n"; //给客户端做出响应,将响应信息写出 clientSocket.getOutputStream().write(serverResponse.getBytes()); } } } catch (IOException e) { e.printStackTrace(); } } } BIO中级形态(多线程模式)
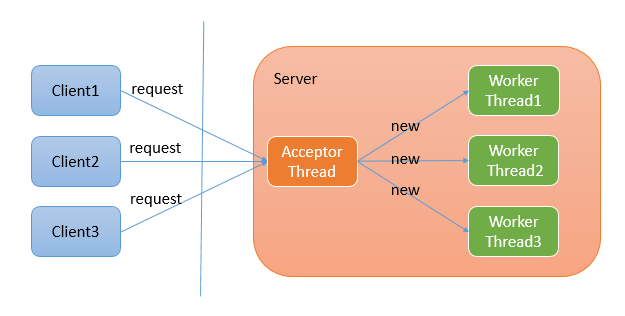
为了代码结构的美观,这里对方法进行封装//处理客户端连接请求 public class ClientHandler implements Runnable { private final Socket clientSocket; private final RequestHandler requestHandler; public ClientHandler(Socket clientSocket, RequestHandler requestHandler) { this.clientSocket = clientSocket; this.requestHandler = requestHandler; } @Override public void run() { try { System.out.println("Connection from:" + clientSocket.getRemoteSocketAddress()); System.out.println("Data waiting......"); //创建输入流读取客户端发送的数据 //******阻塞点****** InputStream is = clientSocket.getInputStream(); //将数据包装到Scanner中 Scanner clientInput = new Scanner(is); String serverResponse; //服务端---客户端循环交互 while (true){ //等待客户端输入 String clientScannerData = clientInput.nextLine(); if ("quit".equals(clientScannerData)){ serverResponse = "BIOServer has been disconnected" + ".n"; //给客户端做出响应,将响应信息写出 clientSocket.getOutputStream().write(serverResponse.getBytes()); //与服务端断开连接 break; } System.out.println("Client data:" + clientScannerData + "---Client address: " + clientSocket.getRemoteSocketAddress()); serverResponse = requestHandler.hendler(clientScannerData); //给客户端做出响应,将响应信息写出 clientSocket.getOutputStream().write(serverResponse.getBytes()); } }catch (IOException e){ e.printStackTrace(); } } } //处理读写数据---实际开发中可能需要对数据进行处理 public class RequestHandler { //业务逻辑处理 public String hendler(String request){ return "The data you sent:" + request + " BIOServer has been received" + ".n"; } } //同步伪非阻塞IO模型---BIO服务端(多线程模式) public class BIOServerMultiThread { public static void main(String[] args) { RequestHandler requestHandler = new RequestHandler(); try { //创建服务端监听特定端口的ServerSocket(获取端口对应的客户端的连接对象) ServerSocket serverSocket = new ServerSocket(8888); System.out.println("BIOServer has started,listening on port:" + serverSocket.getLocalSocketAddress()); //循环监听客户端的连接请求---处理多个客户端的连接请求 while (true){ //创建一个客户端在服务端的引用,accept()是阻塞方法,等待客户端连接 Socket clientSocket = serverSocket.accept(); //创建线程并执行方法 new Thread(new ClientHandler(clientSocket,requestHandler)).start(); } }catch (IOException e){ e.printStackTrace(); } } } BIO高级形态(线程池模式)
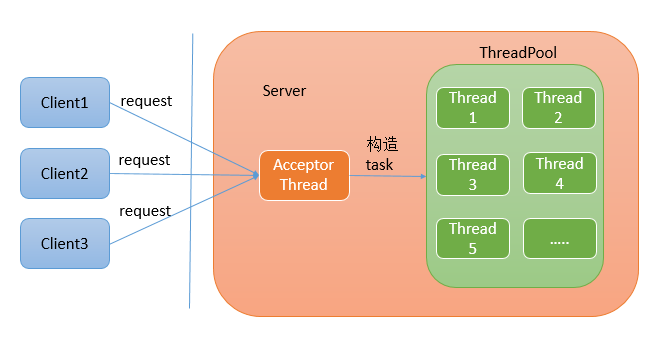
服务端代码 C-3//同步伪非阻塞IO模型---BIO服务端(线程池模式) public class BIOServerThreadPool { public static void main(String[] args) { //创建一个大小为3的线程池 ExecutorService executorService = Executors.newFixedThreadPool(3); RequestHandler requestHandler = new RequestHandler(); try { //创建服务端监听特定端口的ServerSocket(获取端口对应的客户端的连接对象) ServerSocket serverSocket = new ServerSocket(8888); System.out.println("BIOServer has started,listening on port:" + serverSocket.getLocalSocketAddress()); //循环监听客户端的连接请求---处理多个客户端的连接请求 while (true){ //创建一个客户端在服务端的引用,accept()是阻塞方法,等待客户端连接 Socket clientSocket = serverSocket.accept(); //让线程池为其绑定池中的线程来执行 executorService.submit(new ClientHandler(clientSocket,requestHandler)); } }catch (IOException e){ e.printStackTrace(); } } } NIO闪亮登场
NIO简介
NIO弥补了原来同步阻塞IO的不足,它在标准Java代码中提供了高速的、面向块的IO。通过定义包含数据的类和以块的形式处理这些数据,NIO不使用本机代码就可以利用低级优化,这是原来的IO包所无法做到的,接下来博主就与小伙伴们一同认识NIO。NIO三件套
缓冲区Buffer
缓冲区实际上是一个容器对象,更直接的说,其实就是一个数组,在 NIO 库中,所有数据都是用缓冲区处理的。在读 取数据时,它是直接读到缓冲区中的; 在写入数据时,它也是写入到缓冲区中的;任何时候访问 NIO 中的数据,都 是将它放到缓冲区中。而在面向流 I/O 系统中,所有数据都是直接写入或者直接将数据读取到 Stream 对象中。 在 NIO 中,所有的缓冲区类型都继承于抽象类 Buffer,最常用的就是 ByteBuffer,对于 Java 中的基本类型,基本都有 一个具体 Buffer 类型与之相对应,它们之间的继承关系如下图所示:

public abstract class Buffer { //JDK1.4时,引入的api public final int capacity( )//返回此缓冲区的容量 public final int position( )//返回此缓冲区的位置 public final Buffer position (int newPositio)//设置此缓冲区的位置 public final int limit( )//返回此缓冲区的限制 public final Buffer limit (int newLimit)//设置此缓冲区的限制 public final Buffer mark( )//在此缓冲区的位置设置标记 public final Buffer reset( )//将此缓冲区的位置重置为以前标记的位置 public final Buffer clear( )//清除此缓冲区 public final Buffer flip( )//反转此缓冲区 public final Buffer rewind( )//重绕此缓冲区 public final int remaining( )//返回当前位置与限制之间的元素数 public final boolean hasRemaining( )//告知在当前位置和限制之间是否有元素 public abstract boolean isReadOnly( );//告知此缓冲区是否为只读缓冲区 //JDK1.6时引入的api public abstract boolean hasArray();//告知此缓冲区是否具有可访问的底层实现数组 public abstract Object array();//返回此缓冲区的底层实现数组 public abstract int arrayOffset();//返回此缓冲区的底层实现数组中第一个缓冲区元素的偏移量 public abstract boolean isDirect();//告知此缓冲区是否为直接缓冲区 }
下面创建一个简单的IntBuffer实例:public class IntBuffer { public static void main(String[] args) { // 分配新的 int 缓冲区,参数为缓冲区容量 // 新缓冲区的当前位置将为零,其界限(限制位置)将为其容量。它将具有一个底层实现数组,其数组偏移量将为零。 IntBuffer buffer = IntBuffer.allocate(8); for (int i = 0; i < buffer.capacity(); ++i) { int j = 2 * (i + 1); // 将给定整数写入此缓冲区的当前位置,当前位置递增 buffer.put(j); } // 重设此缓冲区,将限制设置为当前位置,然后将当前位置设置为 0 buffer.flip(); // 查看在当前位置和限制位置之间是否有元素 while (buffer.hasRemaining()) { // 读取此缓冲区当前位置的整数,然后当前位置递增 int j = buffer.get(); System.out.print(j + " "); } } }

实际开发中ByteBuffer会比较常用,接下来我们看看ByteBuffer API:public abstract class ByteBuffer { //缓冲区创建相关api public static ByteBuffer allocateDirect(int capacity) public static ByteBuffer allocate(int capacity) public static ByteBuffer wrap(byte[] array) public static ByteBuffer wrap(byte[] array,int offset, int length) //缓存区存取相关API public abstract byte get( );//从当前位置position上get,get之后,position会自动+1 public abstract byte get (int index);//从绝对位置get public abstract ByteBuffer put (byte b);//从当前位置上put,put之后,position会自动+1 public abstract ByteBuffer put (int index, byte b);//从绝对位置上put }
在谈到缓冲区时,我们说缓冲区对象本质上是一个数组,但它其实是一个特殊的数组,缓冲区对象内置了一些机制, 能够跟踪和记录缓冲区的状态变化情况,如果我们使用 get()方法从缓冲区获取数据或者使用 put()方法把数据写入缓冲 区,都会引起缓冲区状态的变化。public abstract class Buffer { ... // Invariants: mark <= position <= limit <= capacity private int mark = -1; private int position = 0; private int limit; private int capacity; ... } public class BufferDemp { public static void main(String[] args) throws Exception { //这用用的是文件 IO 处理 FileInputStream fin = new FileInputStream("F://testio/test.txt"); //创建文件的操作管道 FileChannel fc = fin.getChannel(); FileChannel fc = fin.getChannel(); //分配一个 10 个大小缓冲区,说白了就是分配一个 10 个大小的 byte 数组 ByteBuffer buffer = ByteBuffer.allocate(10); output("初始化", buffer); //先读一下 fc.read(buffer); output("调用 read()", buffer); //准备操作之前,先锁定操作范围 buffer.flip(); output("调用 flip()", buffer); //判断有没有可读数据 while (buffer.remaining() > 0) { byte b = buffer.get(); // System.out.print(((char)b)); } } output("调用 get()", buffer); //可以理解为解锁,清空buffer buffer.clear(); output("调用 clear()", buffer); //最后把管道关闭 fin.close(); fin.close(); } //把这个缓冲里面实时状态给答应出来 public static void output(String step, ByteBuffer buffer) { System.out.println(step + " : "); //标记,备忘位置 System.out.print("mark: " + buffer.mark() + ", "); //容量,数组大小 System.out.print("capacity: " + buffer.capacity() + ", "); //当前操作数据所在的位置,也可以叫做游标 System.out.print("position: " + buffer.position() + ", "); //锁定值,flip,数据操作范围索引只能在 position - limit 之间 System.out.println("limit: " + buffer.limit()); System.out.println(); } }
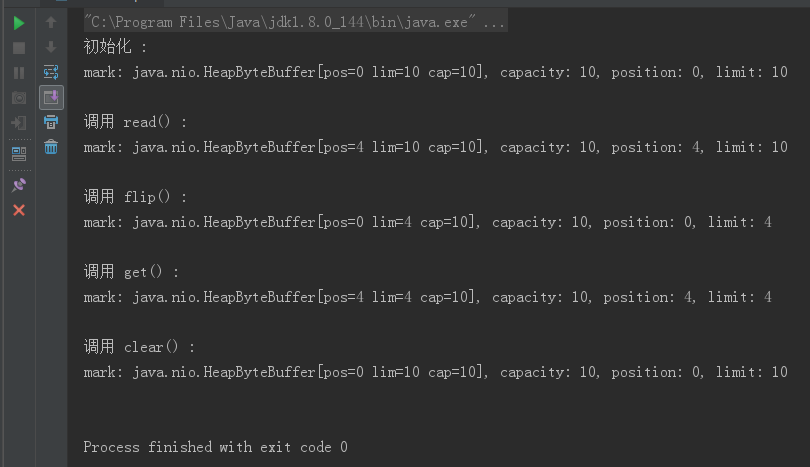
接下来对以上运行结果进行分析
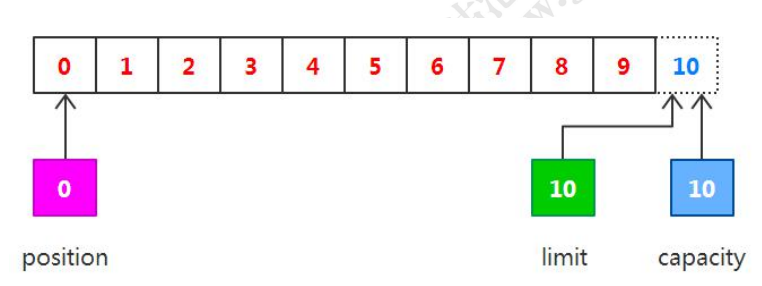
我们从通道(Channel)读取一些数据到缓冲区(Buffer)中,相当于是将通道中的数据写入缓冲区。如果读取4个字节大小的数据,则此时 position 的值为 4,即下一个将要被写入的字节索引为 4,而 limit 仍然是 10,如下图所示:
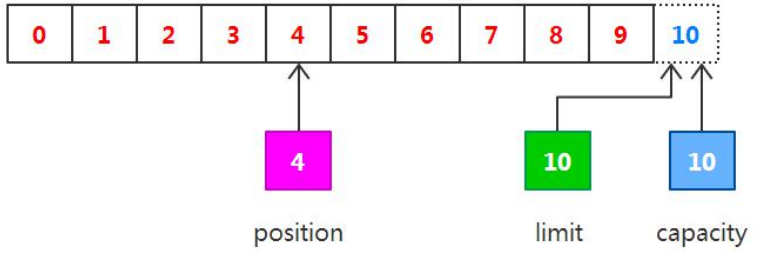
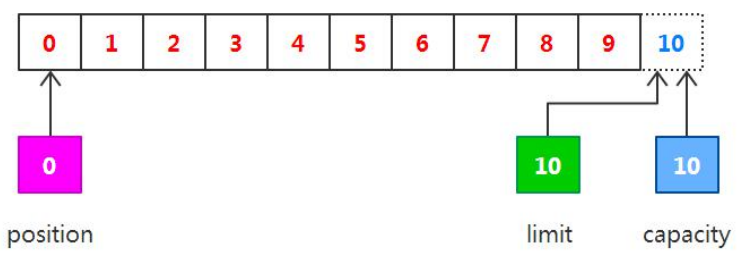
下一步把读取的数据写入到输出通道中,相当于从缓冲区中读取数据,在此之前,必须调用 flip()方法,该方法将会完 成两件事情,首先把 limit 设置为当前的 position 值,再将把 position 设置为 0。由于 position 被设置为 0,所以可以保证在下一步输出时读取到的是缓冲区中的第一个字节,而 limit 被设置为当前的 position,可以保证读取的数据正好是之前写入到缓冲区中的数据,如下图所示:
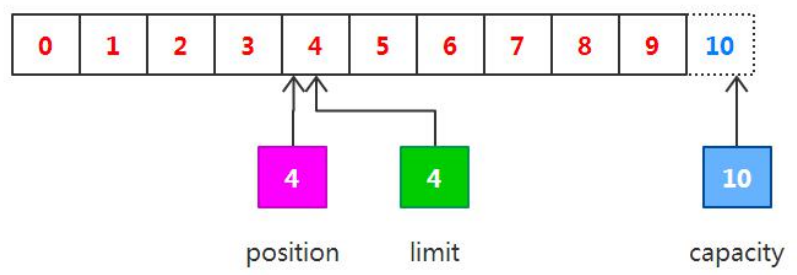
现在调用 get()方法从缓冲区中读取数据写入到输出通道,这会导致 position 的增加而 limit 保持不变,但 position 不 会超过 limit 的值,所以在读取我们之前写入到缓冲区中的 4 个自己之后,position 和 limit 的值都为 4,如下图所示:
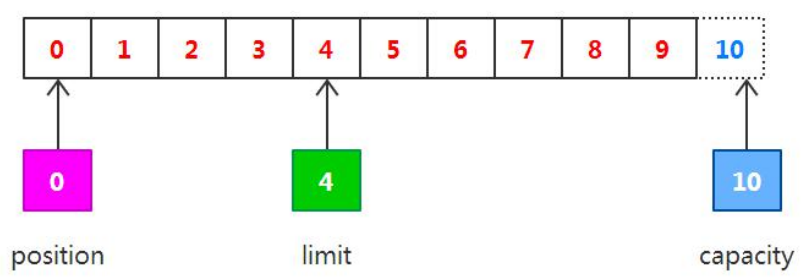
在从缓冲区中读取数据完毕后,limit 的值仍然保持在我们调用 flip()方法时的值,调用 clear()方法能够把所有的状态变 化设置为初始化时的值,如下图所示:
在创建一个缓冲区对象时,会调用静态方法 allocate()来指定缓冲区的容量,其实调用 allocate()相当于创建了一个指定大小的数组,并把它包装为缓冲区对象。或者我们也可以直接将一个现有的数组,包装为缓冲区对象,如下示例代码所示:public class BufferAllot { public void myMethod() { //方式1:分配指定大小的缓冲区,allocate方式直接分配,内部将隐含的创建一个数组 ByteBuffer allocate = ByteBuffer.allocate(10); //方式2:通过wrap对一个现有的数组进行包装,数据元素存在于数组中 byte[] bytes=new byte[10]; ByteBuffer wrap = ByteBuffer.wrap(bytes); //方式3:通过wrap根据一个已有的数组指定区间创建 ByteBuffer wrapoffset = ByteBuffer.wrap(bytes,2,5); } }
在 NIO 中,除了可以分配或者包装一个缓冲区对象外,还可以根据现有的缓冲区对象来创建一个子缓冲区,即在现有缓冲区上切 出一片来作为一个新的缓冲区,但现有的缓冲区与创建的子缓冲区在底层数组层面上是数据共享的,也就是说,子缓冲区相当于是 现有缓冲区的一个视图窗口。调用 slice()方法可以创建一个子缓冲区,让我们通过例子来看一下:public class BufferSlice { public static void main(String args[]) throws Exception{ ByteBuffer buffer = ByteBuffer.allocate(10); // 缓冲区中的数据 0-9 for (int i=0; i<buffer.capacity(); ++i) { buffer.put( (byte)i ); } // 创建子缓冲区 buffer.position(3); buffer.limit(7); ByteBuffer slice = buffer.slice(); // 改变子缓冲区的内容 for (int i=0; i<slice.capacity(); ++i) { byte b = slice.get( i ); b *= 10; slice.put( i, b ); } buffer.position( 0 ); buffer.limit( buffer.capacity() ); while (buffer.remaining()>0) { System.out.println( buffer.get() ); } } }
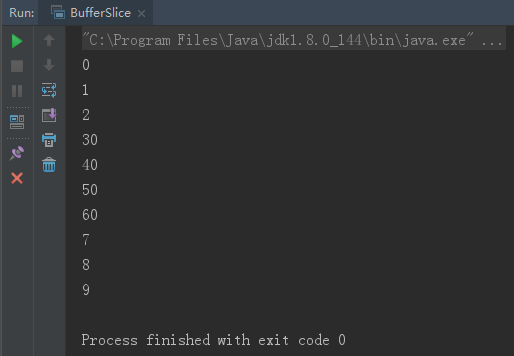
只读顾名思义就是只可以读取数据,不能写入数据。可以通过调用缓冲区的 asReadOnlyBuffer()方法,将任何常规缓 冲区转 换为只读缓冲区,这个方法返回一个与原缓冲区完全相同的缓冲区,并与原缓冲区共享数据,只不过它是只读的。如果原 缓冲区的内容发生了变化,只读缓冲区的内容也随之发生变化:public class ReadOnlyBuffer { public static void main(String args[]) throws Exception { ByteBuffer buffer = ByteBuffer.allocate(10); // 缓冲区中的数据 0-9 for (int i = 0; i < buffer.capacity(); ++i) { buffer.put((byte) i); } // 创建只读缓冲区 ByteBuffer readonly = buffer.asReadOnlyBuffer(); // 改变原缓冲区的内容 for (int i = 0; i < buffer.capacity(); ++i) { byte b = buffer.get(i); b *= 10; buffer.put(i, b); } readonly.position(0); readonly.limit(buffer.capacity()); // 只读缓冲区的内容也随之改变 while (readonly.remaining() > 0) { System.out.println(readonly.get()); } } }
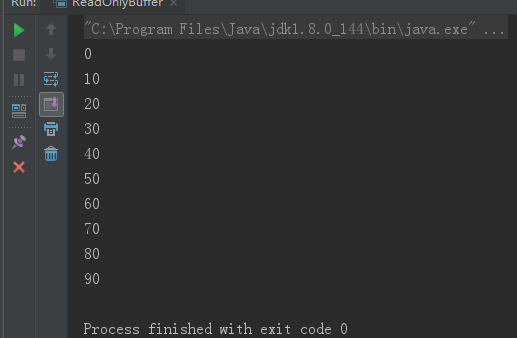
如果尝试修改只读缓冲区的内容,则会报 ReadOnlyBufferException 异常。只读缓冲区对于保护数据很有用。在将缓冲区传递给某 个 对象的方法时,无法知道这个方法是否会修改缓冲区中的数据。创建一个只读的缓冲区可以保证该缓冲区不会被修改。只可以 把常规缓冲区转换为只读缓冲区,而不能将只读的缓冲区转换为可写的缓冲区。
直接缓冲区通常是 I/O 操作最好的选择,它是为加快 I/O 速度,使用一种特殊方式为其分配内存的缓冲区。它支持 JVM 可用的最高效I/O机制。
通常非直接缓冲不可能成为一个本地 I/O 操作的目标。如果您向一个通道中传递一个非直接 ByteBuffer 对象用于写入,通道可能会在每次调用中隐含地创建一个临时的直接ByteBuffer对象,再将非直接缓冲区的内容拷贝到临时缓冲区中,使用临时缓冲区执行底层I/O操作,当临时缓冲区对象离开作用域的时候,会成为被回收的无用数据。这可能导致缓冲区在每个 I/O 上复制并产生大量对象,而这种事都是我们极力避免的。而直接缓冲区,JVM虚拟机将尽最大努力直接对它执行本机 I/O 操作。也就是说,它会在每一次调用底层操作系统的本机 I/O 操作之前(或之后),尝试避免将缓冲区的内容拷贝到一个中间缓冲区中或者从一个中间缓冲区中拷贝数据。要分配直接缓冲区,需要调用 allocateDirect() 方法,而不是 allocate()方法,使用方式与普通缓冲区并无区别,如下面的拷贝文件示例:public class DirectBuffer { public static void main(String args[]) throws Exception { //首先我们从磁盘上读取刚才我们写出的文件内容 String infile = "F://testio/test1.txt"; FileInputStream fin = new FileInputStream(infile); FileChannel fcin = fin.getChannel(); //把刚刚读取的内容写入到一个新的文件中 String outfile = String.format("F://testio/test2.txt"); FileOutputStream fout = new FileOutputStream(outfile); FileChannel fcout = fout.getChannel(); // 使用 allocateDirect,而不是 allocate ByteBuffer buffer = ByteBuffer.allocateDirect(1024); while (true) { buffer.clear(); int r = fcin.read(buffer); if (r == -1) { break; } buffer.flip(); fcout.write(buffer); } } }
映射缓冲区通常是直接存取内存的,只能通过 FileChannel 类创建。映射缓冲区的用法和直接缓冲区类似,但是 MappedByteBuffer 对象(大文件处理方面性能比较高)可以处理独立于文件存取形式的的许多特定字符。简单来说内存映射就是是一种读和写文件数据的方法,它可以比常规的基于流或者基于通道的 I/O 快的多。内存映射文件 I/O 是通过使文件中的 数据出现为 内存数组的内容来完成的,这其初听起来似乎不过就是将整个文件读到内存中,但是事实上并不是这样。一般来说, 只有文件中实际读取或者写入的部分才会映射到内存中。如下面的示例代码:public class MappedBuffer { private static final int start = 0; private static final int size = 1024; public static void main(String args[]) throws Exception { RandomAccessFile raf = new RandomAccessFile("F://testio/test.txt", "rw"); FileChannel fc = raf.getChannel(); //把缓冲区跟文件系统进行一个映射关联 //只要操作缓冲区里面的内容,文件内容也会跟着改变 MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, start, size); mbb.put(0, (byte) 97); mbb.put(1023, (byte) 122); raf.close(); } } 选择器(Selector)
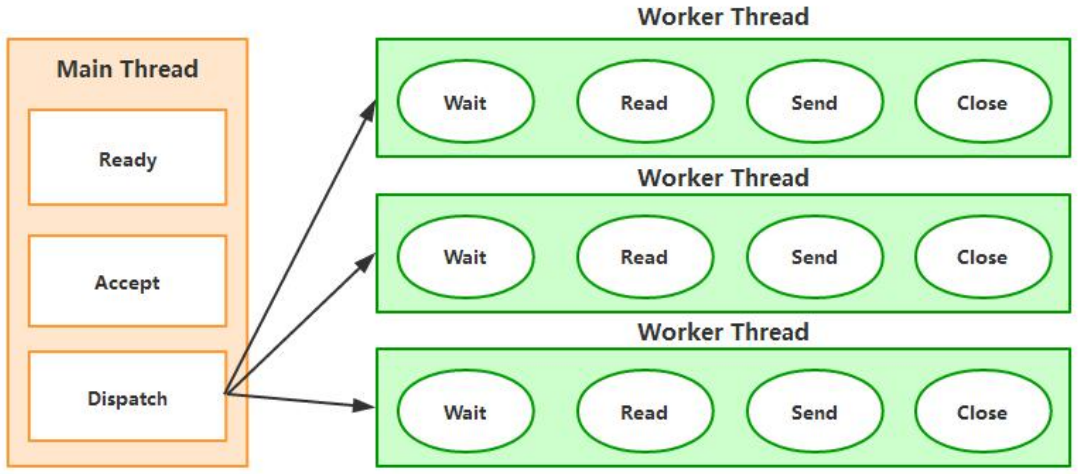
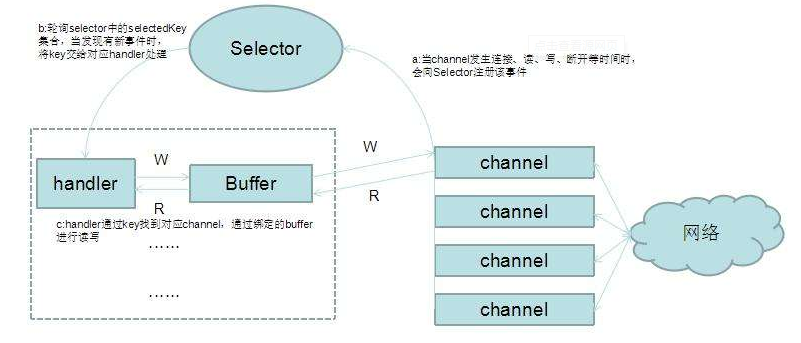
Selector做了什么?它是怎么做的?
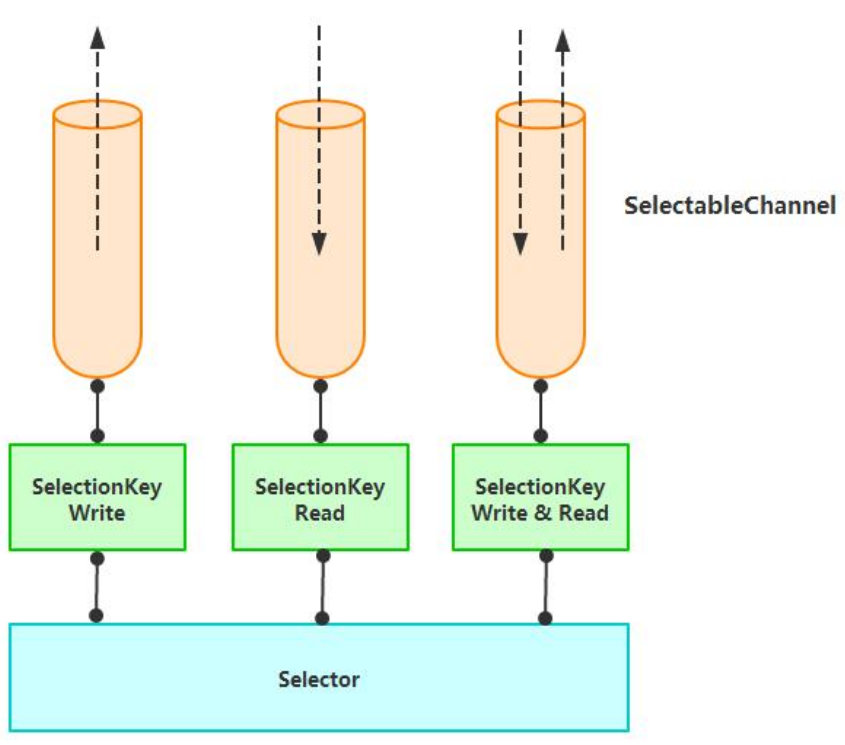
从图中可以看出,当有读或写等任何注册的事件发生时,可以从 Selector 中获得相应的 SelectionKey,同时从 SelectionKey 中可 以找到发生的事件和该事件所发生的具体的 SelectableChannel,以获得客户端发送过来的数据。
方式一: //通过调用静态工厂方法 open( )来实例化 Selector selector = Selector.open( ); 方式二: //通过调用一个自定义的 SelectorProvider对象的 openSelector( )方法来创建一个 Selector 实例 SelectorProvider provider = SelectorProvider.provider(); Selector abstractSelector = provider.openSelector(); public final SelectionKey register(Selector sel, int ops) public abstract class Selector { // This is a partial API listing //返回与选择器关联的已经注册的键的集合 public abstract Set keys( ); //返回已注册的键的集合的子集 public abstract Set selectedKeys( ); //执行就绪检查过程,在没有通道就绪时将无限阻塞 public abstract int select( ) throws IOException; //执行就绪检查过程,在限制时间内没有通道就绪时,它将返回 0 public abstract int select (long timeout) throws IOException; //执行就绪检查过程,但不阻塞。如果当前没有通道就绪,它将立即返回 0 public abstract int selectNow( ) throws IOException; //使线程从被阻塞的 select( )方法中退出 public abstract void wakeup( ); } protected Set<SelectionKey> selectedKeys = new HashSet(); protected HashSet<SelectionKey> keys = new HashSet(); private final Set<SelectionKey> cancelledKeys = new HashSet<SelectionKey>(); 通道(Channel)
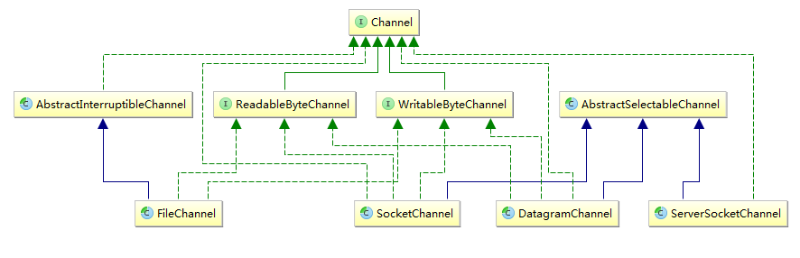
为了保证尽可能清晰的显示我们关注的点,图中只显示了我们关心的Channel。
public class FileInputDemo { public static void main(String[] args) throws Exception { FileInputStream fin = new FileInputStream("F://testio/test.txt"); // 获取通道 FileChannel fc = fin.getChannel(); // 创建缓冲区 ByteBuffer buffer = ByteBuffer.allocate(1024); // 读取数据到缓冲区 fc.read(buffer); buffer.flip(); while (buffer.remaining() > 0) { byte b = buffer.get(); System.out.print(((char) b)); } fin.close(); } } public class FileOutputDemo { private static final byte message[] = {83, 111, 109, 101, 32, 98, 121, 116, 101, 115, 46}; public static void main(String[] args) throws Exception { FileOutputStream fout = new FileOutputStream("F://testio/test.txt"); FileChannel fc = fout.getChannel(); ByteBuffer buffer = ByteBuffer.allocate(1024); for (int i = 0; i < message.length; ++i) { buffer.put(message[i]); } buffer.flip(); fc.write(buffer); fout.close(); } } 实现一个单线程NIO
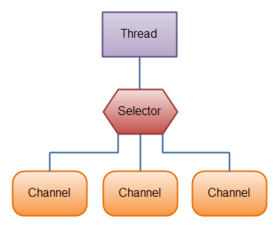
流程图:
服务端代码://同步非阻塞IO模型---NIO服务端(单线程模式) public class NIOServer { //服务端端口号 private int port = 9999; //首先准备两个东西,一个缓冲区(等待大厅),一个轮询器(叫号员)。 //缓冲区,从堆内存分配一个1024大小容量的byte数组作为数据缓冲区(数据存储器) private ByteBuffer buffer = ByteBuffer.allocate(1024); //轮询器(选择器),用于检查一个或多个NIO Channel(通道)的状态是否处于可读、可写 private Selector selector; //创建NIO服务端,port为服务端端口号 public NIOServer(int port){ try { this.port = port; //创建监听TCP链接的通道并打开,类似BIO中的ServerSocket ServerSocketChannel serverSocketChannel = ServerSocketChannel.open(); //为通道绑定端口,告诉客户端创建通道的端口(InetSocketAddress类主要作用是封装端口) serverSocketChannel.socket().bind(new InetSocketAddress("localhost",this.port)); //采用非阻塞模式,NIO是BIO的升级版本,为了兼容BIO,NIO默认采用阻塞模式 serverSocketChannel.configureBlocking(false); //打开轮询器(叫号员上岗准备叫号),用于检查一个或多个NIO Channel(通道)的状态是否处于可读、可写等 selector = Selector.open(); // //将服务端的通道channel注册到选择器selector上并为选择器设置关心事件(通过Selector监听Channel时对什么事件感兴趣) //SelectionKey.OP_ACCEPT —— 接收连接继续事件,表示服务器监听到了客户连接,服务器可以接收这个连接了 //SelectionKey.OP_CONNECT —— 连接就绪事件,表示客户与服务器的连接已经建立成功 //SelectionKey.OP_READ —— 读就绪事件,表示通道中已经有了可读的数据,可以执行读操作了(通道目前有数据,可以进行读操作了) //SelectionKey.OP_WRITE —— 写就绪事件,表示已经可以向通道写数据了(通道目前可以用于写操作) serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT); }catch (IOException e){ e.printStackTrace(); } } //创建监听,对接收到客户端的数据进行处理 public void listen(){ System.out.println("NIOServer has started,listening on port:" + this.port); try { //轮询主线程 while (true){ //选择已经准备就绪的通道(叫号员开始叫号) //select()方法返回的int值表示有多少通道已经就绪,是自上次调用select()方法后有多少通道变成就绪状态。 //***阻塞点***------至少有一个事件发生 ,否则会阻塞 int wait = selector.select(); if (wait == 0){ continue; } //一旦调用select()方法,并且返回值不为0时,则可以通过调用Selector的selectedKeys()方法来访问已选择键集合 //将所有准备就绪的连接存起来 Set<SelectionKey> selectionKeys = selector.selectedKeys(); //创建迭代器,不断迭代,就叫做轮询(在每次为通道注册选择器时都会创建一个SelectionKey) //SelectionKey键表示了一个特定的通道对象和一个特定的选择器对象之间的注册关系 Iterator<SelectionKey> iter = selectionKeys.iterator(); //同步就体现在这里,因为每一次轮询只能拿一个key,所以每一次只能处理一种状态 while (iter.hasNext()){ //每一个key代表一种状态(每一个号对应一种业务),数据就绪、数据可读、数据可写等 SelectionKey key = iter.next(); //每一次轮询调用一次proess方法,每次调用只做一件事,同一个时间点只能做一件事 proess(key); iter.remove(); } } }catch (IOException e){ e.printStackTrace(); } } //对数据具体的处理方法(柜台人员开始处理叫到号的人的业务) //SelectionKey键表示了一个特定的通道对象和一个特定的选择器对象之间的注册关系 private void proess(SelectionKey key) throws IOException{ RequestHandler requestHandler = new RequestHandler(); //针对每一种状态做出相应的反应 if (key.isAcceptable()){//是否可接收 System.out.println("进入连接判断"); //通过SelectionKey对象获取其监听的ServerSocketChannel通道 ServerSocketChannel serverSocketChannel = (ServerSocketChannel) key.channel(); //这里提现非阻塞,不管数据有没有准备好,都会有一个状态的反馈 //在 ServerSocketChannel 上调用 accept( )方法则会返回 SocketChannel 类型的对象,返回的对象能够在非阻塞模式下运行 SocketChannel clientChannel = serverSocketChannel.accept(); System.out.println("Connection from:" + clientChannel.getRemoteAddress()); //这里一定要设置非阻塞 clientChannel.configureBlocking(false); //可接收数据时,将选择器关心事件改为可读 clientChannel.register(selector,SelectionKey.OP_READ); }else if (key.isReadable()){//是否可读 //从多路复用器(选择器/轮询器)中拿到客户端的引用,返回该SelectionKey对应的channel SocketChannel clientChannel = (SocketChannel) key.channel(); //读取通道中一定数量的字节并存入缓冲区数组buffer中,以整数形式返回实际读取的字节数 int len = clientChannel.read(buffer); if (len > 0){ //buffer.flip();一定得有,如果没有,就是从文件最后开始读取的,当然读出来的都是byte=0时候的字符。 //通过buffer.flip();这个语句,就能把buffer的当前位置更改为buffer缓冲区的第一个位置 buffer.flip(); String clientScannerData = new String(buffer.array(),0,len); //可读数据时,将选择器关心事件改为可写 clientChannel.register(selector,SelectionKey.OP_WRITE); //将一个对象或者更多的信息附着到SelectionKey上,这样就能方便的识别某个给定的通道 key.attach(clientScannerData); System.out.println("Client data:" + clientScannerData + "---Client address: " + clientChannel.getRemoteAddress()); } }else if (key.isWritable()){//是否可写 SocketChannel clientChannel = (SocketChannel)key.channel(); //获取数据 String clientScannerData = (String) key.attachment(); //将缓冲区中的数据存放在byte数组中,数组和缓冲区中任意一方的数据改动都会影响另外一方,然后将数据写入通道 clientChannel.write(ByteBuffer.wrap((requestHandler.hendler(clientScannerData)).getBytes())); clientChannel.close(); } } public static void main(String[] args) { new NIOServer(9999).listen(); } } 优化线程模型
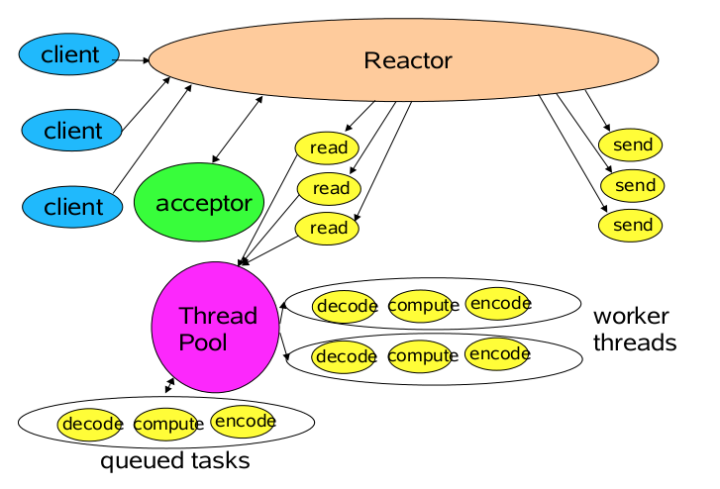
注:每个线程的处理流程大概都是读取数据、解码、计算处理、编码、发送响应。NIO高级主题—Proactor与Reactor
二者的差异(以读操作为例)
如果你对Reactor模型和Proactor模型比较感兴趣,可以点击彻底搞懂Reactor模型和Proactor模型,这里不再做过多解释。NIO给我们来了什么
NIO存在的问题
AIO锦上添花
AIO简介
AIO基本原理
AIO初体验
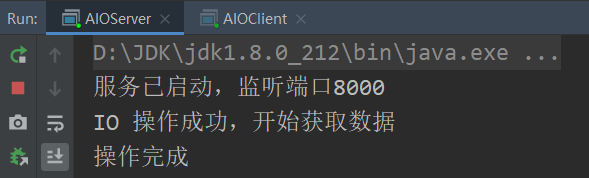
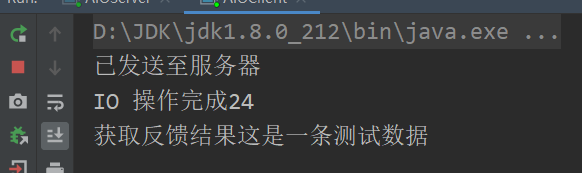
public class AIOServer { private final int port; public AIOServer(int port) { this.port = port; listen(); } private void listen() { try { ExecutorService executorService = Executors.newCachedThreadPool(); AsynchronousChannelGroup threadGroup = AsynchronousChannelGroup.withCachedThreadPool(executorService, 1); final AsynchronousServerSocketChannel server = AsynchronousServerSocketChannel.open(threadGroup); server.bind(new InetSocketAddress(port)); System.out.println("服务已启动,监听端口" + port); server.accept(null, new CompletionHandler<AsynchronousSocketChannel, Object>() { final ByteBuffer buffer = ByteBuffer.allocateDirect(1024); public void completed(AsynchronousSocketChannel result, Object attachment) { System.out.println("IO 操作成功,开始获取数据"); try { buffer.clear(); result.read(buffer).get(); buffer.flip(); result.write(buffer); buffer.flip(); } catch (Exception e) { System.out.println(e.toString()); } finally { try { result.close(); server.accept(null, this); } catch (Exception e) { System.out.println(e.toString()); } } System.out.println("操作完成"); } @Override public void failed(Throwable exc, Object attachment) { System.out.println("IO 操作是失败: " + exc); } }); try { Thread.sleep(Integer.MAX_VALUE); } catch (InterruptedException ex) { System.out.println(ex); } } catch (IOException e) { System.out.println(e); } } public static void main(String args[]) { int port = 8000; new AIOServer(port); } } public class AIOClient { private final AsynchronousSocketChannel client; public AIOClient() throws Exception { client = AsynchronousSocketChannel.open(); } public void connect(String host, int port) throws Exception { client.connect(new InetSocketAddress(host, port), null, new CompletionHandler<Void, Void>() { @Override public void completed(Void result, Void attachment) { try { client.write(ByteBuffer.wrap("这是一条测试数据".getBytes())).get(); System.out.println("已发送至服务器"); } catch (Exception ex) { ex.printStackTrace(); } } @Override public void failed(Throwable exc, Void attachment) { exc.printStackTrace(); } }); final ByteBuffer bb = ByteBuffer.allocate(1024); client.read(bb, null, new CompletionHandler<Integer, Object>() { @Override public void completed(Integer result, Object attachment) { System.out.println("IO 操作完成" + result); System.out.println("获取反馈结果" + new String(bb.array())); } @Override public void failed(Throwable exc, Object attachment) { exc.printStackTrace(); } } ); try { Thread.sleep(Integer.MAX_VALUE); } catch (InterruptedException ex) { System.out.println(ex); } } public static void main(String args[]) throws Exception { new AIOClient().connect("localhost", 8000); } }
客户端:
因为平时AIO用的并不多 ,所以这里就不详细讲解了,如果有小伙伴对AIO感兴趣,可以点击这里AIO基础各IO模型对比总结
BIO 与 NIO 对比
IO模型
BIO
NIO
通信
面向流(乡村公路)
面向缓冲(高速公路,多路复用技术)
处理
阻塞 IO(多线程)
非阻塞 IO(反应堆 Reactor)
触发
无
选择器(轮询机制)
最后来一张总结对比表
属性
同步阻塞 IO(BIO)
伪异步 IO
非阻塞 IO(NIO)
异步 IO(AIO)
客户端数:IO 线程数
1:1
M:N(M>=N)
M:1
M:0
阻塞类型
阻塞
阻塞
非阻塞
非阻塞
同步
同步
同步
同步(多路复用)
异步
API 使用难度
简单
简单
复杂
一般
调试难度
简单
简单
复杂
复杂
可靠性
非常差
差
高
高
吞吐量
低
中
高
高
结束语
这篇文章也是本人在ImapBox上面发表的第一篇博客,曾经一直想做,现在终于付诸于行动了。这篇文章虽然算不上是一篇优秀的文章,但是它也算对我这一个多星期学习网络IO的一个小小的总结,更是这段时间熬夜奋战的心血。文章中如果有不足或错误之处,还请小伙伴们指出,忘海涵。
最后送大家三个词:练习、用心、坚持!追梦人们,加油!
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)


