什么是spark? spark运行架构 SparkContext:整个应用的上下文,spark的主入口,连接Driver与Spark Cluster(Workers)每个JVM仅能有一个活跃的SparkContext Spark特有资源调度系统的Leader。掌管着整个集群的资源信息,类似于Yarn框架中的ResourceManager,主要功能: Spark特有资源调度系统的Slave,有多个。每个Slave掌管着所在节点的资源信息,类似于Yarn框架中的NodeManager,主要功能: Spark的驱动器是执行开发程序中的main方法的进程。它负责开发人员编写的用来创建SparkContext、创建RDD,以及进行RDD的转化操作和行动操作代码的执行。如果你是用spark shell,那么当你启动Spark shell的时候,系统后台自启了一个Spark驱动器程序,就是在Spark shell中预加载的一个叫作 sc的SparkContext对象。如果驱动器程序终止,那么Spark应用也就结束了。主要负责: Spark Executor是一个工作进程,负责在 Spark 作业中运行任务,任务间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。主要负责: Local模式就是运行在一台计算机上模式,通常就是用于本机上的测试。 构建一个基于 Mster+Slaves 的资源调度集群,Spark 任务提交给 Master运行。是 Spark 自身的一个调度系统。 Spark客户端直接连接Yarn,不需要额外构建Spark集群。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
文章目录
一、Spark架构
Sprak是基于内存的快速、通用、可拓展的大数据分析引擎1、Spark 内置模块
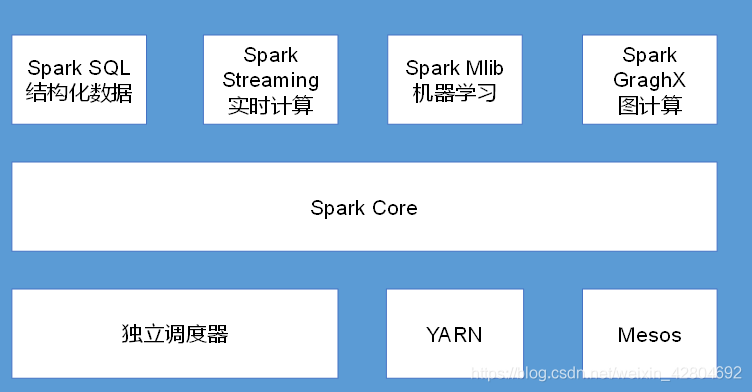
Spark Core: 实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
Spark SQL: 是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
Spark Streaming: 是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API。
Spark MLlib: 提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等
集群管理器: Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度 器,叫作独立调度器。
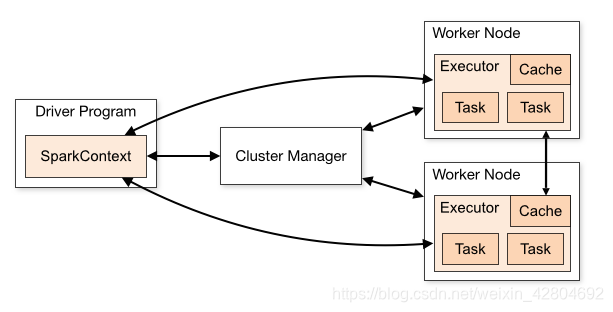
Cluster Manager:节点管理器,把算子(rdd)发送给WorkNode
WorkNode:从节点,负责控制计算节点,启动Executor或者Driver
Cache:workNode之间共享信息,通信
Executor:执行器为应用程序提供分布式计算以及数据存储功能
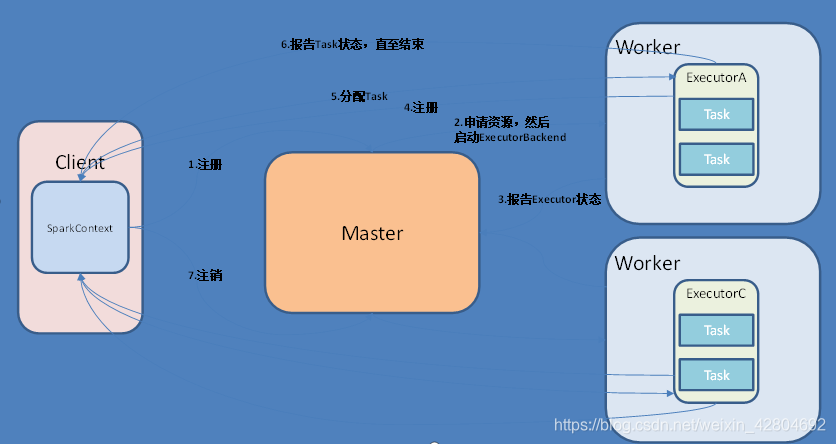
task:任务(core数,一次运行的task) 1)Master
(1)监听Worker,看Worker是否正常工作;
(2)Master对Worker、Application等的管理(接收worker的注册并管理所有的worker,接收client提交的application,(FIFO)调度等待的application并向worker提交)。 2)Worker
(1)通过RegisterWorker注册到Master;
(2)定时发送心跳给Master;
(3)根据master发送的application配置进程环境,并启动StandaloneExecutorBackend(执行Task所需的临时进程) 1)Driver(驱动器)
(1)把用户程序转为任务
(2)跟踪Executor的运行状况
(3)为执行器节点调度任务
(4)UI展示应用运行状况 2)Executor(执行器)
(1)负责运行组成 Spark 应用的任务,并将状态信息返回给驱动器进程;
(2)通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
总结:Master和Worker是Spark的守护进程,即Spark在特定模式下正常运行所必须的进程。Driver和Executor是临时进程,当有具体任务提交到Spark集群才会开启的进程。

2、运行流程
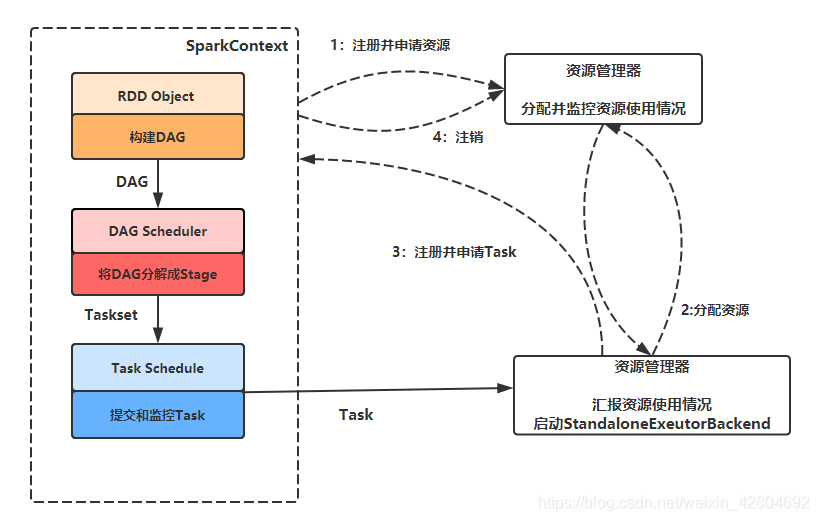
1.构建Spark Application的运行环境,启动SparkContext 2.SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动StandaloneExecutorbackend 3.Executor向SparkContext申请Task 4.SparkContext将应用程序分发给Executor 5.SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task 6.Scheduler将Task发送给Executor运行 Task在Executor上运行,运行完释放所有资源 二、Spark的运行模式
1、Local模式
Local[N]:指定使用几个线程来运行计算,通常我们CPU有几个Core,就指几个线程,最大化利用Cpu计算能力。
local[*]:直接安装Cpu最多Core来设置线程数2、Standalone模式
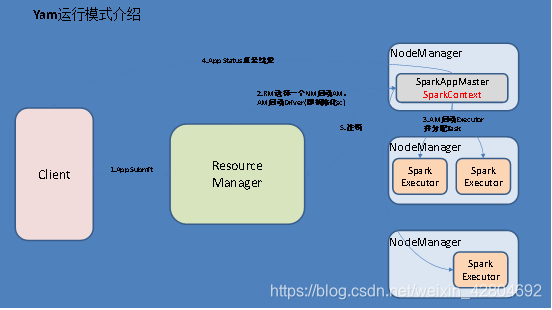
3、Yarn模式
yarn-client: Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
yarn-cluster: Driver程序运行在由RM(ResourceManager)启动的AM(APPMaster)适用于生产环境。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)

