写在前面: 博主是一名软件工程系大数据应用开发专业大二的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白, 说到Apache顶级开源项目,大家首先会想到什么??? 也许你会有些遗憾,这些顶级项目都是由外国友人所贡献的。但认真看了本篇博客标题的朋友都应该清楚,接下来,我要为大家介绍的是正如题目所述,第一个由国人开发的Apache顶级项目——Kylin Kylin是中国团队研发的,是第一个真正由中国人自己主导、从零开始、自主研发、并成为Apache顶级开源项目 Hive的性能比较慢,支持SQL灵活查询,特别慢 HBase的性能快,原生不支持SQL(phoenix:可以写sql语句来查询hbase!! Kylin是将先将数据进行预处理,将预处理的结果放在HBase中,效率很高! Kylin 典型的应用场景如下: Kylin 的核心思想是利用空间换时间,在数据 ETL 导入 OLAP 引擎时提前计算各维度的聚合结果并持久化保存 联机事务处理OLTP、联机分析处理OLAP。 Kylin 是一个 Hadoop 生态圈下的 MOLAP 系统,是 ebay 大数据部门从2014 年开始研发的支持 TB 到 PB 级别数据量的分布式 Olap 分析引擎。其特点包括: 可扩展的超快的 OLAP 引擎 提供 ANSI-SQL 接口 交互式查询能力 MOLAP Cube 的概念 与 BI 工具可无缝整合 Kylin 依赖于 Hadoop、Hive、Zookeeper 和 Hbase 从上面的架构中我们就可以看出,Kylin对于环境的依赖比较高 因为我们之前用的hbase版本是hbase-1.2.0-cdh5.14的版本,所以在安装kylin之前,我们需要下安装 这里我已经下载好了,需要的朋友可以后台私信我 添加JAVA_HOME环境变量 注意: 刷新环境变量 执行上述操作,执行list命令,如果能显示以下内容,表示安装成功。 ok,安装完了Hbase1.1.1,接着我们开始安装kylin kylin.sh文件添加如下内容: 将安装kylin的节点的名称换上,例如node01,总共是3处需要修改。 1、启动zookeeper 6、启动 hiverserver2 7、启动Yarn history server 8、启动spark history server【可选】 9、启动kylin 看到下面的效果图,说明我们的kylin已经启动成功了 10、登录Kylin 到这里,我们可以通过路径 默认的用户名是 然后就可以看到类似下面的界面效果图~~ Kylin的简介以及安装部署的过程的内容到这里就结束了。大家需要在对kylin有所了解的基础上,搭建好kylin所需要的环境。 如果以上过程中出现了任何的纰漏错误,烦请大佬们指正😅 受益的朋友或对大数据技术感兴趣的伙伴记得关注支持一波🙏
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:https://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
不熟悉Apache软件基金会的朋友也不用担心,大家可以去Apache官网,下拉到最下边的页面,查看Apache有哪些开源项目。
相信各位朋友在项目清单中肯定会看到不少熟悉的身影,JavaEE,HTTP,FTP,Hadoop,SQL,Maven,Tomcat,Kafka,Hive…这些几乎我们天天都在打交道的朋友,竟然都是Apache顶级项目的一员。
文章目录
Kylin简介
Kylin的诞生背景
)Kylin的应用场景
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLAP联机分析处理的用户是企业中的专业分析人员及管理决策人员,他们在分析业务经营的数据时,从不同的角度来审视业务的衡量指标是一种很自然的思考模式。例如分析销售数据,可能会综合时间周期、产品类别、分销渠道、地理分布、客户群类等多种因素来考量。使用Kylin的公司

既然都看到这么多大公司选择了Kylin,让我们接下来看看为什么要使用Kylin?为什么要使用Kylin
Kylin的总体架构
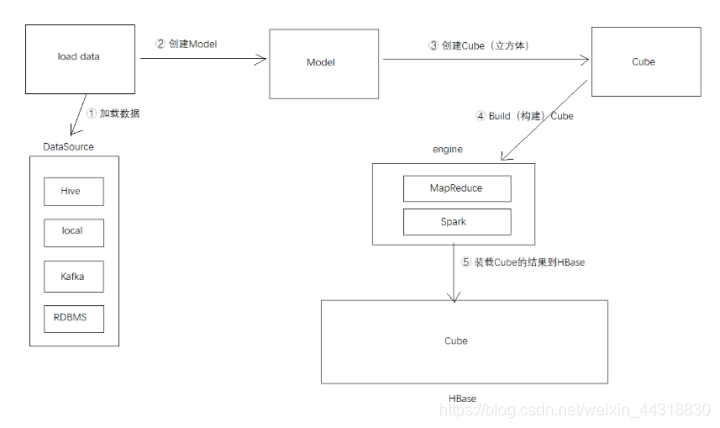
Kylin安装
依赖环境
软件
版本
Apache hbase-1.1.1-bin.tar.gz
1.1.1
spark-2.2.0-bin-2.6.0-cdh5.14.0.tgz
2.2.0-bin-cdh5.14.0
apache-kylin-2.6.3-bin-hbase1x.tar.gz
2.6.3
集群规划

注意:
安装HBase1.1.1
hbase 1.1.1版本<1>下载hbase 1.1.1版本

<2>上传到一台服务器,解压缩
tar -xvzf hbase-1.1.1-bin.tar.gz -C ../servers/ <3>修改hbase-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141/ export HBASE_MANAGES_ZK=false <4>修改hbase-site.xml,添加以下配置
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://node1:8020/hbase_1.1.1</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 --> <property> <name>hbase.master.port</name> <value>16000</value> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> <property> <name>hbase.master.info.port</name> <value>60010</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node1,node2,node3</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/export/servers/zookeeper-3.4.9/zkdatas</value> </property> <property> <name>hbase.thrift.support.proxyuser</name> <value>true</value> </property> <property> <name>hbase.regionserver.thrift.http</name> <value>true</value> </property> </configuration> <5>修改regionservers,添加其他的节点
node1 <6>在hbase conf目录中创建core-site.xml和hdfs-site.xml软连接
ln -s /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/core-site.xml $PWD/core-site.xml ln -s /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/hdfs-site.xml $PWD/hdfs-site.xml <7>配置HBase环境变量
# Apache HBase 1.1.1 export HBASE_HOME=/export/servers/hbase-1.1.1 export PATH=$HADOOP/sbin:$HADOOP/bin:$HBASE_HOME/bin:$PATH source /etc/profile <8>使用 zkCli 删除之前的 hbase 节点
# 进入到 zkCli中 /export/servers/zookeeper-3.4.9/bin/zkCli.sh # 执行删除 rmr /hbase
启动
bin/start-hbase.sh
hbase(main):002:0> list TABLE 0 row(s) in 0.1380 seconds => [] 安装kylin-2.6.3-bin-hbase1x
<1>解压
tar -zxf /export/softwares/apache-kylin-2.6.3-bin-hbase1x.tar.gz -C /export/servers/ <2>增加kylin依赖组件的配置
/export/servers/apache-kylin-2.6.3-bin-hbase1x/conf ln -s $HADOOP_HOME/etc/hadoop/hdfs-site.xml hdfs-site.xml ln -s $HADOOP_HOME/etc/hadoop/core-site.xml core-site.xml ln -s $HBASE_HOME/conf/hbase-site.xml hbase-site.xml ln -s $HIVE_HOME/conf/hive-site.xml hive-site.xml ln -s $SPARK_HOME/conf/spark-defaults.conf spark-defaults.conf <3>配置kylin.sh
/export/servers/apache-kylin-2.6.3-bin-hbase1x/bin vim kylin.sh export HADOOP_HOME=/export/servers/hadoop-2.6.0-cdh5.14.0 export HIVE_HOME=/export/servers/hive-1.1.0-cdh5.14.0 export HBASE_HOME=/export/servers/hbase-1.1.1 export SPARK_HOME=/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0 <4>配置conf/kylin.properties
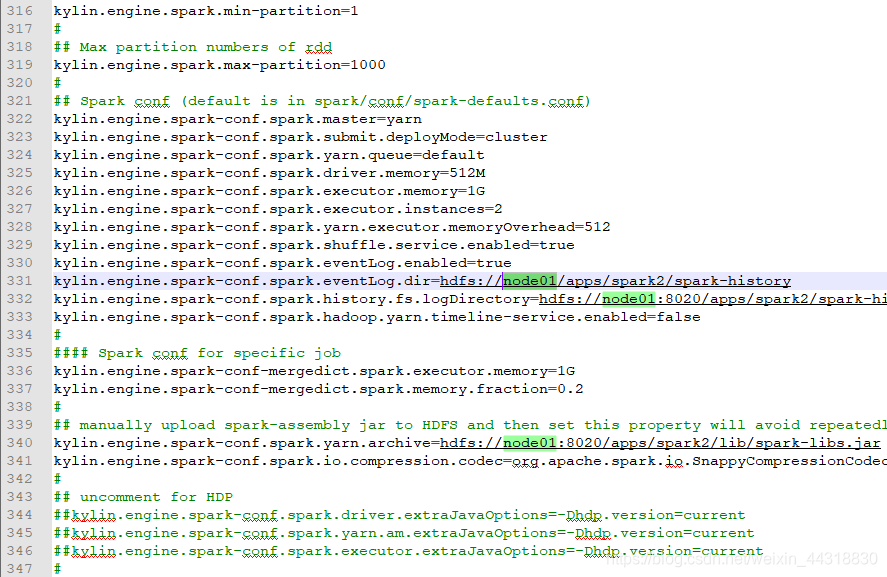
<5>初始化kylin在hdfs上的数据路径
hadoop fs -mkdir -p /apps/kylin <6>启动集群
2、启动HDFS
3、启动YARN集群
4、启动HBase集群
5、启动 metastorenohup hive --service metastore & nohup hive --service hiveserver2 & mr-jobhistory-daemon.sh start historyserver sbin/start-history-server.sh ./kylin.sh start
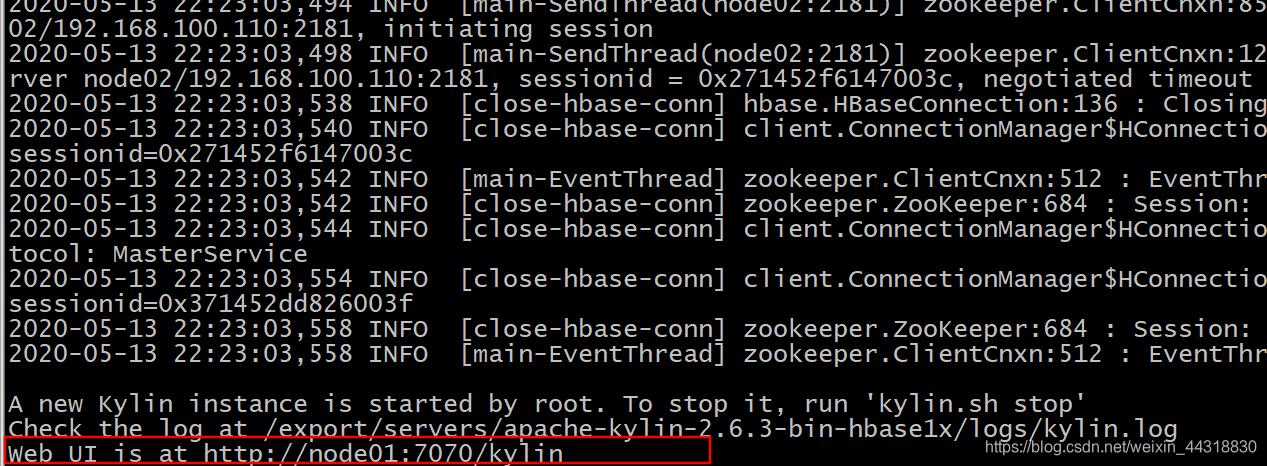
https://node01:7070/kylin对我们的kylin的WEB界面进行访问ADMIN,密码是KYLIN,注意都是大写
小结

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










