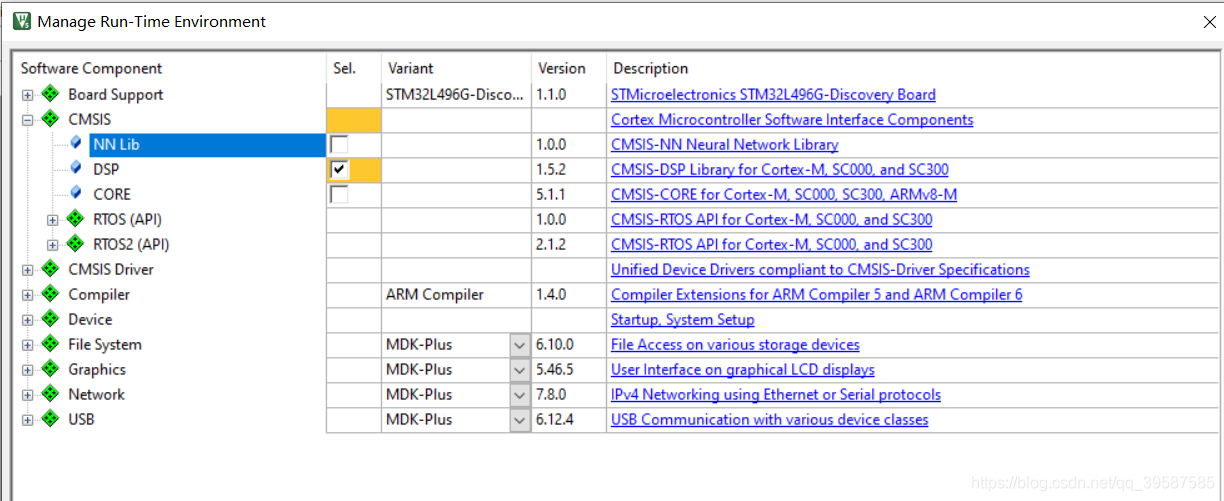
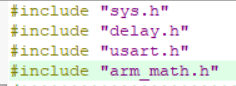
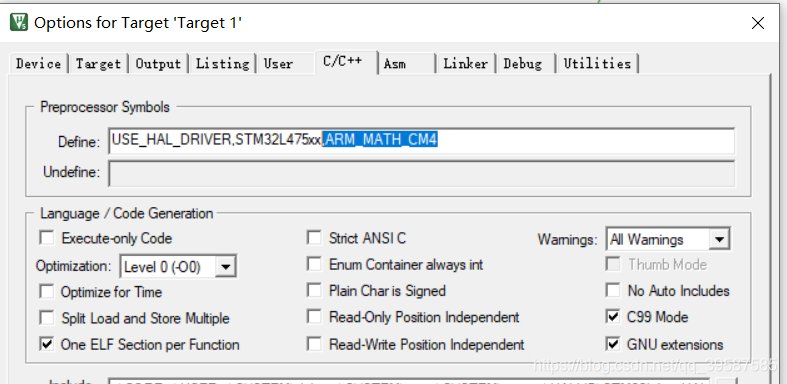
我们在嵌入式上跑矩阵运算时候,会遇到这样一个问题。 假设将矩阵设置成N*N维的二维数组后,我们想求两个矩阵相乘,那就需要按照矩阵计算规则编写矩阵相乘函数,这样的话4*4矩阵得编一个,5*5矩阵又得编一个,要求逆还得编一个,求行列式还得编。 自己写的函数代码效率容易低,将导致本来要跑在单片机上的算法,难达到想象计算速度。 这篇教程将教会你如何使用arm内核库的矩阵计算函数,让你降低代码编写难度还能提高运算效率。据笔者所知,M4内核自带DSP库。 1.创建新模板工程(这里使用的是keil创建工程) 创建一个对应MCU的新模板工程(添加必要的库引用和创建.C文件,详情略) 2.引入arm内核的DSP库文件(含矩阵计算库) 勾选CMSIS下的DSP,确认后将添加库引用至工程 3.添加矩阵函数库 在main函数添加引用,”arm_math.h” 还需在”option of target”中”C/C++”中的define栏添加“,ARM_MATH_CM4”以声明开启arm_math库 再到”option of target”中”target”勾选一下”Use MicroLIB” 4.矩阵计算 //声明大小为NN的浮点一维数组NN=N*N,此处将矩阵转换成一维数组 float32_t Data1[NN] = {}; float32_t Data2[NN] = {}; float32_t Data3[NN]; //声明ARM矩阵类型指针 arm_matrix_instance_f32 Matrix_data1;//再设立 arm_matrix_instance_f32 Matrix_data2; arm_matrix_instance_f32 Matrix_data3; //将一维数组地址赋予给ARM矩阵指针 arm_mat_init_f32(&Matrix_data1,N,N,(float32_t *)Data1); arm_mat_init_f32(&Matrix_data2,N,N,(float32_t *)Data2); arm_mat_init_f32(&Matrix_data3,N,N,(float32_t *)Data3); //使用矩阵相乘函数arm_mat_mult_f32 arm_mat_mult_f32(&Matrix_data1,&Matrix_data2,&Matrix_data3); 总结分析 在ARM内核的单片机中, ARM提供了矩阵运算库”arm_math”。在设置好库引用后,需存入用一维数组表示的矩阵值,再将矩阵的一维数组传递给ARM_matrix的指针,在声明函数中将设置矩阵的行列数,再调用库中的各类运算指令就可。 Ps:在本人stm32单片机上测试,arm自带函数只能计算至16维以内(不含16维)的矩阵计算,大于等于16维矩阵单片机编译没报错,但单片机不正常运行。小编水平有限这个存在疑惑,欢迎大佬们交流。 附图 经测试80M的系统时钟下,两个15维矩阵相乘时间约430us,两个4维矩阵相乘时间仅需14us,这计算速度还是很让人满意的。 附上代码(注释部分为arm官方例程,包括相乘求逆求行列式)

#include "sys.h" #include "delay.h" #include "usart.h" #include "arm_math.h" #include<stdio.h> #include<stdlib.h> #define N 4 #define NN 16 float32_t a = 100; float32_t Data1[NN] = {}; float32_t Data2[NN] = {}; float32_t Data3[NN]; arm_matrix_instance_f32 Matrix_data1; arm_matrix_instance_f32 Matrix_data2; arm_matrix_instance_f32 Matrix_data3; //const float32_t B_f32[4] = //{ // 782.0, 7577.0, 470.0, 4505.0 //}; ///* -------------------------------------------------------------------------------- //* Formula to fit is C1 + C2 * numTaps + C3 * blockSize + C4 * numTaps * blockSize //* -------------------------------------------------------------------------------- */ //const float32_t A_f32[16] = //{ // /* Const, numTaps, blockSize, numTaps*blockSize */ // 1.0, 32.0, 4.0, 128.0, // 1.0, 32.0, 64.0, 2048.0, // 1.0, 16.0, 4.0, 64.0, // 1.0, 16.0, 64.0, 1024.0, //}; ///* ---------------------------------------------------------------------- //* Temporary buffers for storing intermediate values //* ------------------------------------------------------------------- */ ///* Transpose of A Buffer */ //float32_t AT_f32[16]; ///* (Transpose of A * A) Buffer */ //float32_t ATMA_f32[16]; ///* Inverse(Transpose of A * A) Buffer */ //float32_t ATMAI_f32[16]; ///* Test Output Buffer */ //float32_t X_f32[4]; ///* ---------------------------------------------------------------------- //* Reference ouput buffer C1, C2, C3 and C4 taken from MATLAB //* ------------------------------------------------------------------- */ //const float32_t xRef_f32[4] = {73.0, 8.0, 21.25, 2.875}; //float32_t snr; int i = 0,t = 0,j = 0; int main(void) { HAL_Init(); //初始化HAL库 SystemClock_Config(); //初始化系统时钟为80M __HAL_RCC_GPIOE_CLK_ENABLE(); //开启GPIOE时钟 uart_init(115200); //初始化串口,速率为115200 while(1) { for(i=0;i<NN;i++) Data1[i]=rand()/(double)(RAND_MAX/100); for(i=0;i<NN;i++) Data2[i]=rand()/(double)(RAND_MAX/100); arm_mat_init_f32(&Matrix_data1,N,N,(float32_t *)Data1); arm_mat_init_f32(&Matrix_data2,N,N,(float32_t *)Data2); arm_mat_init_f32(&Matrix_data3,N,N,(float32_t *)Data3); arm_mat_mult_f32(&Matrix_data1,&Matrix_data2,&Matrix_data3); for(i=0;i<N;i++) { for(j=0;j<N;j++) printf("%f ",Data3[i*N+j]); printf("rn"); } // arm_matrix_instance_f32 A; /* Matrix A Instance */ // arm_matrix_instance_f32 AT; /* Matrix AT(A transpose) instance */ // arm_matrix_instance_f32 ATMA; /* Matrix ATMA( AT multiply with A) instance */ // arm_matrix_instance_f32 ATMAI; /* Matrix ATMAI(Inverse of ATMA) instance */ // arm_matrix_instance_f32 B; /* Matrix B instance */ // arm_matrix_instance_f32 X; /* Matrix X(Unknown Matrix) instance */ // uint32_t srcRows, srcColumns; /* Temporary variables */ // arm_status status; // /* Initialise A Matrix Instance with numRows, numCols and data array(A_f32) */ // srcRows = 4; // srcColumns = 4; // arm_mat_init_f32(&A, srcRows, srcColumns, (float32_t *)A_f32); // // /* Initialise Matrix Instance AT with numRows, numCols and data array(AT_f32) */ // srcRows = 4; // srcColumns = 4; // arm_mat_init_f32(&AT, srcRows, srcColumns, AT_f32); // // /* calculation of A transpose */ // status = arm_mat_trans_f32(&A, &AT); //// // for(i=0;i<16;i++) // printf("%f,",AT_f32[i]); // printf("rn"); // /* Initialise ATMA Matrix Instance with numRows, numCols and data array(ATMA_f32) */ // srcRows = 4; // srcColumns = 4; // arm_mat_init_f32(&ATMA, srcRows, srcColumns, ATMA_f32); // /* calculation of AT Multiply with A */ // status = arm_mat_mult_f32(&AT, &A, &ATMA); // /* Initialise ATMAI Matrix Instance with numRows, numCols and data array(ATMAI_f32) */ // srcRows = 4; // srcColumns = 4; // arm_mat_init_f32(&ATMAI, srcRows, srcColumns, ATMAI_f32); // /* calculation of Inverse((Transpose(A) * A) */ // status = arm_mat_inverse_f32(&ATMA, &ATMAI); // /* calculation of (Inverse((Transpose(A) * A)) * Transpose(A)) */ // status = arm_mat_mult_f32(&ATMAI, &AT, &ATMA); // /* Initialise B Matrix Instance with numRows, numCols and data array(B_f32) */ // srcRows = 4; // srcColumns = 1; // arm_mat_init_f32(&B, srcRows, srcColumns, (float32_t *)B_f32); // /* Initialise X Matrix Instance with numRows, numCols and data array(X_f32) */ // srcRows = 4; // srcColumns = 1; // arm_mat_init_f32(&X, srcRows, srcColumns, X_f32); // /* calculation ((Inverse((Transpose(A) * A)) * Transpose(A)) * B) */ // status = arm_mat_mult_f32(&ATMA, &B, &X); //// /* Comparison of reference with test output */ //// snr = arm_snr_f32((float32_t *)xRef_f32, X_f32, 4); } }
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)