Python 实现对excel 文件的读写功能主要有三个模块:xlwt 、xlrd 和openpyxl 。 这里用 三个重要概念: 注意:光理论是不够的,在此送大家一套2020最新Python全栈实战视频教程,点击此处 进来获取 跟着练习下,希望大家一起进步哦! 操作步骤: 代码: 举例:生成图表 Word 文档和PDF 是二进制文件,所以它们比纯文本文件要复杂得多,因为除了文本之外,它们还保存了许多字体、颜色和布局信息 。 三个概念: 一个Run对象就是一种样式!一个Run 对象是相同样式文本的延续。 代码: 实例:将Excel表格转换为Word表格 在PyPDF2 中,与PdfFileReader 对象相对的是PdfFileWriter 对象,不能将任意文本写入PDF ,仅限于从其它PDF 中拷贝页面、旋转页面、重叠页面和加密文件 。 模块 不允许直接编辑PDF ,必须创建一个新的PDF ,然后从已有的文档拷贝内容 。 步骤如下: 合并文件: 加密,解密PDF文件: 旋转页面: Word 文件转换为PDF 文件: 添加水印: 注意:最后送大家一套2020最新企业Pyhon项目实战视频教程,点击此处 进来获取 跟着练习下,希望大家一起进步哦! 总有一句会让你找到努力的理由! 希望我们都能用最少的悔恨面对过去,用最少的浪费面对现在,用最多的梦面对未来。加油~
一、Python 处理Excel
openpyxl模块。 Python 没有自带openpyxl ,所以必须安装。openpyxl 只能操作xlsx 文件而不能操作xls 文件。
Workbook 是一个打开的excel 文件,即excel 工作簿;Sheet 是工作簿中的一张表,即工作表;
Cell 就是一个单元格 。
打开Workbook ,定位Sheet ,操作Cell。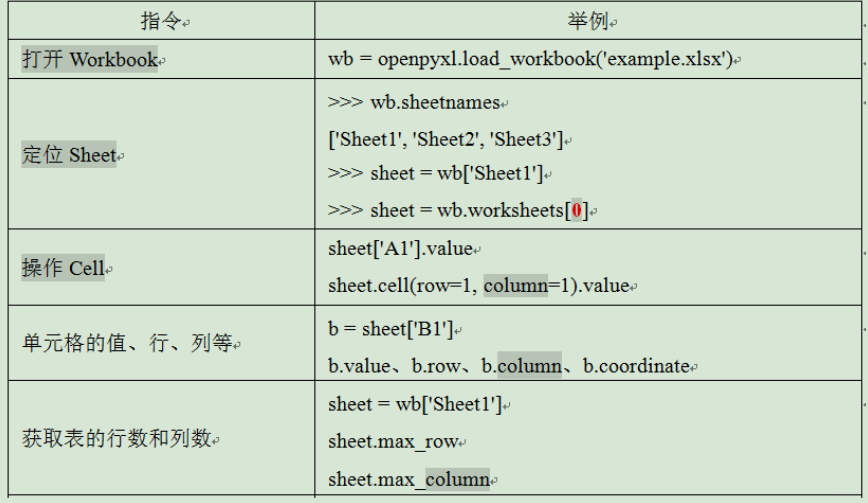


import openpyxl # 导入模块 wb = openpyxl.load_workbook('学生信息.xlsx') # 加载Excel表格 wb.sheetnames # 取得工作簿中所有表名的列表 wb.active #当前活动表格 sheet = wb.worksheets[0] # 获取第一张表格 sheet = wb['Sheet1']# 获取Sheet1表格 sheet.title # 表格的名字 cell=sheet['A1'] # 一个单元格 cell=sheet.cell(row=1, column=1)# 一个单元格 cell.row # 单元格的行号 cell.column # 单元格的列号 cell.value # 单元格的值 sheet['A1'].value = 'Hello' # 给单元格的附值 sheet.cell(row=1, column=2).value = 30 # 给单元格的附值 sheet['A1'].value # 单元格的值 sheet.cell(row=1, column=1).value # 单元格的值 sheet['A1':'C3'] # 获取多个单元格 openpyxl.utils.get_column_letter(2) # B 列字母和数字之间的转换 openpyxl.utils.column_index_from_string("B") # 2 wb = openpyxl.Workbook() # 创建一个空的Excel 文档 wb.save('学生信息.xlsx') # 打开或者创建Excel后都要保存 sheet=wb.create_sheet(index=0, title='First') # 创建一个表格sheet del wb['Sheet1'] # 删除Sheet1表格 wb.remove(wb['Sheet1']) # 删除Sheet1表格 sheet['A3'] = '=SUM(A1:A2)' # 使用加法公式 sheet.row_dimensions[1].height = 10 # 设置第一行的行高为10 sheet.column_dimensions['B'].width = 20 # 设置第一列的宽度为20 sheet.merge_cells('A1:D3') # 合并A1~D3的单元格 sheet.unmerge_cells('A1:D3')# 拆分A1~D3的单元格
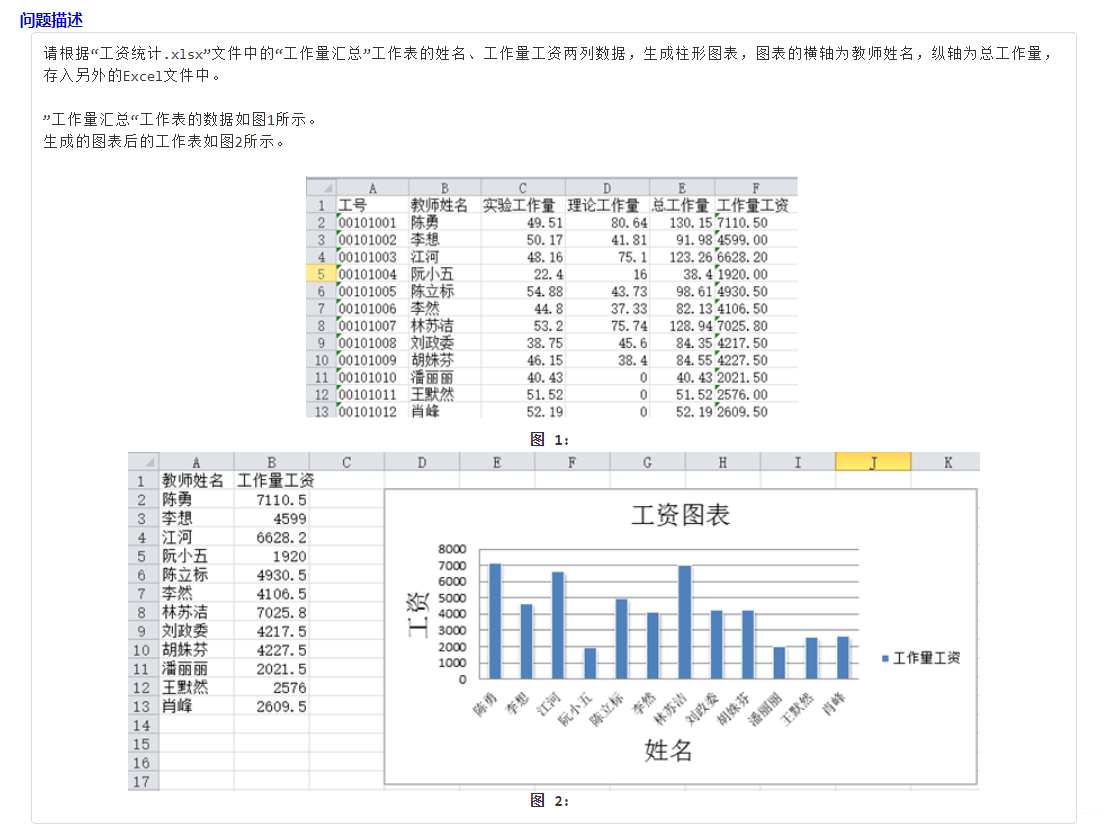
import openpyxl from openpyxl.chart import BarChart, Series, Reference wb=openpyxl.load_workbook("工资统计.xlsx") sheet=wb["工作量汇总"] result=openpyxl.Workbook() result.create_sheet(index=0,title="工资图表") test=result["工资图表"] maxrow=sheet.max_row test.cell(row=1, column=1).value = sheet.cell(row=1, column=2).value test.cell(row=1, column=2).value = sheet.cell(row=1, column=6).value for i in range(2,maxrow+1): test.cell(row=i,column=1).value=sheet.cell(row=i,column=2).value test.cell(row=i, column=2).value = float(sheet.cell(row=i, column=6).value) chart1 = BarChart() chart1.type = "col" chart1.style = 10 chart1.title = "工资图表" chart1.y_axis.title = '工资' chart1.x_axis.title = '姓名' data = Reference(test, min_col=2, max_col=2,min_row=1, max_row=maxrow) # 条形图中的数字数据(看见的矩形) cats = Reference(test, min_col=1, min_row=2, max_row=maxrow) # 横坐标上的姓名 chart1.add_data(data, titles_from_data=True) chart1.set_categories(cats) chart1.shape = 4 test.add_chart(chart1, "A10") wb.save("工资统计.xlsx") result.save("工资表.xlsx")
二、Python 处理 Word
import docx
Document对象表示整个文档,是最高层。
Document 对象包含一个Paragraph对象的列表,表示文档中的段落。
每个Paragraph 对象都包含一个Run对象的列表。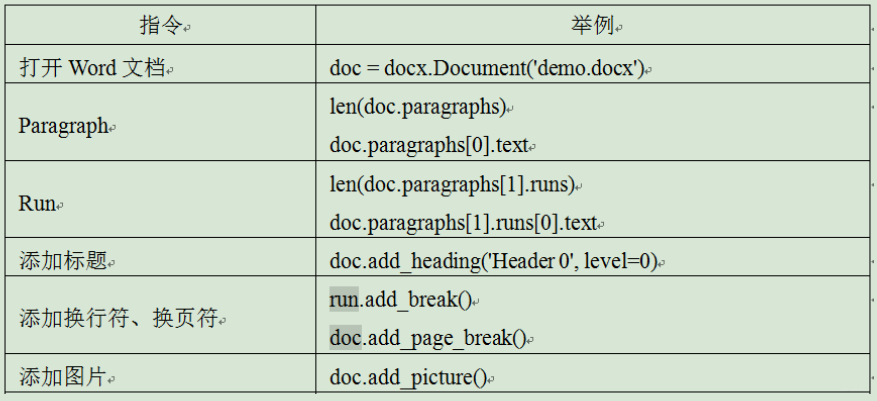

import docx # 加载模块 doc = docx.Document('实验报告.docx') # 加载文档 len(doc.paragraphs) # 文章段落个数 doc.paragraphs[1].text # 第2段文字 doc.paragraphs[1].runs[0].text # 第1段的第1个样式的文字 doc = docx.Document() # 创建一个新的Word文档 para=doc.add_paragraph('Hello world!') # 添加一个段落 para.add_run(' secondparagraph.') # 已有段落的末尾添加文本 doc.save('实验报告.docx') # 保存文档 doc.add_heading('Header 0', level=0) # 添加标题 run1.font.color.rgb = RGBColor(0,0,0) # 设置Run对象的颜色 run1.font.size = Pt(20) # 设置rund对象字体大小 run.add_break() # 添加换行符,注意是Run对象调用 doc.add_page_break() # 添加换页符,注意是doc对象调用 doc.add_picture('gird.png',width=docx.shared.Inches(1),height=docx.shared.Cm(4)) # 添加图像 table = doc.add_table(rows=2, cols=2, style='Table Grid') # 添加表格 cell = table.cell(0, 0) table.cell(0, 1).text = 'world' row = table.rows[1] # 获得表格1行 row.cells[0].text = 'world' 第一行第0个单元格的值 row = table.add_row() # 增加一行

import docx import openpyxl import random from docx.oxml.ns import qn from docx.shared import Pt, RGBColor wb=openpyxl.load_workbook("工资统计.xlsx") sheet=wb["工作量汇总"] doc=docx.Document() maxrow=sheet.max_row maxcol=sheet.max_column table=doc.add_table(rows=maxrow,cols=maxcol) for i in range(maxrow): for j in range(maxcol): run = table.cell(i,j).paragraphs[0].add_run(str(sheet.cell(i+1,j+1).value)) run.font.color.rgb = RGBColor(int(random.random() * 255), int(random.random() * 255), int(random.random() * 255)) wb.save("工资统计.xlsx") doc.save("工资统计.docx")
三、Python 处理 PDF
import PyPDF2
PyPDF2 不能从PDF 文档中提取图像、图表或其它媒体,但它可以提取文本,并将文本返回为Python 字符串 。import PyPDF2 file = open('实验.pdf', 'rb') # 'rb' 读打开pdf文档 reader = PyPDF2.PdfFileReader(file) # 读pdf对象 reader.numPages # 返回文档页数 page = reader.getPage(0) # 获得reader的第一页

addPage() 添加页面,在末尾。import PyPDF2 import os pdf_output=PyPDF2.PdfFileWriter() filter=[".pdf"] for root, dirs, files in os.walk("C:/Users/自由自在/PycharmProjects/文件操作"): for filespath in files: name=os.path.join(root,filespath) ext=os.path.splitext(name)[1] if ext in filter: file = open(filespath, "rb") reader = PyPDF2.PdfFileReader(file) print(reader.isEncrypted) if not reader.isEncrypted: for i in range(reader.getNumPages()): page = reader.getPage(i) pdf_output.addPage(page) file.close() with open("result.pdf","wb") as file1: pdf_output.write(file1) import PyPDF2 reader = PyPDF2.PdfFileReader(open('加密.pdf', 'rb')) writer = PyPDF2.PdfFileWriter() for num in range(reader.numPages): writer.addPage(reader.getPage(num)) writer.encrypt('mima:hello') # 加密,传入口令字符串 with open('加密后.pdf', 'wb') as f: writer.write(f) reader.isEncrypted # 判断是否加密 reader.decrypt('mima:hello') # 解密
利用rotateClockwise()和rotateCounterClockwise() 方法,PDF 文档的页面也可以旋转90 度的整数倍。import glob import re from win32com import client as wc word = wc.Dispatch('Word.Application') # glob.glob 遍历指定目录下的所有文件和文件夹,不递归遍历 files = glob.glob('F:/*.docx') for file in files: name = re.findall('(.*).docx', file)[0] try: doc = word.Documents.Open(file) doc.SaveAs('%s.pdf' % name, 17) # wdFormatPDF = 17 doc.Close() except: continue word.Quit() import PyPDF2 pdf_output=PyPDF2.PdfFileWriter() file=open('meeting.pdf', 'rb') filemark=open("watermark.pdf","rb") pdf_input=PyPDF2.PdfFileReader(file) pdf_watermark=PyPDF2.PdfFileReader(filemark) for i in range(pdf_input.getNumPages()): page=pdf_input.getPage(i) page.mergePage(pdf_watermark.getPage(0)) pdf_output.addPage(page) with open('meeting11111.pdf',"wb") as file3: pdf_output.write(file3) file.close() filemark.close()
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











