屠龙少女的世界可可爱爱没道理 1. 创新点 (1) 外观特征loss (2) 结构特征loss 其中 σ为标准差,S上横线是平均值,S~是中间值。作者发现γ1 = 20,γ2 = 40 ,-µ= 1.2能得到较好的结果 (3) 纹理特征loss Frcs公式如上图所示,把RGB三个通道分开处理,Y表示的是RGB图转化成的灰度图。在本实验中α等于0.8,而β1、2、3则在-1~1之间随机。 (4) 总损失(可以通过改变损失函数中每个特征loss的权重来调整卡通化结果的样式) 这篇文章参数设置如下: Lcontent是为了让经过生成器后的真实图像语义内容不变,这里也用到了预训练后的VGG。 (5)生成器结构 (6)鉴别器结构 (7)实验对比 性能与型号大小对比,LR表示256256分辨率,HR表示7201280分辨率 [20] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision, pages 694–711. Springer, 2016. 1, 3, 5, 7, 8 分类精度和FID评价。通过计算原图像分布和目标图像分布之间的距离,使用Frechet Inception Distance (FID)来评估性能。 可优化点 好了 ,完结撒花!!!!! [1]Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycleconsistent adversarial networks. In Proceedings of IEEE InternationalConferenceonComputerVision,2017. 1,3,5,7, 8
White-box-Cartoonization_CVPR_2020
好了 进入正题 话不多说 快上车
新鲜出炉的CVPR2020 白盒卡通化阅读笔记
Learning to Cartoonize Using White-box Cartoon Representations
github地址:https://github.com/SystemErrorWang/White-box-Cartoonization

(1)提出了三种白盒卡通化的特征表示法。
(2)卡通图像光滑表面的外观特征。
(3)表示稀疏颜色块和平化全局内容的结构特征。
(4)反映卡通图像中高频纹理、轮廓和细节的纹理特征。
2. 数据集
对于真实世界的照片,从FFHQ数据集收集了10000张人脸图像,从[1]数据集收集了5000张风景图像。对于卡通图像,收集了10000张人脸动画图像和10000张风景图片。动画图像来自于京都动画,新海诚、细田守、宫崎骏。对于验证集,收集了3011张动画图像和1978年的真实照片,图片来自于div2k数据集。测试的图片来自于Internet和Microsoft COCO数据集,在训练过程中,所有的图像都被调整为256*256分辨率,并且每5次迭代中只对人脸图像进行一次送入。
3.模型结构
(1)提出了一种基于生成器G和两个鉴别器Ds和Dt的GAN框架。
(2)Ds用于区分从模型输出和动画中提取的表面表示。
(3)Dt用于区分从输出和动画中提取的纹理表示。
(4)预训练的VGG网络用于提取高级特征,并在提取的结构特征和输出之间以及输入照片和输出之间对全局内容施加空间约束。每个组件的权重可以在loss函数中进行调整,这允许用户控制输出样式并根据不同的情况调整模型。
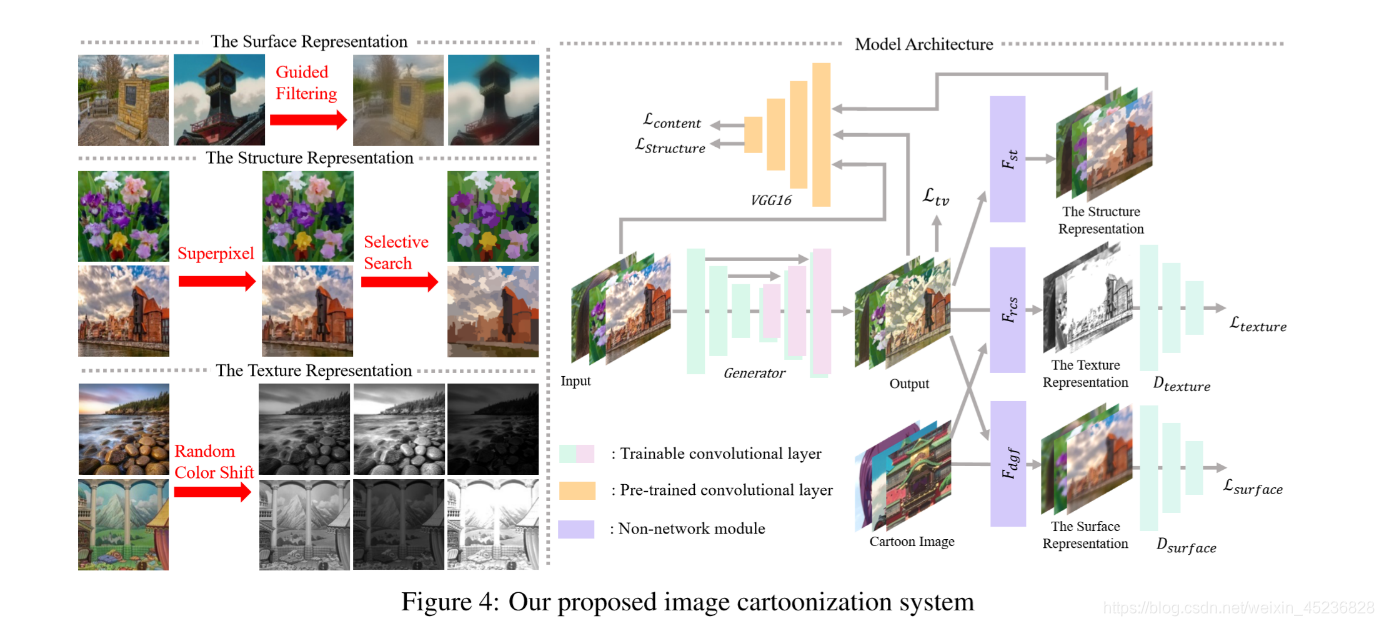
定义了一个网络Fdgf,以图片I为输入,并以它自己为guide map,对图像做一个平滑化,输出提取的去掉纹理和细节的外观特征Fdgf(I,I)。判别器Ds用来判断真实图像和生成的卡通图的外观特征是否一致。其中Ic为生成的卡通图,Ip为真实图。

使用了“adaptive coloring”,一个分段函数来对图像进行颜色分割:


这里的VGGn在源码中使用的是VGG19 conv4_4之前的网络层来提取图像的高级特征。
亮度和颜色会影响分辨真实和卡通图片,作者把RGB图转为了单通道的图也就是灰度图,排除亮度和颜色的影响。

此处也定义了一个Dt判别器,来判断经过Frcs后的输出是来自生成器生成的还是动漫图。


λ1 = 1
λ2 = 10
λ3 = 210^3
λ4 = 210^3
λ5 = 10^4
其中Ltv是为了降低总方差,可以促进生成图像的平滑,并减轻高频的噪音。H, W, C表示图像的空间维数


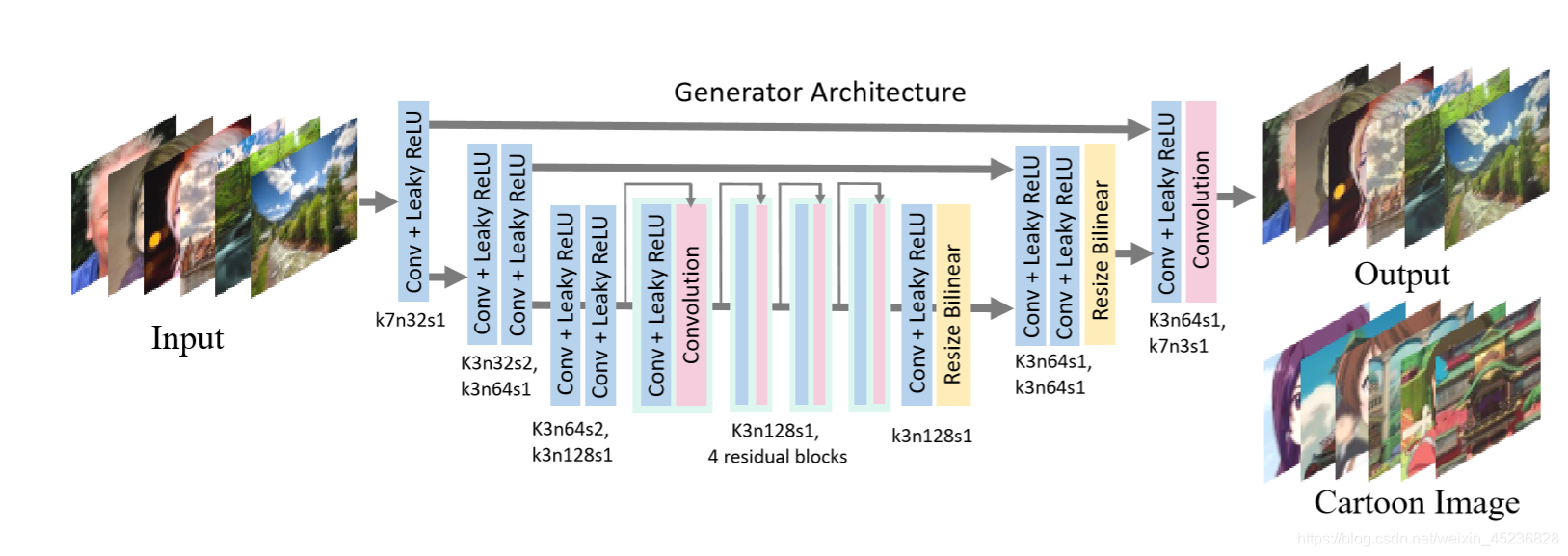
生成器网络是一个全卷积的类似于u – net的网络。使用stride2的卷积层作为下采样层,使用双线性插值层作为上采样层,以避免棋盘效应。该网络仅由三种层组成:卷积层、,LeakyReLU(LReLU)、(bilinear resize)双线性层。
PatchGAN适用于鉴别器网络,其中最后一层是卷积层。输出feature map中的每个像素对应于输入图像中的一个patch, patch的大小等于感知域,用来判断patch是属于卡通图像还是生成的图像。PatchGAN增强了识别细节和加速应变的能力。在每个卷积层(最后一层除外)之后谱归一化(Spectral normalization),对网络进行Lipschitz约束,稳定训练


[6] Yang Chen, Yu-Kun Lai, and Yong-Jin Liu. Cartoongan: Generativeadversarialnetworksforphotocartoonization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9465–9474, 2018. 1, 3, 5, 7, 8
[48] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycleconsistent adversarial networks. In Proceedings of IEEE InternationalConferenceonComputerVision,2017. 1,3,5,7, 8

4.总结
可以通过改变损失函数中每个特征loss的权重来调整卡通化结果的样式。
(1)大部分的图像卡通化对风景或者生活场景有较好的主观效果,对于人物主观效果较差,脸部轮廓、纹理不明显,色彩不平滑过渡效果较差,色块区分过于明显。猜测应该是人脸的数据集分布较少,可以研究如何利用局部的面部特征来提高人脸的卡通化。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











