Redis缓存最突出的特点就是高性能,高并发,我们在项目里面缓存主要用在以下几个方面: 使用缓存可能会带来以下问题: Redis有一下几种数据类型 我们都知道Redis是使用单线程的,Redis的线程模型如图 为什么Redis单线程还那么快? Redis的数据在过期了之后不会马上全部删除,Redis会定时的(每隔100ms)删除一部分数据,同时如果在执行get操作的时候发现数据已经过期了,那么,会把这个数据删除掉。 这个取决于设置的Redis内存淘汰机制,一般来说Redis的内存的淘汰策略有下面几种: 1. noeviction 设计一个LRU淘汰算法可以基于LinkedHashMap来实现 主从模式的结构图如下 主从复制的流程 sentinel,哨兵,是redis 里面的一个组件,用来实现 哨兵是用来实现高可用的,所以它本身也是分布式的,作为一个哨兵集群去运行, 互相协同工作。 Redis提供了RDB和AOF两种持久化方式 在搭建了主从哨兵模式之后可以看到Redis实现了高可用,但是Redis的容量还是只有一台机器的容量,如果想要给Redis增加容量是不行的,这时候就需要使用Redis集群了(在Redis5.X版本之后已经不需要安装插件就可以搭建集群了) 分布式寻址算法一般有: 一致性哈希算法 RedisCluster的hash slot 算法 缓存穿透问题 缓存雪崩的问题 Redis的双写一致性指的是如何保证数据库和缓存之间的数据一致性 2、更新之前删除 但是这样还是会有问题。如果在并发很高的情况下,缓存被删除了,DB操作还没有完成,这时候另一个请求进行了查询,那么缓存里面又会存储旧的值,导致缓存不一致的情况。怎么解决? Redis的竞争问题类似于多线程编程里面的线程安全的问题。尽管Redis本身是线程安全的,但是如果业务不是线程安全的那么还是会出现竞争问题。比如需要把一个key先修改为1,然后改为2,然后改为3,注意:这些操作是并发的 我们的生产环境部署的Redis是使用集群的方式来部署的,一共有六台机器,三主三从,每台机器提供给Redis进程的内存是8G,
文章目录
在项目中如何使用缓存的?
缓存使用不当会有哪些后果?
Redis都有哪些数据类型?使用场景是什么?
最简单的数据类型,get、set就可以
集合类型,可以存储数据集合,和java里面的list类似,可以分页查询,甚至还可以做成一个简单的消息队列
set类型,是一个自动去重的集合,可以用来求交集什么的等等
一个可排序的不重复的集合,可以用来做排行榜什么的
哈希类型,可以存储一些简单的对象Redis的线程模型是什么?为什么单线程还快?
在图中我们可以看到,当Redis客户端去连接Redis服务器的时候会连接服务器的ServerSocket,也就是6379端口,然后把时间亚茹队列里面,等到文件事件选择器收到了时间之后判断如果是连接事件,那么就会创建一个Socket01(图中的S1)与当前的客户端保持连接,同时还会把S1 的READABLE事件和命令请求处理器进行关联,这时候如果Client1发送了一个请求过来,比如是一个Set请求,那么Client1 会把请求发送到S1,然后多路复用器会把事件压到队列里面,文件事件选择器会把接收到的命令请求转发给命令请求处理器去处理,然后处理完成之后把命令回复处理器与S1的WRITEABLE事件进行关联,然后命令恢复处理器会恢复给S1一个响应(比如OK)然后命令回复处理器解除和S1的关联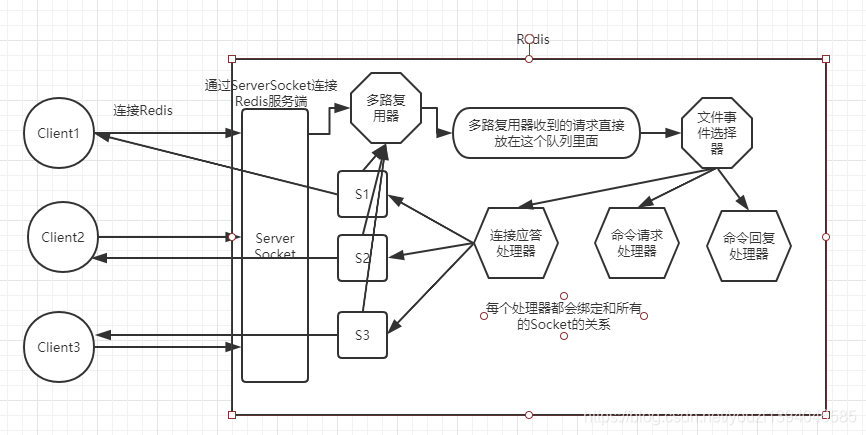
Redis的缓存过期了会立即删除吗?
也就是Redis的过期策略是 定期删除+惰性删除Redis内存满了Redis会怎么做?
如果空间不不足了,会直接报错,不允许插入
2. allkeys-lru
如果空间满了会删除掉最少使用的key
3. allkeys-random
如果空间满了会随机删除掉一个key
4. volatile-lru
会在设置了过期时间的key里面删除最近最少使用的key
5. volatile-random
会在设置了过期时间的key里面随机删除一个key
6. volatile-ttl
会删除掉快要过期的key
一般来说我们使用allkeys-lru策略会比较多如何实现一个LRU算法
public class LRUCache extends LinkedHashMap<K,V>{ private final int SIZE ; public LRUCache(int size){ super(size,0.75f,true); SIZE= size; } protected boolean removeEldestEntry(){ return this.size()>SIZE; } } 如何保证Redis的高并发、高可用
可以使用主从架构,把写操作放在主节点上面执行,从节点执行读操作,这样就提高了Redis的并发效率,不过这样也会有有一个问题。如果Redis主节点挂了怎么办?
在原有的主从模式下面,使用哨兵模式,当主节点挂掉的时候哨兵模式会把存活的从节点升级为主节点,实现主从切换主从复制的原理是啥?
主节点负责数据写入,同时会异步把写入的数据发送给从节点
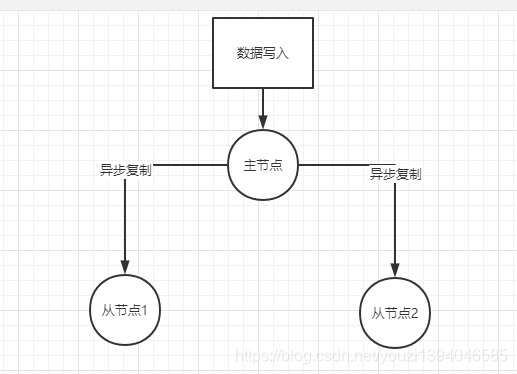
主从复制分为全量复制和增量复制,
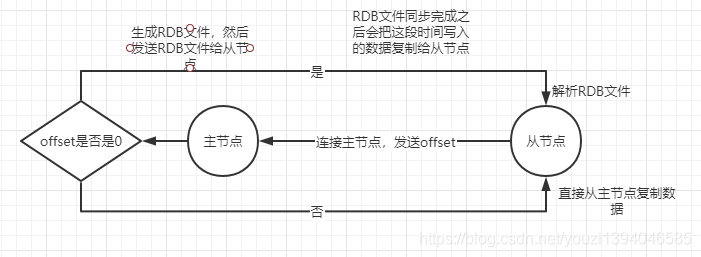
全量复制:当从节点首次连接master的时候主节点会进行一次全量复制,生成一份RDB快照文件发送给从节点(同时这期间新写入的数据会写到缓冲区),从节点解析RDB文件,解析完成之后反馈到主节点,直接点再把缓冲区的数据异步发送给从节点
增量复制:从节点和主节点都会记录当前数据同步的offset来保证数据的一致性,当从节点断开连接之后再重新连接,会从offset记录的位置开始继续同步
哨兵机制的原理是啥?
集群监控:
负责监控Redis的Master和Salve是否有正常工作
消息通知:
如果某一个节点发生了故障,那么会报警给管理员
故障转移:
如果master挂掉了,会立即提升salve为master
配置中心:
故障 转移完成之后,通知client客户端新的master地址
哨兵模式仅仅是保证了系统的高可用,并没有保证数据不丢失。
哨兵模式要求节点最少有3个,不然会发生脑裂问题
脑裂问题:
当一个从节点与master之间出现了网络问题,无法连接,那么这个从节点会变成主节点,这时候系统中就存在了两个主节点,这时候就发生了脑裂问题。
脑裂问题导致数据丢失:
由于发生了脑裂,系统里面存在了两个主节点,client的写请求会发送到其中一个主节点,但是,当发生脑裂的另一个主节点重新连接上集群之后,原先写入数据的master可能就会变为slave,然后与master进行数据同步,slave上面的数据被清空,导致这一部分数据丢失Redis的持久化机制有哪些?RDB和AOF的优缺点?
RDB持久化适合做数据的冷备份。使用RDB持久化方式Redis会每隔一段时间(可自定义,一般5分钟)进行一次数据快照的创建,所以数据会有一段时间的延迟
如果开启AOF持久化,Redis会在每次指令执行同时把指令日志以append only的方式写入OSCache,然后每隔1秒钟刷新到磁盘。
使用RDB做备份对Redis几乎性能影响,不过如果间隔时间太长,可能导致RDB文件太大,生成时间过长,也会对性能有一定影响,RDB每次都会生成一个新的文件,方便冷备
使用AOF的方式会对Redis的性能有些微的影响,因为在写入Redis的时候还要去写OSCache,不过AOF的数据是比较完整的,由于是基于指令日志的备份,所以在数据恢复的时候是会稍微慢一些
一般推荐两种持久化方式都开启Redis的集群工作原理是什么?
Redis集群的特点:
1、Redis集群会自动对数据进行分片,每一个master上面存放一部分数据
2、Redis集群内部提供高可用,部分的master挂掉系统仍然可用
RedisCluster架构下会开放两个端口,一个是原先的6379端口,用来进行客户端通信,在一个就是16379用来进行集群通信,使用gossip协议进行通信,减少网络带宽的占用分布式寻址有哪些算法?什么是一致性hash算法?如何动态增加和删除一个节点?
哈希算法
哈希算法是最简单的分布式寻址算法,其原理就是根据请求数据的哈希值,然后对节点数进行取模运算,把请求落在不同的节点上面,哈希算法实现简单,但是有一定的缺点,比如如果突然有一个节点下线了,那么哈希取模的结果就会发生变化,会导致系统大部分数据都不可用。
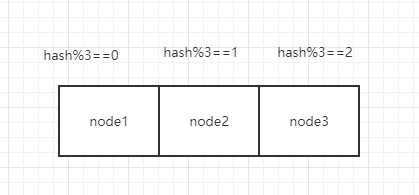
由于哈希算法的缺陷,所以出现了一致性hash算法。
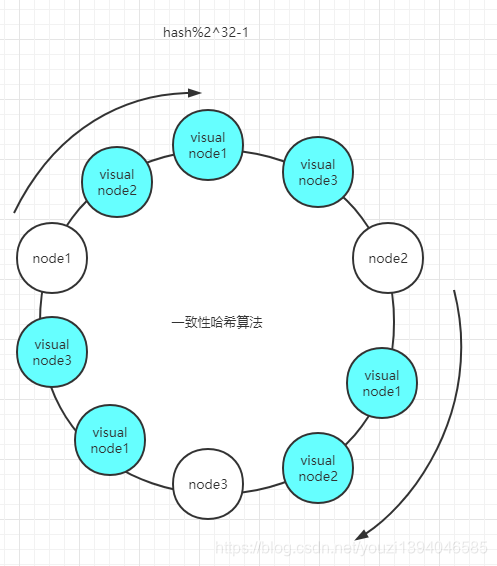
1、那什么是一致性hash算法?
哈希一致性算法想象成为一个环状的图,上面有 0-2^32-1 个槽位,每一台机器可以分散在每个槽位上面,把请求数据以 2^32-1 取模,然后把取模结果落在哈希环上面,一致性哈希算法会顺时针寻找,直到找到一个节点,然后把数据落到那个节点上面。
2、哈希环偏斜怎么解决
哈希环偏斜是指多个节点相隔很近,导致像个的比较远的节点除了故障之后会丢失比较多的数据。如图,为了解决这个问题引入了一部分虚拟节点(实际节点的复制品)这样节点数越多那么分布也就越分散
在一致性哈希算法中,如果某一个节点挂掉,由于取模结果不变,所以之前的数据还是会落到和之前一样的节点上面,新的数据会落到顺时针方向后面的一个可用节点上面
在Redis的HashSlot算法中,Redis会有16384个hash槽,如果我们有3个节点,那么Redis会把这16384个hash槽进行平均分配,到每一个节点上面,如果这时候添加了一个节点,那么Redis会重新分配hash槽,然后把其他节点的部分数据转移到新的节点上面,这个过程是不用停机重启的。同理如果需要下线一个节点,那么Redis也会重新分配,然后转移数据Redis的雪崩和穿透以及击穿是什么?怎么解决?
缓存击穿指的是一个key在失效的一瞬间,大量的并发请求涌了进来,所有的请求打到了数据库,导致数据库崩溃。
解决方法:可以使用分布式锁防止缓存击穿 public Response test(){ Response res = getFromCache(); if(res == null){ Lock lock = getDistributeLock(); try{ if(lock.lock()){ res = getFromCache(); if(res==null){ res = getFromDb(); setCache(res); }else{ return res; } } }finaly{ lock.unlock(); } }else{ return res; } }
缓存穿透指的是大量的请求查询一个缓存里面不存在的数据,导致请求全部打在DB上面,然后DB就挂了
解决办法:布隆过滤器+空值录入缓存
我们可以使用布隆过滤器拦截一部分不存在的数据,然后剩下的如果查出来是null那么也把这些null对应的可以缓存起来
缓存雪崩指的是缓存服务器挂了或者大量的缓存数据在同一时间失效了,导致请求直接打到了DB,这时候DB无法抗住就挂了
解决方案:
对于数据过期的问题,可以错开过期时间,如果不能错开的话可以采取和缓存击穿一样的解决方案,加锁解决
对于缓存服务器不可用的情况,可以使用限流。假设数据库的最大qps是2000,可以使用令牌桶或者漏桶等等进行限流,对于超过的请求直接返回友好的提示信息。Redis双写一致性如何保证
目前DB和Redis之间的数据同步一版是在查询的时候更新Redis数据,在修改的时候删除Redis的数据,那么这时候应该考虑是在更新之前删除呢还是在更新之后删除呢?
1、更新之后删除
如果在更新之后删除,那么如果缓存删除失败就会导致数据库和缓存不一致.... updateDB(); deleteCache(); ....
在更新之前删除解决了上面的不一致的情况,即使数据库操作失败那么在此查询也还是会更新。.... deleteCache(); updateDB(); ....
使用状态标记,在写操作的时候阻塞读操作,首先需要让负载策略把相同ID的写操作和查询操作路由到一台机器上面,然后使用读写锁来保证线程安全 ReadWriteLock readWriteLock = new ReentrantReadWriteLock(); public String getResult(String id){ Lock lock = readWriteLock.readLock(); lock.lock(); try { if (StringUtils.isEmpty(id)) { return null; } String res = CACHE.get(id); if (res != null) { return res; } else { // get from db res = getFromDB(id); CACHE.put(id, res); } return res; }finally { lock.unlock(); } } public void setValue(String id){ Lock lock = readWriteLock.writeLock(); lock.lock(); try { //clear cache CACHE.remove(id); //sleep random time 20ms~120ms Thread.sleep((long) (Math.random()*100+20)); DB.put(id,"value"+id+"new"); } catch (InterruptedException e) { e.printStackTrace(); }finally { lock.unlock(); } } Redis并发竞争问题是什么?怎么解决?Redis事物CAS是什么?
解决方案:
1、分布式锁,使用锁的方式来保证线程的安全性,不过无法保证修改操作的顺序性
2、分布式锁+时间戳,一版我们写入数据库的数据都会带上一个更新时间戳,我们可以根据这个时间戳来判断当前数据的顺序生产环境怎么部署Redis
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











