从本科毕业设计开始就一直做知识图谱方面的应用,回想起刚开始做的时候连一些概念性的博客都很难找到,想结合学到现在的经验做一个知识图谱入门的介绍和简单实战,有兴趣或者有需求入门知识图谱的同学们欢迎和我一起讨论交流,也希望各路大佬在知识图谱领域能给我写建议和帮助。 当初刚刚接触知识图谱这个概念的时候我是一脸懵逼的,连这是个什么东西都不知道,上网查也很难查到说的很明白的科普文章,通常会结合本体、语义网等等延伸过来,致力于做学术的可以看看过往计算机本体、语义网那块的经典论文能够比较了解知识图谱的前世今生。对于希望入门的同学们我们就一起来用白话谈谈知识图谱到底是个什么东西。 知识图谱首先是一个图类型的数据,这个图指的不是现在很火的CV涉及的图像数据,离散数学学过图论的同学们都很清楚,计算机的图就是由节点和边形成的一种数据结构。 所以我们为什么需要知识图谱呢?知识图谱的一个很重要的作用是赋予计算机知识或者说常识。和利用神经网络方法相比较,神经网络是通过海量的数据训练,让计算机产生近乎于神级的直觉,但这种直觉终究有限。比如你的训练数据里南极总有企鹅,那么企鹅这个成分在识别南极可能有很高的权重,如果有一天弄了一个赤道企鹅的图片,那可能会被误认为是南极,但如果计算机从知识图谱里面已经获得了企鹅有南极企鹅和赤道企鹅,那可能就会去分辨其他的元素从而判断正确不跑偏。 知识图谱能够应用到精确检索,关系分析与计算、个性化推荐以及推荐的可解释化等等,个人认为在当下是一个很值得研究的方向。 刚刚讲了很多知识图谱的科普和安利,可能有很多想入门或者正苦恼如何构建知识图谱的同学们,接下来我们讲讲如何构建知识图谱。 在思考一个项目的时候首先需要构建一个框架,以我现在在做的一个科技协同服务项目构筑的知识图谱应用框架来看: 拥有一个好的数据比拥有好的算法有时候更重要,构造能用的知识图谱第一步,就是确定从哪些数据里面抽取你需要的知识。这也就是上图数据源层要做的。 很多同学包括我一开始做的时候,总想从一些高质量文本数据里面,应用nlp相关的关系抽取算法,去抽取三元组。之前我的n次尝试全部失败,不仅抽取效果不佳,无关的噪声关系多,抽取的正确率不高,需要的人工调整花的力气比自己手动制造一个还多。因此我建议,千万要根据自己的项目需求构建知识图谱,不要老想着做泛用型。最优的数据排名:结构化数据(直接可以构筑节点、属性和关系)>半结构化数据(可能需要爬取,爬完可以比较容易的转化为结构化数据)>非结构化数据(高质量文本数据)。 针对半结构化数据需要爬取,整理成结构化数据然后构造宽表,以及其他一些琐碎的数据整理,就是ETL层要做的 以我这个做的为例,我做的小核酸医药领域的科技服务知识图谱,内容偏门,也没有很好的数据支撑,因此我使用了从上到下的专家法+从下到上的归纳法结合的方法。上层复用了UMLS医学知识图谱的上层框架,下层根据需求将专利、论文、技术、小核酸药物等等业务涉及的实体插入框架。上层的设计需要研读高质量的行业研报,自己手工构建,下层根据需求填充,填充完了就可以利用结构化或者半结构化数据往里面增加实例。 构筑好知识图谱你可以像我的业务层做的那样设计一些可视化、关系或者节点查询、路径计算的api。 关于可视化可以看我之前一篇文章:《如何在网页前端里可视化你的知识图谱》https://blog.csdn.net/qq_37477357/article/details/104857495 之后设计一些应用,例如个性化推荐、精确检索、聊天机器人等等。 一个构筑领域聊天机器人简单的思路 核心代码如下: 欢迎大家围观我上述内容的相关知识图谱构建和领域聊天机器人的相关代码: 有兴趣或者有需求入门知识图谱的同学们欢迎和我一起讨论交流,也希望各路大佬在知识图谱领域能给我写建议和帮助。欢迎大家跟我邮箱联系:youlitaiglz@pku.edu.cn 或者评论区沟通,谢谢大家的支持!
博客相关代码:https://github.com/GLZ1925/TechServerKG知识图谱是什么

上图就是一个知识图谱,很简单,包括了水果、苹果、梨子三个节点以及他们的关系。怎么构建知识图谱



基于设计将数据内容整理成neo4j等图数据库可读的创建节点、关系、属性的cypher脚本或者可以批量导入的csv格式数据,在图数据库中构建知识图谱,这就是上图数据层做的。如何构筑一个领域聊天机器人
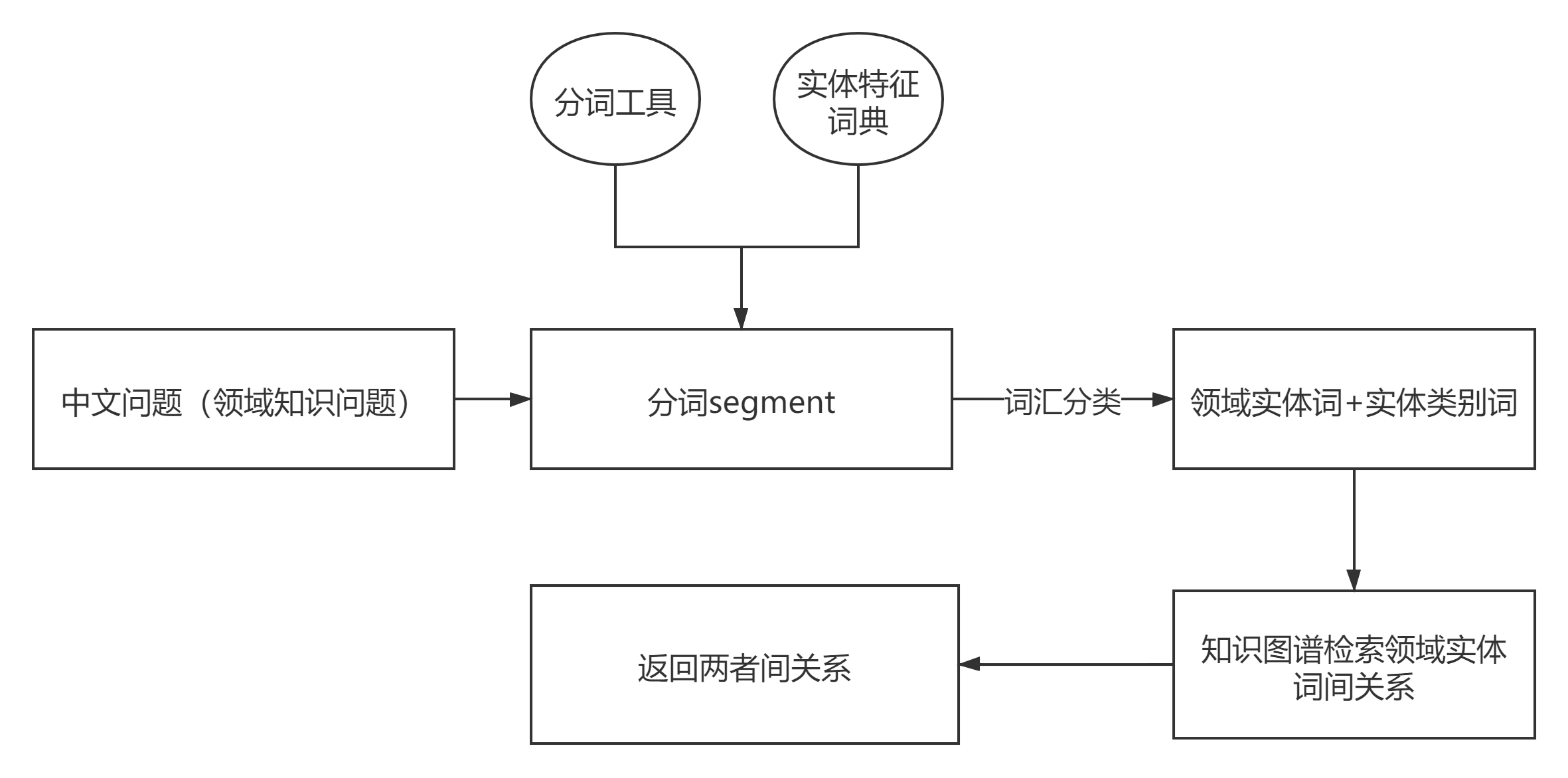
知识图谱中蕴含了大量领域相关的知识,以实体和关系形式存在。我们可以利用命名实体识别方法识别问题中的实体对象,遍历实体对象间的关系,利用知识图谱查询两者关系从而返回回答结果。def analyse_question(text,cutter): cut_text = cutter.cut(text) entity_list = [] entity_type_list = [] for seg in cut_text: if seg[0] in entity_type_dict.keys(): entity_type_list.append(seg[0]) elif seg[0] in entity_dict.keys(): entity_list.append(seg[0]) # print(cut_text) # print(entity_list) # print(entity_type_list) graph = Graph("https://localhost:7474", username="", password='') for entity in entity_list: for entity_type in entity_type_list: # print("MATCH (entity1) - [rel] - (entity2:%s) WHERE entity1.name ='%s' RETURN entity2.name"%(entity_type_dict[entity_type],entity)) ans = graph.run("MATCH (entity1) - [rel] - (entity2:%s) WHERE entity1.name ='%s' RETURN entity2.name"%(entity_type_dict[entity_type],entity)).data() if len(ans) is not 0: response = "%s相关的%s有:"%(entity,entity_type) # print(ans) for dict in ans: response += dict['entity2.name'] + "," response = response[:-1] print(response) else: response = "%s相关的%s暂未有了解,我们会继续完善补充数据的!(≧∀≦)ゞ"%(entity,entity_type) print(response) if len(entity_type_list) == 0: response = "您所提问%s的相关内容我们暂不了解,我们会继续完善补充数据的!(≧∀≦)ゞ"%(entity) print(response) if len(entity_list) == 0: response = "您所提问的我们暂不了解,我们会继续完善补充数据的!(≧∀≦)ゞ" print(response) 写在最后
https://github.com/GLZ1925/TechServerKG
11-10  1087
1087
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











