在这个到处都充斥着互联网和人工智能的时代,你真的了解它吗?可曾想过你每天都在浏览的网页信息都被无数只网络爬虫监控着?你也可能有听到过这样一个名词,但是你真的了解它吗? 爬虫,即自动化的网页抓取程序,它能从网络中的大量网页里提取出所需的信息。同时它也有一个很特殊而又接地气的名字‘网络蜘蛛’。 网络蜘蛛是通过网页的链接地址来寻找网页。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。 如果把整个互联网当成一张紧密的蜘蛛网的话,一个个网站就是这张蜘蛛网的网结,而网站的链接就是这张蜘蛛网的网线,那么网络蜘蛛就可以用这个结点和连接各个结点的网线把互联网上所有的网页都抓取下来。 这样看来,网络蜘蛛就是一个爬行程序,一个抓取网页的程序。 有关网络爬虫的相关技术如下图所示; 如HTML 和简单的 JavaScript。浏览器与 Web 服务器之间的通信采用 HTTP 协议, 所以基本的 HTTP 知识也不能少。这些网页相关的基本知识,对于爬虫系统的开发和运营有着至关重要的的作用。 与此同时,爬虫需要模拟浏览器来向 Web 服务器发起请求,以获取网页内容。在这里就可以用到 Python 的标准库 urllib,或者更好用的第三方库 requests 来达到这个目的。 拿到网页内容后,需要同时对网页进行解析,提取出其中的所需要的信息,或该网页上的其它网页链接。这时需要用到 Python 第三方库 Beautiful Soup 或 pyquery。 以上的抓取、解析过程也可以直接用专业的爬虫框架来完成,如 Scrapy,这是一种更工程化的方式。同时对于爬虫系统的开发也相对来说更加的便捷和正式。 我们也知道,网络爬虫是对整个网站中的几乎所有链接进行访问和抓取,在这其中也难免会有很多的重复网页被多次抓取,这样就造成了爬虫系统在运营过程中的效率低下, 所以当待抓取的网页数量很大时,这时需要格外注意网页判重的效率,也就是说需要有一种高效的方式来检查一个网页是否之前被抓取过,这就要用到布隆过滤器了。 Redis 支持布隆过滤器扩展,能方便解决这个问题。并且对抓取的网页有很好的甄别能力。 也可以理解为让多只网络蜘蛛在同一张网上捕食,这时的我们就需要一个分布式队列来统一管理、调度所有的抓取任务,Scrapy-Redis 可以做这件事。 关于以上提到的相关知识和免费课程,大灰狼已经为大家总结好了。直接点击就可以跳转链接。 入门资料; 了解和认识爬虫的最基本架构和运行流程,《Python开发简单爬虫》 关于Scrapy 的基本使用;《Python最火爬虫框架Scrapy入门与实践》 Scrapy 的详细内容可以阅读翻译文档《Scrapy入门教程》 MySQL 数据库入门,免费课程《与MySQL的零距离接触》 MongoDB 数据库入门,参看 W3Cschool 在线教程《MongoDB教程》 至于前面所涉及技术的全面讲解,可以阅读图书《Python3网络爬虫开发实战》 之后大灰狼也会陆续跟大家Python在机器学习、自动化运维与测试等方面的资讯。 同时你也可以关注我的微信公众号“灰狼洞主”获取更多Python技术和互联网资讯。 觉得有用的记得关注喔,大灰狼期待与你一同进步!

到底什么是网络爬虫?今天大灰狼就来和大家简单的一下。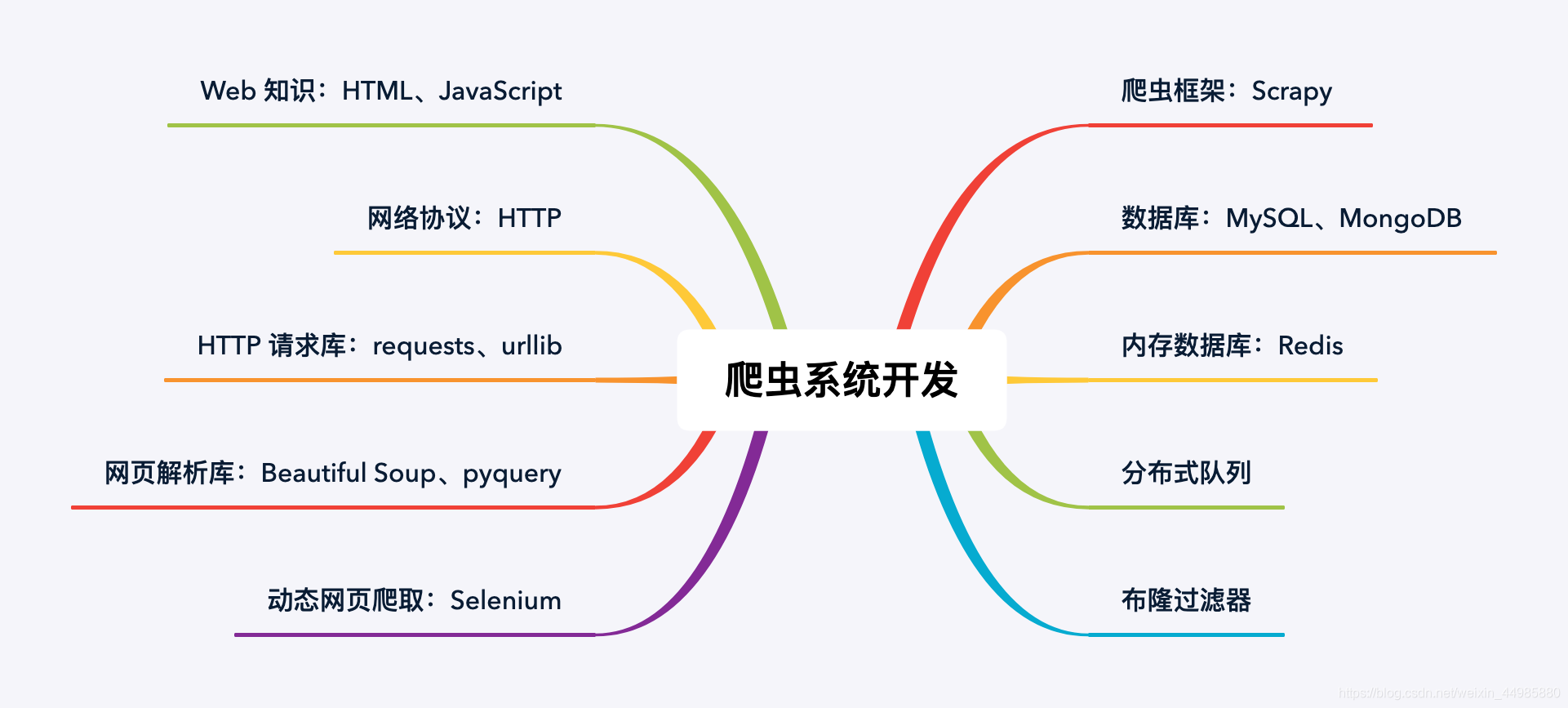
因为爬虫系统是从网页中提取内容,所以我们首先需要掌握基本的网页知识,
从网页中提取出来的有用信息,如果数据量不大,那么可以保存在文件中,但通常更通用更专业的做法是保存在数据库中,可以选择关系型数据库 MySQL 或非关系型数据库 MongoBD来存储这些从网页中提取出来的信息。
然而互联网是一个相当庞大的系统网络,当待抓取的网页数量进一步扩大时,单机的爬虫程序效率就十分低下了,这时就需要考虑构建分布式的爬虫程序。也就是说在多台机器上同时来跑爬虫任务。
。
。
。
的免费在线版,基本上所有的爬虫相关知识和工具都有覆盖,大灰狼觉得还是值得一读的。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











