在业界有几种不同的流派(业界建立逻辑回归) 预测函数(线性回归模型上加了sigmoid函数): woe的计算公式: 具体可参考建模流程https://blog.csdn.net/weixin_41851055/article/details/106194063 输入数据必须是数值型数据、缺失值必须要填充、数据需要归一化或者标准化 优点: 缺点: 为什么用极大似然估计作为损失函数 训练过程中,有很多特征高的相关,会造成怎样的影响 为什么在训练过程中将高度相关的特征去掉 为什么我们选自然对数作为成本函数(符合上面性质函数很多) 注:
信贷评分卡
前言
1.逻辑回归原理
1.1 求解方式
对于二分类:
将其合并得到:
利用极大似然估计得到(MLE):
两边同时取log:
对于
求最优解即是求最大值(MLE),为了用梯度下降的算法对
取负数,即
最小值也就是
的最大值:
根据梯度下降的求解可得
的更新方式:
1.2 逻辑回归为什么用sigmoid并且转化后的输出即为1的概率

逻辑回归的假设是y服从伯努利分布(E(X)=p,D(X)=p(1-p)),可以得出概率函数:
在伯努利分布中E(Y)=p表示的就是1的概率2.逻辑回归到评分卡
2.1 woe及IV
IV的计算公式:
2.2 逻辑回归到评分卡
以上给的是概率,有时候还需要将概率以分数形式输出,类似于蚂蚁分。具体如下:
转换步骤:
1、设定
时的分数
2、设定
每增加一倍时,增加分数为
3、当
时的分数
,
分数为
2.3 评分卡的开发流程
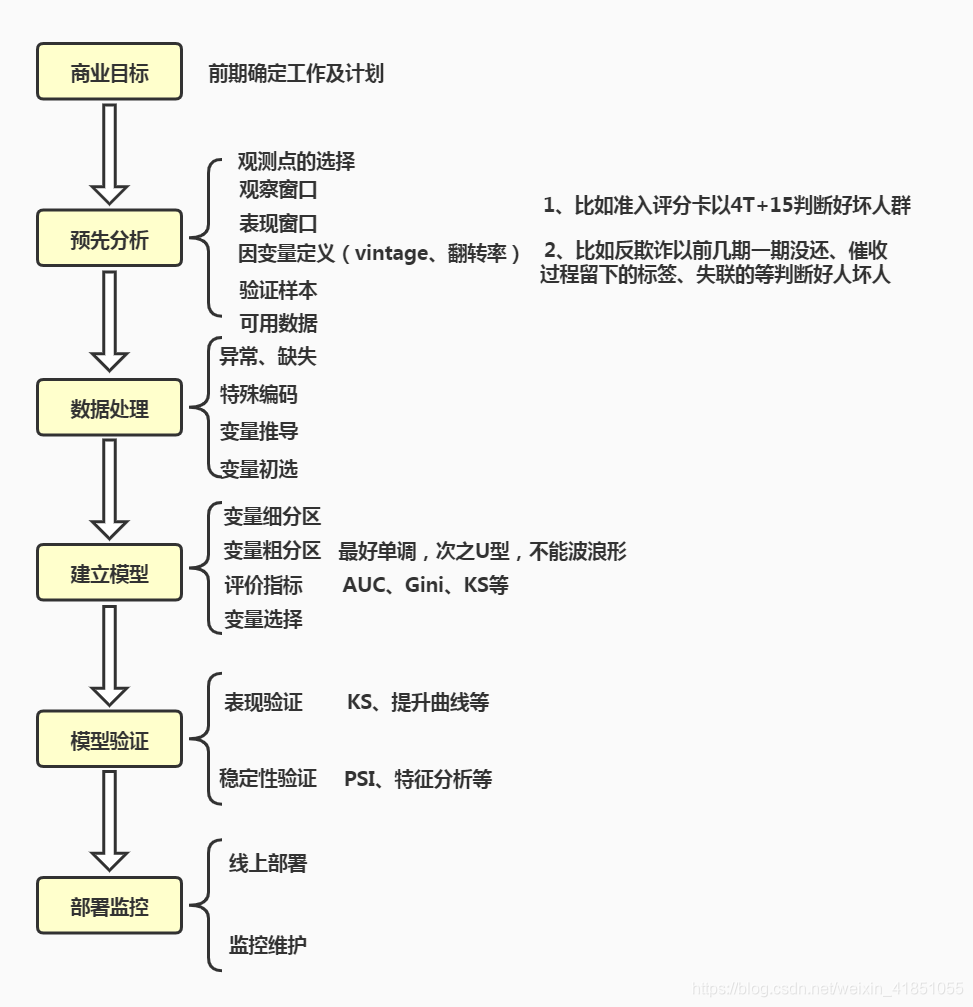
和评分之间具有线性关系
当PSI<0.2样本稳定3.逻辑回归对数据的要求(比较严格)
4.逻辑回归的优缺点
5.算法需要注意的点
更新速度只与
相关,与sigmoid梯度无关,如果用平方损失函数会推导出更新的速度和sigmoid函数本身很相关。sigmoid在它定义域内梯度都不大于0.25,这样训练会非常缓慢。
损失函数最终收敛的情况下,最后不会影响分类效果。但是对于可解释性会产生很大的影响。(一方面权重分给了不同的特征,另一方面可能正负相互抵消)
1、让模型的可解释性更好。2、大大提高训练速度。
因为预测函数有sigmoid,函数中含有
,其逆运算刚好是自然对数,最终会推导出形式优美模型参数的迭代函数,而不涉及指数或对数运算。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









