作为一个男孩子,你会受得了一群大眼萌妹对着你日式问侯,搭配主人般的服务?? 没错,4月17日,B站首发《公主连结》这款游戏,已经火爆了!通过我的初步了解,这是一款轻度卖萌,剧情类,然后抽卡刷图的网页游戏,也有人也说这是一款猛男专属游戏,因为他的画工完全是符合成人的思想构造的,由于整体呈现二次元风格,已经在B站开始走火起来,那我们就从这个萌游中挖掘点宝藏出来吧! 其他渠道平台的下载评分也均在八分以上,这对于一个新款手游来说相当了不起了! 要想评价一个新款游戏,常规的从画质,美工,手感这些方向开始入手,但是我们作为程序员,这些常规操作我们根本不屑,要做就得做大的,才能体现我们的逼格对吧,这里用到一点点爬虫知识,还有plt和一点wordcloud知识,但是不要担心,我很详细的! 因为我的爬虫还在学习中,有些地方不能解释的很清楚,还请各位见谅见谅! 那下面我们开始吧! 这个我觉得难度系数是最低的嘻嘻,先放一张图压压惊: 代码如下: 这里使用到字典功能,具体的我们看代码: 效果图: 这有一点出乎意料呀,果然公主焊接才是猛男爱的游戏! 很不好意思,程序到这里,突然bug了,我爬虫也不是很好,也不知道发生了什么,我找了好久,还是找不到程序到底出错在哪里了,所以后面我打算换一种方式继续下去,真的很抱歉!但是我还是想把文章写下去的, 那我们就自己生成一下词汇,总要达到我要的结果 代码: 效果图: 一下子知识体系跨越的让我很晕,通过这次我感觉到了自己的能力还是欠缺,不管怎么说,加油吧!
游戏界面:

整体界面都是那种很二次元风格,包括里面的角色也是,都是女性角色,完全的满足了猛男的种种幻想,据我了解,到现在开服不到一周的时间内,各渠道下载量已经快三百多万了,这对于一个新款游戏流量打造已经很不错了。
B站下载得分:
python骚操作:

下面是我打算做的步骤:
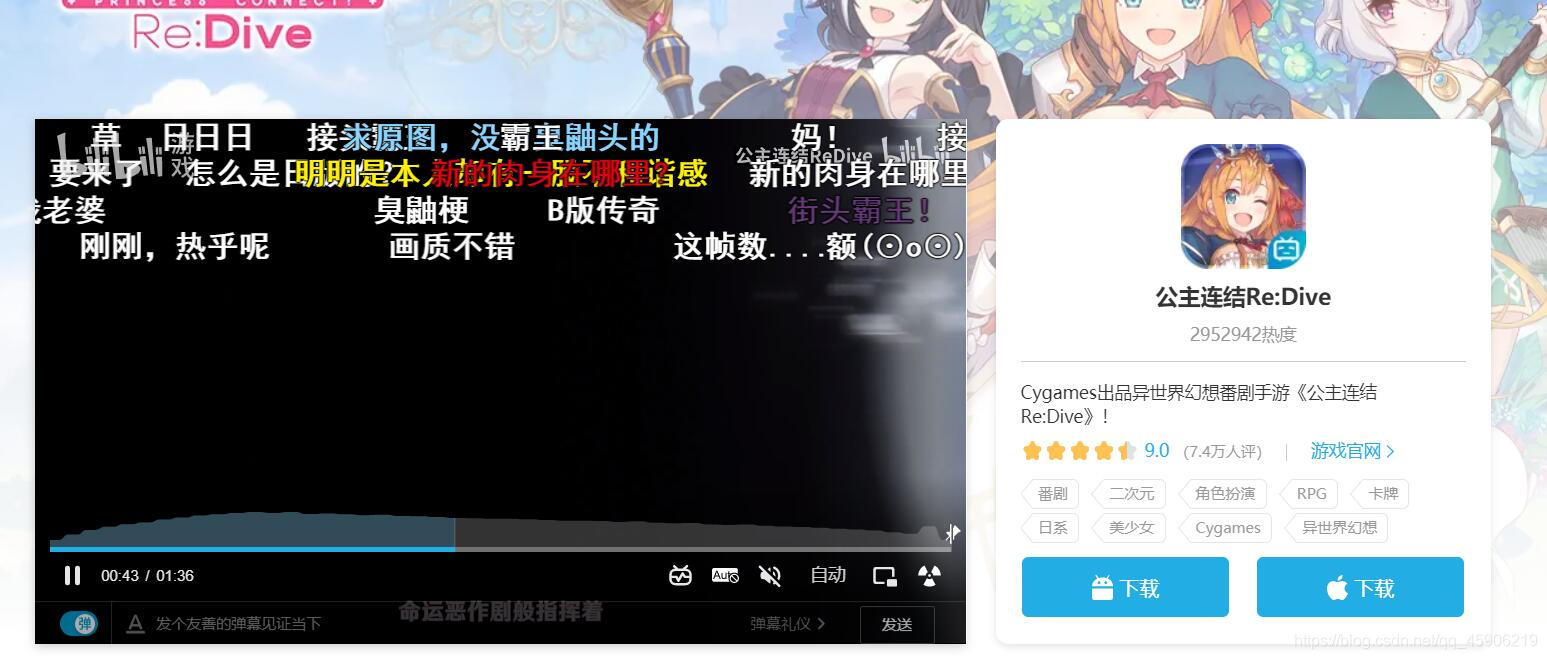
抓取高清壁纸:

import requests import os def get_img(): # 抓取图片 url = 'https://static.biligame.com/pcr/gw/pc/images/p6/op/' # 网址相同的部分 girl_url = [] for i in range(1, 30): # 假设抓取三十个文件 s = url + str(i) + '.jpg' girl_url.append(s) # 拼接网址,然后装入列表 path = 'D://公主连结壁纸//' if not os.path.exists(path): # 如果path不存在 os.mkdir(path) # 创建path os.chdir(path) # 进入path else: os.chdir(path) for j, k in enumerate(girl_url): r = requests.get(k) if r.status_code == 200: # 如果请求正常 那我们就下载它 with open('girl' + str(j) + '.jpg', 'wb') as fw: fw.write(r.content) else: print('壁纸数量不足!') break
抓取B站下载评论:
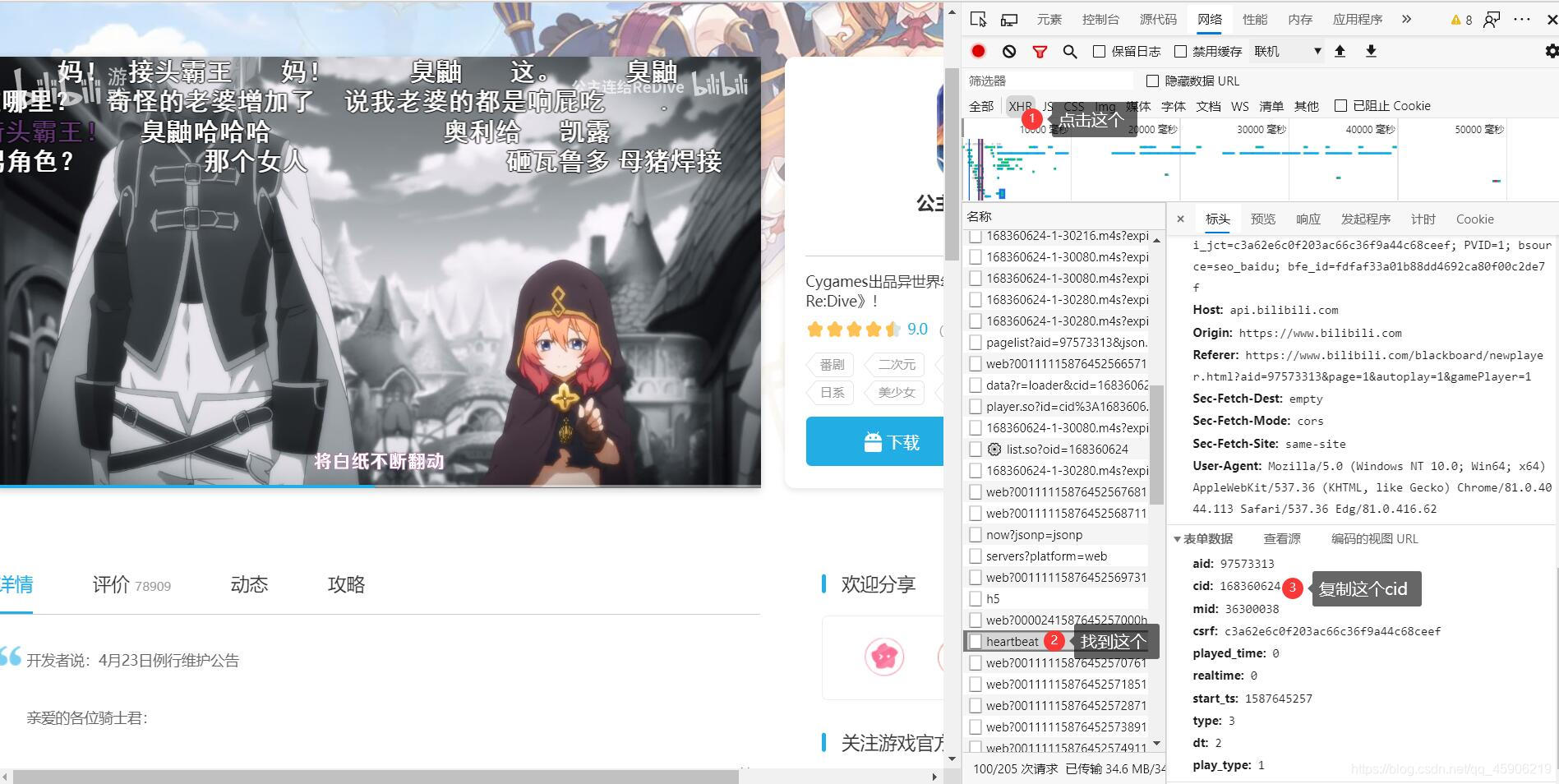
在这里把复制好的cid加入,那我们就得到这样的网页:

import requests from bs4 import BeautifulSoup def get_data(girl_url): # 获得中文词汇 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36 Edg/81.0.416.58'} # 这里加一个请求头 r = requests.get(girl_url, headers=headers) # 获得网页 r.encoding = r.apparent_encoding # 转码 soup = BeautifulSoup(r.text, 'html.parser') # 解析库 d = soup.find_all('d') # 获得含有d标签 d_text = [i.text for i in d] # 获得所有的中文词汇 d_text = [i.replace(' ', '') for i in d_text] # 去除空格 return d_text
统计高频词汇:
def get_item(girl_text): # 统计高频词汇 counts = {} # 设置一个字典 for i in girl_text: counts[i] = counts.get(i, 0) + 1 # 存在就给值,不存在就给0,然后加1 item = list(counts.items()) # 列表 item.sort(key=lambda x: x[1], reverse=True) # 正序 for i in range(10): # 打印前十个 girl_data, girl_count = item[i] print(girl_data, girl_count) return item[:10]

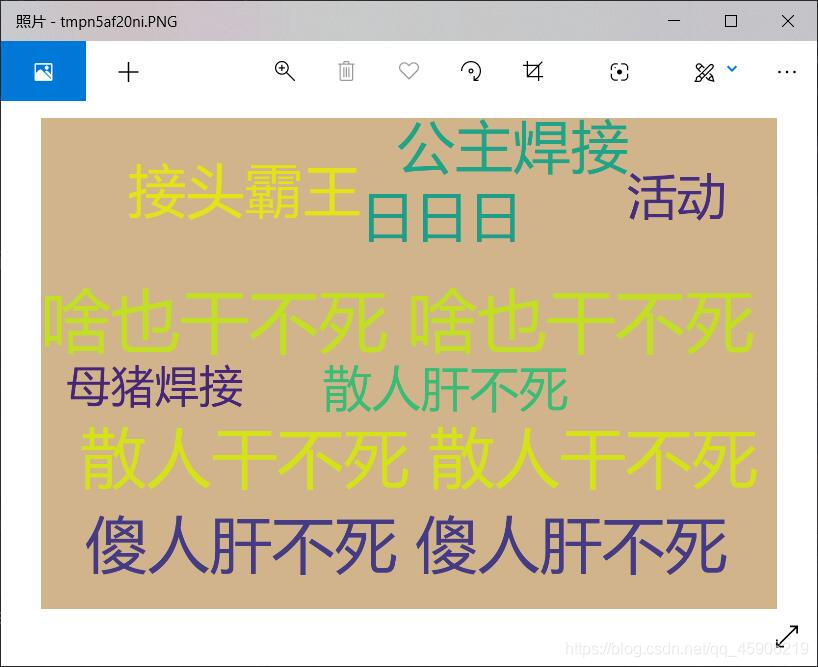
生成高频词云:
pip install wordcloud 
import wordcloud from PIL import Image def make_wordcloud(): # 制作词云 item = [('啥也干不死', 11), ('散人干不死', 10), ('傻人肝不死', 9), ('接头霸王', 7), ('公主焊接', 7), ('妈!', 6), ('日日日', 6), ('活动', 5), ('散人肝不死', 5), ('母猪焊接', 4)] word = [] # 存放总的词汇 for i in range(len(item)): # 长度 girl_data, girl_count = item[i] s = [girl_data for i in range(girl_count)] word.append(s) # 获得总词汇 # 下面制作词云 t = sum(word, []) # 使用sum方式把二维变成一维 t = ' '.join(t) twc = wordcloud.WordCloud(background_color='Tan', width=1500, height=1000, font_path="msyh.ttc") twc.generate(t) # 生成词云 twc.to_file('girl.png') a = Image.open('girl.png') a.show()
后记:
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)

