本文是鉴于有些粉丝的工作需求,有时候需要遇到这些文件的处理。因此,我写了一个文章集合,供大家参考,整篇文章已经整理成册(如下图所示),如有需求,请私聊! 章节一:python使用openpyxl操作excel 这里需要大家仔细查看图中的每一项内容,知道什么是“行(row)、列(column)”?什么是“格子(cell)”?什么是“sheet表”? 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 演示效果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 首先,我们有如下几个文件,可以发现这里共有三个PDF文件需要我们合并。同时可以发现他们的文件名都是有规律的(如果文件名,没有先后顺序,我们合并起来就没有意义了。) 结果如下: 这里有一个“时间序列.pdf”的文件,共3页,我们将其每一页存为一个PDF文件。 结果如下: 其中一页效果展示如下: 需求:我们有一个PDF文件,我们需要倒序排列,应该怎么做呢? 结果如下: 结果如下: 结果如下: 结果如下: 有一个这样的docx文件,我们想要提取其中的文字,应该怎么做? 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下: 结果如下:
目录
1、openpyxl库介绍
2、python怎么打开及读取表格内容?
1)Excel表格述语
2)打开Excel表格并获取表格名称
3)通过sheet名称获取表格
4)获取表格的尺寸大小
5)获取表格内某个格子的数据
① sheet[“A1”]方式
② sheet.cell(row=, column=)方式
6)获取某个格子的行数、列数、坐标
7)获取一系列格子
① sheet[]方式
② .iter_rows()方式
③ sheet.rows()
3、python如何向excel中写入某些内容?
1)修改表格中的内容
① 向某个格子中写入内容并保存
② .append():向表格中插入行数据
③ 在python中使用excel函数公式(很有用)
④ .insert_cols()和.insert_rows():插入空行和空列
⑤ .delete_rows()和.delete_cols():删除行和列
⑥ .move_range():移动格子
⑦ .create_sheet():创建新的sheet表格
⑧ .remove():删除某个sheet表
⑨ .copy_worksheet():复制一个sheet表到另外一张excel表
⑩ sheet.title:修改sheet表的名称
⑪ 创建新的excel表格文件
⑫ sheet.freeze_panes:冻结窗口
⑬ sheet.auto_filter.ref:给表格添加“筛选器”
4、批量调整字体和样式
1)修改字体样式
2)获取表格中格子的字体样式
3)设置对齐样式
4)设置边框样式
5)设置填充样式
6)设置行高和列宽
7)合并单元格
章节二:python使用PyPDF2和pdfplumber操作pdf
1、PyPDF2和pdfplumber库介绍
2、python提取PDF文字内容
1)利用pdfplumber提取文字
2)利用pdfplumber提取表格并写入excel
3、PDF合并及页面的排序和旋转
1)分割及合并pdf
① 合并pdf
② 拆分pdf
2)旋转及排序pdf
① 旋转pdf
② 排序pdf
4、pdf批量加水印及加密、解密
1)批量加水印
2)批量加密、解密
① 加密pdf
② 解密pdf并保存为未加密的pdf
章节三:python使用python-docx操作word
1、python-docx库介绍
2、Python读取Word文档内容
1)word文档结构介绍
2)python-docx提取文字和文字块儿
① python-docx提取文字
② python-docx提取文字块儿
3)利用Python向Word文档写入内容
① 添加段落
② 添加文字块儿
③ 添加一个分页
④ 添加图片
⑤ 添加表格
⑥ 提取word表格,并保存在excel中(很重要)
3、利用Python调整Word文档样式
1)修改文字字体样式
2)修改段落样式
① 对齐样式
② 行间距调整
③ 段前与段后间距章节一:python使用openpyxl操作excel
1、openpyxl库介绍
2、python怎么打开及读取表格内容?
1)Excel表格述语
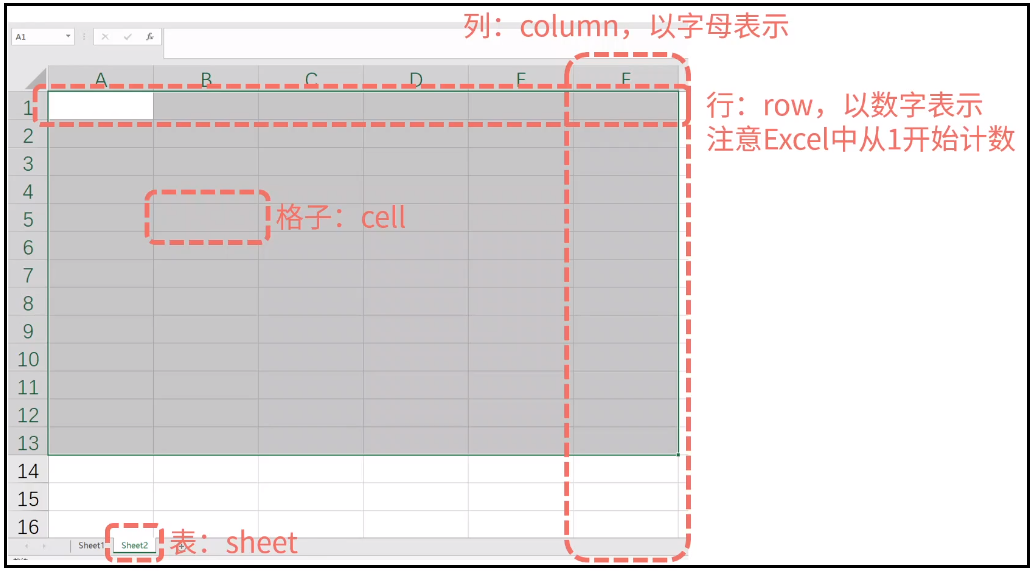
2)打开Excel表格并获取表格名称
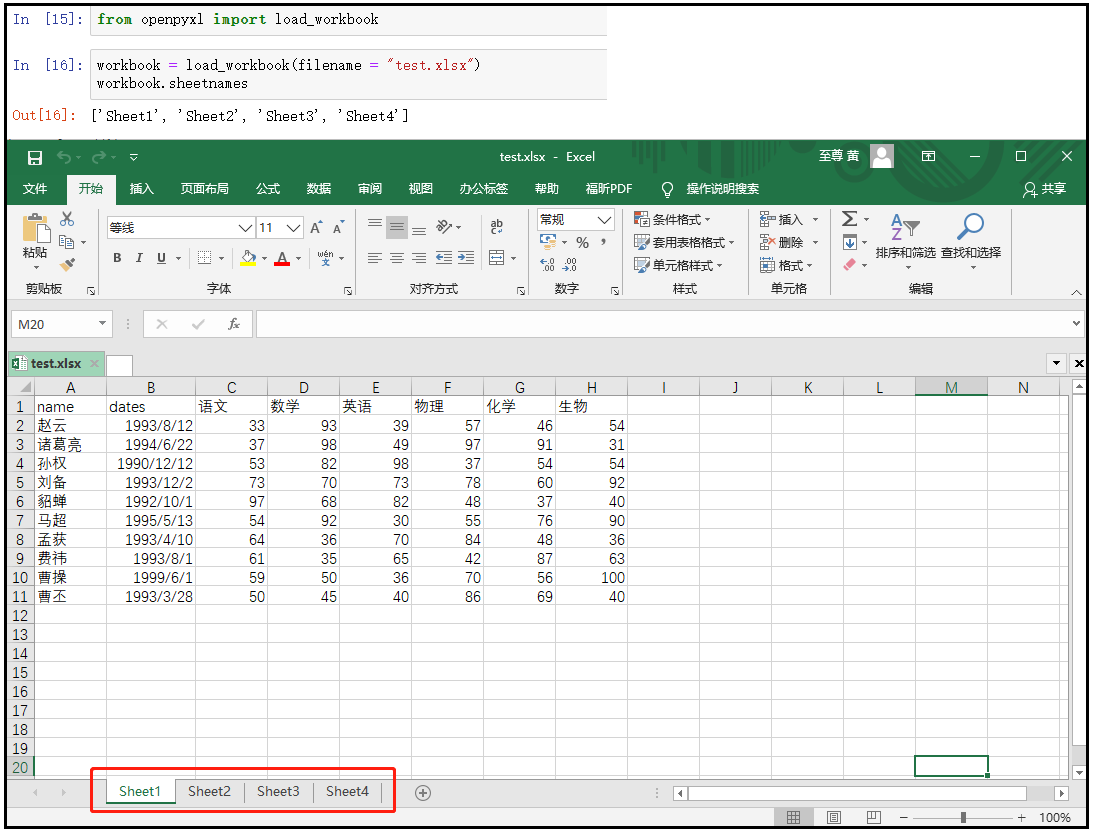
from openpyxl import load_workbook workbook = load_workbook(filename = "test.xlsx") workbook.sheetnames
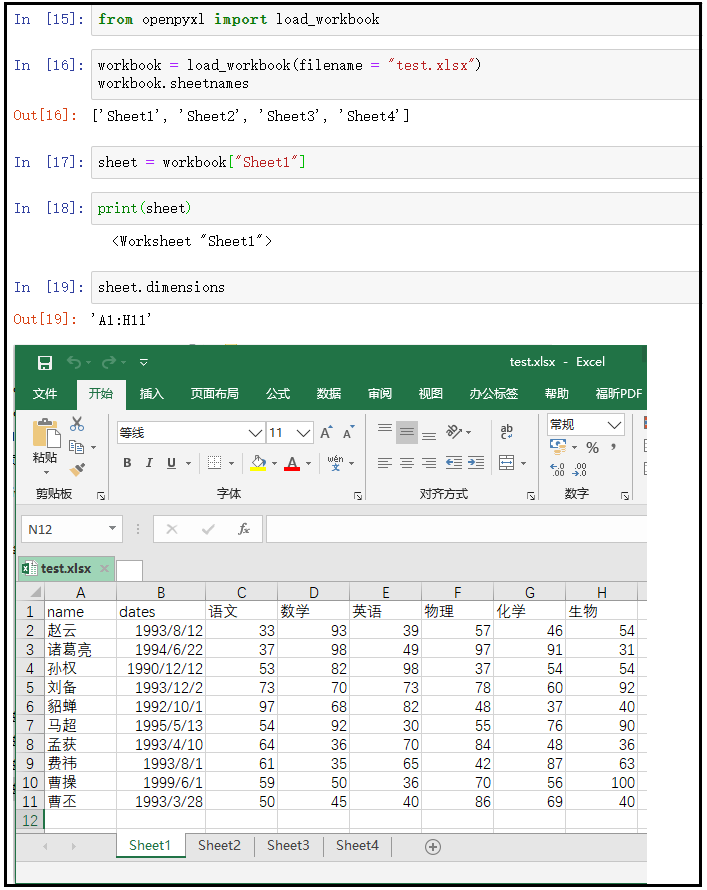
3)通过sheet名称获取表格
from openpyxl import load_workbook workbook = load_workbook(filename = "test.xlsx") workbook.sheetnames sheet = workbook["Sheet1"] print(sheet)

4)获取表格的尺寸大小
sheet.dimensions
5)获取表格内某个格子的数据
① sheet[“A1”]方式
workbook = load_workbook(filename = "test.xlsx") sheet = workbook.active print(sheet) cell1 = sheet["A1"] cell2 = sheet["C11"] print(cell1.value, cell2.value) """ workbook.active 打开激活的表格; sheet["A1"] 获取A1格子的数据; cell.value 获取格子中的值; """
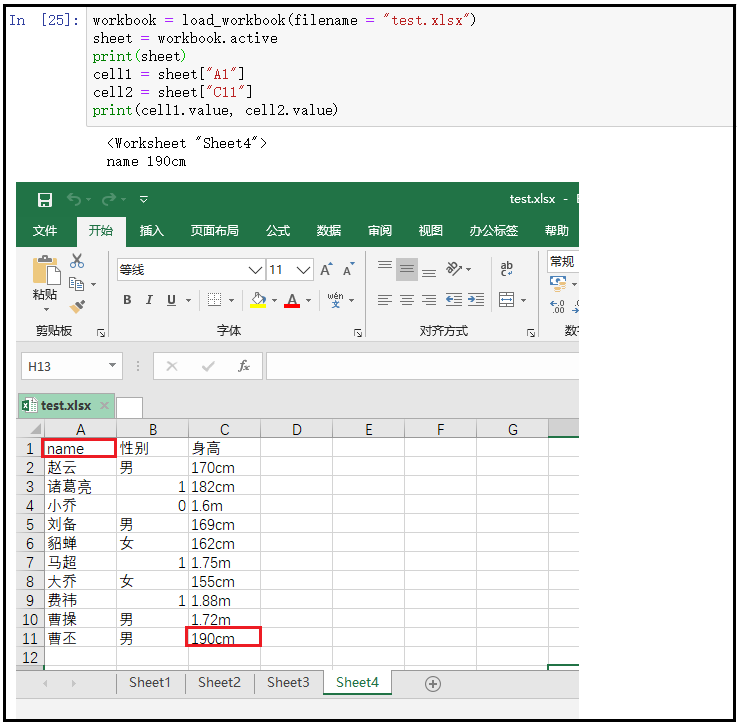
② sheet.cell(row=, column=)方式
workbook = load_workbook(filename = "test.xlsx") sheet = workbook.active print(sheet) cell1 = sheet.cell(row = 1,column = 1) cell2 = sheet.cell(row = 11,column = 3) print(cell1.value, cell2.value)
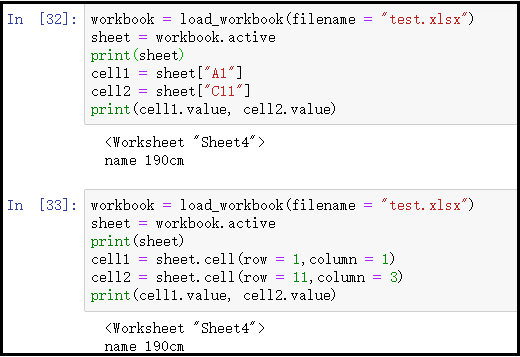
6)获取某个格子的行数、列数、坐标
workbook = load_workbook(filename = "test.xlsx") sheet = workbook.active print(sheet) cell1 = sheet["A1"] cell2 = sheet["C11"] print(cell1.value, cell1.row, cell1.column, cell1.coordinate) print(cell2.value, cell2.row, cell2.column, cell2.coordinate) """ .row 获取某个格子的行数; .columns 获取某个格子的列数; .corordinate 获取某个格子的坐标; """
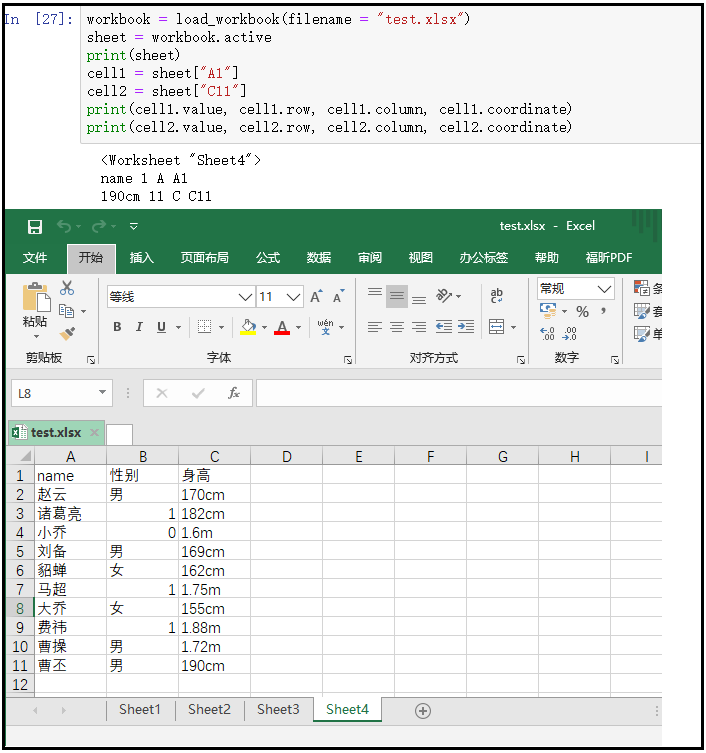
7)获取一系列格子
① sheet[]方式
workbook = load_workbook(filename = "test.xlsx") sheet = workbook.active print(sheet) # 获取A1:C2区域的值 cell = sheet["A1:C2"] print(cell) for i in cell: for j in i: print(j.value)
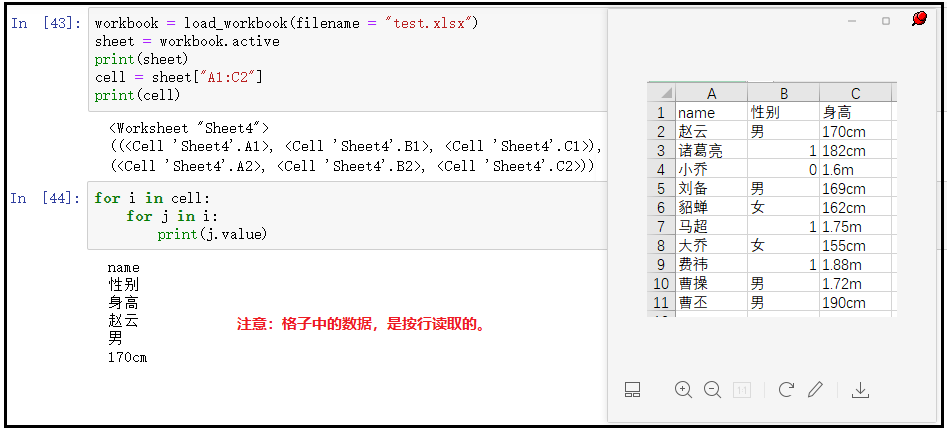
特别的:如果我们只想获取“A列”,或者获取“A-C列”,可以采取如下方式:sheet["A"] --- 获取A列的数据 sheet["A:C"] --- 获取A,B,C三列的数据 sheet[5] --- 只获取第5行的数据 ② .iter_rows()方式
workbook = load_workbook(filename = "test.xlsx") sheet = workbook.active print(sheet) # 按行获取值 for i in sheet.iter_rows(min_row=2, max_row=5, min_col=1, max_col=2): for j in i: print(j.value) # 按列获取值 for i in sheet.iter_cols(min_row=2, max_row=5, min_col=1, max_col=2): for j in i: print(j.value)
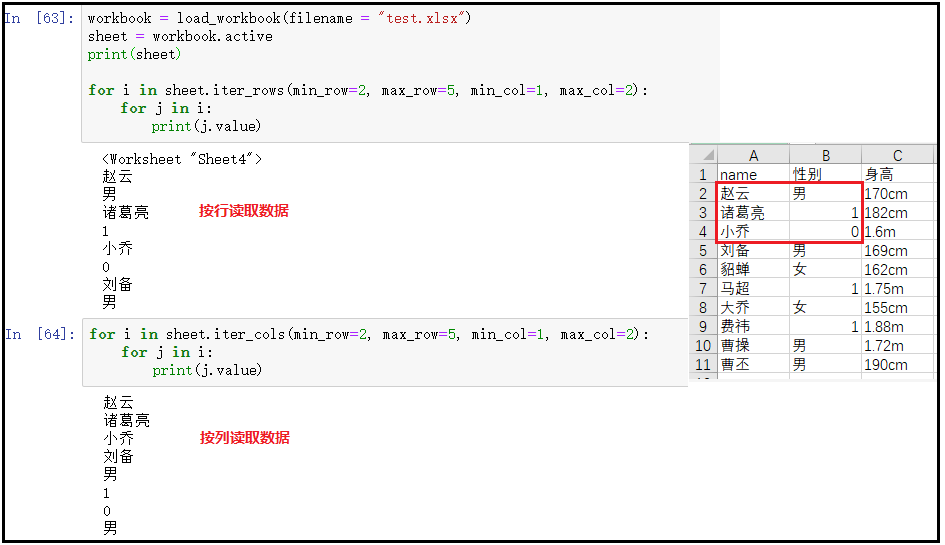
③ sheet.rows()
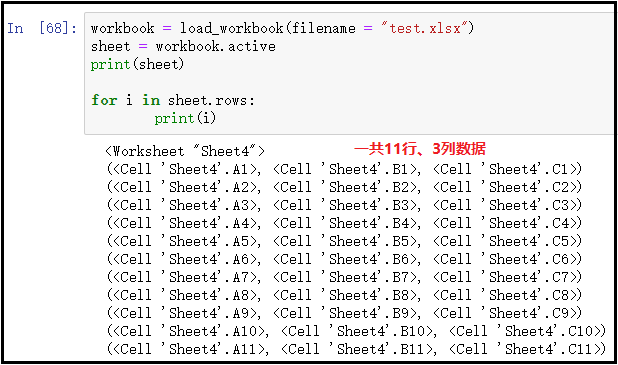
workbook = load_workbook(filename = "test.xlsx") sheet = workbook.active print(sheet) for i in sheet.rows: print(i)
3、python如何向excel中写入某些内容?
1)修改表格中的内容
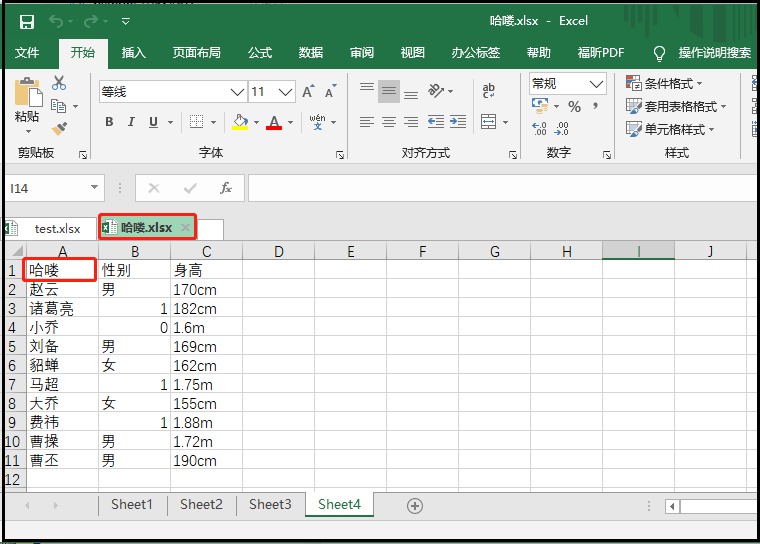
① 向某个格子中写入内容并保存
workbook = load_workbook(filename = "test.xlsx") sheet = workbook.active print(sheet) sheet["A1"] = "哈喽" # 这句代码也可以改为cell = sheet["A1"] cell.value = "哈喽" workbook.save(filename = "哈喽.xlsx") """ 注意:我们将“A1”单元格的数据改为了“哈喽”,并另存为了“哈喽.xlsx”文件。 如果我们保存的时候,不修改表名,相当于直接修改源文件; """
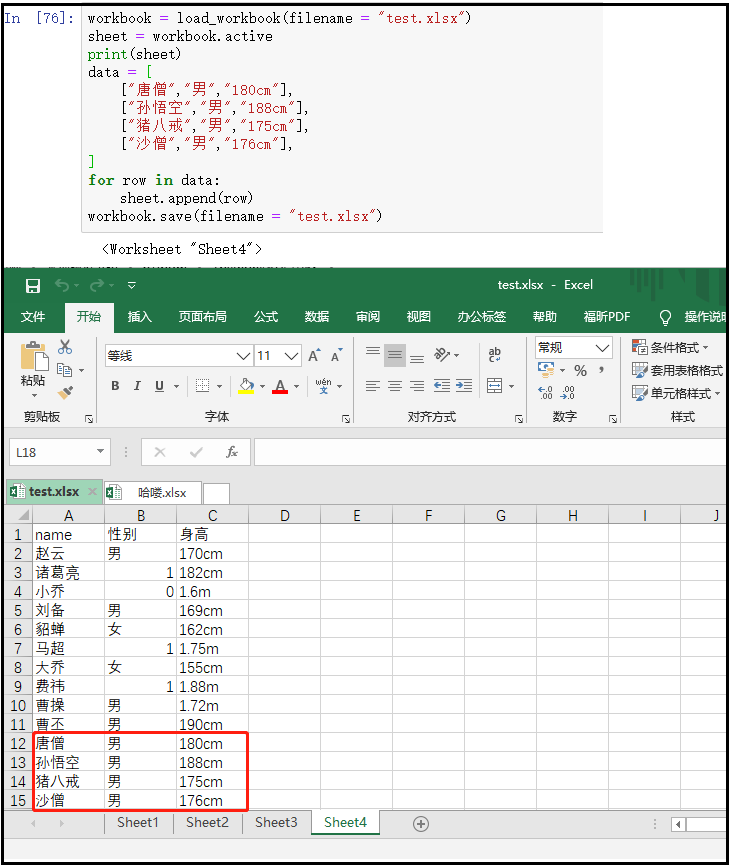
② .append():向表格中插入行数据
workbook = load_workbook(filename = "test.xlsx") sheet = workbook.active print(sheet) data = [ ["唐僧","男","180cm"], ["孙悟空","男","188cm"], ["猪八戒","男","175cm"], ["沙僧","男","176cm"], ] for row in data: sheet.append(row) workbook.save(filename = "test.xlsx")
③ 在python中使用excel函数公式(很有用)
# 这是我们在excel中输入的公式 =IF(RIGHT(C2,2)="cm",C2,SUBSTITUTE(C2,"m","")*100&"cm") # 那么,在python中怎么插入excel公式呢? workbook = load_workbook(filename = "test.xlsx") sheet = workbook.active print(sheet) sheet["D1"] = "标准身高" for i in range(2,16): sheet["D{}".format(i)] = '=IF(RIGHT(C{},2)="cm",C{},SUBSTITUTE(C{},"m","")*100&"cm")'.format(i,i,i) workbook.save(filename = "test.xlsx")
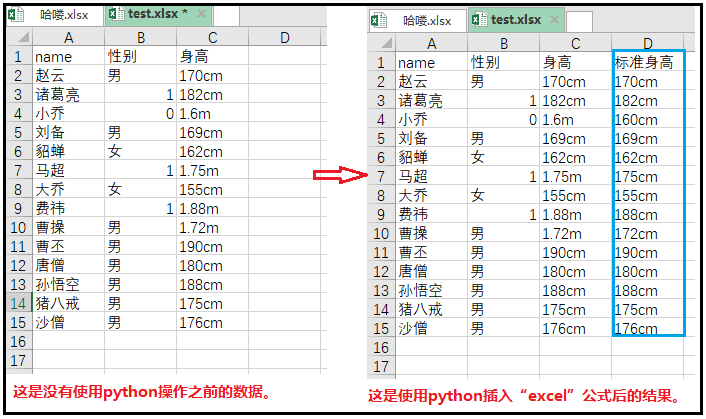
此时,你肯定会好奇,python究竟支持写哪些“excel函数公式”呢?我们可以使用如下操作查看一下。import openpyxl from openpyxl.utils import FORMULAE print(FORMULAE)

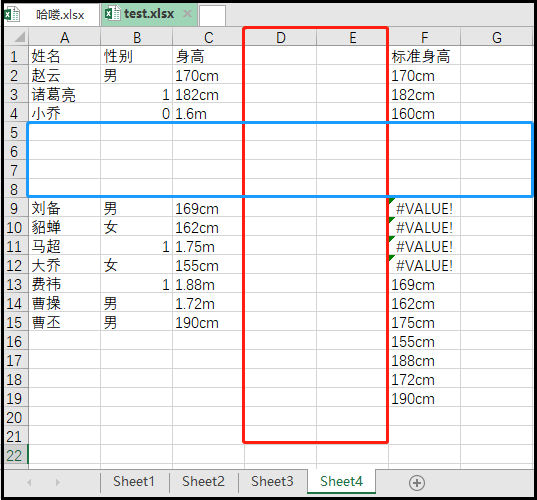
④ .insert_cols()和.insert_rows():插入空行和空列
workbook = load_workbook(filename = "test.xlsx") sheet = workbook.active print(sheet) sheet.insert_cols(idx=4,amount=2) sheet.insert_rows(idx=5,amount=4) workbook.save(filename = "test.xlsx")
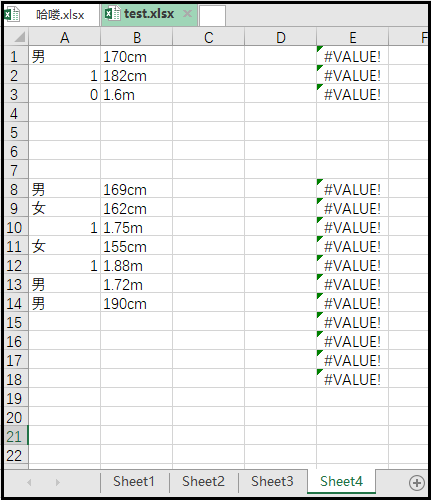
⑤ .delete_rows()和.delete_cols():删除行和列
workbook = load_workbook(filename = "test.xlsx") sheet = workbook.active print(sheet) # 删除第一列,第一行 sheet.delete_cols(idx=1) sheet.delete_rows(idx=1) workbook.save(filename = "test.xlsx")
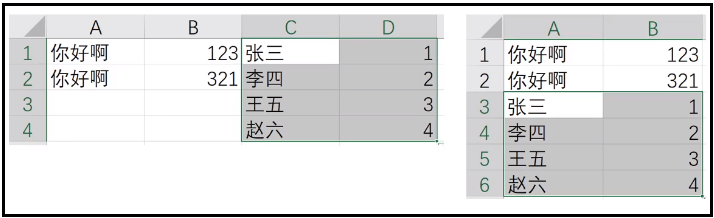
⑥ .move_range():移动格子
# 向左移动两列,向下移动两行 sheet.move_range("C1:D4",rows=2,cols=-1)
⑦ .create_sheet():创建新的sheet表格
workbook = load_workbook(filename = "test.xlsx") sheet = workbook.active print(sheet) workbook.create_sheet("我是一个新的sheet") print(workbook.sheetnames) workbook.save(filename = "test.xlsx")

⑧ .remove():删除某个sheet表
workbook = load_workbook(filename = "test.xlsx") sheet = workbook.active print(workbook.sheetnames) # 这个相当于激活的这个sheet表,激活状态下,才可以操作; sheet = workbook['我是一个新的sheet'] print(sheet) workbook.remove(sheet) print(workbook.sheetnames) workbook.save(filename = "test.xlsx")

⑨ .copy_worksheet():复制一个sheet表到另外一张excel表
workbook = load_workbook(filename = "a.xlsx") sheet = workbook.active print("a.xlsx中有这几个sheet表",workbook.sheetnames) sheet = workbook['姓名'] workbook.copy_worksheet(sheet) workbook.save(filename = "test.xlsx")
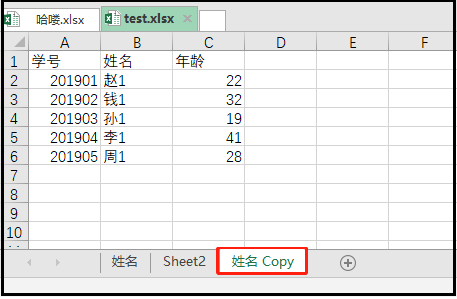
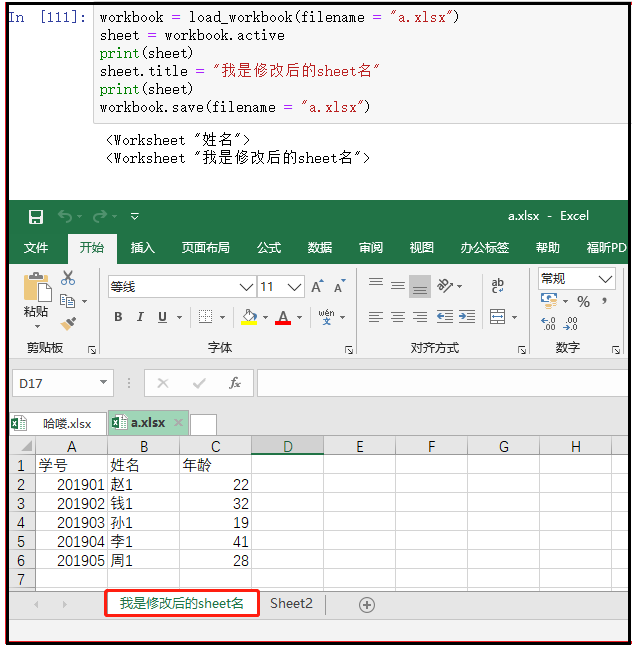
⑩ sheet.title:修改sheet表的名称
workbook = load_workbook(filename = "a.xlsx") sheet = workbook.active print(sheet) sheet.title = "我是修改后的sheet名" print(sheet)
⑪ 创建新的excel表格文件
from openpyxl import Workbook workbook = Workbook() sheet = workbook.active sheet.title = "表格1" workbook.save(filename = "新建的excel表格")
⑫ sheet.freeze_panes:冻结窗口
workbook = load_workbook(filename = "花园.xlsx") sheet = workbook.active print(sheet) sheet.freeze_panes = "C3" workbook.save(filename = "花园.xlsx") """ 冻结窗口以后,你可以打开源文件,进行检验; """

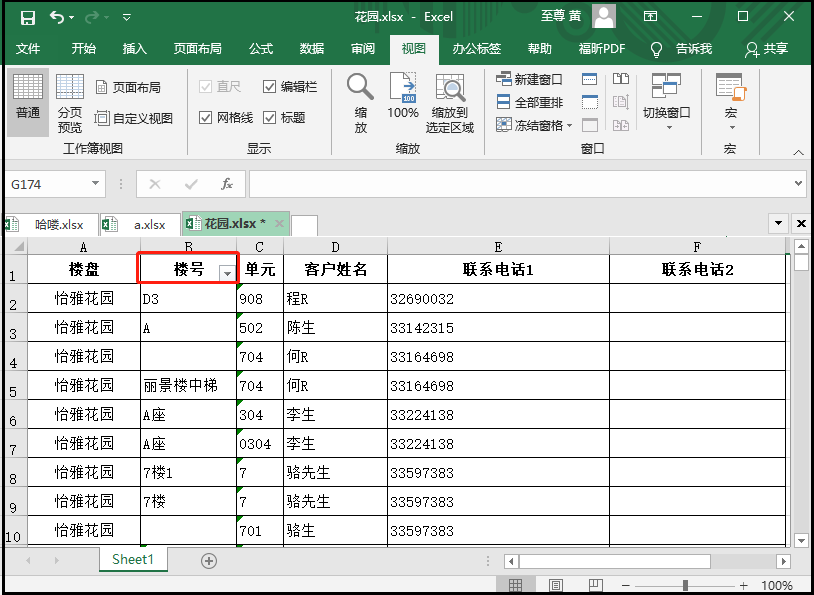
⑬ sheet.auto_filter.ref:给表格添加“筛选器”
workbook = load_workbook(filename = "花园.xlsx") sheet = workbook.active print(sheet) sheet.auto_filter.ref = sheet["A1"] workbook.save(filename = "花园.xlsx")
4、批量调整字体和样式
1)修改字体样式
from openpyxl.styles import Font from openpyxl import load_workbook workbook = load_workbook(filename="花园.xlsx") sheet = workbook.active cell = sheet["A1"] font = Font(name="微软雅黑",size=20,bold=True,italic=True,color="FF0000") cell.font = font workbook.save(filename = "花园.xlsx") """ 这个color是RGB的16进制表示,自己下去百度学习; """
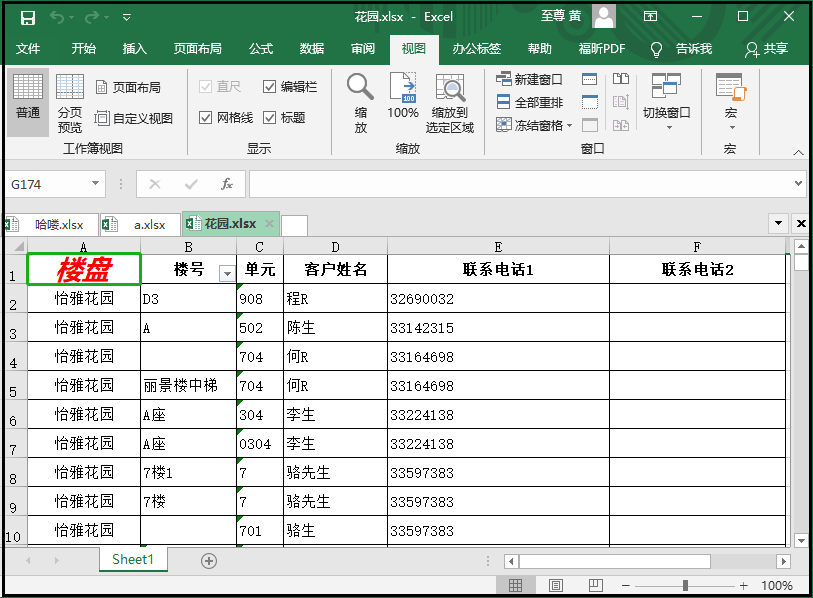
2)获取表格中格子的字体样式
from openpyxl.styles import Font from openpyxl import load_workbook workbook = load_workbook(filename="花园.xlsx") sheet = workbook.active cell = sheet["A2"] font = cell.font print(font.name, font.size, font.bold, font.italic, font.color)

3)设置对齐样式
from openpyxl.styles import Alignment from openpyxl import load_workbook workbook = load_workbook(filename="花园.xlsx") sheet = workbook.active cell = sheet["A1"] alignment = Alignment(horizontal="center",vertical="center",text_rotation=45,wrap_text=True) cell.alignment = alignment workbook.save(filename = "花园.xlsx")
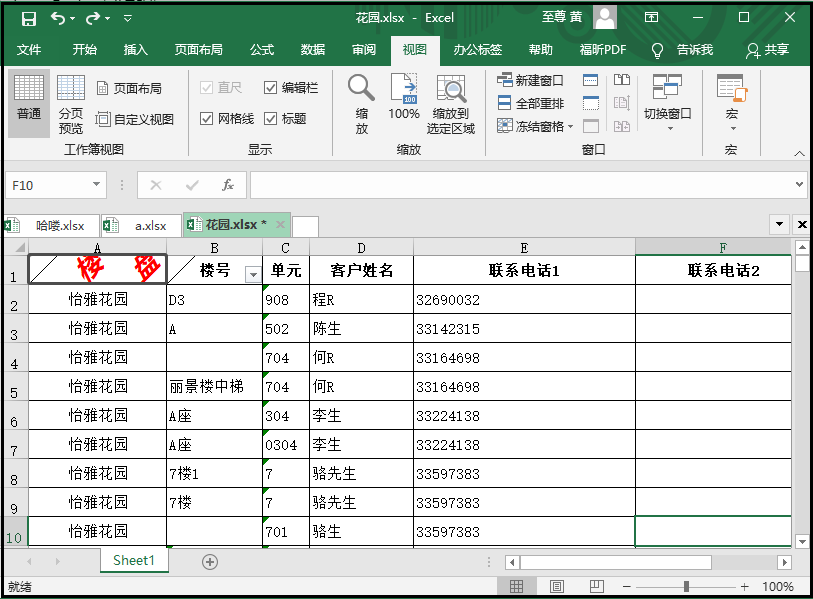
4)设置边框样式
openpyxl import load_workbook workbook = load_workbook(filename="花园.xlsx") sheet = workbook.active cell = sheet["D6"] side1 = Side(style="thin",color="FF0000") side2 = Side(style="thick",color="FFFF0000") border = Border(left=side1,right=side1,top=side2,bottom=side2) cell.border = border workbook.save(filename = "花园.xlsx")
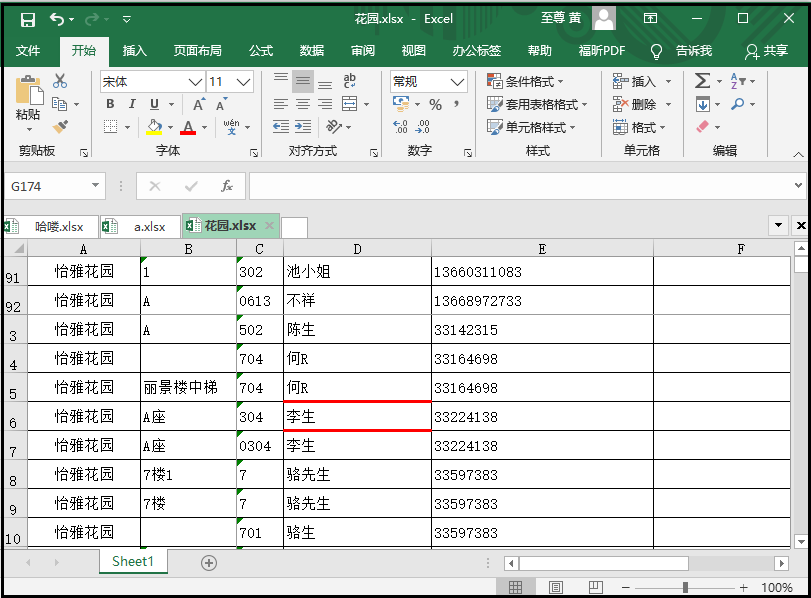
5)设置填充样式
from openpyxl.styles import PatternFill,GradientFill from openpyxl import load_workbook workbook = load_workbook(filename="花园.xlsx") sheet = workbook.active cell_b9 = sheet["B9"] pattern_fill = PatternFill(fill_type="solid",fgColor="99ccff") cell_b9.fill = pattern_fill cell_b10 = sheet["B10"] gradient_fill = GradientFill(stop=("FFFFFF","99ccff","000000")) cell_b10.fill = gradient_fill workbook.save(filename = "花园.xlsx")
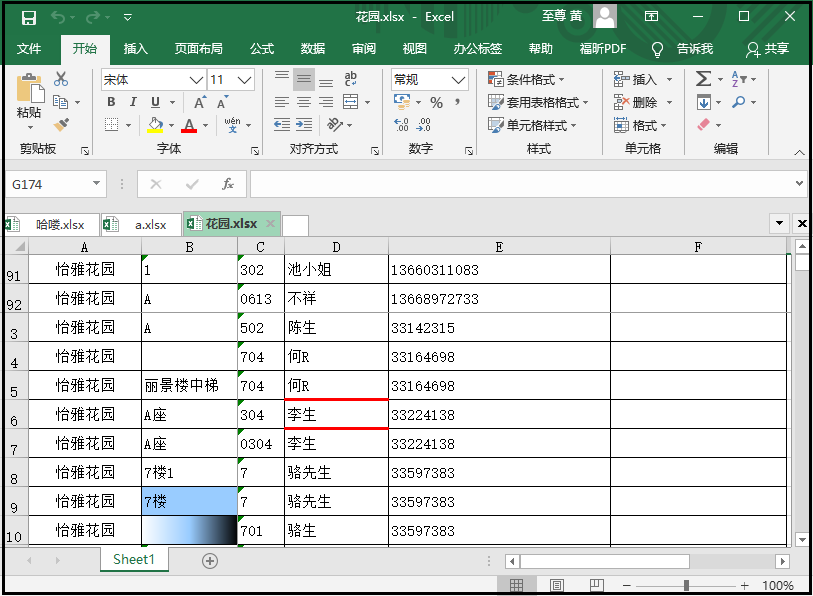
6)设置行高和列宽
workbook = load_workbook(filename="花园.xlsx") sheet = workbook.active # 设置第1行的高度 sheet.row_dimensions[1].height = 50 # 设置B列的宽度 sheet.column_dimensions["B"].width = 20 workbook.save(filename = "花园.xlsx") """ sheet.row_dimensions.height = 50 sheet.column_dimensions.width = 30 这两句代码,是将整个表的行高设置为50,列宽设置为30; """
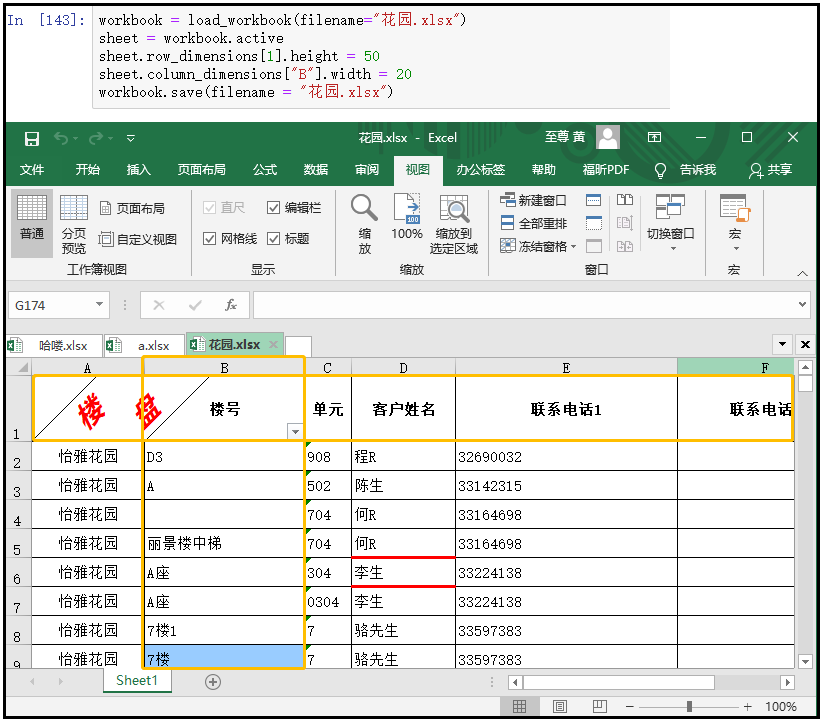
7)合并单元格
workbook = load_workbook(filename="花园.xlsx") sheet = workbook.active sheet.merge_cells("C1:D2") sheet.merge_cells(start_row=7,start_column=1,end_row=8,end_column=3) workbook.save(filename = "花园.xlsx")
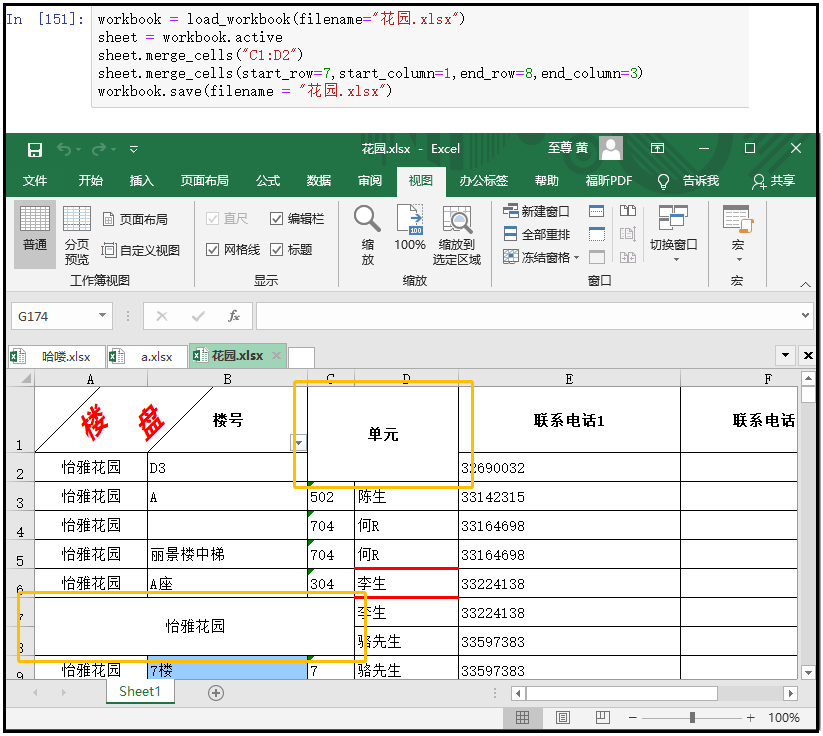
当然,也有“取消合并单元格”,用法一致。
章节二:python使用PyPDF2和pdfplumber操作pdf
1、PyPDF2和pdfplumber库介绍
2、python提取PDF文字内容
1)利用pdfplumber提取文字
import PyPDF2 import pdfplumber with pdfplumber.open("餐饮企业综合分析.pdf") as p: page = p.pages[2] print(page.extract_text())
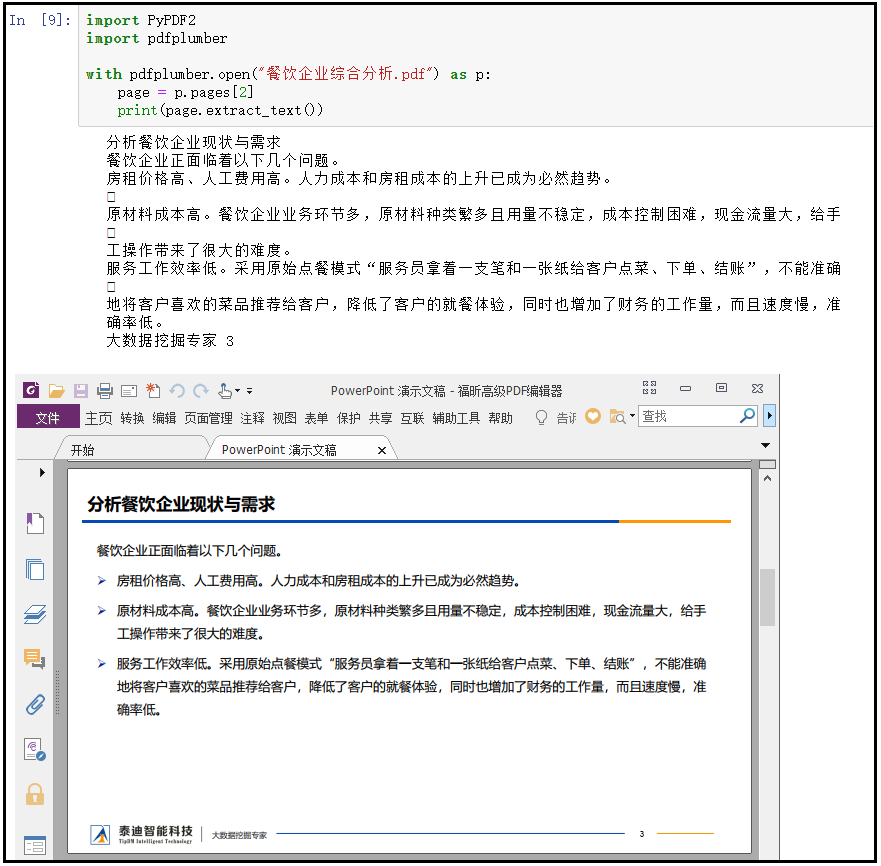
2)利用pdfplumber提取表格并写入excel
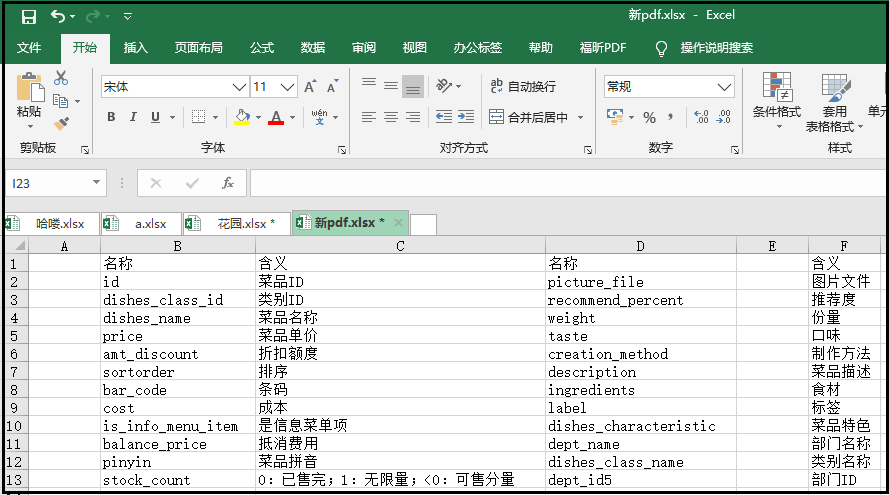
import PyPDF2 import pdfplumber from openpyxl import Workbook with pdfplumber.open("餐饮企业综合分析.pdf") as p: page = p.pages[4] table = page.extract_table() print(table) workbook = Workbook() sheet = workbook.active for row in table: if not "".join() == "" sheet.append(row) workbook.save(filename = "新pdf.xlsx")
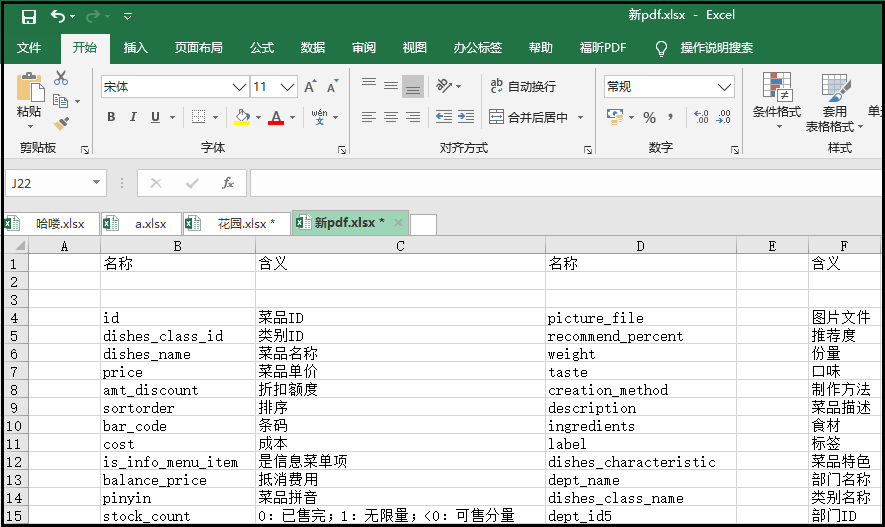
缺陷:可以看到,这里提取出来的表格有很多空行,怎么去掉这些空行呢?
判断:将列表中每个元素都连接成一个字符串,如果还是一个空字符串那么肯定就是空行。import PyPDF2 import pdfplumber from openpyxl import Workbook with pdfplumber.open("餐饮企业综合分析.pdf") as p: page = p.pages[4] table = page.extract_table() print(table) workbook = Workbook() sheet = workbook.active for row in table: if not "".join([str(i) for i in row]) == "": sheet.append(row) workbook.save(filename = "新pdf.xlsx")
3、PDF合并及页面的排序和旋转
1)分割及合并pdf
① 合并pdf

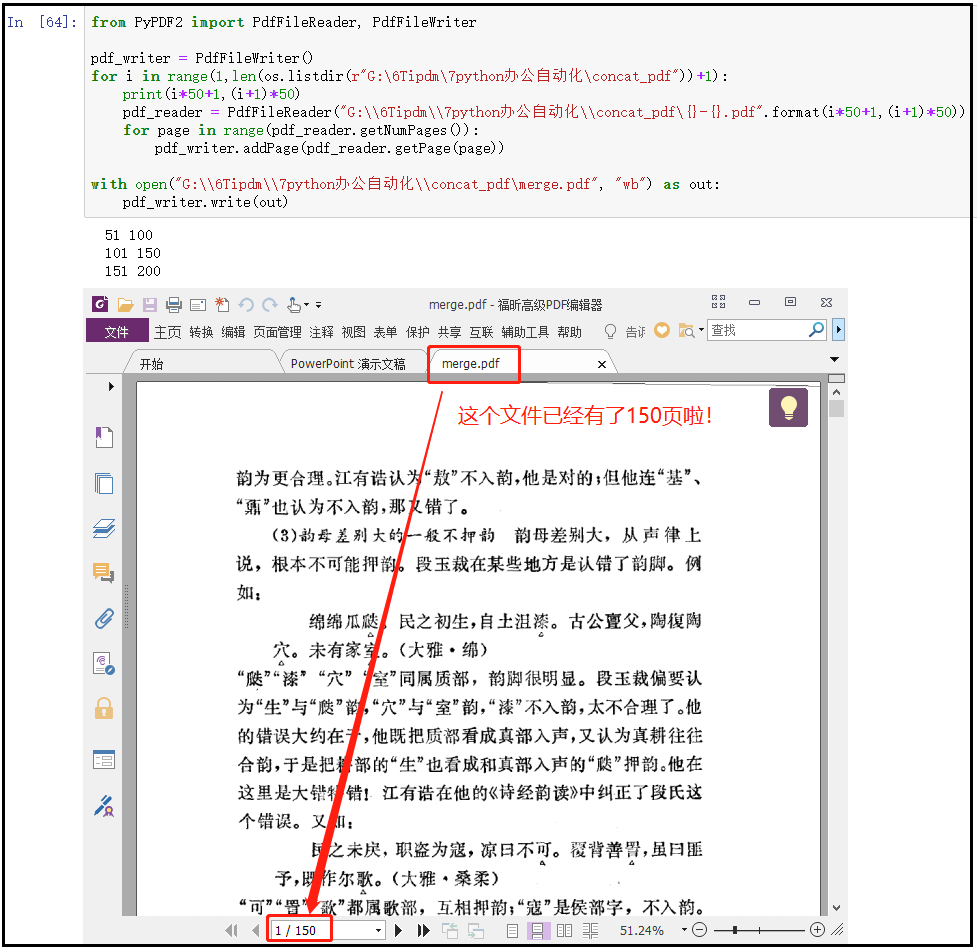
代码如下:from PyPDF2 import PdfFileReader, PdfFileWriter pdf_writer = PdfFileWriter() for i in range(1,len(os.listdir(r"G:6Tipdm7python办公自动化concat_pdf"))+1): print(i*50+1,(i+1)*50) pdf_reader = PdfFileReader("G:\6Tipdm\7python办公自动化\concat_pdf{}-{}.pdf".format(i*50+1,(i+1)*50)) for page in range(pdf_reader.getNumPages()): pdf_writer.addPage(pdf_reader.getPage(page)) with open("G:\6Tipdm\7python办公自动化\concat_pdfmerge.pdf", "wb") as out: pdf_writer.write(out)
② 拆分pdf
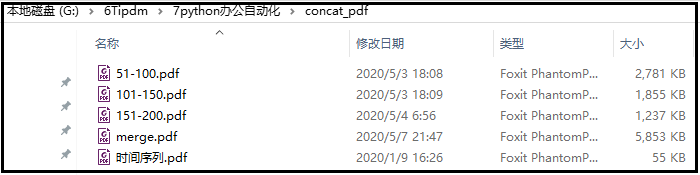
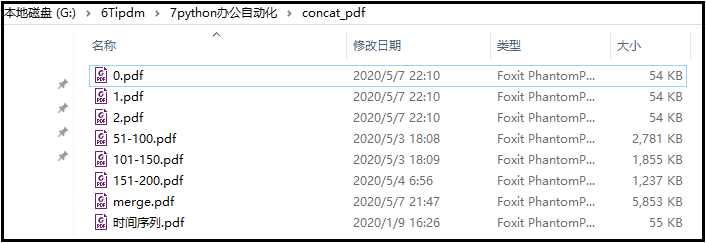
代码如下:from PyPDF2 import PdfFileReader, PdfFileWriter pdf_reader = PdfFileReader(r"G:6Tipdm7python办公自动化concat_pdf时间序列.pdf") for page in range(pdf_reader.getNumPages()): pdf_writer = PdfFileWriter() pdf_writer.addPage(pdf_reader.getPage(page)) with open(f"G:\6Tipdm\7python办公自动化\concat_pdf\{page}.pdf", "wb") as out: pdf_writer.write(out)
2)旋转及排序pdf
① 旋转pdf
from PyPDF2 import PdfFileReader, PdfFileWriter pdf_reader = PdfFileReader(r"G:6Tipdm7python办公自动化concat_pdf时间序列.pdf") pdf_writer = PdfFileWriter() for page in range(pdf_reader.getNumPages()): if page % 2 == 0: rotation_page = pdf_reader.getPage(page).rotateCounterClockwise(90) else: rotation_page = pdf_reader.getPage(page).rotateClockwise(90) pdf_writer.addPage(rotation_page) with open("G:\6Tipdm\7python办公自动化\concat_pdf\旋转.pdf", "wb") as out: pdf_writer.write(out) """ 上述代码中,我们循环遍历了这个pdf,对于偶数页我们逆时针旋转90°,对于奇数页我们顺时针旋转90°; 注意:旋转的角度只能是90的倍数; """
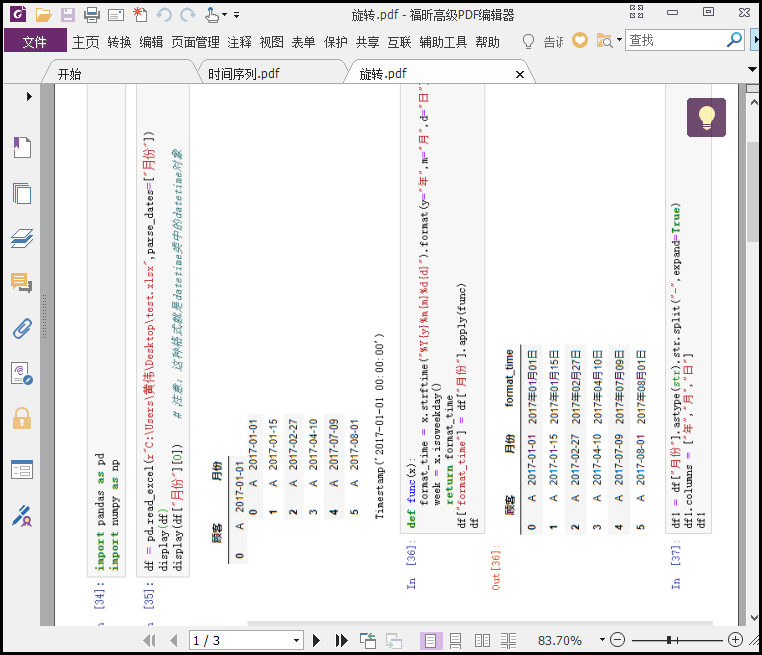
② 排序pdf
首先,我们来看python中,怎么倒叙打印一串数字,如下图所示。

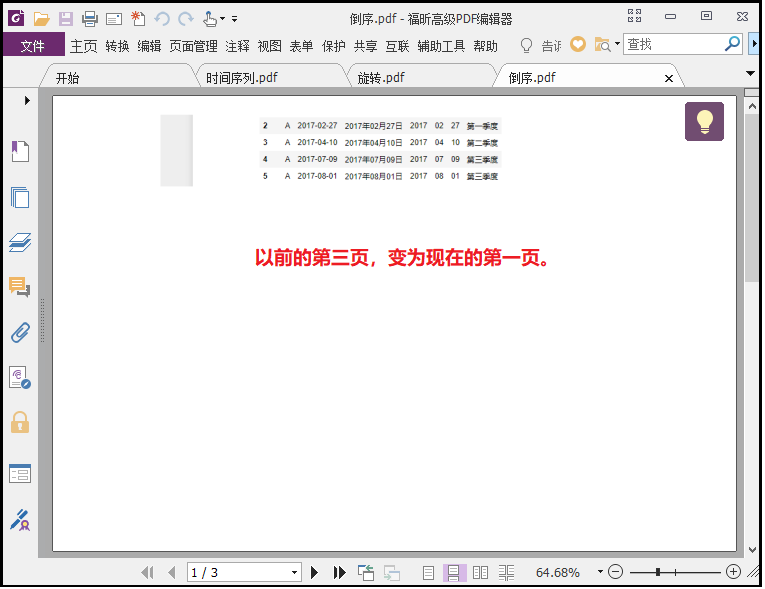
那么倒序排列一个pdf,思路同上,代码如下:from PyPDF2 import PdfFileReader, PdfFileWriter pdf_reader = PdfFileReader(r"G:6Tipdm7python办公自动化concat_pdf时间序列.pdf") pdf_writer = PdfFileWriter() for page in range(pdf_reader.getNumPages()-1, -1, -1): pdf_writer.addPage(pdf_reader.getPage(page)) with open("G:\6Tipdm\7python办公自动化\concat_pdf\倒序.pdf", "wb") as out: pdf_writer.write(out)
4、pdf批量加水印及加密、解密
1)批量加水印
from PyPDF2 import PdfFileReader, PdfFileWriter from copy import copy water = PdfFileReader(r"G:6Tipdm7python办公自动化concat_pdf水印.pdf") water_page = water.getPage(0) pdf_reader = PdfFileReader(r"G:6Tipdm7python办公自动化concat_pdfaa.pdf") pdf_writer = PdfFileWriter() for page in range(pdf_reader.getNumPages()): my_page = pdf_reader.getPage(page) new_page = copy(water_page) new_page.mergePage(my_page) pdf_writer.addPage(new_page) with open("G:\6Tipdm\7python办公自动化\concat_pdf\添加水印后的aa.pdf", "wb") as out: pdf_writer.write(out) """ 这里有一点需要注意:进行pdf合并的时候,我们希望“水印”在下面,文字在上面,因此是“水印”.mergePage(“图片页”) """
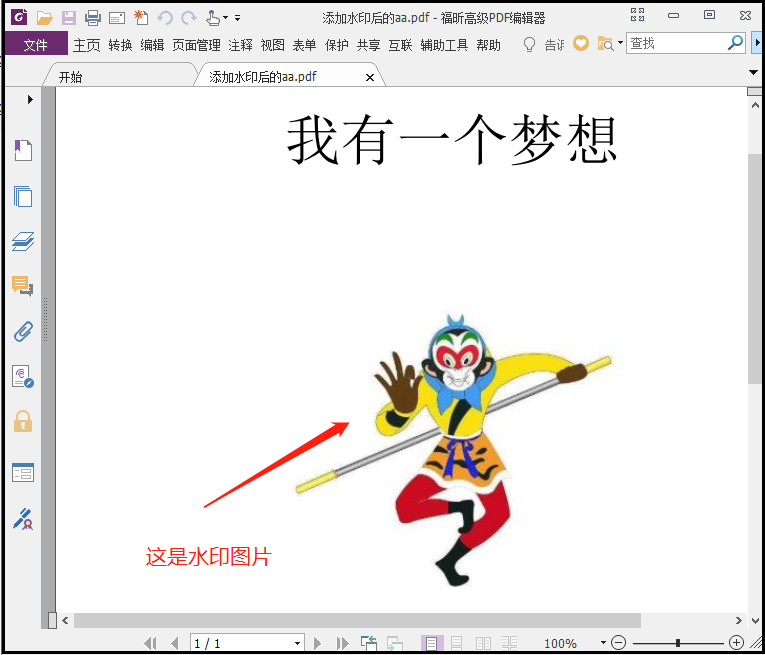
2)批量加密、解密
① 加密pdf
from PyPDF2 import PdfFileReader, PdfFileWriter pdf_reader = PdfFileReader(r"G:6Tipdm7python办公自动化concat_pdf时间序列.pdf") pdf_writer = PdfFileWriter() for page in range(pdf_reader.getNumPages()): pdf_writer.addPage(pdf_reader.getPage(page)) # 添加密码 pdf_writer.encrypt("a123456") with open("G:\6Tipdm\7python办公自动化\concat_pdf\时间序列.pdf", "wb") as out: pdf_writer.write(out)
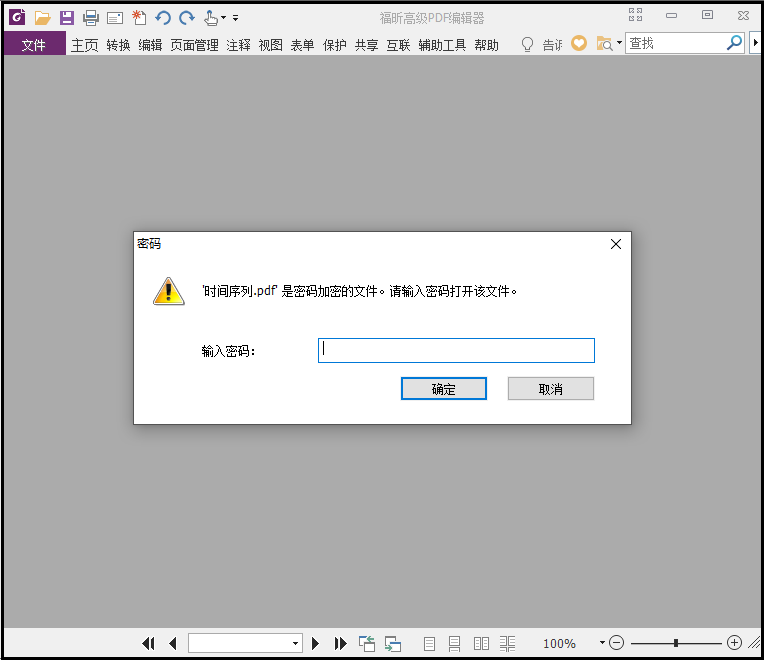
② 解密pdf并保存为未加密的pdf
from PyPDF2 import PdfFileReader, PdfFileWriter pdf_reader = PdfFileReader(r"G:6Tipdm7python办公自动化concat_pdf时间序列.pdf") # 解密pdf pdf_reader.decrypt("a123456") pdf_writer = PdfFileWriter() for page in range(pdf_reader.getNumPages()): pdf_writer.addPage(pdf_reader.getPage(page)) with open("G:\6Tipdm\7python办公自动化\concat_pdf\未加密的时间序列.pdf", "wb") as out: pdf_writer.write(out)
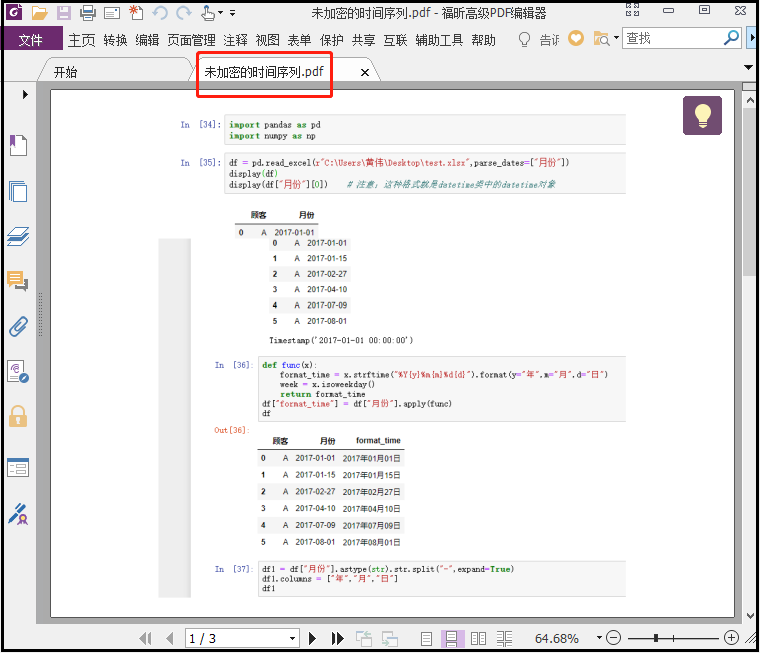
章节三:python使用python-docx操作word
1、python-docx库介绍
2、Python读取Word文档内容
1)word文档结构介绍
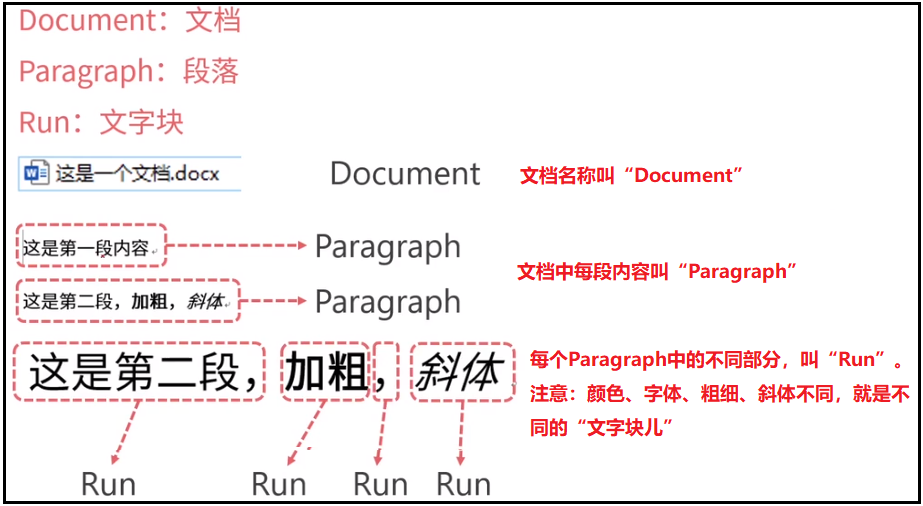
2)python-docx提取文字和文字块儿
① python-docx提取文字
代码如下:from docx import Document doc = Document(r"G:6Tipdm7python办公自动化concat_wordtest1.docx") print(doc.paragraphs) for paragraph in doc.paragraphs: print(paragraph.text)

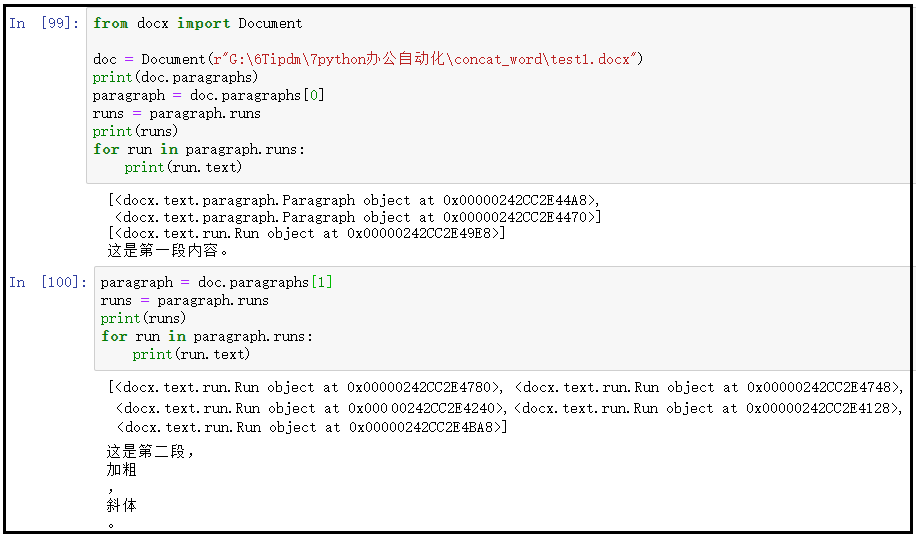
② python-docx提取文字块儿
from docx import Document doc = Document(r"G:6Tipdm7python办公自动化concat_wordtest1.docx") print(doc.paragraphs) paragraph = doc.paragraphs[0] runs = paragraph.runs print(runs) for run in paragraph.runs: print(run.text) ------------------------------ paragraph = doc.paragraphs[1] runs = paragraph.runs print(runs) for run in paragraph.runs: print(run.text)
3)利用Python向Word文档写入内容
① 添加段落
from docx import Document doc = Document(r"G:6Tipdm7python办公自动化concat_wordtest1.docx") # print(doc.add_heading("一级标题", level=1)) 添加一级标题的时候出错,还没有解决! paragraph1 = doc.add_paragraph("这是一个段落") paragraph2 = doc.add_paragraph("这是第二个段落") doc.save(r"G:6Tipdm7python办公自动化concat_wordtest1.docx") """ 添加段落的时候,赋值给一个变量,方便我们后面进行格式调整; """
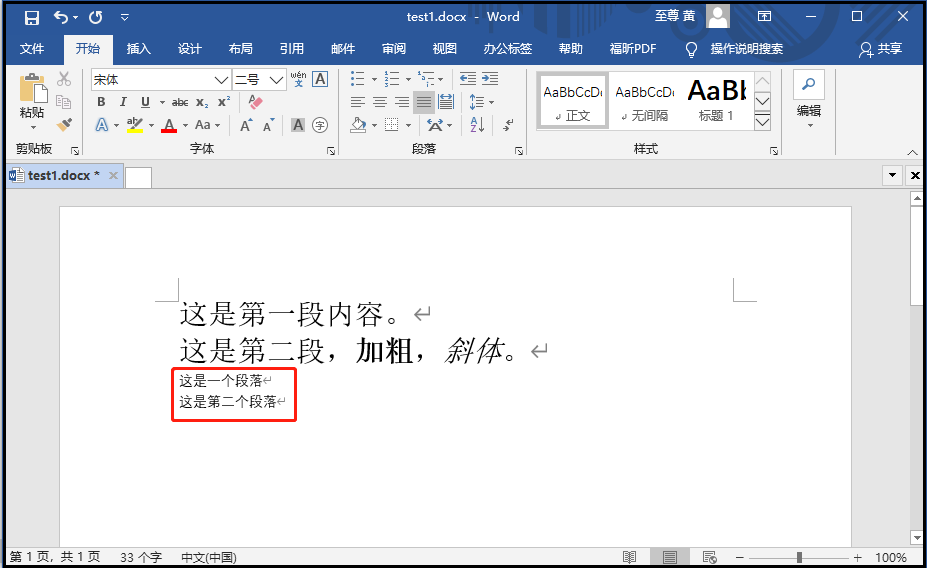
② 添加文字块儿
from docx import Document doc = Document(r"G:6Tipdm7python办公自动化concat_wordtest1.docx") # 这里相当于输入了一个空格,后面等待着文字输入 paragraph3 = doc.add_paragraph() paragraph3.add_run("我被加粗了文字块儿").bold = True paragraph3.add_run(",我是普通文字块儿,") paragraph3.add_run("我是斜体文字块儿").italic = True doc.save(r"G:6Tipdm7python办公自动化concat_wordtest1.docx")
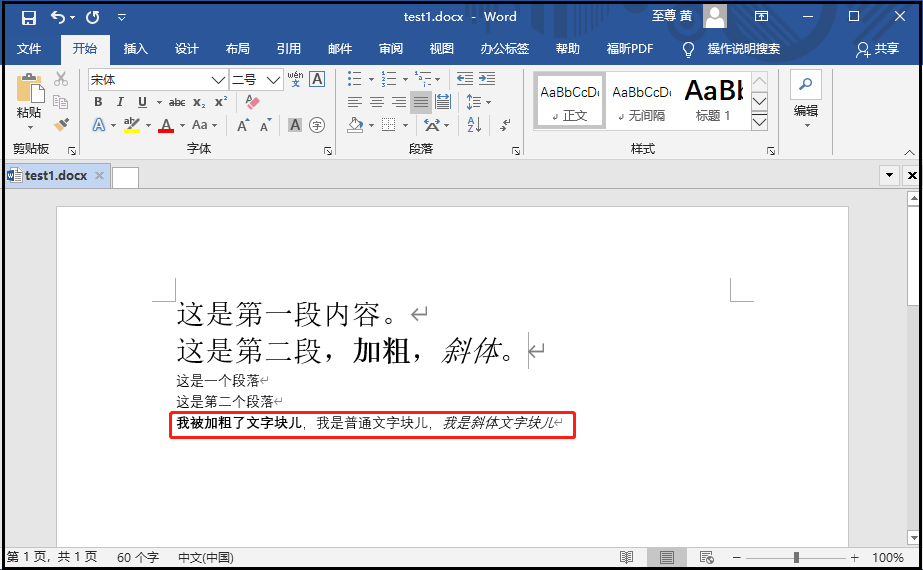
③ 添加一个分页
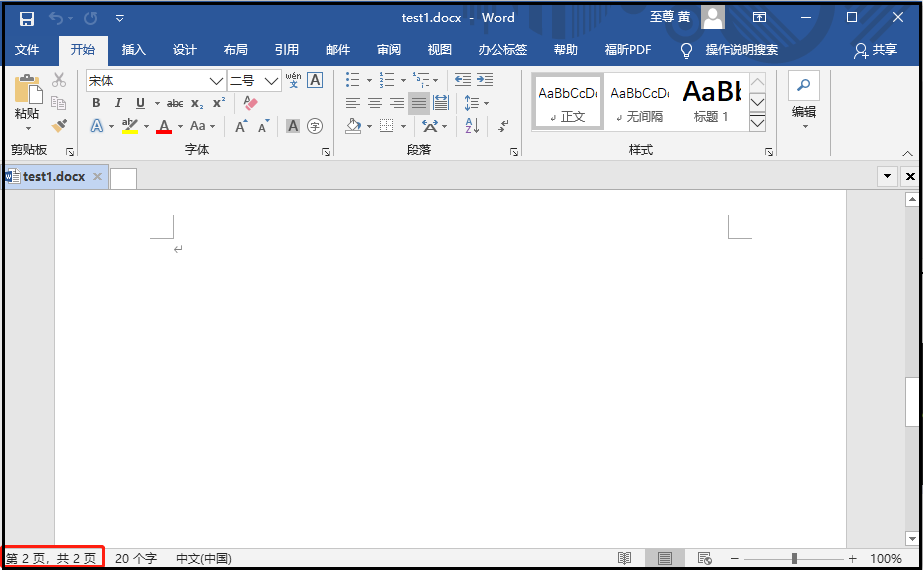
from docx import Document doc = Document(r"G:6Tipdm7python办公自动化concat_wordtest1.docx") doc.add_page_break() doc.save(r"G:6Tipdm7python办公自动化concat_wordtest1.docx")
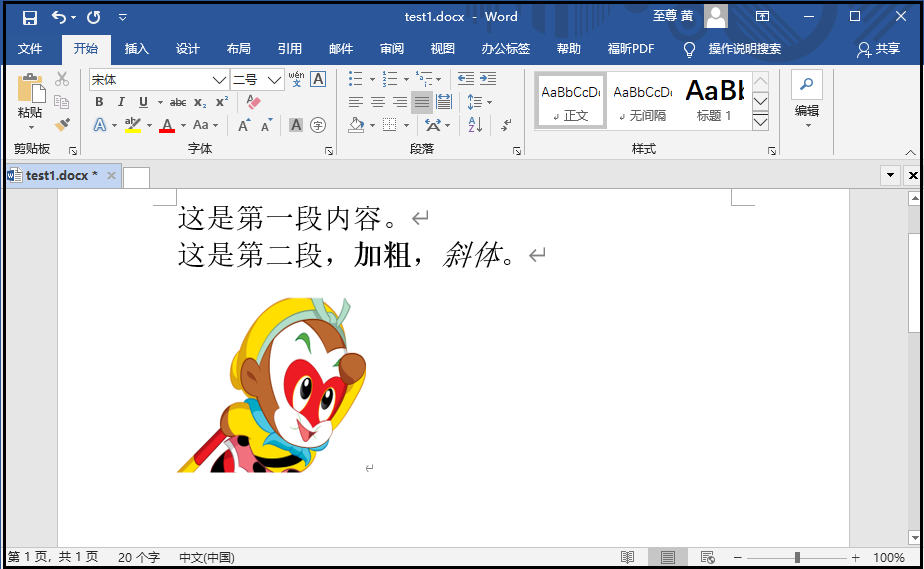
④ 添加图片
from docx import Document from docx.shared import Cm doc = Document(r"G:6Tipdm7python办公自动化concat_wordtest1.docx") doc.add_picture(r"G:6Tipdm7python办公自动化concat_wordsun_wu_kong.png",width=Cm(5),height=Cm(5)) doc.save(r"G:6Tipdm7python办公自动化concat_wordtest1.docx") """ Cm模块,用于设定图片尺寸大小 """
⑤ 添加表格
from docx import Document doc = Document(r"G:6Tipdm7python办公自动化concat_wordtest1.docx") list1 = [ ["姓名","性别","家庭地址"], ["唐僧","男","湖北省"], ["孙悟空","男","北京市"], ["猪八戒","男","广东省"], ["沙和尚","男","湖南省"] ] list2 = [ ["姓名","性别","家庭地址"], ["貂蝉","女","河北省"], ["杨贵妃","女","贵州省"], ["西施","女","山东省"] ] table1 = doc.add_table(rows=5,cols=3) for row in range(5): cells = table1.rows[row].cells for col in range(3): cells[col].text = str(list1[row][col]) doc.add_paragraph("-----------------------------------------------------------") table2 = doc.add_table(rows=4,cols=3) for row in range(4): cells = table2.rows[row].cells for col in range(3): cells[col].text = str(list2[row][col]) doc.save(r"G:6Tipdm7python办公自动化concat_wordtest1.docx")
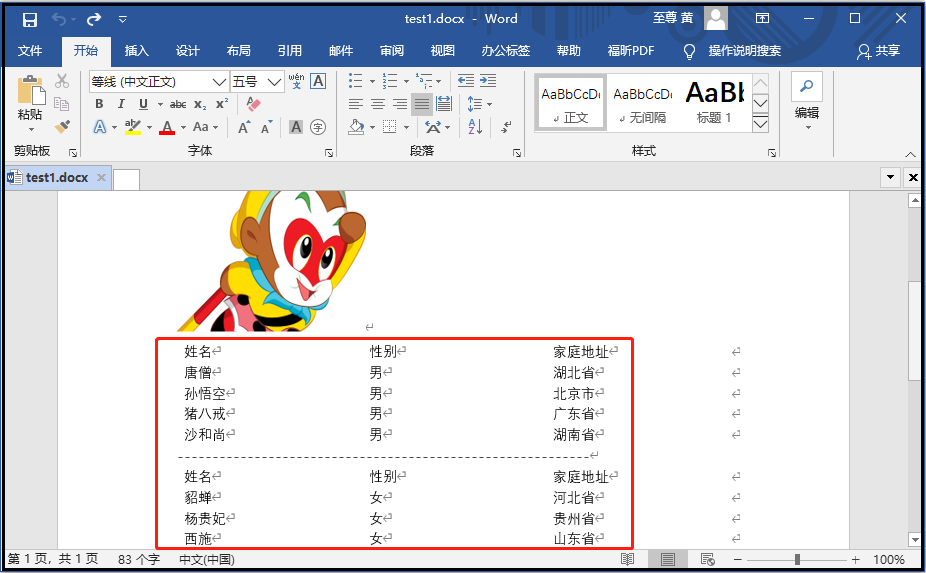
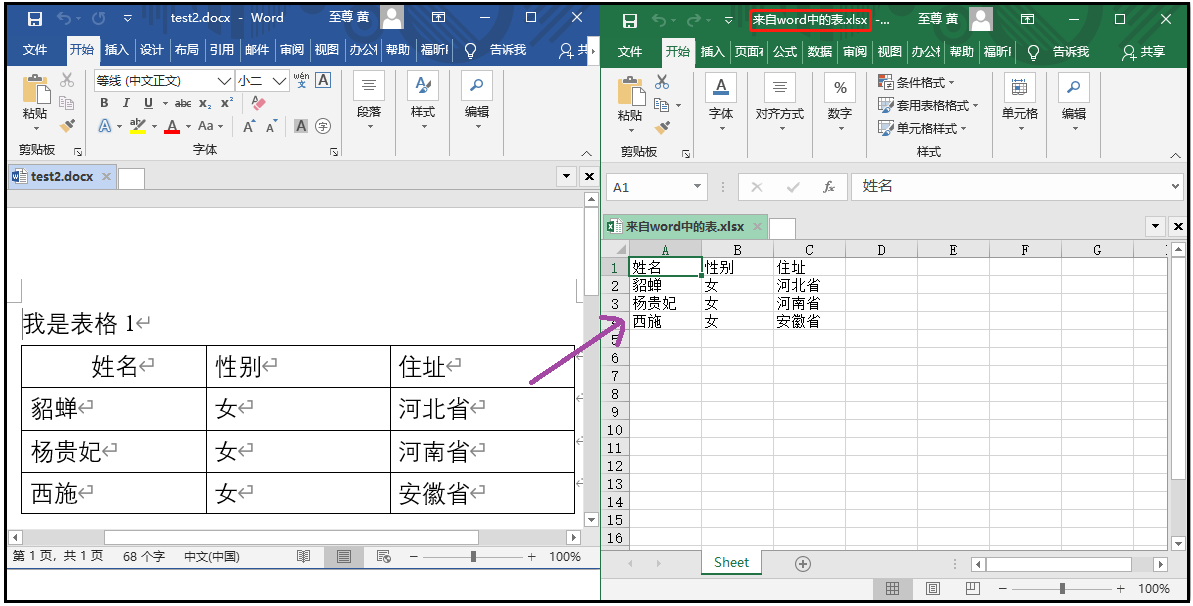
⑥ 提取word表格,并保存在excel中(很重要)
from docx import Document from openpyxl import Workbook doc = Document(r"G:6Tipdm7python办公自动化concat_wordtest2.docx") t0 = doc.tables[0] workbook = Workbook() sheet = workbook.active for i in range(len(t0.rows)): list1 = [] for j in range(len(t0.columns)): list1.append(t0.cell(i,j).text) sheet.append(list1) workbook.save(filename = r"G:6Tipdm7python办公自动化concat_word来自word中的表.xlsx")
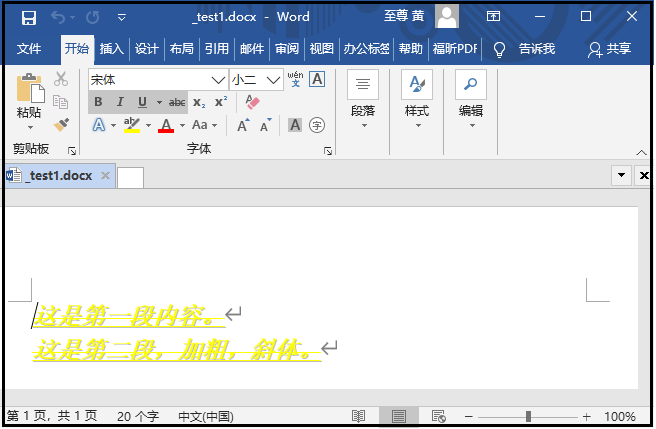
3、利用Python调整Word文档样式
1)修改文字字体样式
from docx import Document from docx.shared import Pt,RGBColor from docx.oxml.ns import qn doc = Document(r"G:6Tipdm7python办公自动化concat_wordtest2.docx") for paragraph in doc.paragraphs: for run in paragraph.runs: run.font.bold = True run.font.italic = True run.font.underline = True run.font.strike = True run.font.shadow = True run.font.size = Pt(18) run.font.color.rgb = RGBColor(255,255,0) run.font.name = "宋体" # 设置像宋体这样的中文字体,必须添加下面2行代码 r = run._element.rPr.rFonts r.set(qn("w:eastAsia"),"宋体") doc.save(r"G:6Tipdm7python办公自动化concat_word_test1.docx")
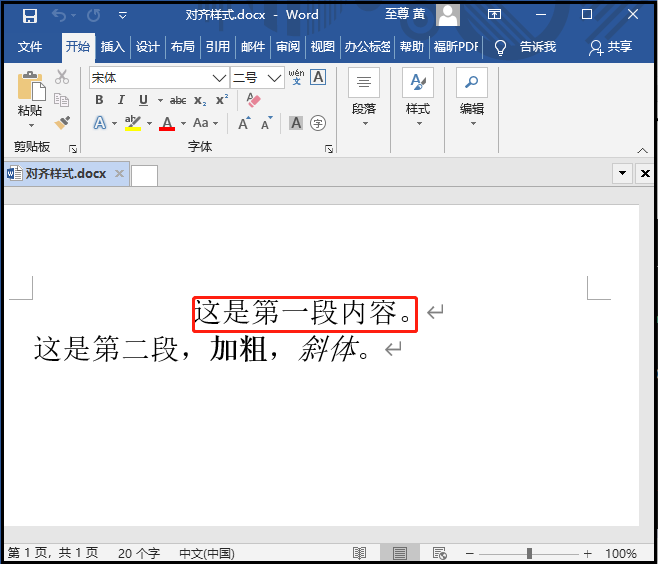
2)修改段落样式
① 对齐样式
from docx import Document from docx.enum.text import WD_ALIGN_PARAGRAPH doc = Document(r"G:6Tipdm7python办公自动化concat_wordtest1.docx") print(doc.paragraphs[0].text) doc.paragraphs[0].alignment = WD_ALIGN_PARAGRAPH.CENTER # 这里设置的是居中对齐 doc.save(r"G:6Tipdm7python办公自动化concat_word对齐样式.docx") """ LEFT,CENTER,RIGHT,JUSTIFY,DISTRIBUTE,JUSTIFY_MED,JUSTIFY_HI,JUSTIFY_LOW,THAI_JUSTIFY """
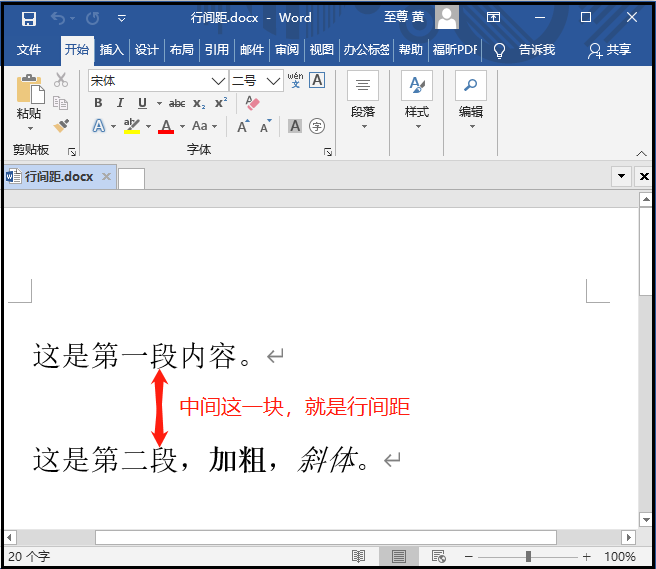
② 行间距调整
from docx import Document from docx.enum.text import WD_ALIGN_PARAGRAPH doc = Document(r"G:6Tipdm7python办公自动化concat_wordtest1.docx") for paragraph in doc.paragraphs: paragraph.paragraph_format.line_spacing = 5.0 doc.save(r"G:6Tipdm7python办公自动化concat_word行间距.docx")
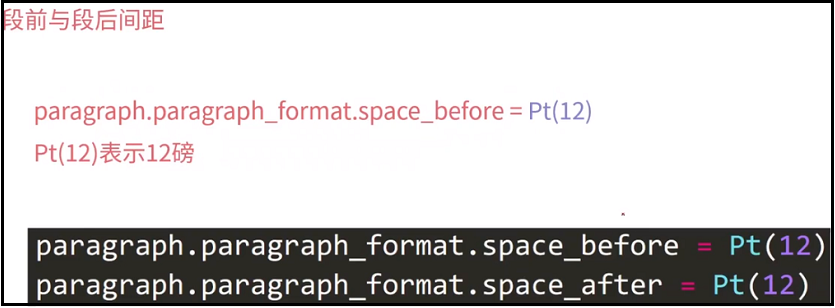
③ 段前与段后间距
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)


 博客专家
博客专家 









 174
174