目录 累加器accumulators:累加器支持在所有不同节点之间进行累加计算 在每个机器上缓存一份、不可变的、只读的、相同的变量,该节点每个任务都能访问。起到节省资源和优化的作用。 用于处理结构化数据的Spark模块。 DataFrame和DataSet Hive和SparkSQL的对比 Hive是将sql转化成MapReduce进行计算(降低学习成本、提高开发效率) SparkSQL是将sql转化成rdd集进行计算(降低学习成本、提高开发效率) DataFrame是以RDD为基础的带有Schema元信息的分布式数据集。 含有类型信息的DataFrame就是DataSet (DataSaet=DataFrame+类型= Schema+RDD*n+类型) personDF.select($”id”,$”name”,$”age”+1).filter($”age”>25).show spark.sql(“select * from personDFT where age >25”).show 第1种:指定列名添加Schema 第2种:通过StructType指定Schema 第3种:编写样例类,利用反射机制推断Schema 指定列名添加Schema代码流程 1 创建sparksession 2 创建sc 3 读取数据并加工 4 设置表结构 ttRDD.toDF(“id”,”name”,”age”) 5 注册成表并查询 6 关闭sc sparksession 1 创建sparksession 2 创建sc 3 读取数据并加工 4 设置表结构 types.StructType( 5 创建DS DF val ttDF: DataFrame = spark.createDataFrame(RowRDD,structTable) 6 注册成表并查询 准备样例类 1 创建sparksession 3 读取数据并加工 5 注册成表并查询 6 关闭sc sparksession
累加器的作用
广播变量的作用
SparkSQL基本介绍
什么是SparkSQL?
SparkSQL底层的数据抽象
什么是DataFrame??
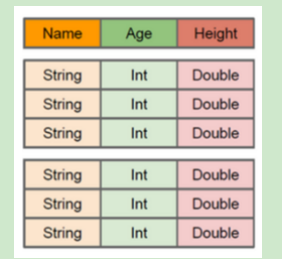
什么是DataSet??
SparkSQL查询数据的形态
添加Schema的方式
通过StructType指定Schema代码流程
// 字段类型 (字段名,字段类型,是否为空)
List(StructField(“id”,IntegerType,true)
)
)
7 关闭sc sparksession利用反射机制推断Schema代码流程
2 创建sc
val PersonRDD: RDD[Person] = ttRDD.map(z=>Person(z(0).toInt,z(1),z(2).toInt))
4 RDD转DF
val personDF: DataFrame = PersonRDD.toDF()
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)
