这几篇SVM介绍是从0到1慢慢学会支持向量机,将是满满的干货,都是我亲自写的,没有搬运,可以随我一起从头了解SVM,并在短期内能使用SVM做到想要的分类或者预测~我也将附上自己基础训练的完整代码,可以直接跑,建议同我一样初学者们,自己从头到尾打一遍,找找手感,代码不能光看看,实践出真知! 回顾一下,上篇,我们建立和比较了线性分类器和非线性分类器,比较了多元线性核函数和线性核函数,解决了类型数量不平衡问题,话不多说,原理篇和实战基础一 请参见上几篇博客,我们循序渐进慢慢贴近真实情景!解决生活问题 获取对位置数据分类的置信水平,在现实问题中非常有用,当一个心得数据点被分类为某一个一直类别时,我们可以训练SVM来计算输出类型的置信度。 先上图: 在我们用上一篇的方法做好训练分类器后:我们找几个点,如上图,黑色部分几个点是在我们认定的“正例”,其他的为负例,我们观察一下置信度(通俗的说也就是分类为正例还是负例的概率): 上代码: 介绍一下核心部分代码: 看一下到边界的距离和置信度: 可以看到:上面几行是该点到黑圈边界的距离,为正说明在黑圈边界以外,为负说明在内。例如: [7.6 2. ] –> 2.0058455177573045 可以根据我们最上面的图明白该点越离边界远,值越大,同样的,越在黑圈中间,越小(绝对值越大) 我们看置信度: [2. 1.5] –> [0.01421961 0.98578039] 说明该点为正例(在圈内)的概率为:0.01421961 同样的为负例的概率:0.98578039 使用交叉验证网格搜索的方法(原理过段时间集中介绍) 我们要验证这几个参数的组合搭配的效果 介绍一下重点部分代码: 看结果: 各种参数搭配的Precison 由结果可知,最高的组合是 {‘C’: 10, ‘gamma’: 0.01, ‘kernel’: ‘rbf’} 同样的看一下recall(召回率) 同样的这一组参数的召回率最高{‘C’: 600, ‘gamma’: 0.01, ‘kernel’: ‘rbf’} 在理想中,我们总是希望precison和recall越高越好,但是真实情况中,往往两者有着负相关,precision越高,往往recall越低,以后慢慢介绍这几种! 这是一个低维度预测器,只反映原理,并不代表实际情况,预测的准确率有待优化 下面我们准备一组数据: 上代码: 代码逻辑也很简单,同上一样,训练数据,建立预测分类器,最后检验,用一批数据喂给分类器,就能得出预测结果 预测结果是有活动的在 ‘Tuesday’, ‘12:30:00’,‘21’,‘23’ 这样的情况下我们再换个比较难以分辨的数据: 接下来,再少一些出入大楼的人,这一天的这个时刻就预测为没有活动发生了。 这些都是简单的代码,并且没有逻辑可言,就稍微介绍一下这里吧: 这里我发现我的参考资料是错误的,我把它修改,并且在资料官网:Python Machine Learning CookBook留言了 首先在input_data中迭代,判断输入数据是否为纯数字(isdigit())方法,如果不是,那么就使用 然后使用reshape转换成数组形式,符合预测的形状(维度匹配),最后predict预测。 同样的我们修改一下数据: 我们同样的预测一下(方法不变) ok!跟真实结果一致。 通过上述两个方法,可以先预测出某时刻这栋大楼是否有事件,然后再预测是哪个事件,数据越多,预测越准确,防止过拟合是一种好的优化方案,我们以后再说,又到了文末,下期继续实践!感受一下魅力!现在还只是使用传统机器学习,做着与真实情况差别较大的理论基础,我们把地基打好,就开始实战!请求关注,我们下期再见~ 最后附上上述代码用到的数据集:
【实战】支持向量机SVM基础实战篇(二)
原理篇请戳这里
提取数据置信度
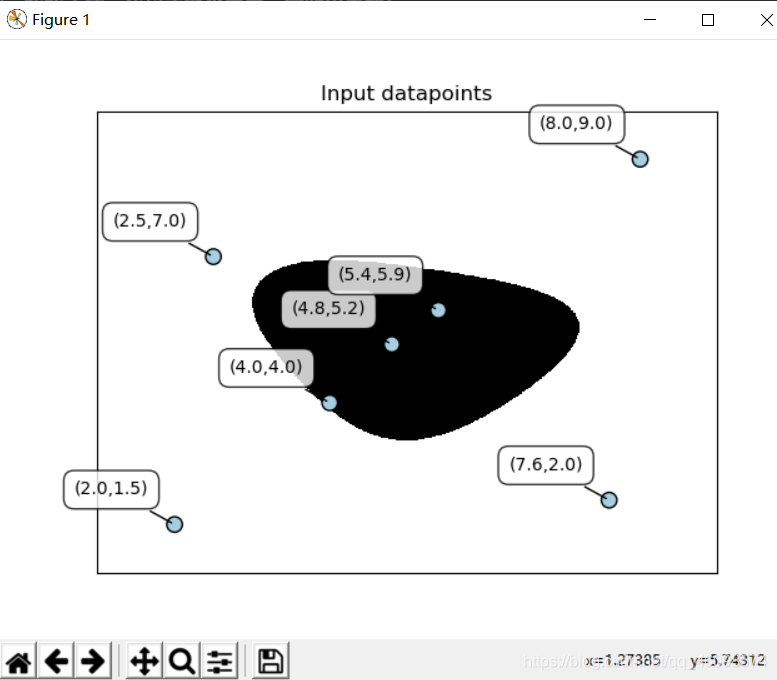
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import _validation def load_data(input_file): X = [] y = [] with open(input_file, 'r') as f: for line in f.readlines(): data = [float(x) for x in line.split(',')] X.append(data[:-1]) y.append(data[-1]) X = np.array(X) y = np.array(y) return X, y def plot_classifier(classifier, X, y, title='Classifier boundaries', annotate=False): x_min, x_max = min(X[:, 0]) - 1.0, max(X[:, 0]) + 1.0 y_min, y_max = min(X[:, 1]) - 1.0, max(X[:, 1]) + 1.0 step_size = 0.01 x_values, y_values = np.meshgrid(np.arange(x_min, x_max, step_size), np.arange(y_min, y_max, step_size)) mesh_output = classifier.predict(np.c_[x_values.ravel(), y_values.ravel()]) mesh_output = mesh_output.reshape(x_values.shape) plt.figure() plt.title(title) plt.pcolormesh(x_values, y_values, mesh_output, cmap=plt.cm.gray) plt.scatter(X[:, 0], X[:, 1], c=y, s=80, edgecolors='black', linewidth=1, cmap=plt.cm.Paired) plt.xlim(x_values.min(), x_values.max()) plt.ylim(y_values.min(), y_values.max()) plt.xticks(()) plt.yticks(()) if annotate: for x, y in zip(X[:, 0], X[:, 1]): plt.annotate( '(' + str(round(x, 1)) + ',' + str(round(y, 1)) + ')', xy=(x, y), xytext=(-15, 15), textcoords='offset points', horizontalalignment='right', verticalalignment='bottom', bbox=dict(boxstyle='round,pad=0.6', fc='white', alpha=0.8), arrowprops=dict(arrowstyle='-', connectionstyle='arc3,rad=0')) def print_accuracy_report(classifier, X, y, num_validations=5): accuracy = _validation.cross_val_score(classifier, X, y, scoring='accuracy', cv=num_validations) print("Accuracy: " + str(round(100*accuracy.mean(), 2)) + "%") f1 = _validation.cross_val_score(classifier, X, y, scoring='f1_weighted', cv=num_validations) print("F1: " + str(round(100*f1.mean(), 2)) + "%") precision = _validation.cross_val_score(classifier, X, y, scoring='precision_weighted', cv=num_validations) print("Precision: " + str(round(100*precision.mean(), 2)) + "%") recall = _validation.cross_val_score(classifier, X, y, scoring='recall_weighted', cv=num_validations) print("Recall: " + str(round(100*recall.mean(), 2)) + "%") load_file(input_file) # 输入数据点,转成np.array 函数 plot_classifier(classifier, X, y, title='Classifier boundaries', annotate=False): # 数据可视化函数 classifier.decision_function([i])[0] # 这是测量数据点到边界的距离 方法 classifier.predict_proba([i])[0] # 测量置信度 方法
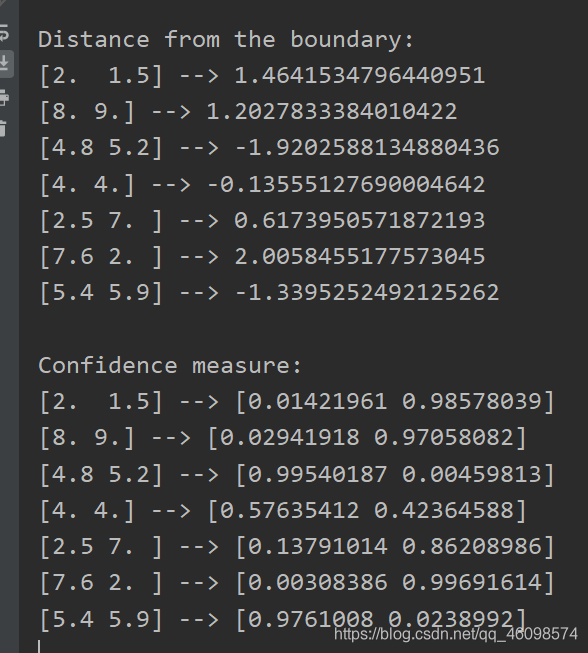
[4.8 5.2] –> -1.9202588134880436
寻找最优超参数
parameter_grid = [{'kernel': ['linear'], 'C': [1, 10, 50, 600]}, {'kernel': ['poly'], 'degree': [2, 3]}, {'kernel': ['rbf'], 'gamma': [0.01, 0.001], 'C': [1, 10, 50, 600]}, ]
上代码:import numpy as np import matplotlib.pyplot as plt from sklearn import svm from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.model_selection import GridSearchCV def load_file(input_file): x = [] y = [] with open(input_file, "r") as f: for line in f.readlines(): data = [float(x) for x in line.split(',')] x.append(data[:-1]) y.append(data[-1]) X = np.array(x) y = np.array(y) return X, y input_file = 'data_multivar.txt' X, y =load_file(input_file) ############################################### # Train test split X_train, X_test, y_train, y_test =train_test_split(X, y, test_size=0.25, random_state=5) # Set the parameters by cross-validation parameter_grid = [{'kernel': ['linear'], 'C': [1, 10, 50, 600]}, {'kernel': ['poly'], 'degree': [2, 3]}, {'kernel': ['rbf'], 'gamma': [0.01, 0.001], 'C': [1, 10, 50, 600]}, ] metrics = ['precision', 'recall_weighted'] for metric in metrics: print("n#### Searching optimal hyperparameters for", metric) classifier = GridSearchCV(svm.SVC(C=1), parameter_grid, cv=5, scoring=metric) classifier.fit(X_train, y_train) print("nScores across the parameter grid:") for means, params in zip(classifier.cv_results_['mean_test_score'], classifier.cv_results_['params']): print(params, '-->', means) print("nHighest scoring parameter set:", classifier.best_params_) y_true, y_pred = y_test, classifier.predict(X_test) print("nFull performance report:n") print(classification_report(y_true, y_pred)) metrics = ['precision', 'recall_weighted'] # 定义好需要测量的指标 precision 和recall(甚至可以设置accuracy和F1_score) classifier = GridSearchCV(svm.SVC(C=1), # 网格搜索 parameter_grid, cv=5, scoring=metric) classifier.fit(X_train, y_train) 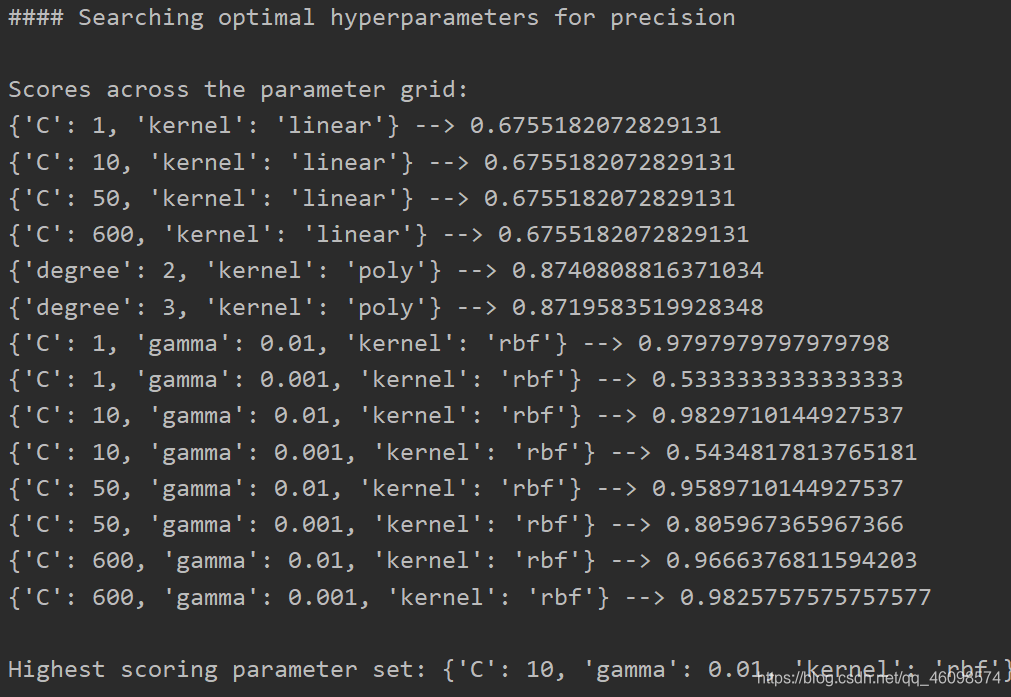

建立一个预测某时刻是否某地点有活动展开预测器
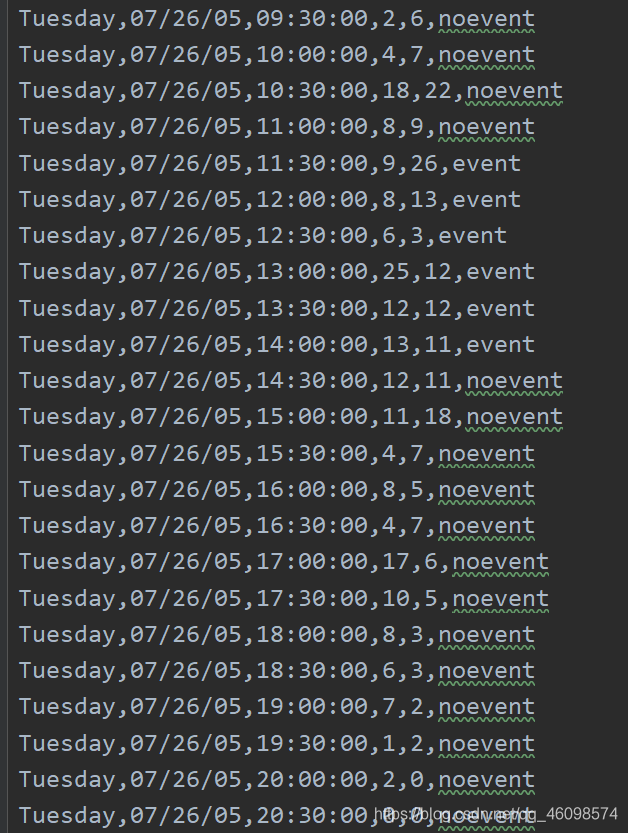
准备了五千条数据可以看出:在 7 月 26号Tuesday 的20:00这一时刻,一栋大楼内进入的人数为2人
出大楼的人数为0人次,真实情况是:NOEVENT(也就是没有活动)根据这样的方法,记录了5000条数据,用于训练SVM的分类器,目的是给出某一时刻的数据,用于预测是否可能有聚会等活动发生(可供白嫖党吃吃喝喝-_-技术员始终不会饿着,哈哈)
from sklearn import preprocessing import numpy as np from sklearn.svm import SVC from sklearn.model_selection import KFold, cross_val_score input_file = 'building_event_multiclass.txt' X = [] count = 0 with open(input_file, 'r') as f: for line in f.readlines(): data = line[:-1].split(',') X.append([data[0]] + data[2:]) X = np.array(X) label_encoder = [] X_encoded = np.empty(X.shape) for i, item in enumerate(X[0]): if item.isdigit(): X_encoded[:, i] = X[:, i] else: label_encoder.append(preprocessing.LabelEncoder()) X_encoded[:, i] = label_encoder[-1].fit_transform(X[:, i]) X = X_encoded[:, :-1].astype(int) y = X_encoded[:, -1].astype(int) params = {'kernel': 'rbf', 'probability': True, 'class_weight': 'balanced', 'C':100} classifier = SVC(**params) classifier.fit(X, y) accuracy = cross_val_score(classifier, X, y, scoring='accuracy', cv=3) print("Accuracy of the classifier: " + str(round(100*accuracy.mean(), 2)) + "%") input_data = ['Tuesday', '12:30:00','21','23'] input_data_encoded = [-1] * len(input_data) count = 0 for i, item in enumerate(input_data): if item.isdigit(): input_data_encoded[i] = int(input_data[i]) else: input_data_encoded[i] = int(label_encoder[count].transform([input_data[i]])) count = count + 1 input_data_encoded = np.array(input_data_encoded) input_data_encoded = input_data_encoded.reshape(1, len(input_data)) output_class = classifier.predict(input_data_encoded) print("Output class:", label_encoder[-1].inverse_transform(output_class)[0]) 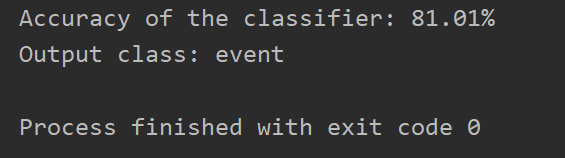

for i, item in enumerate(input_data): if item.isdigit(): input_data_encoded[i] = int(input_data[i]) else: input_data_encoded[i] = int(label_encoder[count].transform([input_data[i]])) count = count + 1 input_data_encoded = np.array(input_data_encoded) input_data_encoded = input_data_encoded.reshape(1, len(input_data)) output_class = classifier.predict(input_data_encoded) print("Output class:", label_encoder[-1].inverse_transform(output_class)[0])
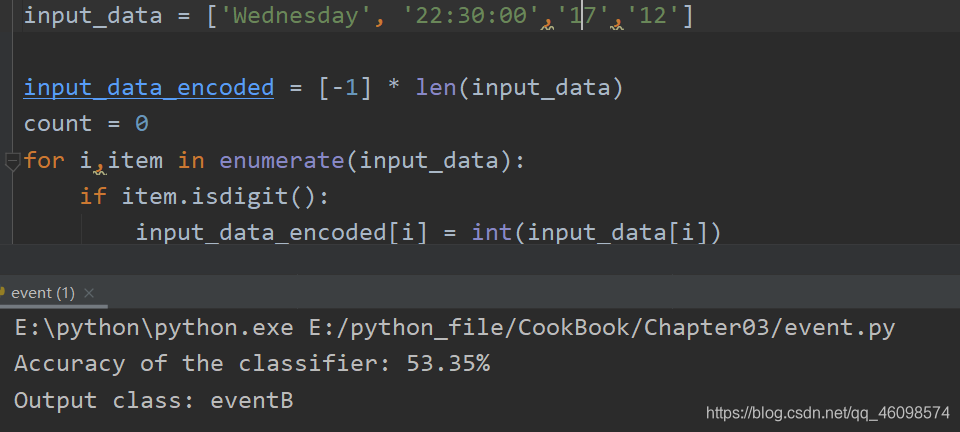
transform方法做标准化处理,这边的标准化处理以及transform与fit_transform的区别,我们慢慢介绍。
这次明确了有一些活动:eventA,eventB,eventC
网盘:
链接:https://pan.baidu.com/s/1w8MJVkRsQkx8hy977RY27A
提取码:68pw
感谢关注!
上海第二工业大学智能科学与技术大二 周小夏(CV调包侠)
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











