House.java Spider.java App.java 控制台输出: Spider.java App.java 控制台输出: 以上就是 利用爬虫快速获取企业招聘信息,有问题的小伙伴,欢迎留言!!!
基于JSoup的HTML解析(以58同城为例)
package com.newer.spider; public class House { String room; String des; String money; String jjr; public House() { } public String getRoom() { return room; } public void setRoom(String room) { this.room = room; } public String getDes() { return des; } public void setDes(String des) { this.des = des; } public String getMoney() { return money; } public void setMoney(String money) { this.money = money; } public String getJjr() { return jjr; } public void setJjr(String jjr) { this.jjr = jjr; } @Override public String toString() { return String.format("%s,%sn",des,jjr); } }
package com.newer.spider; import java.io.IOException; import java.util.List; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; /** * 爬虫 * @author Admin * */ public class Spider { /** * 爬虫的爬取(解析)的目标页面 */ String url; /** * 存储抓取的信息 */ List<House> list; /** *创建爬虫 * @param url 目标页面 */ public Spider(String url,List<House> list) { this.url=url; this.list=list; } /** * 抓取信息 */ public void run() { // 使用Jsoup获得目标页面 // DOM定义的树形结构 try { Document document=Jsoup.connect(url).get(); // 访问文档中的特定节点 // a <a> // .abc class="abc" // #main id="main" // 抽丝剥茧 Elements es=document.select(".house-list .house-cell"); System.out.println(es.size()); for (Element e : es) { // System.out.println(e.text()); String room=e.selectFirst(".room").text(); String des=e.selectFirst(".des").text(); String money= e.selectFirst(".money").text(); String jjr=e.selectFirst(".jjr").text(); // System.out.printf("%s.%s,%s,%sn",room,money,jjr,des); House house=new House(); house.setDes(des); house.setRoom(room); house.setMoney(money); house.setJjr(jjr); System.out.println(house.toString()); list.add(house); } } catch (IOException e) { e.printStackTrace(); } } }
package com.newer.spider; import java.util.ArrayList; import java.util.List; public class App { public static void main(String[] args) { List<House> list=new ArrayList<>(); // 创建一个爬虫,指定了任务 Spider spider=new Spider("https://cs.58.com/chuzu/?PGTID=0d200001-0019-e299-bb21-2ff05b0bc4e2&ClickID=1", list); // 让爬虫开始工作 spider.run(); } }

基于线程池的并发编程(以招聘网为例)
package com.newer.spider2; /** * 基于线程的爬虫 * @author Admin * */ public class Spider implements Runnable { String url; public Spider(String url) { this.url=url; } @Override public void run() { System.out.printf("%s处理:%sn",Thread.currentThread().getName(),url); try { Thread.sleep(5000); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
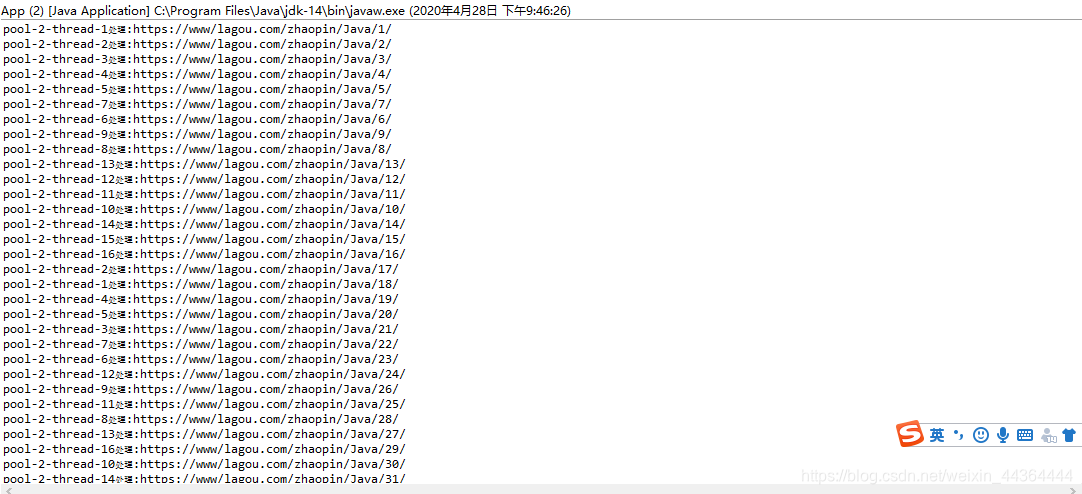
package com.newer.spider2; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; /** * 基于线程池的爬虫 * @author Admin * */ public class App { public static void main(String[] args) { // 创建一个线程池,数量不限,循环使用 ExecutorService pool= Executors.newCachedThreadPool(); // 固定大小的线程池 pool=Executors.newFixedThreadPool(16); // 单一线程池 // pool=Executors.newSingleThreadExecutor(); // 16个线程去执行30个任务 for(int i=0;i<100;i++) { String url=String.format("https://www/lagou.com/zhaopin/Java/%d/",i+1); pool.execute(new Spider(url)); } } }
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











