Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful
web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
| es | 数据库 |
|---|---|
| 索引(index) | 表 |
| 文档 (document) | 行(记录) |
| 字段 (fields) | 列 |
| 类型(type) | 字段属性 |
stu_index //这个就是索引 //这就是一个行 { //这就是一个列 id: 1001, name: jason, age: 19 }, { id: 1002, name: tom, age: 18 }, { id: 1003, name: rose, age: 22 } 
分片(shard):把索引库拆分为多份,分别放在不同的节点上,比如有3个节点,3个节点的所有数据内容加在一起是一个完整的索引库。分别保存到三个节点上,目的为了水平扩展,提高吞吐量。
备份(replica):每个shard的备份。
简称
shard = primary shard(主分片)
replica = replica shard(备份节点)

通过id去寻找内容,比如我想查到‘我喜欢学java’这个内容,我就需要知道他的id来查找这个内容,这个就是正排索引,通过id来建立索引
| id | 内容 |
|---|---|
| 1 | 我喜欢学java语言 |
| 2 | java是世界上最好的语言 |
| 3 | 996是福报 |
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
简单来说就是不通过key来进行搜索,而是根据value来进行搜索。
利用value来进行搜索有以下几个好处:
词频TF:位置POS:
文档id:出现次数:在文档中的位置
| 单词 | 文档ids | 词频TF:位置POS |
|---|---|---|
| 我 | 1 | 1:1<1> |
| 喜欢 | 1 | 1:1<2> |
| 学 | 1 | 1:1<3> |
| java | 1,2 | 1:1:<4>,2:1:<1> |
| 是 | 2,3 | 2:1:<2>,3:1:<2> |
| 世界上 | 2 | 2:1:<3> |
| 最好 | 2 | 2:1:<4> |
| 的 | 2 | 2:1:<5> |
| 语言 | 1,2 | 1:1:<5>,2:1:<6> |
| 996 | 3 | 3:1:<1> |
| 福报 | 3 | 3:1:<3> |
linux版本:centos7
资源地址:
链接:https://pan.baidu.com/s/13HBOtno8Z7sHYWbS9cwCLg
提取码:kygy
将文件上传的服务器上
解压缩文件tar -zxvf elasticsearch-7.4.2-linux-x86_64.tar.gz
将解压后的文件夹移动到local下好管理mv elasticsearch-7.4.2 /usr/local
进入到local文件夹下cd /usr/local
修改核心配置文件
修改集群名称,虽然目前是单机,但是也会有默认的
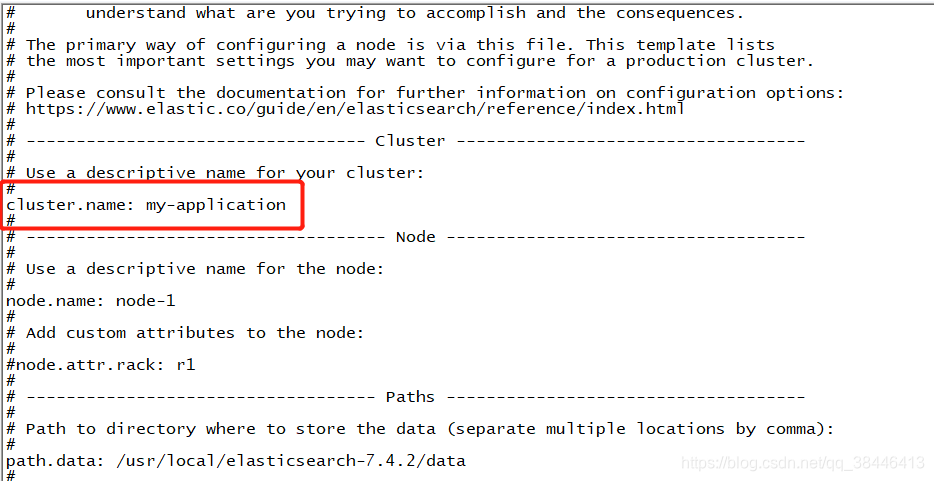
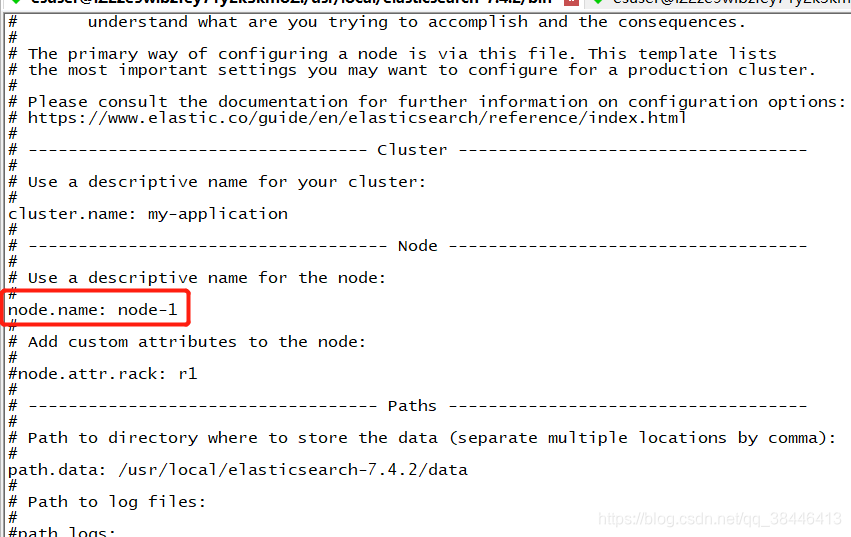
为当前的es节点取个名称,名称随意,如果在集群环境中,都要有相应的名字
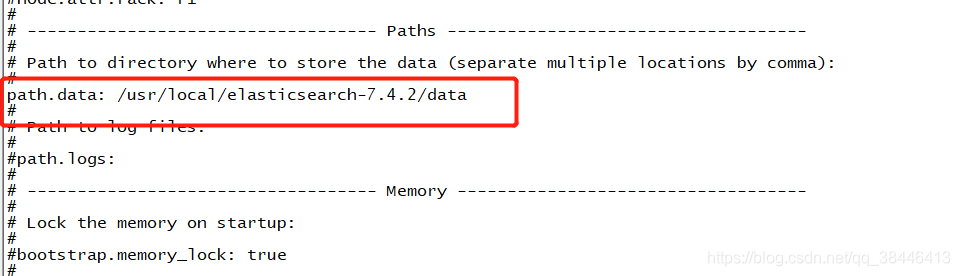
修改data数据保存地址
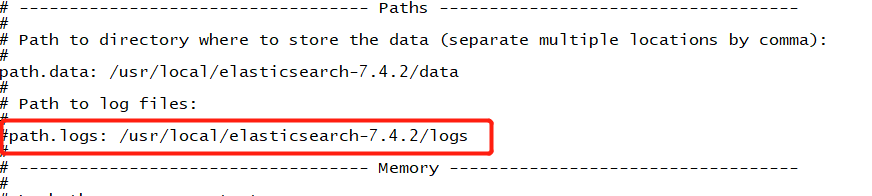
修改日志数据保存地址
绑定es网络ip,原理同redis默认端口号,可以自定义修改
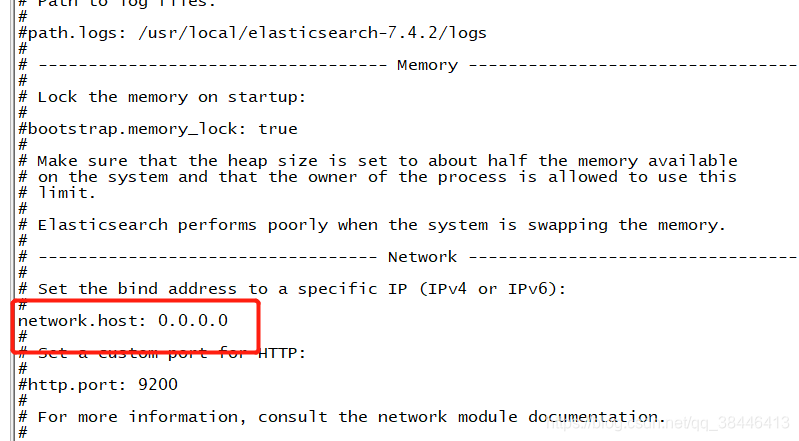
集群节点,名字可以先改成之前的那个节点名称
添加用户 ES不允许使用root操作es,需要添加用户,操作如下:
useradd esuser chown -R esuser:esuser /usr/local/elasticsearch-7.4.2 su esuser whoami ./elasticsearchIP:9200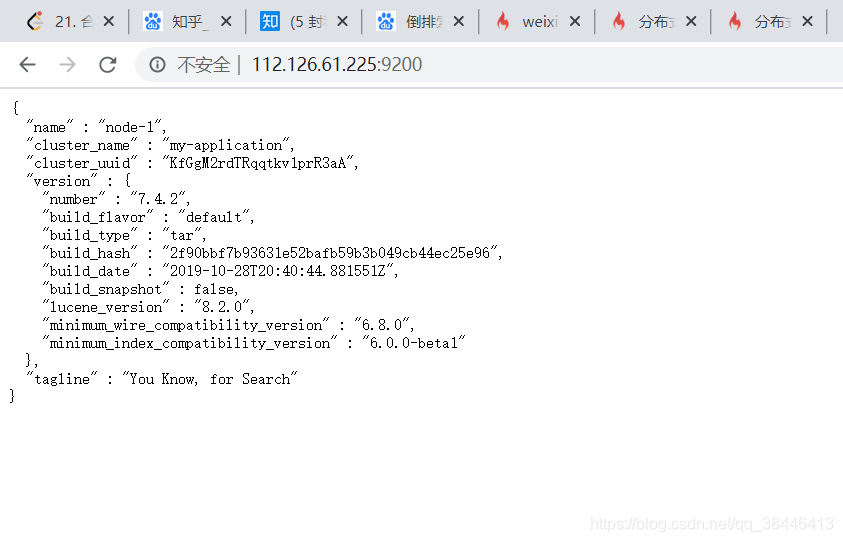
注意:如果启动失败请往下看!!!
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c5330000, 986513408, 0) failed; error='Cannot allocate memory' (errno=12) 解决办法:
注:如果你的安装步骤和我一样,那么这个配置文件就在这个目录下面,如果不一样,请到你自己的es安装目录下修改这个配置文件
vim /usr/.local/elasticsearch-7.4.2/config/jvm.options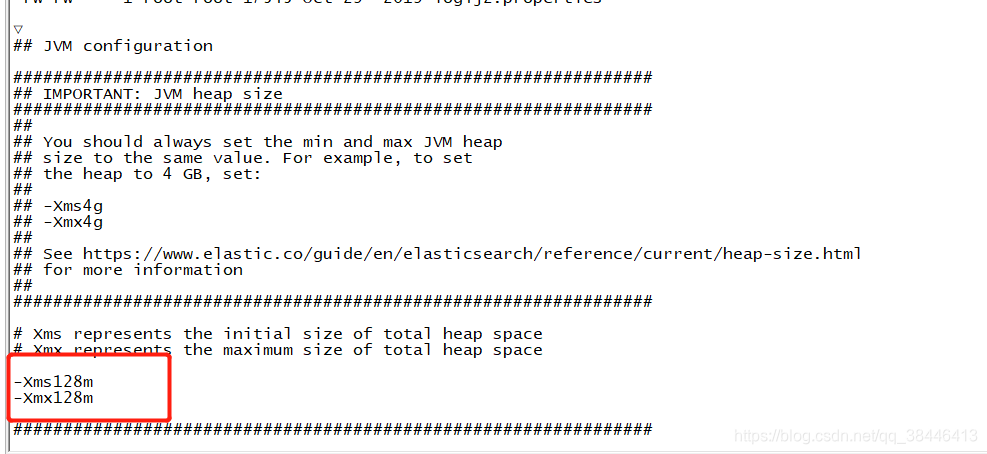
ERROR: [1] bootstrap checks failed [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 解决办法:
vim /etc/sysctl.confvm.max_map_count=262145
sysctl -p刷新一下Caused by: java.lang.RuntimeException: can not run elasticsearch as root 解决办法:新建一个用户,切换到新建用户下启动
useradd esuser chown -R esuser:esuser /usr/local/elasticsearch-7.4.2 su esuser whoami 
解决办法:
vim /etc/security/limits.conf* soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096 解决办法:云服务器记得添加安全组配置,虚拟机把防火墙关掉
es进行搜索是很快,但是还是会有瓶颈的,如果一台es的吞吐量为1000/s,那么当请求超过1000的时候,es就处理不了的,这个时候怎么办呢?es提供了一种解决办法,就是将多台es做成一个集群来处理请求,而集群中的每一个es就被称为shard(分片),用户的请求会平均分配到集群中的每一个分片上,并且每一个分片都可以并行的处理用户的请求,通过es的集群就可以加大es的请求处理数,但是数据是平均分配到各个分片上的,如果有一台es崩溃了怎么办,那不就是会有一批数据搜索不到了嘛,这个时候就得引出另外一个名词了备份(replica),在每一个分片上在加上一个备份节点,这样如果shard崩溃了,还有备份节点可以工作,保证数据的准确性。
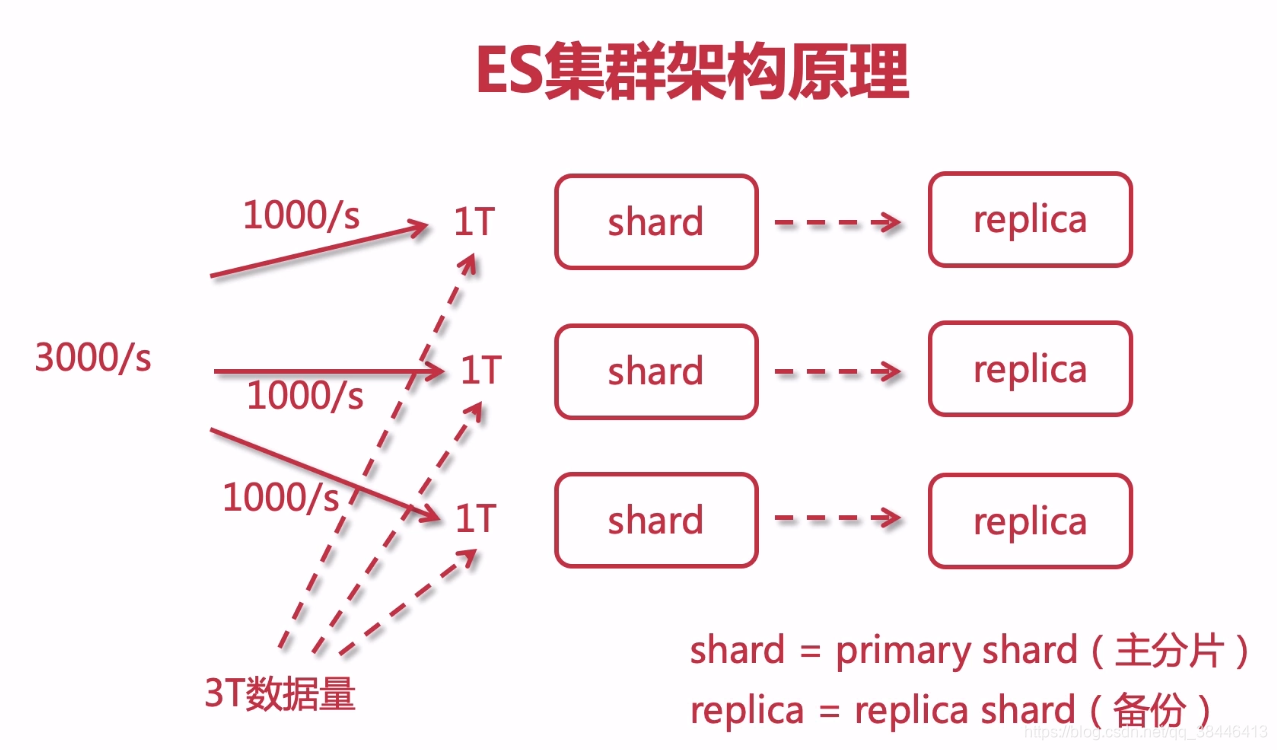
每个索引可以被分片,就相当于吃披萨的时候被切了好几块,然后分给不同的人吃
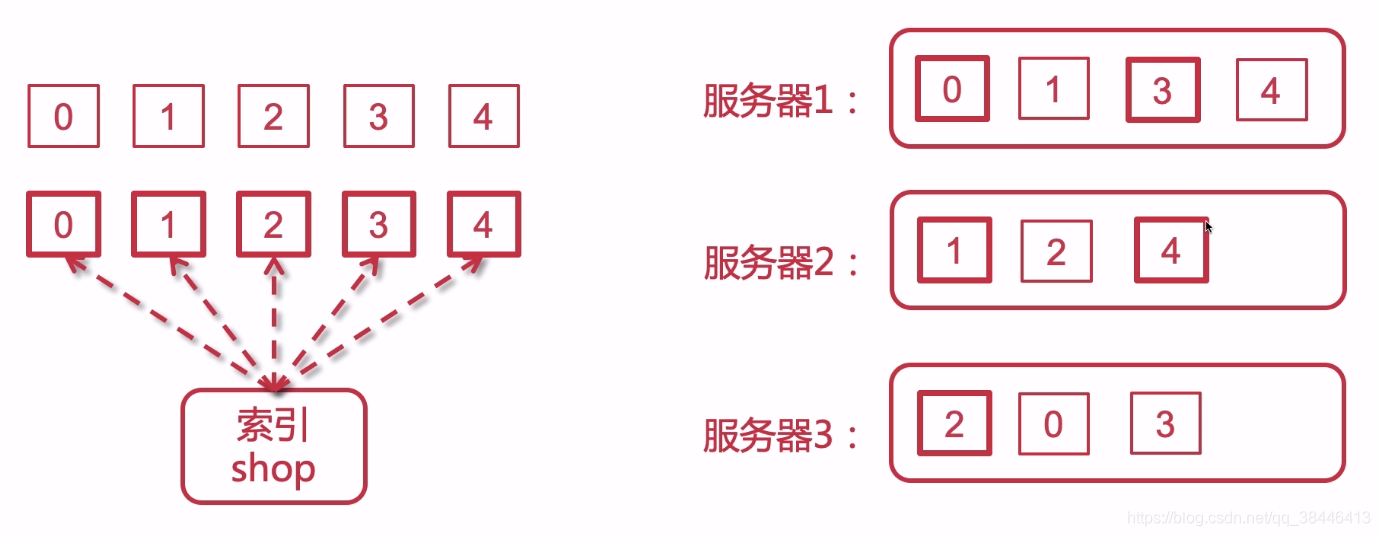
假如有三台服务器配成集群,那么每一个分片会分配到不同的集群上,并且同一个分片和副本不会分配到同一台服务器上
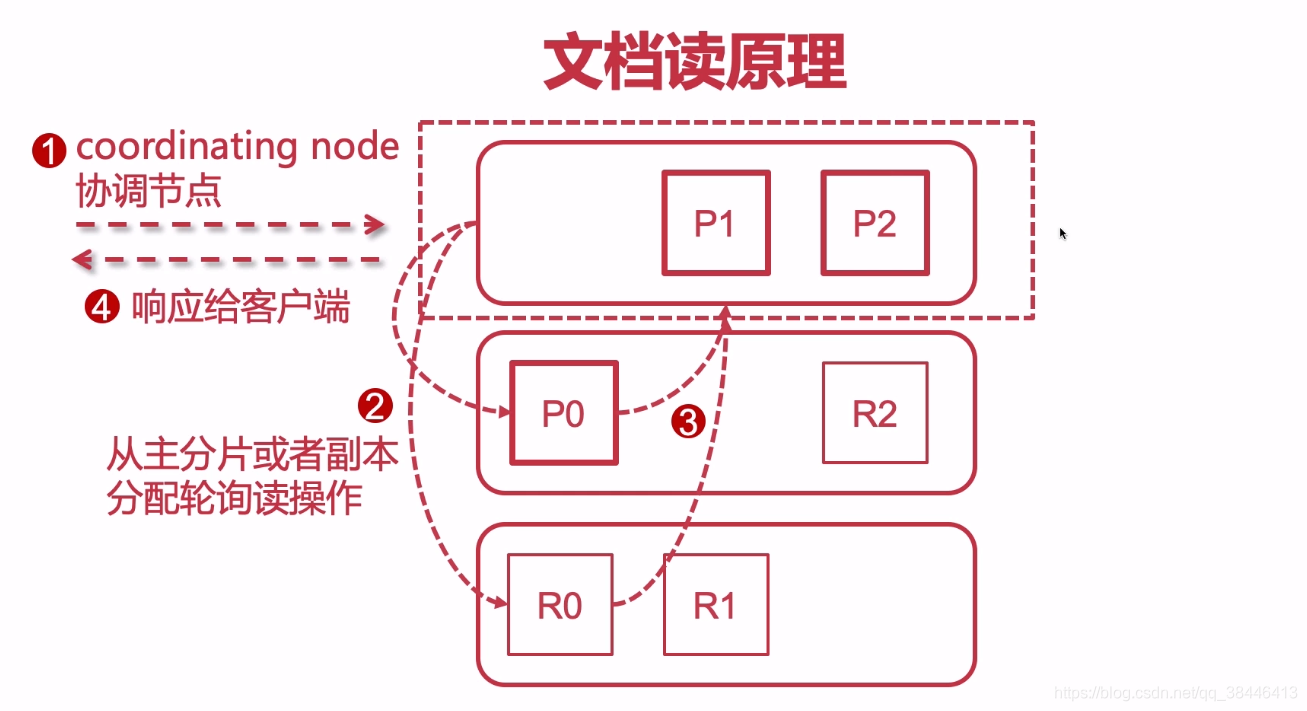
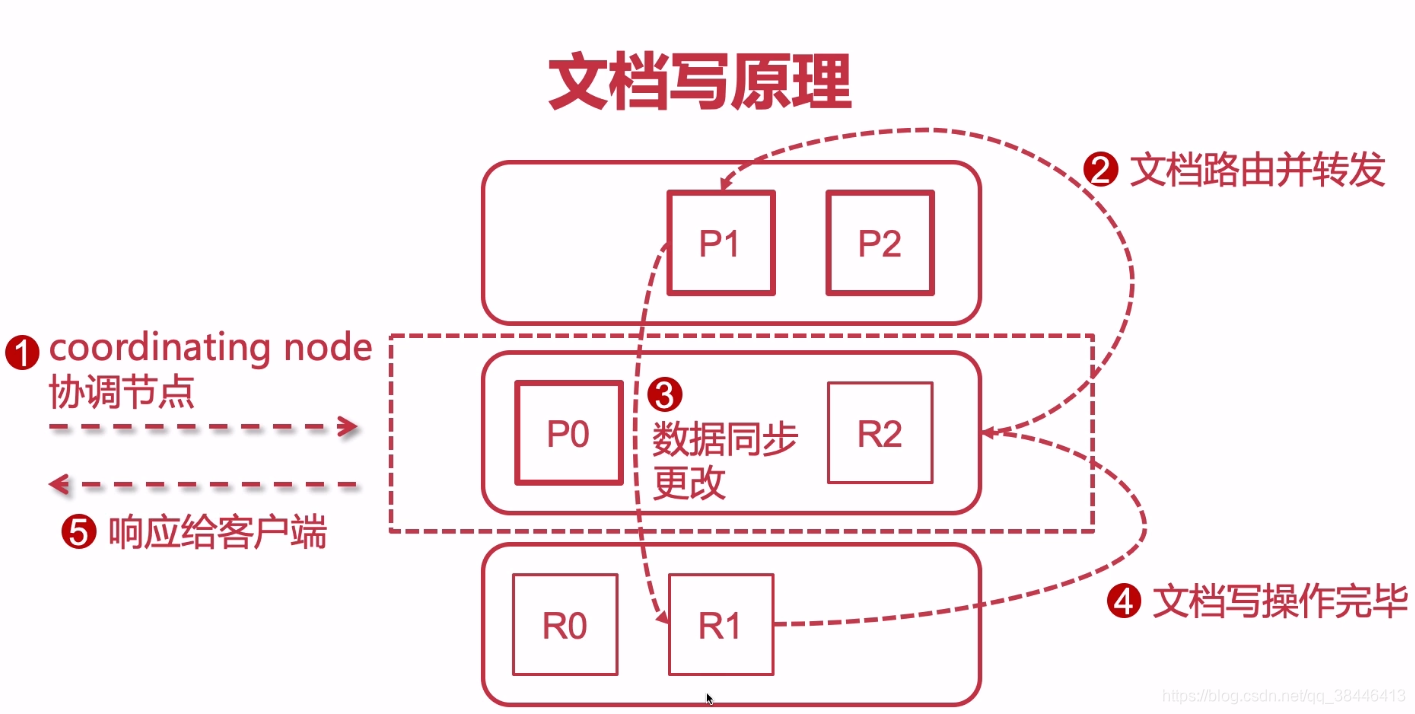
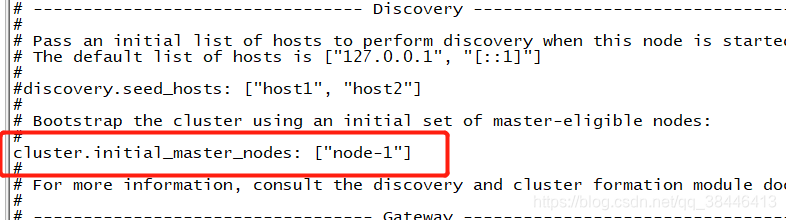
rm -rf nodes/# 配置集群名称,保证每个节点的名称相同,如此就能都处于一个集群之内了 cluster.name: imooc-es-cluster # 每一个节点的名称,必须不一样 node.name: es-node1 # http端口(使用默认即可) http.port: 9200 # 主节点,作用主要是用于来管理整个集群,负责创建或删除索引,管理其他非master节点(相当于企业老总) node.master: true # 数据节点,用于对文档数据的增删改查 node.data: true # 集群列表 discovery.seed_hosts: ["192.168.1.184", "192.168.1.185", "192.168.1.186"] # 启动的时候使用一个master节点 cluster.initial_master_nodes: ["es-node1"] 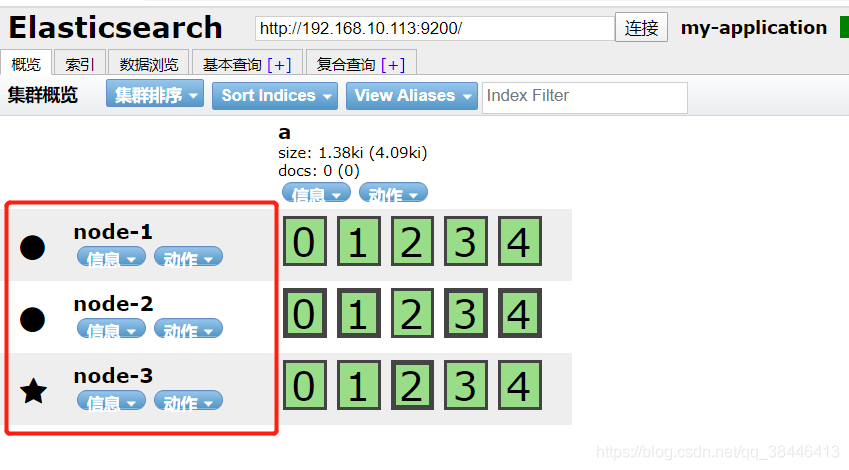
1.将压缩包上传的linux上
2.解压缩zip包,将解压后的文件放到{Elasticsearch}/plugin/ik(ik自己建)
unzip elasticsearch-analysis-ik-6.4.3 .zip -d /usr/local/elasticsearch-6.4.3/ik
注:如果环境上没有unzip ,就先安装
yum -y install zip unzip
3.重启 Elasticsearch
请求方式:POST
请求路径:/_analyze
请求信息:
{ "analyzer": "ik_max_word", "text": "上下班车流量很大" } 响应结果:
{ "tokens": [ { "token": "上下班", "start_offset": 0, "end_offset": 3, "type": "CN_WORD", "position": 0 }, { "token": "上下", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 1 }, { "token": "下班", "start_offset": 1, "end_offset": 3, "type": "CN_WORD", "position": 2 }, { "token": "班车", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 }, { "token": "车流量", "start_offset": 3, "end_offset": 6, "type": "CN_WORD", "position": 4 }, { "token": "车流", "start_offset": 3, "end_offset": 5, "type": "CN_WORD", "position": 5 }, { "token": "流量", "start_offset": 4, "end_offset": 6, "type": "CN_WORD", "position": 6 }, { "token": "很大", "start_offset": 6, "end_offset": 8, "type": "CN_WORD", "position": 7 } ] } 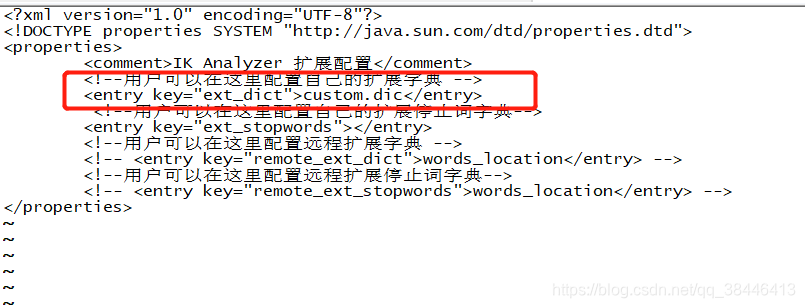
都是用的Restful形式
_index:文档数据所属那个索引,理解为数据库的某张表即可。
_type:文档数据属于哪个类型,新版本使用_doc。
_id:文档数据的唯一标识,类似数据库中某张表的主键。可以自动生成或者手动指定。
_score:查询相关度,是否契合用户匹配,分数越高用户的搜索体验越高。
_version:版本号。
_source:文档数据,json格式。
文档删除不是立即删除,文档还是保存在磁盘上,索引增长越来越多,才会把那些曾经标识过删除的,进行清理,从磁盘上移出去
每次修改版本号都会更新
注:如果索引没有手动建立mappings,那么当插入文档数据的时候,会根据文档类型自动设置属性类型。这个就是es的动态映射,帮我们在index索引库中去建立数据结构的相关配置信息。
“fields”: {“type”: “keyword”}
对一个字段设置多种索引模式,使用text类型做全文检索,也可使用keyword类型做聚合和排序“ignore_above” : 256
设置字段索引和存储的长度最大值,超过则被忽略
请求方式:GET
请求路径:https://112.126.61.225:9200/
返回值:
{ "name": "node-1", "cluster_name": "my-application", "cluster_uuid": "KfGgM2rdTRqqtkv1prR3aA", "version": { "number": "7.4.2", "build_flavor": "default", "build_type": "tar", "build_hash": "2f90bbf7b93631e52bafb59b3b049cb44ec25e96", "build_date": "2019-10-28T20:40:44.881551Z", "build_snapshot": false, "lucene_version": "8.2.0", "minimum_wire_compatibility_version": "6.8.0", "minimum_index_compatibility_version": "6.0.0-beta1" }, "tagline": "You Know, for Search" } 请求方式:GET
请求路径:https://112.126.61.225:9200/_cluster/health
返回值:
{ "cluster_name": "my-application", "status": "green", "timed_out": false, "number_of_nodes": 1, "number_of_data_nodes": 1, "active_primary_shards": 2, "active_shards": 2, "relocating_shards": 0, "initializing_shards": 0, "unassigned_shards": 0, "delayed_unassigned_shards": 0, "number_of_pending_tasks": 0, "number_of_in_flight_fetch": 0, "task_max_waiting_in_queue_millis": 0, "active_shards_percent_as_number": 100.0 } 请求方式:PUT
请求路径:https://112.126.61.225:9200/my_doc
返回值:
{ "acknowledged": true, "shards_acknowledged": true, "index": "my_doc" } 请求方式:DELETE
请求路径:https://112.126.61.225:9200/demo
返回值:
{ "acknowledged": true } 请求方式:GET
请求路径:https://112.126.61.225:9200/_cat/indices?v
返回值:
{ "index_demo": { "aliases": {}, "mappings": {}, "settings": { "index": { "creation_date": "1588839521441", "number_of_shards": "2", "number_of_replicas": "0", "uuid": "_6jMGpZfTu2E4Vfp7yd9bg", "version": { "created": "7040299" }, "provided_name": "index_demo" } } } } 请求方式:GET
请求路径:https://112.126.61.225:9200/index_demo
返回值:
{ "index_demo": { "aliases": {}, "mappings": {}, "settings": { "index": { "creation_date": "1588839521441", "number_of_shards": "2", "number_of_replicas": "0", "uuid": "_6jMGpZfTu2E4Vfp7yd9bg", "version": { "created": "7040299" }, "provided_name": "index_demo" } } } } 请求方式:PUT
请求路径:https://112.126.61.225:9200/index_test
请求参数:
{ "mappings": { "properties": { "realname": { "type": "text", "index": true }, "username": { "type": "keyword", "index": false } } } } 返回值:
{ "acknowledged": true, "shards_acknowledged": true, "index": "index_test" } 请求方式:POST
请求路径:https://112.126.61.225:9200/index_test/_mapping
请求参数:
{ "properties": { "name": { "type": "long" } } } 返回值:
{ "acknowledged": true } 请求方式:GET
请求路径:https://112.126.61.225:9200/index_test/_analyze
请求参数:
{ "field": "realname", "text": "spj is good" } 返回值:
{ "tokens": [ { "token": "spj", "start_offset": 0, "end_offset": 3, "type": "<ALPHANUM>", "position": 0 }, { "token": "is", "start_offset": 4, "end_offset": 6, "type": "<ALPHANUM>", "position": 1 }, { "token": "good", "start_offset": 7, "end_offset": 11, "type": "<ALPHANUM>", "position": 2 } ] } 请求方式:POST
请求路径:https://112.126.61.225:9200/my_doc/_doc/2
请求参数:
{ "id": 1002, "name": "imooc-2", "desc": "china is fashion, !", "create_date": "2019-12-25" } 返回值:
{ "_index": "my_doc", "_type": "_doc", "_id": "2", "_version": 1, "result": "created", "_shards": { "total": 1, "successful": 1, "failed": 0 }, "_seq_no": 5, "_primary_term": 4 } 请求方式:DELETE
请求路径:https://112.126.61.225:9200/my_doc/_doc/2
请求参数:
{ "id": 1002, "name": "imooc-2", "desc": "china is fashion, !", "create_date": "2019-12-25" } 返回值:
{ "_index": "my_doc", "_type": "_doc", "_id": "2", "_version": 2, "result": "deleted", "_shards": { "total": 1, "successful": 1, "failed": 0 }, "_seq_no": 2, "_primary_term": 2 } 请求方式:POST
请求路径:https://112.126.61.225:9200/my_doc/_doc/1/_update
请求参数:
{ "doc": { "name": "奥" } } 返回值:
{ "_index": "my_doc", "_type": "_doc", "_id": "1", "_version": 2, "result": "updated", "_shards": { "total": 1, "successful": 1, "failed": 0 }, "_seq_no": 3, "_primary_term": 2 } 请求方式:PUT
请求路径:https://112.126.61.225:9200/my_doc/_doc/1
请求参数:
{ "id": 1001, "name": "test-1", "desc": "china is very good, 中国非常牛!", "create_date": "2020-05-08" } 返回值:
{ "_index": "my_doc", "_type": "_doc", "_id": "1", "_version": 4, "result": "updated", "_shards": { "total": 1, "successful": 1, "failed": 0 }, "_seq_no": 6, "_primary_term": 4 } 请求方式:GET
请求路径:https://112.126.61.225:9200/my_doc/_doc/_search
返回值:
{ "took": 2056, "timed_out": false, "_shards": { "total": 2, "successful": 2, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 2, "relation": "eq" }, "max_score": 1.0, "hits": [ { "_index": "my_doc", "_type": "_doc", "_id": "1", "_score": 1.0, "_source": { "id": 1001, "name": "test-1", "desc": "china is very good, 中国非常牛!", "create_date": "2020-05-08" } } ] } } 请求方式:GET
请求路径:https://112.126.61.225:9200/my_doc/_doc/1
返回值:
{ "_index": "my_doc", "_type": "_doc", "_id": "1", "_version": 4, "_seq_no": 6, "_primary_term": 4, "found": true, "_source": { "id": 1001, "name": "test-1", "desc": "china is very good, 中国非常牛!", "create_date": "2020-05-08" } } 请求方式:GET
请求路径:https://112.126.61.225:9200/my_doc/_doc/1?_source=id,name
返回值:
{ "_index": "my_doc", "_type": "_doc", "_id": "1", "_version": 4, "_seq_no": 6, "_primary_term": 4, "found": true, "_source": { "name": "test-1", "id": 1001 } } <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> <!--<version>2.1.5.RELEASE</version>--> <version>2.2.2.RELEASE</version> </dependency> Spring: data: elasticsearch: cluster-nodes: 192.168.10.182:9300 cluster-name: my-application ElasticsearchTemplate @Autowired private ElasticsearchTemplate esTemplate; package com.es.pojo; import org.springframework.data.annotation.Id; import org.springframework.data.elasticsearch.annotations.Document; import org.springframework.data.elasticsearch.annotations.Field; import org.springframework.data.elasticsearch.annotations.FieldType; @Document(indexName = "stu",type = "_doc") public class Stu { @Id private Long stuid; @Field(store = true) private String name; @Field() private Integer age; @Field(store = true) private Float money; @Field(store = true, type = FieldType.Keyword) private String sign; @Field(store = true) private String description; public Long getStuid() { return stuid; } public void setStuid(Long stuid) { this.stuid = stuid; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public Float getMoney() { return money; } public void setMoney(Float money) { this.money = money; } public String getSign() { return sign; } public void setSign(String sign) { this.sign = sign; } public String getDescription() { return description; } public void setDescription(String description) { this.description = description; } @Override public String toString() { return "Stu{" + "stuid=" + stuid + ", name='" + name + ''' + ", age=" + age + ", money=" + money + ", sign='" + sign + ''' + ", description='" + description + ''' + '}'; } } public void createIndexStu(){ Stu stu = new Stu(); stu.setStuid(1004L); stu.setName("toto"); stu.setAge(30); stu.setMoney(1999.8f); stu.setSign("I am very wuwu"); stu.setDescription("i am fine"); IndexQuery indexQuery = new IndexQueryBuilder().withObject(stu).build(); esTemplate.index(indexQuery); } public void deleteIndexStu(){ esTemplate.deleteIndex(Stu.class); } pojo对象还是用的上面的那个对象
public void updateStuDoc(){ Map map = new HashMap(); map.put("age",45); IndexRequest indexRequest =new IndexRequest(); indexRequest.source(map); UpdateQuery query = new UpdateQueryBuilder().withClass(Stu.class).withId("1001").withIndexRequest(indexRequest).build(); esTemplate.update(query); } public void getStuDec(){ GetQuery query = new GetQuery(); query.setId("1001"); Stu stu = esTemplate.queryForObject(query,Stu.class); System.out.println(stu); } public void deleteStuDec(){ esTemplate.delete(Stu.class,"1001"); } public void searchStuDoc(){ //分页参数 Pageable pageable = PageRequest.of(0,2); //查询语句 SearchQuery query = new NativeSearchQueryBuilder().withPageable(pageable).withQuery(QueryBuilders.matchQuery("sign","am")).build(); //查询 AggregatedPage<Stu> pageStu = esTemplate.queryForPage(query,Stu.class); //查询结果 List<Stu> stuList = pageStu.getContent(); System.out.println("总页数:"+pageStu.getTotalPages()); for(Stu s:stuList){ System.out.println(s); } } public void highlightStuDoc(){ String preTags = "<font color='red'>"; String postTags = "</font>"; //分页配置 Pageable pageable = PageRequest.of(0,2); //排序配置 SortBuilder sortBuilder = new FieldSortBuilder("money").order(SortOrder.ASC); List<Stu> stuListHighlight = new ArrayList<>(); SearchQuery query = new NativeSearchQueryBuilder() .withPageable(pageable)//分页 .withQuery(QueryBuilders.matchQuery("sign","am"))//查询 .withHighlightFields(new HighlightBuilder.Field("sign").preTags(preTags).postTags(postTags))//高亮 .withSort(sortBuilder)//排序 .build(); AggregatedPage<Stu> pageStu = esTemplate.queryForPage(query,Stu.class, new SearchResultMapper() { //重写返回结果 @Override public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> clazz, Pageable pageable) { SearchHits hits = response.getHits(); for(SearchHit h:hits){ HighlightField highlightField=h.getHighlightFields().get("sign"); String sign = highlightField.getFragments()[0].toString(); Object stuId = (Object)h.getSourceAsMap().get("stuid"); String name = (String)h.getSourceAsMap().get("name"); Integer age = (Integer)h.getSourceAsMap().get("age"); String description = (String)h.getSourceAsMap().get("description"); Object money = (Object)h.getSourceAsMap().get("money"); Stu stuHL = new Stu(); stuHL.setDescription(description); stuHL.setStuid(Long.valueOf(stuId.toString())); stuHL.setName(name); stuHL.setAge(age); stuHL.setSign(sign); stuHL.setMoney(Float.valueOf(money.toString())); stuListHighlight.add(stuHL); } return new AggregatedPageImpl<>((List<T>)stuListHighlight); } }); List<Stu> stuList = pageStu.getContent(); System.out.println("总页数:"+pageStu.getTotalPages()); for(Stu s:stuList){ System.out.println(s); } } Logstash是elastic技术栈中的一个技术。它是一个数据采集引擎,可以从数据库采集数据到es中。我们可以通过设置自增id主键或者时间来控制数据的自动同步,这个id或者时间就是用于给logstash进行识别的
tar -zxvf logstash-6.4.3.tar.gz/usr/local/(注:这步不是必须的,只是为了好管理)mkdir syncsync下面创建配置文件logstash-db-sync.confvim logstash-db-sync.confinput { jdbc { # 设置 MySql/MariaDB 数据库url以及数据库名称 jdbc_connection_string => "jdbc:mysql://192.168.1.6:3306/foodie-shop-dev?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true" # 用户名和密码 jdbc_user => "root" jdbc_password => "root" # 数据库驱动所在位置,可以是绝对路径或者相对路径 jdbc_driver_library => "/usr/local/logstash-6.4.3/sync/mysql-connector-java-5.1.41.jar" # 驱动类名 jdbc_driver_class => "com.mysql.jdbc.Driver" # 开启分页 jdbc_paging_enabled => "true" # 分页每页数量,可以自定义 jdbc_page_size => "10000" # 执行的sql文件路径 statement_filepath => "/usr/local/logstash-6.4.3/sync/foodie-items.sql" # 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务 schedule => "* * * * *" # 索引类型 type => "_doc" # 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件 use_column_value => true # 记录上一次追踪的结果值 last_run_metadata_path => "/usr/local/logstash-6.4.3/sync/track_time" # 如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间 tracking_column => "updated_time" # tracking_column 对应字段的类型 tracking_column_type => "timestamp" # 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录 clean_run => false # 数据库字段名称大写转小写 lowercase_column_names => false } } output { elasticsearch { # es地址 hosts => ["192.168.1.187:9200"] # 同步的索引名 index => "foodie-items" # 设置_docID和数据相同,这个id是sql语句要有的 document_id => "%{id}" } # 日志输出 stdout { codec => json_lines } } vim foodie-items.sql./logstash -f /usr/local/logstash-6.4.3/sync/logstash-db-sync.conf注:Logstash的版本要和es的版本一致
如果没有配置中文分词器,那么中文不会识别,这块有两种方式,一种就是手动创建索引,自己配置分词器,一种就是自定义模板配置中文分词。
GET /_template/logstash{ "logstash": { "order": 0, "version": 60001, "index_patterns": [ "logstash-*" ], "settings": { "index": { "refresh_interval": "5s" } }, "mappings": { "_default_": { "dynamic_templates": [ { "message_field": { "path_match": "message", "match_mapping_type": "string", "mapping": { "type": "text", "norms": false } } }, { "string_fields": { "match": "*", "match_mapping_type": "string", "mapping": { "type": "text", "norms": false, "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } ], "properties": { "@timestamp": { "type": "date" }, "@version": { "type": "keyword" }, "geoip": { "dynamic": true, "properties": { "ip": { "type": "ip" }, "location": { "type": "geo_point" }, "latitude": { "type": "half_float" }, "longitude": { "type": "half_float" } } } } } }, "aliases": {} } } "analyzer": "ik_max_word",{ "order": 0, "version": 1, "index_patterns": ["*"], "settings": { "index": { "refresh_interval": "5s" } }, "mappings": { "_default_": { "dynamic_templates": [ { "message_field": { "path_match": "message", "match_mapping_type": "string", "mapping": { "type": "text", "norms": false } } }, { "string_fields": { "match": "*", "match_mapping_type": "string", "mapping": { "type": "text", "norms": false, "analyzer": "ik_max_word", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } ], "properties": { "@timestamp": { "type": "date" }, "@version": { "type": "keyword" }, "geoip": { "dynamic": true, "properties": { "ip": { "type": "ip" }, "location": { "type": "geo_point" }, "latitude": { "type": "half_float" }, "longitude": { "type": "half_float" } } } } } }, "aliases": {} } vi /usr/local/logstash-6.4.3/sync/logstash-ik.json# 定义模板名称 template_name => "myik" # 模板所在位置 template => "/usr/local/logstash-6.4.3/sync/logstash-ik.json" # 重写模板 template_overwrite => true # 默认为true,false关闭logstash自动管理模板功能,如果自定义模板,则设置为false manage_template => false ./logstash -f /usr/local/logstash-6.4.3/sync/logstash-db-sync.conf
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 10万+
10万+