本文是基于CentOS 7.3系统环境,进行HDFS的学习和使用 HDFS是一个分布式文件系统,用于存储文件,通过目录树来定位文件,适合一次写入,多次读出的场景,不支持文件的修改。 HDFS的master,是一个主管,名称节点,管理元数据 HDFS的slave,NameNode下达命令,DataNode执行实际的操作 并非NameNode的热备,当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务 HDFS的客户端 合并两个文件 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。 这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。 但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。 Fsimage:NameNode内存中元数据序列化后形成的文件。 Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。 NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。 由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。 SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了,默认1小时,100w条)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中。 (1)通常情况下,SecondaryNameNode每隔一小时执行一次。 (2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。 将SecondaryNameNode中数据拷贝到NameNode存储数据的目录; 杀掉NameNode进程 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name) 拷贝SecondaryNameNode中数据到原NameNode存储数据目录 重新启动NameNode 使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。 修改hdfs-site.xml中的 杀掉NameNode进程 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name) 如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件 导入检查点数据,并手动启动NameNode NameNode启动时,首先将镜像文件(Fsimage)载入内存,并执行编辑日志(Edits)中的各项操作。一旦在内存中成功创建文件系统元数据的镜像,在创建一个新的Fsimage文件和一个空的编辑日志。此时,NameNode开始监听DataNode请求。这个过程期间,NameNode一直运行在安全模式,即NameNode的文件系统对于客户端来说是只读的。 系统中的数据库的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。在系统的正常操作期间,NameNode会在内存中保留所有块位置的映射信息。在安全模式下,各个DataNode会想NameNode发送最新的块列表信息,NameNode了解到足够多的块位置信息之后,即可高效运行文件系统。 如果满足“最小副本条件”,NameNode会在30秒后退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1)。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以NameNode不会进入安全模式 HDFS默认的超时时长为10分钟+30秒 退役黑名单生效后,hdfs会自动将黑名单上的机器的数据复制到其他节点,不需要用户干预,但是白名单不会这样做 等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役 不允许白名单和黑名单中同时出现同一个主机名称。 把/user/xuzheng/input目录里面的所有文件归档成一个叫input.har的归档文件,并把归档后文件存储到/user/xuzheng/output路径下
HDFS的学习和使用
1. HDFS简介
1.1 什么是HDFS
1.2 HDFS的优点
数据自动保存多个副本;当某一个副本丢失以后,可以自动恢复
能够处理数据规模达到GB、TB的数据;能够处理百万规模以上的文件数量1.3 HDFS的缺点
存储大量小文件的话,会占用NameNode大量的内存来存储文件目录和块目录,因为NameNode的内存总是有限的(128G);小文件存储的寻址时间会超过读取时间,它违反HDFS的设计目标2. HDFS架构组成
2.1 NameNode
2.2 DataNode
2.3 Secondary NameNode
2.4 Client
3. HDFS文件块大小
3.1 块的大小为什么为128M
3.2 块的大小不能设置太小,也不能设置太大
4. HDFS的shell操作
4.1 启动集群
sbin/start-dfs.sh sbin/start-yarn.sh 4.2 查看目录信息
hadoop fs -ls /user hdfs dfs -ls /user 4.3 创建目录
hadoop fs -mkdir -p /user/xuzheng/input hdfs dfs -mkdir -p /user/xuzheng/input 4.4 本地剪切文件至HDFS
hadoop fs -moveFromLocal ./aa.txt /user/xuzheng/input hdfs dfs -moveFromLocal ./aa.txt /user/xuzheng/input 4.5 追加一个文件到已经存在HDFS的文件
hadoop fs -appendToFile ./bb.txt /user/xuzheng/input/aa.txt hdfs dfs -appendToFile ./bb.txt /user/xuzheng/input/aa.txt 4.6 显示文件内容
hadoop fs -cat /user/xuzheng/input/aa.txt hdfs dfs -cat /user/xuzheng/input/aa.txt 4.7 修改文件权限
hadoop fs -chmod 777 /user/xuzheng/input/aa.txt hdfs dfs -chmod 777 /user/xuzheng/input/aa.txt hadoop fs -chown root:root /user/xuzheng/input/aa.txt hdfs dfs -chown root:root /user/xuzheng/input/aa.txt 4.8 从本地文件系统中拷贝文件到HDFS路径去
hadoop fs -copyFromLocal README.txt / hdfs dfs -copyFromLocal README.txt / 4.9 从HDFS拷贝到本地
hadoop fs -copyToLocal /user/xuzheng/input/aa.txt ./ hdfs dfs -copyToLocal /user/xuzheng/input/aa.txt ./ 4.10 在HDFS目录中移动文件
hadoop fs -mv /zhuge.txt /user/xuzheng/ hdfs dfs -mv /zhuge.txt /user/xuzheng/ 4.11 从HDFS下载文件到本地
hadoop fs -get /user/xuzheng/input/aa.txt ./ hdfs dfs -get /user/xuzheng/input/aa.txt ./ 4.12 从本地上传文件到HDFS
hadoop fs -put README.txt / hdfs dfs -put README.txt / 4.13 合并下载多个文件
hadoop fs -getmerge /user/atguigu/test/* ./zaiyiqi.txt hdfs dfs -getmerge /user/atguigu/test/* ./zaiyiqi.txt 4.14 显示一个文件的末尾
hadoop fs -tail /sanguo/shuguo/kongming.txt hdfs dfs -tail /sanguo/shuguo/kongming.txt 4.15 删除文件或文件夹
hadoop fs -rm /user/atguigu/test/jinlian2.txt hdfs dfs -rm /user/atguigu/test/jinlian2.txt 4.16 删除空文件夹
hadoop fs -rmkdir /test hdfs dfs -rmkdir /test 4.17 统计文件夹的大小信息
hadoop fs -du -s -h /user/atguigu/test hdfs dfs -du -s -h /user/atguigu/test 4.18 设置HDFS中文件的副本数量
hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt hdfs dfs -setrep 10 /sanguo/shuguo/kongming.txt 5. HDFS的Java操作
5.1 创建目录
@Test public void testMkdirs() throws InterruptedException, URISyntaxException, IOException { Configuration conf= new Configuration(); URI uri = new URI("hdfs://hadoop101:9000"); FileSystem fs = FileSystem.get(uri, conf, "xuzheng"); Path path = new Path("/test/user/xuzheng/"); fs.mkdirs(path); fs.close(); } 5.2 上传文件
@Test public void testCopyFromLocalFile() throws InterruptedException, URISyntaxException, IOException { Configuration conf= new Configuration(); URI uri = new URI("hdfs://hadoop101:9000"); FileSystem fs = FileSystem.get(uri, conf, "xuzheng"); fs.copyFromLocalFile(new Path("C:\Users\bailang\Desktop\CentOS-Self.repo"), new Path("/test/user/xuzheng/")); fs.close(); } 5.3 下载文件
@Test public void testCopyToLocalFile() throws InterruptedException, URISyntaxException, IOException { Configuration conf= new Configuration(); URI uri = new URI("hdfs://hadoop101:9000"); FileSystem fs = FileSystem.get(uri, conf, "xuzheng"); fs.copyToLocalFile(new Path("/test/user/xuzheng/CentOS-Self.repo"),new Path("C:\Users\bailang\Desktop\test")); fs.close(); } 5.4 递归删除
@Test public void testDelete() throws InterruptedException, URISyntaxException, IOException { Configuration conf= new Configuration(); URI uri = new URI("hdfs://hadoop101:9000"); FileSystem fs = FileSystem.get(uri, conf, "xuzheng"); fs.delete(new Path("/test"), true); fs.close(); } 5.5 文件重命名
@Test public void testRename() throws InterruptedException, URISyntaxException, IOException { Configuration conf= new Configuration(); URI uri = new URI("hdfs://hadoop101:9000"); FileSystem fs = FileSystem.get(uri, conf, "xuzheng"); fs.rename(new Path("/user/xuzheng/input/wc.input"), new Path("/user/xuzheng/input/aa.input")); fs.close(); } 5.6 文件详情查看
@Test public void testListFiles() throws InterruptedException, URISyntaxException, IOException { Configuration conf = new Configuration(); URI uri = new URI("hdfs://hadoop101:9000"); FileSystem fs = FileSystem.get(uri, conf, "xuzheng"); RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true); while (listFiles.hasNext()) { LocatedFileStatus fileStatus = listFiles.next(); System.out.println(fileStatus.getAccessTime()); System.out.println(fileStatus.getBlockSize()); System.out.println(fileStatus.getGroup()); System.out.println(fileStatus.getLen()); System.out.println(fileStatus.getModificationTime()); System.out.println(fileStatus.getOwner()); System.out.println(fileStatus.getPath()); System.out.println(fileStatus.getPermission()); System.out.println(fileStatus.getReplication()); BlockLocation[] blockLocations = fileStatus.getBlockLocations(); for (BlockLocation blockLocation : blockLocations) { String[] hosts = blockLocation.getHosts(); for(String host:hosts){ System.out.println("-->"+host); } } } fs.close(); } 5.7 通过IO流上传文件
@Test public void testCopyFromLocalFileByIO() throws InterruptedException, URISyntaxException, IOException { Configuration conf = new Configuration(); URI uri = new URI("hdfs://hadoop101:9000"); FileSystem fs = FileSystem.get(uri, conf, "xuzheng"); FileInputStream in = new FileInputStream("C:\Users\bailang\Desktop\CentOS-Self.repo"); FSDataOutputStream out = fs.create(new Path("/user/xuzheng/input/centos.repo")); IOUtils.copyBytes(in, out, conf); IOUtils.closeStream(out); IOUtils.closeStream(in); fs.close(); } 5.8 通过IO流下载文件
@Test public void testCopyToLocalFileByIO() throws InterruptedException, URISyntaxException, IOException { Configuration conf = new Configuration(); URI uri = new URI("hdfs://hadoop101:9000"); FileSystem fs = FileSystem.get(uri, conf, "xuzheng"); FSDataInputStream in = fs.open(new Path("/user/xuzheng/input/centos.repo")); FileOutputStream out = new FileOutputStream("C:\Users\bailang\Desktop\CentOS-test.repo"); IOUtils.copyBytes(in, out,conf); IOUtils.closeStream(out); IOUtils.closeStream(in); fs.close(); } 5.9 定位读取文件
@Test public void testReadFileSeek1() throws InterruptedException, URISyntaxException, IOException { Configuration conf = new Configuration(); URI uri = new URI("hdfs://hadoop101:9000"); FileSystem fs = FileSystem.get(uri, conf, "xuzheng"); FSDataInputStream in = fs.open(new Path("/user/xuzheng/input/hadoop-2.7.2.tar.gz")); FileOutputStream out = new FileOutputStream("C:\Users\bailang\Desktop\hadoop-2.7.2.tar.gz.part1"); byte[] buf = new byte[1024]; for (int i = 0; i < 1024 * 128; i++) { in.read(buf); out.write(buf); } IOUtils.closeStream(out); IOUtils.closeStream(in); fs.close(); } @Test public void testReadFileSeek2() throws InterruptedException, URISyntaxException, IOException { Configuration conf = new Configuration(); URI uri = new URI("hdfs://hadoop101:9000"); FileSystem fs = FileSystem.get(uri, conf, "xuzheng"); FSDataInputStream in = fs.open(new Path("/user/xuzheng/input/hadoop-2.7.2.tar.gz")); in.seek(1024 * 1024 * 128); FileOutputStream out = new FileOutputStream("C:\Users\bailang\Desktop\hadoop-2.7.2.tar.gz.part2"); IOUtils.copyBytes(in, out, conf); IOUtils.closeStream(out); IOUtils.closeStream(in); fs.close(); } type hadoop-2.7.2.tar.gz.part2>>hadoop-2.7.2.tar.gz.part1 6. HDFS的写数据流程
6.1 剖析文件写入

6.2 网络拓扑-节点距离计算
两个节点到达最近的共同祖先的距离总和
一个节点到达父节点的距离为1
Distance(/d1/r1/n0,/d1/r1/n0)=0
Distance(/d1/r1/n1,/d1/r1/n2)=2
Distance(/d1/r2/n0,/d1/r3/n2)=4
Distance(/d1/r2/n1,/d2/r4/n1)=6
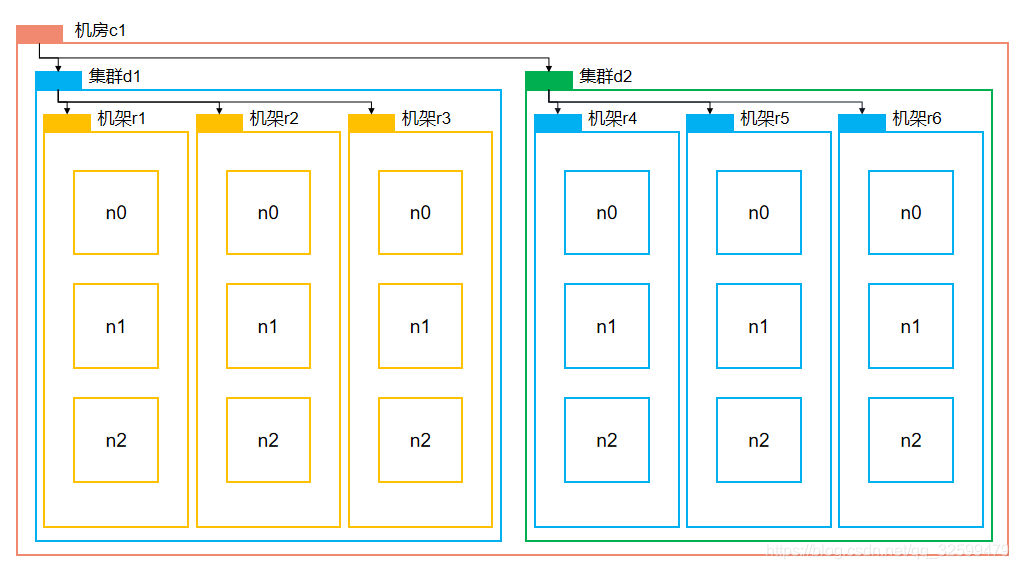
6.3 机架感知(副本存储节点选择)

7. HDFS的读数据流程
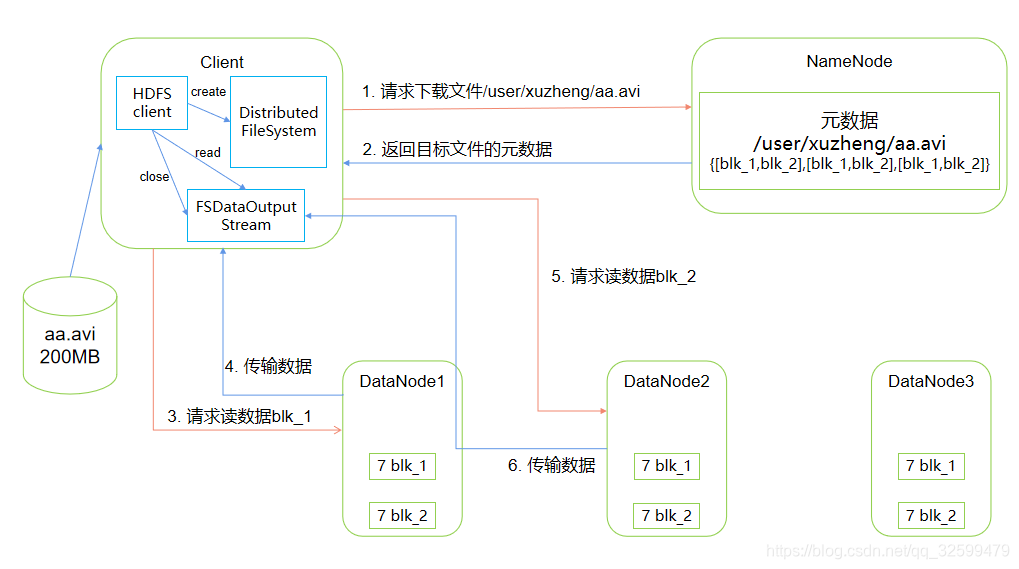
8. NameNode
8.1 NameNode中的元数据是存储在哪里的
8.2 NN和2NN工作流程
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对数据进行增删改。
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。

8.3 NN和2NN工作机制
8.3 CheckPoint时间设置
[hdfs-default.xml] <property> <name>dfs.namenode.checkpoint.period</name> <value>3600</value> </property> <property> <name>dfs.namenode.checkpoint.txns</name> <value>1000000</value> <description>操作动作次数</description> </property> <property> <name>dfs.namenode.checkpoint.check.period</name> <value>60</value> <description> 1分钟检查一次操作次数</description> </property > 8.4 NameNode故障处理
(1) 方法一(推荐使用)
kill -9 NameNode进程 rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/* scp -r atguigu@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/* ./name/ sbin/hadoop-daemon.sh start namenode (2) 方法二(不推荐使用)
<property> <name>dfs.namenode.name.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp/dfs/name</value> </property> # 同步配置文件 /home/xuzheng/bin/xsync hdfs-sit.xml kill -9 NameNode进程 rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/* scp -r atguigu@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary ./ rm -rf in_use.lock bin/hdfs namenode -importCheckpoint sbin/hadoop-daemon.sh start namenode 8.5 集群安全模式
NameNode启动
DataNode启动
安全模式退出判断
基本语法
# 查看安全模式状态 hdfs dfsadmin -safemode get # 进入安全模式状态 hdfs dfsadmin -safemode enter # 离开安全模式状态 hdfs dfsadmin -safemode leave # 等待安全模式状态 hdfs dfsadmin -safemode wait 9. DataNode
9.1 DataNode工作机制

9.2 DataNode超时时长
TimeOut=2×dfs.namenode.heartbeat.recheck-interval +10×dfs.heartbeat.intervalvi hdfs-site.xml # 添加如下配置,心跳重新检查时间间隔和心跳时间间隔 <property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>300000</value> </property> <property> <name>dfs.heartbeat.interval</name> <value>3</value> </property> 9.3 服役新的DataNode节点
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start nodemanager 9.4 添加白名单(不推荐使用)
vi dfs.hosts # 添加如下白名单节点 hadoop101 hadoop102 hadoop103
vi hdfs-site.xml # 添加如下配置,增加dfs.hosts属性 <property> <name>dfs.hosts</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value> </property>
# 分发配置文件 xsync hdfs-site.xml xsync dfs.hosts
# 分发配置文件 hdfs dfsabmin -refreshNodes
# 分发配置文件 yarn rmabmin -refreshNodes
# 分发配置文件 sbin/start-balancer.sh 黑名单退役(推荐使用)
vi dfs.hosts.exclude # 添加如下白名单节点 hadoop104 hadoop105
vi hdfs-site.xml # 添加如下配置,增加dfs.hosts属性 <property> <name>dfs.hosts.exclude</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value> </property>
# 分发配置文件 xsync hdfs-site.xml xsync dfs.hosts.exclude
# 分发配置文件 NameNode节点 hdfs dfsabmin -refreshNodes
# 分发配置文件 NameNode节点 yarn rmabmin -refreshNodes
sbin/hadoop-daemon.sh stop datanode
sbin/yarn-daemon.sh stop nodemanager
# 分发配置文件 sbin/start-balancer.sh 10. HDFS新特性
9.1 集群拷贝
# 这里的地址都是NameNode的地址 bin/hadoop distcp hdfs://hadoop202:9000/user/xuzheng/a.txt hdfs://hadoop302:9000/user/xuzheng/a.txt 9.2 小文件归档
归档文件
bin/hadoop archive -archiveName input.har –p /user/xuzheng/input /user/xuzheng/output 查看归档
hadoop fs -lsr har:///user/xuzheng/output/input.har 解归档文件
hadoop fs -cp har:///user/xuzheng/output/input.har/* /user/xuzheng 9.3 回收站
启用回收站
vi core-site.xml # 添加下面信息,开启回收站文件保留时间,分钟 <property> <name>fs.trash.interval</name> <value>1</value> </property> # 修改访问垃圾回收站用户名称 <property> <name>hadoop.http.staticuser.user</name> <value>xuzheng</value> </property> 重启集群
sbin/stop-yarn.sh sbin/stop-dfs.sh sbin/start-dfs.sh sbin/start-yarn.sh 恢复回收站数据
hadoop fs -mv /user/atguigu/.Trash/Current/user/xuzheng/input /user/xuzheng/input
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










