写在前面: 博主是一名软件工程系大数据应用开发专业大二的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白, 之前刚学Spark时过一篇磨炼基础的练习题,➤Ta来了,Ta来了,Spark基础能力测试题Ta来了!,收到的反馈还是不错的。于是,在正式结课Spark之后,博主又为大家倾情奉献一道关于Spark的综合练习题,希望大家能有所收获✍ 以下是RNG S8 8强赛失败后,官微发表道歉微博下一级评论 数据说明: <1> 在kafak中创建rng_comment主题,设置2个分区2个副本 <2>数据预处理,把空行和缺失字段的行过滤掉 <3>请把给出的文件写入到kafka中,根据数据id进行分区,id为奇数的发送到一个分区中,偶数的发送到另一个分区 <4>使用Spark Streaming对接kafka <5>使用Spark Streaming对接kafka之后进行计算 在mysql中创建一个数据库rng_comment <6>查询出微博会员等级为5的用户,并把这些数据写入到mysql数据库中的vip_rank表中 <7>查询出评论赞的个数在10个以上的数据,并写入到mysql数据库中的like_status表中 <8>分别计算出2018/10/20 ,2018/10/21,2018/10/22,2018/10/23这四天每一天的评论数是多少,并写入到mysql数据库中的count_conmment表中 在命令行窗口执行Kafka创建Topic的命令,并指定对应的分区数和副本数 需要先写一个实现自定义分区逻辑的java类 然后在下面的程序中引用分区类的类路径 下面的代码完成了: 查询出微博会员等级为5的用户,并把这些数据写入到mysql数据库中的vip_rank表中 查询出评论赞的个数在10个以上的数据,并写入到mysql数据库中的like_status表中 运行成功后的效果 vip_rank like_status 下面的代码完成了: 运行成功后的效果 count_comment 本次的就到这里,因为博主还是一个萌新,能力有限,如果以上过程中出现了任何的纰漏错误,烦请大佬们指正。受益的朋友或对大数据技术感兴趣的伙伴记得关注支持一波(^U^)ノ~YO
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:https://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
文章目录
题目
字段
字段含义
index
数据id
child_comment
回复数量
comment_time
评论时间
content
评论内容
da_v
微博个人认证
like_status
赞
pic
图片评论url
user_id
微博用户id
user_name
微博用户名
vip_rank
微博会员等级
stamp
时间戳
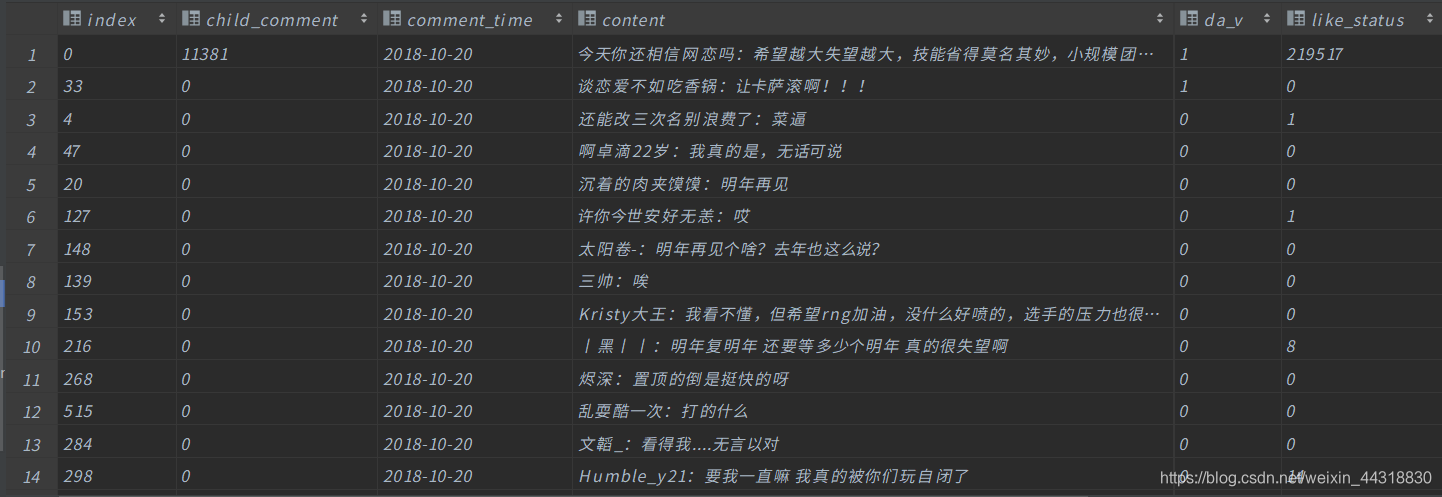
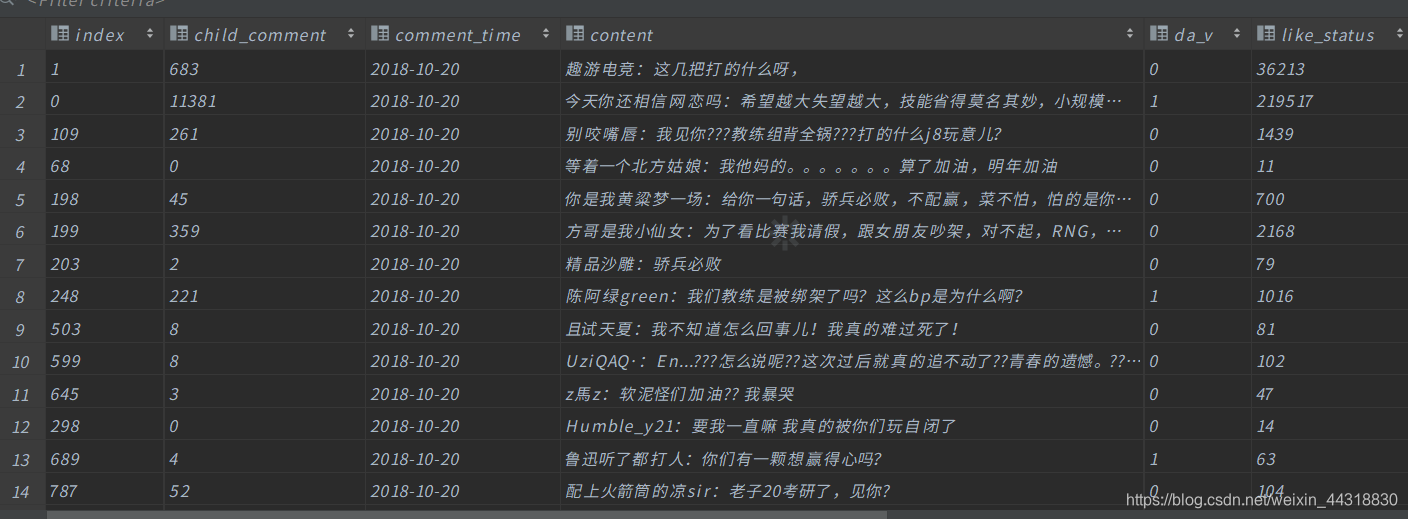
在数据库rng_comment创建vip_rank表,字段为数据的所有字段
在数据库rng_comment创建like_status表,字段为数据的所有字段
在数据库rng_comment创建count_conmment表,字段为 时间,条数

答案
<1> 创建Topic
/export/servers/kafka_2.11-1.0.0/bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 2 --partitions 2 --topic rng_comment <2> 读取文件,并对数据做过滤并输出到新文件
object test01_filter { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder().master("local[*]").appName("demo01").getOrCreate() val sc: SparkContext = spark.sparkContext // 读取数据 //testFile是多行数据 val rddInfo: RDD[String] = sc.textFile("E:\rng_comment.txt") // 对数据进行一个过滤 val RNG_INFO: RDD[String] = rddInfo.filter(data => { // 判断长度:将每行的内容用tab键切割,判断最后的长度 // 判读是否为空字符: trim之后不为empty data.split("t").length == 11 && !data.trim.isEmpty }) // // 如果想直接将数据写入到Kafka,而不通过输出文件的方式 // val kafkaProducer: KafkaProducer[String, String] = new KafkaProducer[String, String](props) // // def saveToKafka(INFO:RDD[String]): Unit ={ // // try { // // INFO.foreach(x=>{ // val record: ProducerRecord[String, String] = new ProducerRecord[String,String]("rng_test",x.split("t")(0),x.toString) // // kafkaProducer.send(record) // }) // // }catch { // case e:Exception => println("发送数据出错:"+e) // } // // } // 导入隐式转换 // 将RDD转换成DF import spark.implicits._ val df: DataFrame = RNG_INFO.toDF() // 输出数据【默认分区数为2,这里我们指定分区数为1】 df.repartition(1).write.text("E:\outputtest") // 关闭资源 sc.stop() spark.stop() } } <3>读取新文件,将数据按照题意发送到Kafka的不同分区
/* 编写自定义分区逻辑 */ public class ProducerPartition implements Partitioner { @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { /* 编写自定义分区代码 */ //System.out.println(value.toString()); String[] str = value.toString().split("t"); // 由题意可得,id为奇数的发送到一个分区中,偶数的发送到另一个分区 if (Integer.parseInt(str[0]) % 2 == 0){ return 0; }else { return 1; } } @Override public void close() { } @Override public void configure(Map<String, ?> configs) { } } public class test02_send { /* 程序的入口 */ public static void main(String[] args) throws IOException { //编写生产数据的程序 //1、配置kafka集群环境(设置) Properties props = new Properties(); //kafka服务器地址 props.put("bootstrap.servers", "node01:9092,node02:9092,node03:9092"); //消息确认机制 props.put("acks", "all"); //重试机制 props.put("retries", 0); //批量发送的大小 props.put("batch.size", 16384); //消息延迟 props.put("linger.ms", 1); //批量的缓冲区大小 props.put("buffer.memory", 33554432); // kafka key 和value的序列化 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 根据题意得,需要自定义分区 props.put("partitioner.class", "com.czxy.scala.demo12_0415.han.ProducerPartition"); KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(props); // 指定需要读取的文件 File file = new File("E:\outputtest\part-00000-fe536dc7-523d-4fdd-b0b5-1a045b8cb1ab-c000.txt"); // 创建对应的文件流,进行数据的读取 FileInputStream fileInputStream = new FileInputStream(file); // 指定编码格式进行读取 InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, "UTF-8"); // 创建缓冲流 BufferedReader bufferedReader = new BufferedReader(inputStreamReader); // 创建一个变量,用来保存每次读取的数据 String tempString = null; // 循环遍历读取文件内容 while ((tempString = bufferedReader.readLine()) != null) { // 利用kafka对象发送数据 kafkaProducer.send(new ProducerRecord<>("rng_comment", tempString)); // 发送完成之后打印数据 System.out.println("已发送:" + tempString); } System.out.println("数据发送完毕!"); // 关闭kafka数据生产者 kafkaProducer.close(); } } <4> 先在数据库中创建好接收数据需要用到的表
create table vip_rank ( `index` varchar(100) null comment '数据id', child_comment varchar(100) null comment '回复数量', comment_time DATE null comment '评论时间', content TEXT null comment '评论内容', da_v varchar(100) null comment '微博个人认证', like_status varchar(100) null comment '赞', pic varchar(100) null comment '图片评论url', user_id varchar(100) null comment '微博用户id', user_name varchar(100) null comment '微博用户名', vip_rank int null comment '微博会员等级', stamp varchar(100) null comment '时间戳' ); create table like_status ( `index` varchar(100) null comment '数据id', child_comment varchar(100) null comment '回复数量', comment_time DATE null comment '评论时间', content varchar(10000) null comment '评论内容', da_v varchar(100) null comment '微博个人认证', like_status varchar(100) null comment '赞', pic varchar(100) null comment '图片评论url', user_id varchar(100) null comment '微博用户id', user_name varchar(100) null comment '微博用户名', vip_rank int null comment '微博会员等级', stamp varchar(100) null comment '时间戳' ); create table count_comment ( time DATE null comment '时间', count int null comment '出现的次数', constraint rng_comment_pk primary key (time) ); <5> 使用Spark Streaming对接kafka之后进行计算
object test03_calculate { /* 将数据从kafka集群中读取,并将数据做进一步的处理过后,写入到mysql数据库中 */ def ConnectToMysql() ={ // 连接驱动,设置需要连接的MySQL的位置以及数据库名 + 用户名 + 密码 DriverManager.getConnection("jdbc:mysql://localhost:3306/rng_comment?characterEncoding=UTF-8", "root", "root") } /** * 将数据写入到MySQL的方法 * @param tableName 表名 * @param data List类型的数据 */ def saveDataToMysql(tableName:String,data:List[String]): Unit ={ // 获取连接 val connection: Connection = ConnectToMysql() // 创建一个变量用来保存sql语句 val sql = s"insert into ${tableName} (`index`, child_comment, comment_time, content, da_v,like_status,pic,user_id,user_name,vip_rank,stamp) values (?,?,?,?,?,?,?,?,?,?,?)" // 将数据存入到mysql中 val ps: PreparedStatement = connection.prepareStatement(sql) ps.setString(1,data.head) ps.setString(2,data(1)) ps.setString(3,data(2)) ps.setString(4,data(3)) ps.setString(5,data(4)) ps.setString(6,data(5)) ps.setString(7,data(6)) ps.setString(8,data(7)) ps.setString(9,data(8)) ps.setString(10,data(9)) ps.setString(11,data(10)) // 提交[因为是插入数据,所以这里需要更新] ps.executeUpdate() // 关闭连接 connection.close() } def main(args: Array[String]): Unit = { //1 创建sparkConf var conf = new SparkConf().setMaster("local[*]").setAppName("SparkStremingDemo1") //2 创建一个sparkcontext var sc = new SparkContext(conf) sc.setLogLevel("WARN") //3 创建streamingcontext var ssc = new StreamingContext(sc,Seconds(3)) //设置kafka对接参数 var kafkaParams= Map[String, Object]( "bootstrap.servers" -> "node01:9092,node02:9092,node03:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "SparkKafkaDemo", //earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 //latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据 //none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常 //这里配置latest自动重置偏移量为最新的偏移量,即如果有偏移量从偏移量位置开始消费,没有偏移量从新来的数据开始消费 "auto.offset.reset" -> "earliest", //false表示关闭自动提交.由spark帮你提交到Checkpoint或程序员手动维护 "enable.auto.commit" -> (false: java.lang.Boolean) ) // 设置检查点的位置 ssc.checkpoint("sparkstreaming/") //kafkaDatas 含有key和value //key是kafka成产数据时指定的key(可能为空) //value是真实的数据(100%有数据) val kafkaDatas: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String]( ssc, //设置位置策略 均衡 LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](Array("rng_comment"), kafkaParams)) kafkaDatas.foreachRDD(rdd=>rdd.foreachPartition(line=>{ // 遍历每一个分区的数据 for (row <- line){ // 获取到行数据组成的array数组 val str: Array[String] = row.value().split("t") // 将数据转成List集合 val list: List[String] = str.toList /* 查询出微博会员等级为5的用户,并把这些数据写入到mysql数据库中的vip_rank表中 */ if (list(9).equals("5")){ // 调用方法,将集合数据写入到指定的表中 saveDataToMysql("vip_rank",list) } /* 查询出评论赞的个数在10个以上的数据,并写入到mysql数据库中的like_status表中 */ if (Integer.parseInt(list(5))>10){ saveDataToMysql("like_status",list) } } })) //5 开启计算任务 ssc.start() //6 等待关闭 ssc.awaitTermination() } }
分别计算出2018/10/20 ,2018/10/21,2018/10/22,2018/10/23这四天每一天的评论数是多少,并写入到mysql数据库中的count_conmment表中object test04_count { def ConnectToMysql() ={ // 连接驱动,设置需要连接的MySQL的位置以及数据库名 + 用户名 + 密码 DriverManager.getConnection("jdbc:mysql://localhost:3306/rng_test?characterEncoding=UTF-8", "root", "root") } /** * 将数据存入到mysql中 * * @param time 时间 * @param count 数量 */ def saveDataToMysql(time: String, count: Int): Unit = { println(s"$timet $count") if (time.contains("2018/10/20") || time.contains("2018/10/21") || time.contains("2018/10/22") || time.contains("2018/10/23")) { //获取连接 val connection: Connection = ConnectToMysql() //创建一个变量用来保存sql语句 val sql: String = "INSERT INTO count_comment (time,count) VALUES (?,?) ON DUPLICATE KEY UPDATE count = ?" //将一条数据存入到mysql val ps: PreparedStatement = connection.prepareStatement(sql) ps.setString(1, time) ps.setInt(2, count) ps.setInt(3, count) //提交 ps.executeUpdate() //关闭连接 connection.close() } } def main(args: Array[String]): Unit = { //1 创建sparkConf var conf: SparkConf =new SparkConf().setMaster("local[*]").setAppName("SparkStremingDemo1") //2 创建一个sparkcontext var sc: SparkContext =new SparkContext(conf) sc.setLogLevel("WARN") //3 创建StreamingContext var ssc: StreamingContext =new StreamingContext(sc,Seconds(5)) //设置缓存数据的位置 ssc.checkpoint("./TmpCount") // 设置kafka的参数 var kafkaParams: Map[String, Object] = Map[String, Object]( "bootstrap.servers" -> "node01:9092,node02:9092,node03:9092", // 集群位置 "key.deserializer" -> classOf[StringDeserializer], // key序列化标准 "value.deserializer" -> classOf[StringDeserializer], // value序列化标准 "group.id" -> "SparkKafkaDemo", // 分组id //earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 //latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据 //none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常 //这里配置latest自动重置偏移量为最新的偏移量,即如果有偏移量从偏移量位置开始消费,没有偏移量从新来的数据开始消费 "auto.offset.reset" -> "earliest", //false表示关闭自动提交.由spark帮你提交到Checkpoint或程序员手动维护 "enable.auto.commit" -> (false: java.lang.Boolean) ) // 接收Kafka的数据并根据业务逻辑进行计算 val kafkaDatas: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String,String]( ssc, // StreamingContext对象 LocationStrategies.PreferConsistent, // 位置策略 ConsumerStrategies.Subscribe[String,String](Array("rng_comment"),kafkaParams) // 设置需要消费的topic和kafka参数 ) // 2018/10/23 16:09 需要先获取到下标为2的数据,再按照空格进行切分,获取到年月日即可 val kafkaWordOne: DStream[(String, Int)] = kafkaDatas.map(z=>z.value().split("t")(2).split(" ")(0)).map((_,1)) // 更新数据 val wordCounts: DStream[(String, Int)] = kafkaWordOne.updateStateByKey(updateFunc) // 遍历RDD wordCounts.foreachRDD(rdd=>rdd.foreachPartition(line=>{ for(row <- line){ saveDataToMysql(row._1,row._2) //println("保存成功!") } })) println("完毕!") // 开启计算任务 ssc.start() // 等待关闭 ssc.awaitTermination() } //currentValues:当前批次的value值,如:1,1,1 (以测试数据中的hadoop为例) //historyValue:之前累计的历史值,第一次没有值是0,第二次是3 //目标是把当前数据+历史数据返回作为新的结果(下次的历史数据) def updateFunc(currentValues:Seq[Int], historyValue:Option[Int] ):Option[Int] ={ // currentValues当前值 // historyValue历史值 val result: Int = currentValues.sum + historyValue.getOrElse(0) Some(result) } } 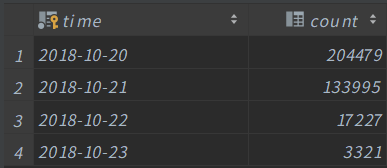

结语

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)

