写在前面: 博主是一名软件工程系大数据应用开发专业大二的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白, 上一篇博客已经为各位朋友带来了Kylin的简介以及安装部署(👉第一个”国产”Apache顶级项目——Kylin,了解一下!)。本篇博客,博主为大家带来的是关于Kylin的实际应用操作! 码字不易,先赞后看,养成习惯 1、(事实表)dw_sales 2、(维度表_渠道方式)dim_channel 3、(维度表_产品名称)dim_product 4、(维度表_区域)dim_region 为了方便后续学习Kylin的使用,需要准备一些测试表、测试数据。 1.Hive中创建表 操作步骤 1、使用 beeline 连接Hive 2、创建并切换到 itcast_dw 数据库 3、找到资料中的hive.sql文件,执行sql、创建测试表 导入数据到表中 5、执行一条SQL语句,确认数据是否已经成功导入 在完成了上面的数据准备操作后,我们就开始进行kylin的实际操作了。但我们还需要先了解什么是指标和维度? 先来看下面这个问题 红色字体是指标/度量?还是维度? 蓝色字体是指标/度量?还是维度? 结论:需求决定哪些是维度,哪些是指标。 好了,明确了什么是维度,什么是指标之后,我们就可以开启kylin的使用之旅了~ 要使用Kylin进行OLAP分析,需要按照以下方式来进行。 1、创建项目(Project) 2、创建数据源(DataSource) 3、创建模型(Model) 4、创建立方体(Cube) 5、执行构建、等待构建完成 6、再执行SQL查询,获取结果 从Cube中查询数据 我们可以发现用Kylin执行HQL语句的速度最早为 那如果在Hive的命令行窗口执行相同的HQL语句,耗时将为多少呢? 下面我们来总结一下上面这个入门案例: 如果有认真执行上面演示的案例 在创建一个Cube的时候,第一步就需要选择依赖于一个Model,所以Model和Cube的对应关系应该是一对多,且Model包含Cube的关系。 另外,在Cube内的元素,也是可以重复的,不同的Cube就相当于一个Model的子集。 另外,我们在最后查看最终计算完毕的结果数据时,可以发现一些额外的信息。 Kylin将查询后的结果写入到了HBase的表中 说明初次体验Kylin体验还是不错的~ 本篇博客用一个入门案例为大家演示了Kylin的基本操作,关于Kylin的进阶操作会在后续的博文中为大家揭晓,敬请期待! 如果以上过程中出现了任何的纰漏错误,烦请大佬们指正😅 受益的朋友或对大数据技术感兴趣的伙伴记得关注支持一波🙏
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:https://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
文章目录
入门案例
测试数据表结构介绍
列名
列类型
说明
id
string
订单id
date1
string
订单日期
channelid
string
订单渠道(商场、京东、天猫)
productid
string
产品id
regionid
string
区域名称
amount
int
商品下单数量
price
double
商品金额
列名
列类型
说明
channelid
string
渠道id
channelname
string
渠道名称
列名
列类型
说明
productid
string
产品id
productname
string
产品名称
列名
列类型
说明
regionid
string
区域id
regionname
string
区域名称
导入测试数据
2.将数据从本地文件导入到Hive!connect jdbc:hive2://node1:10000 create database itcast_kylin_dw; use itcast_kylin_dw; -- 查看表是否创建成功 show tables; 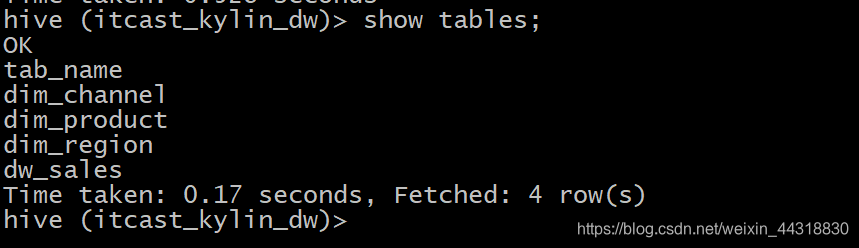
4、在home目录创建~/dat_file 文件夹,并将测试数据文件上传到该文件夹中
mkdir ~/dat_file-- 导入数据 LOAD DATA LOCAL INPATH '/root/dat_file/dw_sales_data.txt' OVERWRITE INTO TABLE dw_sales; LOAD DATA LOCAL INPATH '/root/dat_file/dim_channel_data.txt' OVERWRITE INTO TABLE dim_channel; LOAD DATA LOCAL INPATH '/root/dat_file/dim_product_data.txt' OVERWRITE INTO TABLE dim_product; LOAD DATA LOCAL INPATH '/root/dat_file/dim_region_data.txt' OVERWRITE INTO TABLE dim_region;

指标和维度

相信各位朋友已经有了自己的答案,这里提供一种思路:
答案:指标/度量【到底要看什么?获取什么?】
答案:维度【怎么看!怎么获取!】

按照日期统计订单总额/总数量(Kylin方式)
具体步骤:
1、创建项目(Project)
2、创建数据源(DataSource)
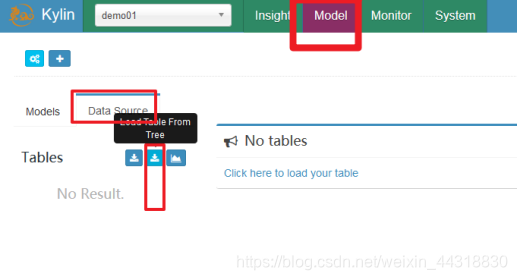
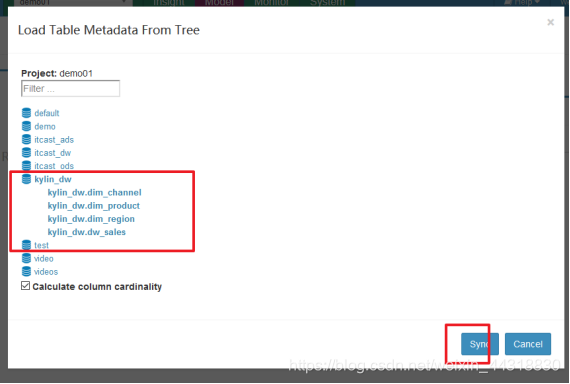
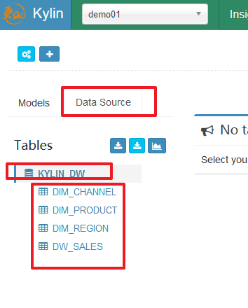
3、创建模型(Model)
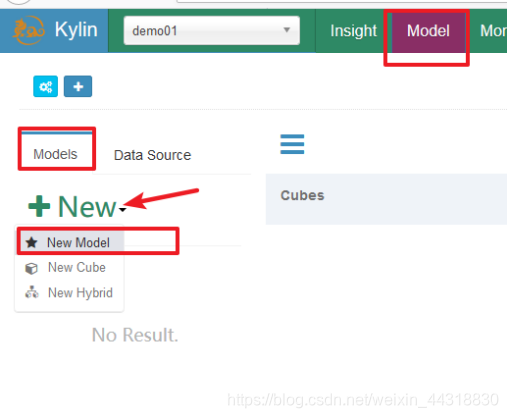
设置model名称
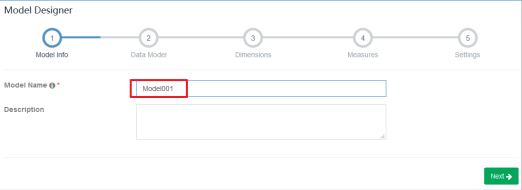
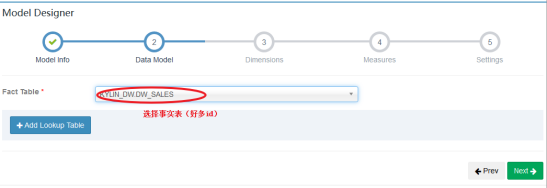
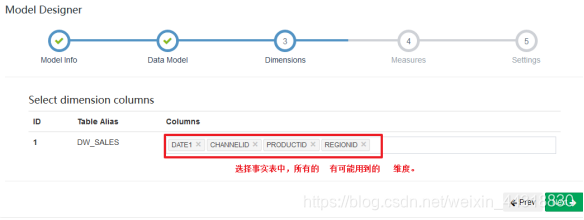
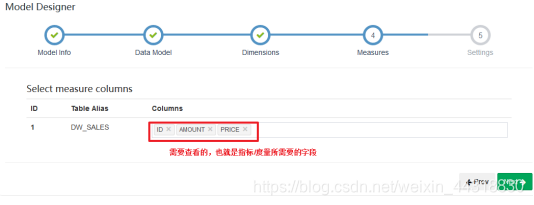
直接下一步
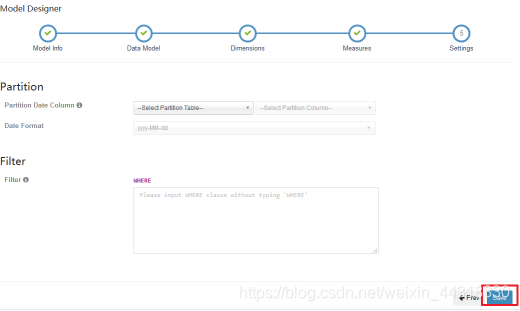
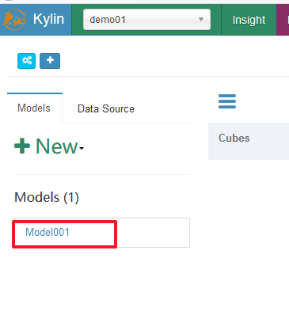
save保存完毕,就可以看见一个已经创建好了的Model
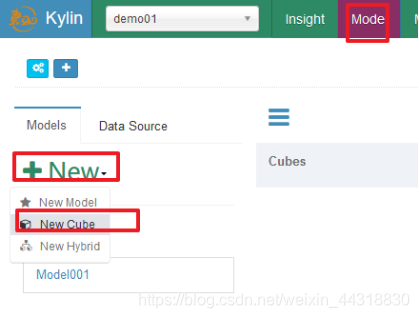
4、创建立方体(Cube)
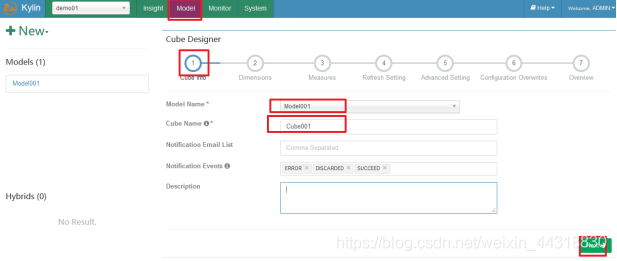
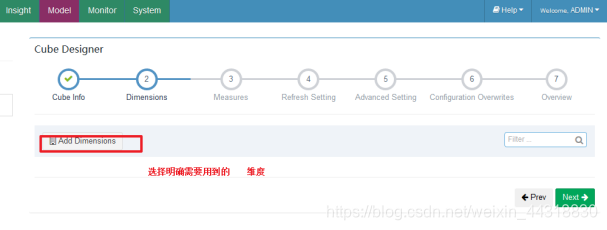
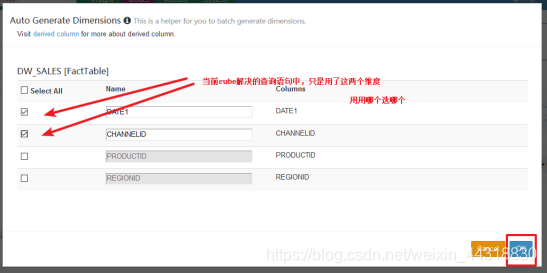
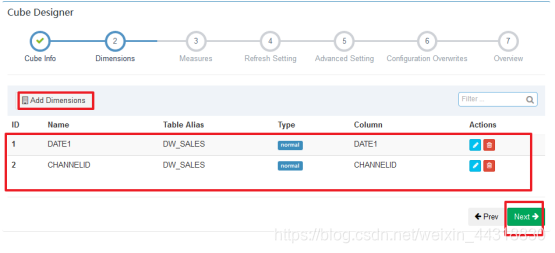
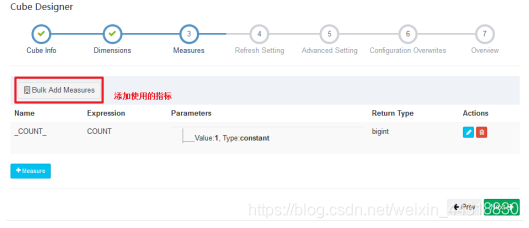
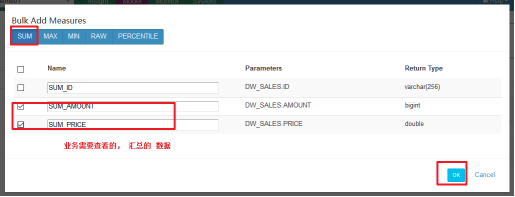
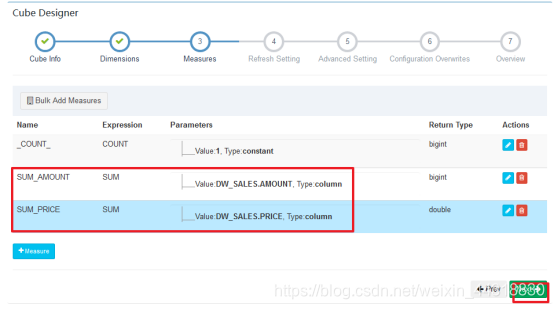
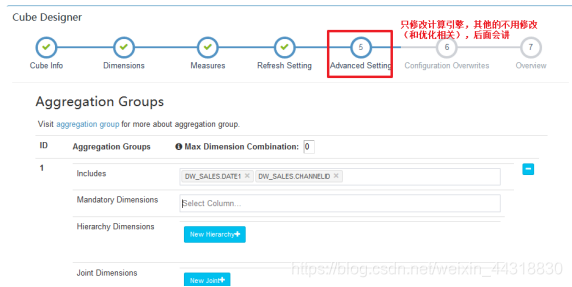
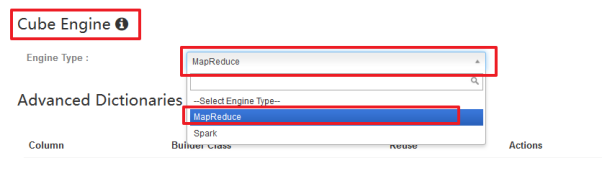

保存完毕,我们可以看见一个新的Cube已经创建好了~
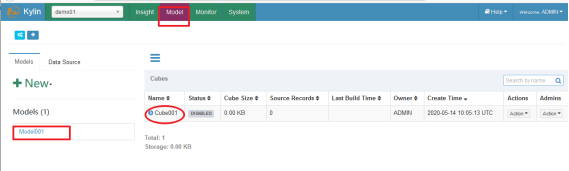
5、执行构建、等待构建完成
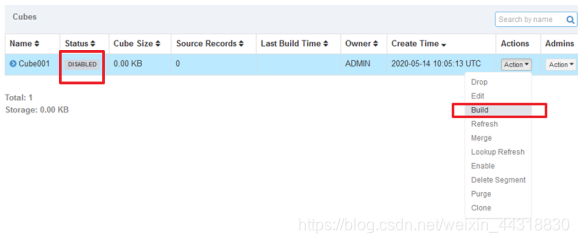
此时进度条还是灰色的,稍等片刻,等到加载完毕~
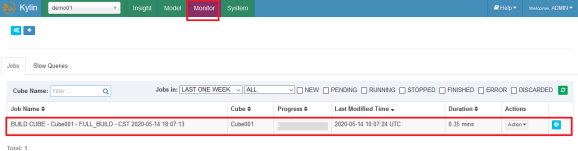

待加载完毕,我们可以发现此时的cube状态已经变成READY了。
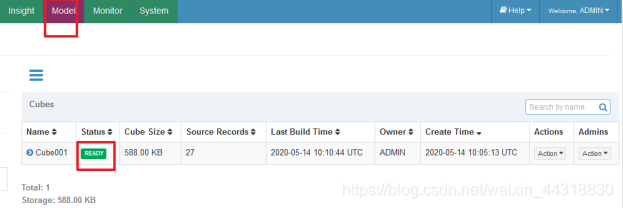
6、再执行SQL查询,获取结果
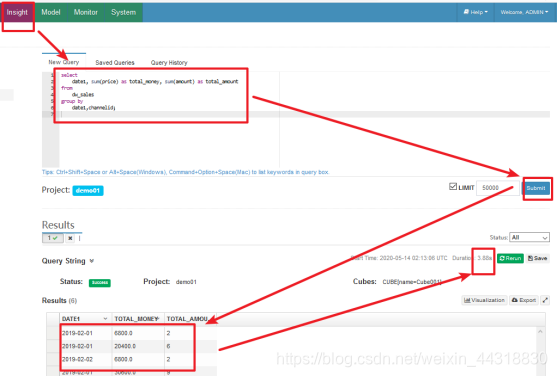
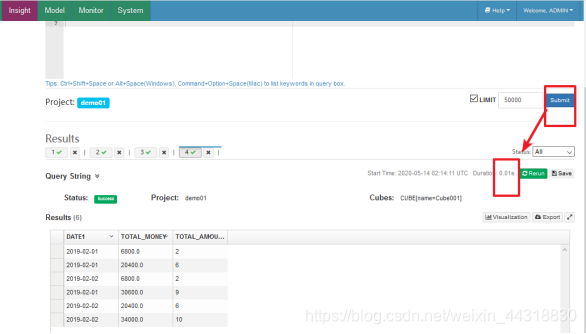
3.88s,第二次执行就变成了0.01s
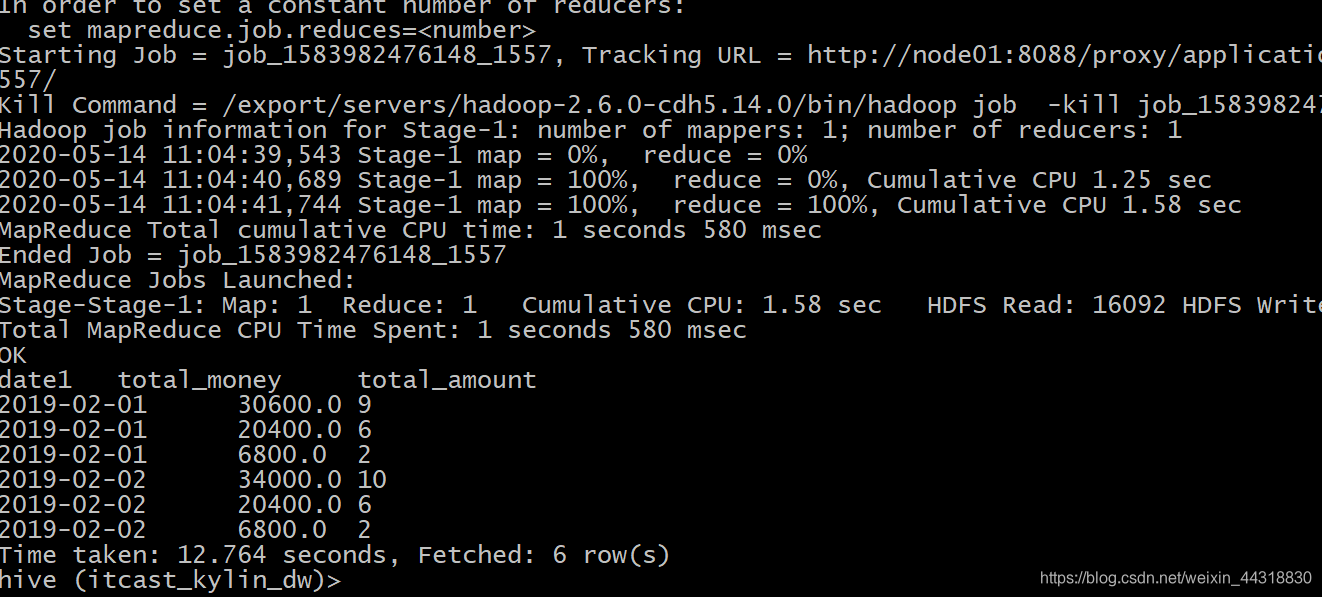
可以看到Hive将HQL转化成MapReduce程序去执行后,查询的时间为12.764s,这个速度与上面用Kylin执行的速度相比,差了近100倍。如果数据量更大一些,Kylin的优势将会更加明显。
我相信推导出下面的关系应该不难
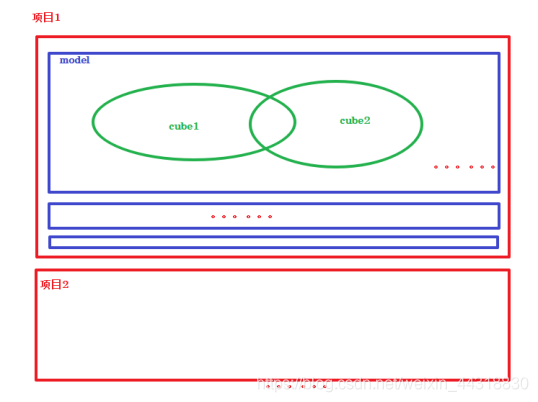
因为我们在设置Model的时候,会选择事实表中所有有可能用到的维度,而在设置Cube的时候,就需要根据实际的SQL需求,选择确定使用到的维度。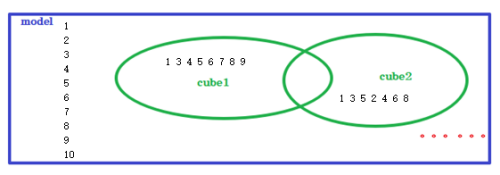
关于前面的步骤中,设置维度—维度就是sql中GroupBY后面的字段.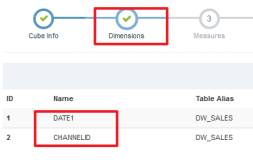
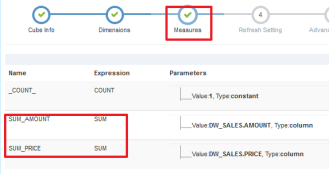
设置指标/度量—指标/度量就是sql中select 后面的字段.
整个配置过程都来源于SQL,来源于需求。
运用所学这里再回顾一下刚介绍Kylin时所介绍的架构图
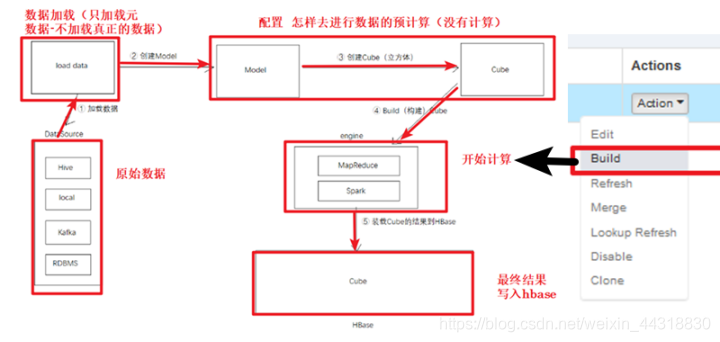
可以看出,整个流程分为创建项目—引入数据—创建模型—创建cube –编译 – 查询
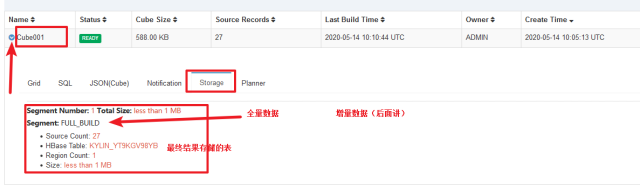
我们根据显示的信息,去HBase中查询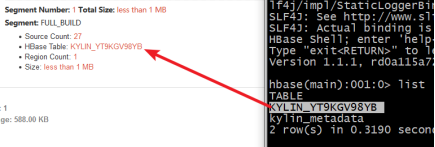
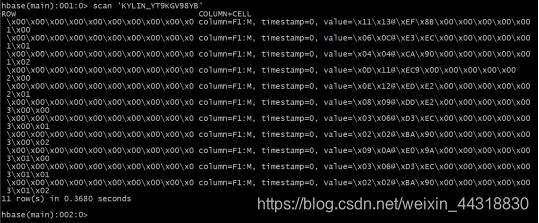
可以发现虽然内容被加密了,但是能证明有数据
总结

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










