计算机视觉工程师在面试过程中主要考察三个内容:图像处理、机器学习、深度学习。然而,各类资料纷繁复杂,或是简单的知识点罗列,或是有着详细数学推导令人望而生畏的大部头。为了督促自己学习,也为了方便后人,决心将常考必会的知识点以通俗易懂的方式设立专栏进行讲解,努力做到长期更新。此专栏不求甚解,只追求应付一般面试。希望该专栏羽翼渐丰之日,可以为大家免去寻找资料的劳累。每篇介绍一个知识点,没有先后顺序。想了解什么知识点可以私信或者评论,如果重要而且恰巧我也能学会,会尽快更新。最后,每一个知识点我会参考很多资料。考虑到简洁性,就不引用了。如有冒犯之处,联系我进行删除或者补加引用。在此先提前致歉了! K-Nearest Neighbor 由来 基于以上分析 原理 KNN的应用 分类如上,不再赘述 分类和回归 回归: 异常值处理: 剔除冗余样本 先对每个已知数据进行KNN k的大小 关于模型复杂度 距离 邻居的权重 为避免上述情况,通常将k设置为奇数 所以,我们可以根据邻居和测试点的距离增加权重 权重可以是距离的倒数 计算量的问题 这种数据结构通常有两种实现方法: 可以发现,KD Tree是针对欧式距离分割的 超球体空间分割 核函数 完
K最近邻
KNN
判断一个样本和另一个样本是否属于一个类
最直观的想法是
看两者的特征是否相等
这是可行的,但是有一定的缺点:
考虑到可以用特征相似的样本对未知类别的样本进行估计
从而诞生了KNN
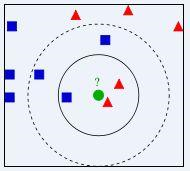
如图,在特征空间中
两类已知类别的样本,蓝色和红色
一个未知类别样本,绿色
通过绿色周围邻居的类别来决定绿色的种类:
看3个邻居:红色多,绿色被判为红色
看5个邻居:蓝色多,绿色被判为蓝色
上述的3或者5就是KNN算法中的超参数k
注意:以上过程并不需要学习,不需要训练,给定样本特征,可以直接进行预测
当然,样本的特征可能需要学习得到,但是一般没这么干的
KNN使用的特征一般比较低级
比如预测动物种类
特征可以是,是否会飞?是否下蛋?几只脚这类的
如果模型都能学习样本特征了,那一般也不用KNN了
分类、回归、异常值处理、剔除冗余样本
分类:判定样本类别
回归:根据输入得到输出的值,比如拟合曲线
得到k个邻居后,k个邻居输出的均值作为测试样本的输出
比如拟合曲线:
和测试点最近的k个点对应的y取平均值,就是测试点的y值
在分类问题中,测试样本可能不属于任何一类
强行分类必定造成性能下降
可以用KNN先判断测试样本是否属于任意一类
具体做法有很多:
比如测试样本是A
找到A最近的邻居B,距离是dAB
找到B最近的距离C,距离是dBC
如果dBC<a*dAB(也就是A离样本点们比较远),那么A是异常值(a是超参数)
复杂一点,
可以找B的n个邻居,计算距离平均值,然后和a*dAB比较
再复杂一点,
找A的m个邻居,每个邻居找n个邻居,计算m*n个距离的平均值,然后和a*dAB比较
在这个数据至上的时代,数据存在即合理
通常不会剔除数据
这个应用通常也只是针对KNN本身
如果KNN的结果和它的标签是相同的
也就是说这个样本可以被其它样本表示
这个样本就被视为冗余的,被剔除
使用剔除冗余样本后的数据进行KNN
可以提升准确率
k太小,受噪声影响严重,模型复杂度高,容易过拟合
k太大,模型复杂度降低,精度不高
举个例子方便理解
如果k等于样本总数,模型的意义就是,哪类样本多,测试样本就属于哪类
这个模型就很简单
如果k等于1,那要求构造的特征空间中,每一个样本点的位置都是鲜明可区分的,哪怕是噪声,所以特征维度会很高,模型复杂度高
连噪声都能拟合,就肯定过拟合了
在特征空间中选邻居的标准就是距离
距离近的才是邻居
一般用欧式距离和曼哈顿距离
两种距离的理解如下(二维空间的情况):

在测试点的邻居中,A类样本和B类样本数量相同,测试点属于哪一类呢?
然而,如果多分类,设置为奇数,仍然可能出现上述情况
比如3个A类,3个B类,1个C类
所以,k为奇数更多的是一种习惯而已
离测试点距离近的样本点话语权大一些
但是如果距离为0,会出现运算错误
(针对距离为0的问题,通常做法是让测试样本直接和距离为0的样本点类别相同)
所以也可以用exp(-d)作为权重,d是距离
可以看出,每测试一个样本
哪怕k=1,也要计算出测试样本和所有样本的距离
如果样本总量巨大,这个计算量是很可怕的
然而,很多样本离测试样本是很远的,没什么计算的必要
我们就可以利用某种数据结构将样本点进行存储
只计算和测试样本相近的样本点
K dimensional tree
KD Tree
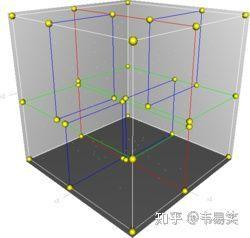
如下图,简单说,针对三维特征空间,我们根据坐标轴将空间分为8块
那么如果测试样本落在某一块中,就只需要在对应的块中找邻居
(以上说法十分不严格!!!只是为了方便理解)
具体来讲,先根据x1维度的中位数划分数据为两块
每一块再根据x2维度的中位数划分为两块
这样就是一个树的结构,也就是KD Tree
防止跑题,就不展开了
如果使用的距离不是欧式距离呢?
如图,原理类似
只是特征空间不需要一定是欧式空间
我们用超球体进行分割
具体到二维特征空间
超球体就是圆
当然,这种方法最终也是生成了KD Tree
只是距离的度量方法和分割方法不同了

将特征进行映射,使特征的表征能力更强
可以提升KNN的性能
核函数以后会分析,不再展开
这里理解成一种映射关系就足以了
欢迎讨论 欢迎吐槽
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











