人工智能:Artificial Intelligence,英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新技术科学。 研究AI非常难,需要数学、编程、机器学习的基础,但是使用AI却很简单。Python最大的优势,就是它非常接近自然语言,易于阅读理解,编程更加简单直接,更加适合初学者。人工智能和Python互相之间成就者对方,人工智能算法促进Python的发展,而Python也让算法更加简单。随着NumPy,SciPy,Matplotlib等众多程序库的开发,Python越来越适合于做科学计算。 作业二:查找特定名称文件 第二天的课程介绍了python的进阶语法、linux命令、vim编辑器、爬虫知识。 作业:《青春有你2》选手信息爬取 Python被大量应用在数据挖掘和深度学习领域,其中使用极其广泛的是Numpy、pandas、Matplotlib、PIL等库。 作业:《青春有你2》选手数据分析 本节主要介绍PaddleHub的体验与应用,接下来让大家学会如何利用PaddleHub解决实际工作中的问题,以图像分类来举例。 作业:《青春有你2》五人识别 第一步:数据获取üDay2课程中爬取的选手照片。 模型训练输出信息: 由于数据量不够,没有做数据增强,参数也不是最优,最后5个人中有一个预测的不对,准确率在80%。 EasyDL与飞桨的关系: 大作业:数据爬取、分析与内容审核 输出信息: 1、百度AI开放平台:https://ai.baidu.com/productlist 相关链接:

笔者近期体验了免费的“百度深度学习7日打卡第六期:Python小白逆袭大神”训练营,课程每天都有对应的直播,由中科院团队负责教学,每天有对应的作业贯穿其中,带你全程体验百度AI开放平台——AI Studio,飞桨PaddlePaddle,EasyDL。
看到课程还有这么多丰厚的礼品,打卡更有动力了!

介绍完课程,下面来点学习过程中的干货:Day1-人工智能概述与入门基础
机器学习:一种实现人工智能的方法。
深度学习:一种实现机器学习的技术,人工神经网络是机器学习中的一个重要的算法“深度”就是说神经网络中众多的层。

作业
作业一:输出 9*9 乘法口诀表(注意格式)def table(): #在这里写下您的乘法口诀表代码吧! for j in range(1,10): for i in range(1,j+1): print("%d*%d=%dt"%(i,j,i*j),end="") print("") if __name__ == '__main__': table() 1 * 1 = 1 1 * 2 = 2 2 * 2 = 4 1 * 3 = 3 2 * 3 = 6 3 * 3 = 9 1 * 4 = 4 2 * 4 = 8 3 * 4 = 12 4 * 4 = 16 1 * 5 = 5 2 * 5 = 10 3 * 5 = 15 4 * 5 = 20 5 * 5 = 25 1 * 6 = 6 2 * 6 = 12 3 * 6 = 18 4 * 6 = 24 5 * 6 = 30 6 * 6 = 36 1 * 7 = 7 2 * 7 = 14 3 * 7 = 21 4 * 7 = 28 5 * 7 = 35 6 * 7 = 42 7 * 7 = 49 1 * 8 = 8 2 * 8 = 16 3 * 8 = 24 4 * 8 = 32 5 * 8 = 40 6 * 8 = 48 7 * 8 = 56 8 * 8 = 64 1 * 9 = 9 2 * 9 = 18 3 * 9 = 27 4 * 9 = 36 5 * 9 = 45 6 * 9 = 54 7 * 9 = 63 8 * 9 = 72 9 * 9 = 81
遍历”Day1-homework”目录下文件;找到文件名包含“2020”的文件;将文件名保存到数组result中;按照序号、文件名分行打印输出。#导入OS模块 import os #待搜索的目录路径 path = "Day1-homework" #待搜索的名称 filename = "2020" #定义保存结果的数组 result = [] def findfiles(): #在这里写下您的查找文件代码吧! all = [] for dirpath,dirnames,filenames in os.walk(path): for file in filenames: dirpathnames = os.path.join(dirpath, file) if filename in dirpathnames: result.append(dirpathnames) for i,name in enumerate(result): print(i+1,name) if __name__ == '__main__': findfiles() 1 Day1-homework/18/182020.doc 2 Day1-homework/26/26/new2020.txt 3 Day1-homework/4/22/04:22:2020.txtDay2-深度学习实践平台与Python进阶
# 一、爬取百度百科中《青春有你2》中所有参赛选手信息,返回页面数据 import json import re import requests import datetime from bs4 import BeautifulSoup import os #获取当天的日期,并进行格式化,用于后面文件命名,格式:20200420 today = datetime.date.today().strftime('%Y%m%d') def crawl_wiki_data(): """ 爬取百度百科中《青春有你2》中参赛选手信息,返回html """ headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } url='https://baike.baidu.com/item/青春有你第二季' try: response = requests.get(url,headers=headers) print(response.status_code) #将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象, 可以传入一段字符串 soup = BeautifulSoup(response.text,'lxml') #返回的是class为table-view log-set-param的<table>所有标签 tables = soup.find_all('table',{'class':'table-view log-set-param'}) crawl_table_title = "参赛学员" for table in tables: #对当前节点前面的标签和字符串进行查找 table_titles = table.find_previous('div').find_all('h3') for title in table_titles: if(crawl_table_title in title): return table except Exception as e: print(e)# 二、对爬取的页面数据进行解析,并保存为JSON文件 def parse_wiki_data(table_html): ''' 从百度百科返回的html中解析得到选手信息,以当前日期作为文件名,存JSON文件,保存到work目录下 ''' bs = BeautifulSoup(str(table_html),'lxml') all_trs = bs.find_all('tr') error_list = [''','"'] stars = [] for tr in all_trs[1:]: all_tds = tr.find_all('td') star = {} #姓名 star["name"]=all_tds[0].text #个人百度百科链接 star["link"]= 'https://baike.baidu.com' + all_tds[0].find('a').get('href') #籍贯 star["zone"]=all_tds[1].text #星座 star["constellation"]=all_tds[2].text #身高 star["height"]=all_tds[3].text #体重 star["weight"]= all_tds[4].text #花语,去除掉花语中的单引号或双引号 flower_word = all_tds[5].text for c in flower_word: if c in error_list: flower_word=flower_word.replace(c,'') star["flower_word"]=flower_word #公司 if not all_tds[6].find('a') is None: star["company"]= all_tds[6].find('a').text else: star["company"]= all_tds[6].text stars.append(star) json_data = json.loads(str(stars).replace("'",""")) with open('work/' + today + '.json', 'w', encoding='UTF-8') as f: json.dump(json_data, f, ensure_ascii=False)# 三、爬取每个选手的百度百科图片,并进行保存 def crawl_pic_urls(): ''' 爬取每个选手的百度百科图片,并保存 ''' with open('work/'+ today + '.json', 'r', encoding='UTF-8') as file: json_array = json.loads(file.read()) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } for star in json_array: name = star['name'] link = star['link'] #!!!请在以下完成对每个选手图片的爬取,将所有图片url存储在一个列表pic_urls中!!! pic_urls = [] try: response = requests.get(link, headers = headers) #print(response.status_code) soup = BeautifulSoup(response.text,"lxml") div = soup.find_all("div",{"class":"summary-pic"})[0] imgsLink = div.find_all("a")[0].get("href") imgsLink = r"https://baike.baidu.com"+imgsLink response_img = requests.get(imgsLink, headers=headers) soup_img = BeautifulSoup(response_img.text,"lxml") divs = soup_img.find_all("a",{"class":"pic-item"}) for div_img in divs: img = div_img.find_all("img")[0].get("src") pic_urls.append(img) except Exception as e: print(e) #!!!根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中!!! down_pic(name,pic_urls) def down_pic(name,pic_urls): ''' 根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中, ''' path = 'work/'+'pics/'+name+'/' if not os.path.exists(path): os.makedirs(path) for i, pic_url in enumerate(pic_urls): try: pic = requests.get(pic_url, timeout=15) string = str(i + 1) + '.jpg' with open(path+string, 'wb') as f: f.write(pic.content) print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url))) except Exception as e: print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url))) print(e) continue# 四、打印爬取的所有图片的路径 def show_pic_path(path): ''' 遍历所爬取的每张图片,并打印所有图片的绝对路径 ''' pic_num = 0 for (dirpath,dirnames,filenames) in os.walk(path): for filename in filenames: pic_num += 1 print("第%d张照片:%s" % (pic_num,os.path.join(dirpath,filename))) print("共爬取《青春有你2》选手的%d照片" % pic_num) if __name__ == '__main__': #爬取百度百科中《青春有你2》中参赛选手信息,返回html html = crawl_wiki_data() #解析html,得到选手信息,保存为json文件 parse_wiki_data(html) #从每个选手的百度百科页面上爬取图片,并保存 crawl_pic_urls() #打印所爬取的选手图片路径 show_pic_path('/home/aistudio/work/pics/') print("所有信息爬取完成!")
Day3-深度学习常用Python库
Numpy是Python科学计算库的基础。包含了强大的N维数组对象和向量运算。
Pandas是建立在numpy基础上的高效数据分析处理库,是Python的重要数据分析库。
Matplotlib是一个主要用于绘制二维图形的Python库。
PIL库是一个具有强大图像处理能力的第三方库。
基于第二天实践使用Python来爬去百度百科中《青春有你2》所有参赛选手的信息,进行数据可视化分析。# 下载中文字体 #!wget https://mydueros.cdn.bcebos.com/font/simhei.ttf # 将字体文件复制到matplotlib字体路径 !cp simhei.ttf /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/ # 一般只需要将字体文件复制到系统字体目录下即可,但是在aistudio上该路径没有写权限,所以此方法不能用 # !cp simhei.ttf /usr/share/fonts/ # 创建系统字体文件路径 #!mkdir .fonts # 复制文件到该路径 !cp simhei.ttf .fonts/ !rm -rf .cache/matplotlib# 绘制选手区域分布柱状图 import matplotlib.pyplot as plt import numpy as np import json import matplotlib.font_manager as font_manager #显示matplotlib生成的图形 %matplotlib inline with open('data/data31557/20200422.json', 'r', encoding='UTF-8') as file: json_array = json.loads(file.read()) #绘制小姐姐区域分布柱状图,x轴为地区,y轴为该区域的小姐姐数量 zones = [] for star in json_array: zone = star['zone'] zones.append(zone) print(len(zones)) print(zones) zone_list = [] count_list = [] for zone in zones: if zone not in zone_list: count = zones.count(zone) zone_list.append(zone) count_list.append(count) print(zone_list) print(count_list) # 设置显示中文 plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体 plt.figure(figsize=(20,15)) plt.bar(range(len(count_list)), count_list,color='r',tick_label=zone_list,facecolor='#9999ff',edgecolor='white') # 这里是调节横坐标的倾斜度,rotation是度数,以及设置刻度字体大小 plt.xticks(rotation=45,fontsize=20) plt.yticks(fontsize=20) plt.legend() plt.title('''《青春有你2》参赛选手''',fontsize = 24) plt.savefig('/home/aistudio/work/result/bar_result.jpg') plt.show()
# 请在下面完成作业,对选手体重分布进行可视化,绘制饼状图 import matplotlib.pyplot as plt import numpy as np import json import matplotlib.font_manager as font_manager import pandas as pd #显示matplotlib生成的图形 %matplotlib inline df = pd.read_json('data/data31557/20200422.json') #print(df) weights = df["weight"] arrs = weights.values for i in range(len(arrs)): #print(float(arrs[i][0:-2])) arrs[i] = float(arrs[i][0:-2]) #print(arrs) #pandas.cut 用来对数据分组。 bin =[0,45,50,55,100] cut = pd.cut(arrs,bin) #pandas的value_counts()函数可以对Series里面的每个值进行计数并且排序。 labels = "45~50kg","<=45kg","50~55kg",">55kg" sizes = pd.value_counts(cut) print(sizes) explode = (0.05,0.08,0,0) colors = ['red', 'yellow', 'blue', 'green'] fig, ax = plt.subplots() ax.pie(sizes,explode=explode,labels=labels,autopct="%1.1f%%", colors=colors,shadow=True,startangle=160) ax.axis("equal") plt.title('''《青春有你2》参赛选手体重分布图''',fontsize = 16) plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体 plt.savefig('/home/aistudio/work/result/bar_result02.jpg') plt.show() (45, 50] 66 (0, 45] 25 (50, 55] 13 (55, 100] 5 dtype: int64
Day4-PaddleHub体验与应用
图像分类:是计算机视觉的重要领域,它的目标是将图像分类到预定义的标签,本实践基于自己创建的数据集(青春有你2选手)介绍如何使PaddleHub进行图像分类任务。
第二步:制作数据集数据标签:图片对应到标签。
第三步:使用PaddleHub实现分类。#CPU环境启动请务必执行该指令 %set_env CPU_NUM=1 #安装paddlehub !pip install paddlehub==1.6.0 -i https://pypi.tuna.tsinghua.edu.cn/simple # 上传自制数据集 !unzip -o file.zip -d ./dataset/ # 加载预训练模型 import paddlehub as hub module = hub.Module(name="resnet_v2_50_imagenet") # 数据准备 from paddlehub.dataset.base_cv_dataset import BaseCVDataset class DemoDataset(BaseCVDataset): def __init__(self): # 数据集存放位置 self.dataset_dir = "." super(DemoDataset, self).__init__( base_path= self.dataset_dir, train_list_file="dataset/train_list.txt", validate_list_file="dataset/validate_list.txt", test_list_file="dataset/test_list.txt", label_list_file="dataset/label_list.txt", ) dataset = DemoDataset() # 生成数据读取器 data_reader = hub.reader.ImageClassificationReader( image_width=module.get_expected_image_width(), image_height=module.get_expected_image_height(), images_mean=module.get_pretrained_images_mean(), images_std=module.get_pretrained_images_std(), dataset=dataset) # 配置策略 config = hub.RunConfig( use_cuda=False, #是否使用GPU训练,默认为False; num_epoch=3, #Fine-tune的轮数; checkpoint_dir="cv_finetune_turtorial_demo",#模型checkpoint保存路径, 若用户没有指定,程序会自动生成; batch_size=2, #训练的批大小,如果使用GPU,请根据实际情况调整batch_size; eval_interval=10, #模型评估的间隔,默认每100个step评估一次验证集; strategy=hub.finetune.strategy.DefaultFinetuneStrategy()) #Fine-tune优化策略; # 组建Finetune Task input_dict, output_dict, program = module.context(trainable=True) img = input_dict["image"] feature_map = output_dict["feature_map"] feed_list = [img.name] task = hub.ImageClassifierTask( data_reader=data_reader, feed_list=feed_list, feature=feature_map, num_classes=dataset.num_labels, config=config) # 开始Finetune run_states = task.finetune_and_eval()[2020-04-27 19:28:35,776] [ INFO] - Strategy with slanted triangle learning rate, L2 regularization, [2020-04-27 19:28:35,846] [ INFO] - Try loading checkpoint from cv_finetune_turtorial_demo/ckpt.meta [2020-04-27 19:28:35,847] [ INFO] - PaddleHub model checkpoint not found, start from scratch... [2020-04-27 19:28:35,946] [ INFO] - PaddleHub finetune start [2020-04-27 19:28:52,958] [ TRAIN] - step 10 / 187: loss=1.70172 acc=0.05000 [step/sec: 0.59] [2020-04-27 19:28:52,959] [ INFO] - Evaluation on dev dataset start share_vars_from is set, scope is ignored. [2020-04-27 19:28:59,149] [ EVAL] - [dev dataset evaluation result] loss=1.69627 acc=0.26923 [step/sec: 2.36] [2020-04-27 19:28:59,151] [ EVAL] - best model saved to cv_finetune_turtorial_demo/best_model [best acc=0.26923] [2020-04-27 19:29:16,136] [ TRAIN] - step 20 / 187: loss=1.80405 acc=0.15000 [step/sec: 0.64] [2020-04-27 19:29:16,138] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:29:22,092] [ EVAL] - [dev dataset evaluation result] loss=1.61843 acc=0.30769 [step/sec: 2.21] [2020-04-27 19:29:22,095] [ EVAL] - best model saved to cv_finetune_turtorial_demo/best_model [best acc=0.30769] [2020-04-27 19:29:38,693] [ TRAIN] - step 30 / 187: loss=1.57683 acc=0.35000 [step/sec: 0.64] [2020-04-27 19:29:38,696] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:29:44,801] [ EVAL] - [dev dataset evaluation result] loss=1.52250 acc=0.46154 [step/sec: 2.15] [2020-04-27 19:29:44,804] [ EVAL] - best model saved to cv_finetune_turtorial_demo/best_model [best acc=0.46154] [2020-04-27 19:30:01,984] [ TRAIN] - step 40 / 187: loss=1.56317 acc=0.15000 [step/sec: 0.62] [2020-04-27 19:30:01,988] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:30:07,723] [ EVAL] - [dev dataset evaluation result] loss=1.45854 acc=0.38462 [step/sec: 2.29] [2020-04-27 19:30:22,890] [ TRAIN] - step 50 / 187: loss=1.65609 acc=0.25000 [step/sec: 0.66] [2020-04-27 19:30:22,895] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:30:28,417] [ EVAL] - [dev dataset evaluation result] loss=1.35443 acc=0.53846 [step/sec: 2.39] [2020-04-27 19:30:28,423] [ EVAL] - best model saved to cv_finetune_turtorial_demo/best_model [best acc=0.53846] [2020-04-27 19:30:45,369] [ TRAIN] - step 60 / 187: loss=1.68136 acc=0.35000 [step/sec: 0.63] [2020-04-27 19:30:45,371] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:30:51,190] [ EVAL] - [dev dataset evaluation result] loss=1.31653 acc=0.50000 [step/sec: 2.26] [2020-04-27 19:31:07,273] [ TRAIN] - step 70 / 187: loss=1.19829 acc=0.71429 [step/sec: 0.60] [2020-04-27 19:31:07,275] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:31:12,979] [ EVAL] - [dev dataset evaluation result] loss=1.30945 acc=0.50000 [step/sec: 2.31] [2020-04-27 19:31:28,912] [ TRAIN] - step 80 / 187: loss=1.12100 acc=0.60000 [step/sec: 0.63] [2020-04-27 19:31:28,921] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:31:35,136] [ EVAL] - [dev dataset evaluation result] loss=1.26691 acc=0.50000 [step/sec: 2.12] [2020-04-27 19:31:51,610] [ TRAIN] - step 90 / 187: loss=1.32904 acc=0.45000 [step/sec: 0.61] [2020-04-27 19:31:51,617] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:31:57,267] [ EVAL] - [dev dataset evaluation result] loss=1.35002 acc=0.38462 [step/sec: 2.33] [2020-04-27 19:32:12,782] [ TRAIN] - step 100 / 187: loss=1.30772 acc=0.55000 [step/sec: 0.64] [2020-04-27 19:32:12,786] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:32:18,640] [ EVAL] - [dev dataset evaluation result] loss=1.28365 acc=0.42308 [step/sec: 2.24] [2020-04-27 19:32:34,136] [ TRAIN] - step 110 / 187: loss=1.26464 acc=0.50000 [step/sec: 0.65] [2020-04-27 19:32:34,139] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:32:39,989] [ EVAL] - [dev dataset evaluation result] loss=1.48371 acc=0.34615 [step/sec: 2.25] [2020-04-27 19:32:55,842] [ TRAIN] - step 120 / 187: loss=0.84075 acc=0.80000 [step/sec: 0.63] [2020-04-27 19:32:55,846] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:33:01,778] [ EVAL] - [dev dataset evaluation result] loss=1.61648 acc=0.42308 [step/sec: 2.21] [2020-04-27 19:33:17,356] [ TRAIN] - step 130 / 187: loss=1.05649 acc=0.37500 [step/sec: 0.58] [2020-04-27 19:33:17,358] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:33:23,344] [ EVAL] - [dev dataset evaluation result] loss=1.70825 acc=0.30769 [step/sec: 2.19] [2020-04-27 19:33:39,025] [ TRAIN] - step 140 / 187: loss=0.96893 acc=0.60000 [step/sec: 0.64] [2020-04-27 19:33:39,026] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:33:44,888] [ EVAL] - [dev dataset evaluation result] loss=1.49983 acc=0.38462 [step/sec: 2.24] [2020-04-27 19:34:01,003] [ TRAIN] - step 150 / 187: loss=1.20475 acc=0.55000 [step/sec: 0.62] [2020-04-27 19:34:01,006] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:34:06,719] [ EVAL] - [dev dataset evaluation result] loss=1.04901 acc=0.53846 [step/sec: 2.30] [2020-04-27 19:34:21,905] [ TRAIN] - step 160 / 187: loss=0.64030 acc=0.90000 [step/sec: 0.66] [2020-04-27 19:34:21,909] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:34:27,547] [ EVAL] - [dev dataset evaluation result] loss=0.99199 acc=0.61538 [step/sec: 2.33] [2020-04-27 19:34:27,550] [ EVAL] - best model saved to cv_finetune_turtorial_demo/best_model [best acc=0.61538] [2020-04-27 19:34:43,550] [ TRAIN] - step 170 / 187: loss=0.96540 acc=0.75000 [step/sec: 0.66] [2020-04-27 19:34:43,551] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:34:49,254] [ EVAL] - [dev dataset evaluation result] loss=1.03128 acc=0.61538 [step/sec: 2.29] [2020-04-27 19:35:04,857] [ TRAIN] - step 180 / 187: loss=0.91474 acc=0.70000 [step/sec: 0.64] [2020-04-27 19:35:04,858] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:35:10,828] [ EVAL] - [dev dataset evaluation result] loss=1.12821 acc=0.61538 [step/sec: 2.20] [2020-04-27 19:35:23,954] [ INFO] - Evaluation on dev dataset start [2020-04-27 19:35:29,623] [ EVAL] - [dev dataset evaluation result] loss=1.19437 acc=0.61538 [step/sec: 2.32] [2020-04-27 19:35:29,624] [ INFO] - Load the best model from cv_finetune_turtorial_demo/best_model [2020-04-27 19:35:29,953] [ INFO] - Evaluation on test dataset start [2020-04-27 19:35:31,332] [ EVAL] - [test dataset evaluation result] loss=1.20542 acc=0.83333 [step/sec: 2.59] [2020-04-27 19:35:31,334] [ INFO] - Saving model checkpoint to cv_finetune_turtorial_demo/step_189 [2020-04-27 19:35:32,278] [ INFO] - PaddleHub finetune finished.# 预测 # 当Finetune完成后,我们使用模型来进行预测,先通过以下命令来获取测试的图片 import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mpimg with open("dataset/test_list.txt","r") as f: filepath = f.readlines() data = [filepath[0].split(" ")[0],filepath[1].split(" ")[0],filepath[2].split(" ")[0],filepath[3].split(" ")[0],filepath[4].split(" ")[0]] label_map = dataset.label_dict() index = 0 run_states = task.predict(data=data) results = [run_state.run_results for run_state in run_states] for batch_result in results: print(batch_result) batch_result = np.argmax(batch_result, axis=2)[0] print(batch_result) for result in batch_result: index += 1 result = label_map[result] print("input %i is %s, and the predict result is %s" % (index, data[index - 1], result)) [2020-04-27 19:37:08,918] [ INFO] - PaddleHub predict start [2020-04-27 19:37:08,996] [ INFO] - The best model has been loaded share_vars_from is set, scope is ignored. [2020-04-27 19:37:10,544] [ INFO] - PaddleHub predict finished. [array([[6.65915251e-01, 1.50493905e-01, 3.18900719e-02, 1.36465594e-01, 1.52352415e-02], [5.85734379e-04, 9.93534088e-01, 2.54869647e-03, 1.84836087e-03, 1.48322794e-03]], dtype=float32)] [0 1] input 1 is dataset/test/yushuxin.jpg, and the predict result is 虞书欣 input 2 is dataset/test/xujiaqi.jpg, and the predict result is 许佳琪 [array([[7.4708308e-03, 2.1471712e-01, 1.1480367e-02, 7.4527597e-01, 2.1055693e-02], [4.2892623e-04, 1.2857275e-04, 8.7951841e-05, 9.9891067e-01, 4.4397759e-04]], dtype=float32)] [3 3] input 3 is dataset/test/zhaoxiaotang.jpg, and the predict result is 安崎 input 4 is dataset/test/anqi.jpg, and the predict result is 安崎 [array([[0.05975387, 0.29274008, 0.19715454, 0.14172643, 0.30862507]], dtype=float32)] [4] input 5 is dataset/test/wangchengxuan.jpg, and the predict result is 王承渲Day5-EasyDL体验与大作业发布
飞桨的使用方法通常是下载安装包后,配置本地环境,通过使用飞桨的工具集和API在本地算力环境上完成模型开发;üEasyDL是飞桨的企业版,一个云端平台,集成了飞桨框架,预置了完善的开发环境、模型训练集群及任务调度机制,同时提供数据服务、模型训练完成后的服务部署,开发者上手即用。
EasyDL与AI Studio的关系:
AI Studio用于学习实践,提供编程环境、算力、让大家自由发挥;üEasyDL偏向企业应用,经典版适合AI零基础或追求高效率开发的企业和个人开发者,专业版内置预训练模型,开放的脚本调参是限于某些超参和部分网络结构,同时还有一些自动化调优的机制,帮助提升模型效果。
第一步:爱奇艺《青春有你2》评论数据爬取。
第二步:词频统计并可视化展示。
第三步:绘制词云。
第四步:结合PaddleHub,对评论进行内容审核。# 需要的配置和准备 !pip install jieba !pip install wordcloud # Linux系统默认字体文件路径 !ls /usr/share/fonts/ # 查看系统可用的ttf格式中文字体 !fc-list :lang=zh | grep ".ttf" !wget https://mydueros.cdn.bcebos.com/font/simhei.ttf # 下载中文字体 #创建字体目录fonts !mkdir .fonts # # 复制字体文件到该路径 !cp SimHei.ttf .fonts/ #安装模型 !hub install porn_detection_lstm==1.1.0 !pip install --upgrade paddlehub from __future__ import print_function import requests import json import re #正则匹配 import time #时间处理模块 import jieba #中文分词 import numpy as np import matplotlib import matplotlib.pyplot as plt import matplotlib.font_manager as font_manager from PIL import Image from wordcloud import WordCloud #绘制词云模块 import paddlehub as hub #请求爱奇艺评论接口,返回response信息 def getMovieinfo(url): ''' 请求爱奇艺评论接口,返回response信息 参数 url: 评论的url :return: response信息 ''' session = requests.Session() headers = { "User-Agent": "Mozilla/5.0", "Accept": "application/json", "Referer": "https://m.iqiyi.com/v_19rqriflzg.html", "Origin": "https://m.iqiyi.com", "Host": "sns-comment.iqiyi.com", "Connection": "keep-alive", "Accept-Language":"en-US,en;q=0.9,zh-cn;q=0.8,zh;q=0.7,zh-TW;q=0.6", "Accept-Encoding":"gzip,deflate" } response = session.get(url,headers=headers) if response.status_code == 200: return response.text return None #解析json数据,获取评论 def saveMovieInfoToFile(lastId,arr): ''' 解析json数据,获取评论 参数 lastId:最后一条评论ID arr:存放文本的list :return: 新的lastId ''' url = "https://sns-Comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118& agent_version=9.11.5&business_type=17&content_id=15068699100&page_size=10&types=time&last_id=" url += str(lastId) responseTxt =getMovieinfo(url) responseJson = json.loads(responseTxt) comments = responseJson["data"]["comments"] for val in comments: if "content" in val.keys(): print(val["content"]) arr.append(val["content"]) lastId = str(val["id"]) return lastId #去除文本中特殊字符 def clear_special_char(content): ''' 正则处理特殊字符 参数 content:原文本 return: 清除后的文本 ''' s = re.sub(r"</?(.+?)>| |t|r","",content) s = re.sub(r"n"," ",s) s = re.sub(r"*","\*",s) s = re.sub('[^u4e00-u9fa5^a-z^A-Z^0-9]','',s) s = re.sub('[�01�02�03�04�05�06�07x08x09x0ax0bx0cx0dx0ex0fx10x11x12x13x14x15x16x17x18x19x1a]+', '',s) s = re.sub('[a-zA-Z]','',s) s = re.sub('^d+(.d+)?$','',s) highpoints = re.compile(u'[uD800-uDBFF][uDC00-uDFFF]') s = highpoints.sub(u'', s) return s def fenci(text): ''' 利用jieba进行分词 参数 text:需要分词的句子或文本 return:分词结果 ''' jieba.load_userdict("add_words.txt") #添加自定义字典 seg = jieba.lcut(text,cut_all=False) return seg def stopwordslist(file_path): ''' 创建停用词表 参数 file_path:停用词文本路径 return:停用词list ''' stopwords = [line.strip() for line in open(file_path,encoding="UTF-8").readlines()] return stopwords def movestopwords(sentence,stopwords,counts): ''' 去除停用词,统计词频 参数 file_path:停用词文本路径 stopwords:停用词list counts: 词频统计结果 return:None ''' out = [] for word in sentence: if word not in stopwords: if len(word) !=1: counts[word] = counts.get(word,0)+1 return None def drawcounts(counts,num): ''' 绘制词频统计表 参数 counts: 词频统计结果 num:绘制topN return:none ''' x_aixs = [] y_aixs = [] c_order = sorted(counts.items(),key=lambda x:x[1],reverse=True) for c in c_order[:num]: x_aixs.append(c[0]) y_aixs.append(c[1]) # 设置显示中文 matplotlib.rcParams["font.sans-serif"] = ["SimHei"] matplotlib.rcParams["axes.unicode_minus"] = False plt.bar(x_aixs,y_aixs) plt.title("词频统计结果") plt.show() def drawcloud(word_f): ''' 根据词频绘制词云图 参数 word_f:统计出的词频结果 return:none ''' clound_mask = np.array(Image.open("cloud.jpg")) st = set(["东西","这是"]) wc = WordCloud(background_color="white", mask=clound_mask, max_words=150, font_path="simhei.ttf", min_font_size=10, max_font_size=100, width=400, relative_scaling=0.3, stopwords=st) wc.fit_words(word_f) wc.to_file("pic.png") def text_detection(text,file_path): ''' 使用hub对评论进行内容分析 return:分析结果 ''' porn_decetion_lstm = hub.Module(name="porn_detection_lstm") f = open("aqy.txt","r",encoding="utf-8") for line in f: if len(line.strip()) == 1: continue else: test_text.append(line) f.close() input_dict = {"text":test_text} results = porn_decetion_lstm.detection(data=input_dict,use_gpu=True,batch_size=1) for index,item in enumerate(results): if item["porn_detection_key"] == "porn": print(item["text"],":",item["porn_probs"]) #评论是多分页的,得多次请求爱奇艺的评论接口才能获取多页评论,有些评论含有表情、特殊字符之类的 #num 是页数,一页10条评论,假如爬取1000条评论,设置num=100 if __name__ == "__main__": num =120 lastId = "0" arr = [] with open("aqy.txt","a",encoding = "utf-8") as f: for i in range(num): lastId = saveMovieInfoToFile(lastId,arr) time.sleep(0.5) for item in arr: Item = clear_special_char(item) if Item.strip()!='': try: f.write(Item+"n") except Exception as e: print("含有特殊字符") print("共爬取评论:",len(arr)) f = open("aqy.txt","r",encoding="utf-8") counts = {} for line in f: words = fenci(line) stopwords = stopwordslist("cn_stopwords.txt") movestopwords(words,stopwords,counts) drawcounts(counts,8) drawcloud(counts) f.close() file_path = "aqy.txt" test_text = [] text_detection(test_text,file_path)虞书欣加油😊 不需要在意别人的看法 加油😊你是最棒的[色] 谢可寅是不是参加过【下一站传奇】 不要让王承渲成为第二个李子璇成为遗憾 王承渲出道 一个说是努力就能成功却还是看人气的节目,讽不讽刺?一个不算努力也没实力的人还是靠着人气第一,那些真的昼夜努力的却以为努力就能成功。 终于想起赵小棠像谁了[偷笑]像火凤凰里的芭比 现在估计很多人喜欢那些傻的吧,现在什么药水哥,giao哥都能火,只能说现在人太盲目了,自己喜欢的就什么都好,毫无理性可言 次 看到安崎一点点变强大,有更多的人喜欢她,真的感觉好快乐。 对排名有些疑惑,人类迷之行为,不懂 我文哲啊!! 安崎!!冲C位冲C位冲C位!!!! 一点都不喜欢虞书欣 刘雨昕值得!!!!! 心情跌宕起伏的时候就会看这个。[微笑]有没有跟我一样的。让我们上高层! 王承渲说话好像有口音 爱你!! 赵小棠和虞书欣用最放松的笑容说着最心酸的话💔 怎么助力? 帮帮投虞书欣我手上有多余的票 刘雨昕冲啊!!! …… Building prefix dict from the default dictionary ... 2020-04-28 15:41:45,616-DEBUG: Building prefix dict from the default dictionary ... 共爬取评论: 1197 Dumping model to file cache /tmp/jieba.cache 2020-04-28 15:41:46,435-DEBUG: Dumping model to file cache /tmp/jieba.cache Loading model cost 0.891 seconds. 2020-04-28 15:41:46,508-DEBUG: Loading model cost 0.891 seconds. Prefix dict has been built successfully. 2020-04-28 15:41:46,510-DEBUG: Prefix dict has been built successfully. [2020-04-28 15:41:52,597] [ INFO] - Installing porn_detection_lstm module Downloading porn_detection_lstm [==================================================] 100.00% Uncompress /home/aistudio/.paddlehub/tmp/tmpnjjsmns9/porn_detection_lstm [==================================================] 100.00% [2020-04-28 15:41:55,880] [ INFO] - Successfully installed porn_detection_lstm-1.0.0 [2020-04-28 15:41:55,971] [ INFO] - 0 pretrained paramaters loaded by PaddleHub 喻言刘雨欣曾可妮谢可寅刘令姿许佳琪这几个比较适合色色 : 0.9986 我也喜欢虞书欣色色色 : 0.9947 喻言刘雨欣曾可妮谢可寅刘令姿许佳琪这几个比较适合色色 : 0.9986 我也喜欢虞书欣色色色 : 0.9947 陆柯燃林凡冲鸭加油啊大家看看这两个吧真的很好啊 : 0.7359 让我康下我昕姐的粉在哪里吖刘总真的太了好爱好爱色 : 0.7552 刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣啊啊啊啊妈妈爱你嗷嗷嗷嗷嗷么么哒亲亲亲亲亲亲亲亲加油喔 : 0.8556 喻言刘雨欣曾可妮谢可寅刘令姿许佳琪这几个比较适合色色 : 0.9986 陆柯燃林凡冲鸭加油啊大家看看这两个吧真的很好啊 : 0.7359 让我康下我昕姐的粉在哪里吖刘总真的太了好爱好爱色 : 0.7552 刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣刘雨欣啊啊啊啊妈妈爱你嗷嗷嗷嗷嗷么么哒亲亲亲亲亲亲亲亲加油喔 : 0.8556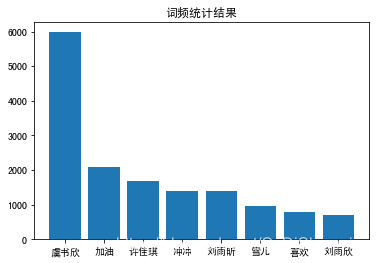
display(Image.open('pic.png')) #显示生成的词云图像
AI在线体验
这里有很多新奇有趣的深度学习应用,下面是计算机视觉和自然语言处理方面的两个例子。


2、AI Studio一站式深度学习开发平台
AI Studio新手指南,可参考官方使用文档:https://ai.baidu.com/ai-doc/AISTUDIO/Tk39ty6ho


3、PaddleHub
PaddleHub就是为了解决对深度学习模型的需求而开发的工具。基于飞桨领先的核心框架,精选效果优秀的算法,提供了百亿级大数据训练的预训练模型,方便用户不用花费大量精力从头开始训练一个模型。
PaddleHub的官网:https://www.paddlepaddle.org.cn/hub
PaddleHub的github地址:https://github.com/PaddlePaddle/PaddleHub


4、飞桨企业版EasyDL:一站式AI开发平台
EasyDL是百度大脑面向企业开发者推出的AI开发平台,提供智能标注、模型训练、服务部署等全流程功能。内置丰富的预训练模型,支持公有云/私有化/设备端等灵活部署方式。EasyDL面向不同人群提供经典版、专业版、零售版三款产品,已在工业、零售、制造、医疗等领域落地。
官方网站:https://ai.baidu.com/easydl/

飞桨官网:https://www.paddlepaddle.org.cn
飞桨GitHub:https://github.com/paddlepaddle/paddle
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










