最近老妈在用word给文字添加拼音的时候遇到了这样的问题,对于一段话,word的拼音是直接放在文字的头上,因此对这段话复制的时候就会出现文字拼音交杂的情况(如下图),想要得到这段文字完整的拼音需要手动处理。(因为她不懂正则表达式,笑) 因此我用python简单的对这项任务进行了封装,以下是我的代码: 这一工具简单实现了拼音文字分离的问题,并且容易上手,不足之处在于 (1)输出的文字选中需要按快捷键ctrl+A进行全选 (2)不能自动识别分离拼音中的词语,比如měidāng,可以考虑添加拼音分割的功能,设计规则实现词的分割。

#使用了tkinter图形化界面 import re import tkinter import tkinter.messagebox root= tkinter.Tk() root.title('文字拼音分离') root.geometry('700x650') #窗口大小 contentVar=tkinter.StringVar(root,'') contentEntry=tkinter.Entry(root,textvariable=contentVar) contentEntry.place(x=50,y=50,width=600,height=200) hz = tkinter.Entry(root) #汉字输出框 hz.place(x=50,y=500,width=600,height=50) py = tkinter.Entry(root) #拼音输出框 py.place(x=50,y=570,width=600,height=50) btn=tkinter.Button(root,text='开始转换',bg = 'pink',command=lambda:Click()) #点击按钮开始转换 btn.place(x=310,y=400,width=80,height=40) def Click(): #根据正则表达式的替换 content=contentVar.get() #获取输入框内容 hanzi = ''.join(re.findall('[u4e00-u9fa5]|[()《》——;,。“”<>!]',content)) pinyin = ''.join(re.findall('[^u4e00-u9fa5]|[()《》——;,。“”<>!]',content)).replace('(','').replace(')',' ') #在词与词之间添加一些空格 hz.insert(0,hanzi) py.insert(0,pinyin) root.mainloop()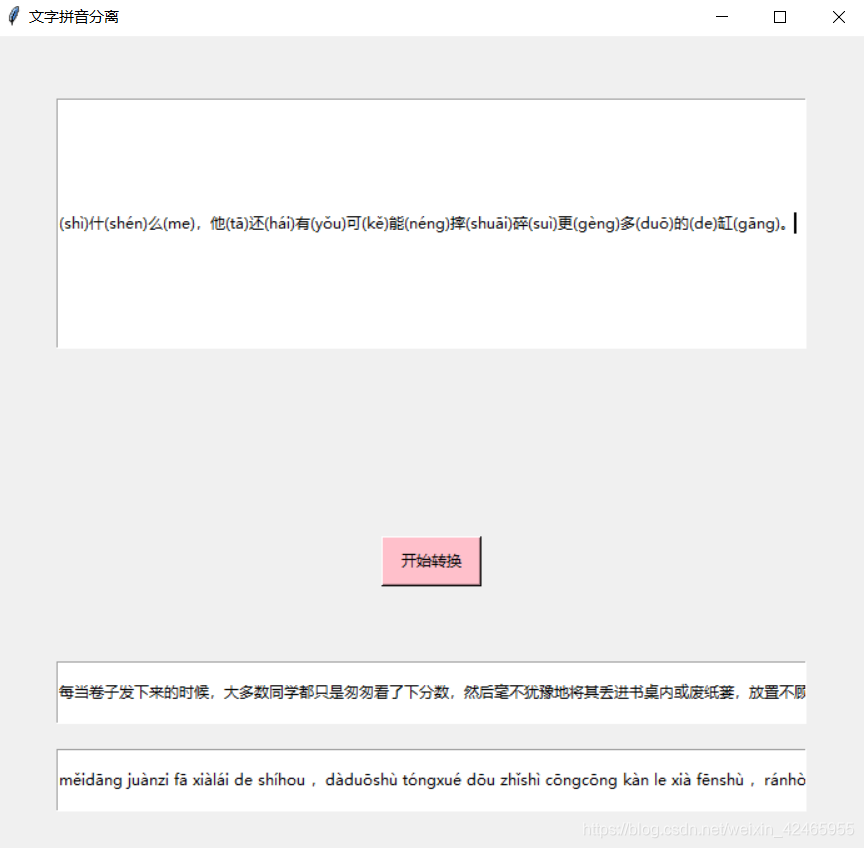
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











