写在前面: 博主是一名软件工程系大数据应用开发专业大二的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白, 有一段时间没写关于爬虫的博客了,距离上一次自学爬虫已经过去了有一年的时间。想起刚写博客那会,没有什么粉丝,写关于大数据技术的博客受众面不是很广,所以基本上不怎么涨粉。每次涨粉都是因为那段时间的几篇关于爬虫入门的几个小Demo,像图片下载器,酷狗Top250,稍微难一点的像爬取拉勾网等等,至今历历在目… 我们首先根据网址 第二页的网址 第三页的网址 … 一直到最后一页的网址 我们可以写一个url的列表推导式 但这次咱用多线程的方式,先写好主程序入口,在main函数的调用中传递一个列表参数。 猫眼电影网站有反爬虫措施,我们可以通过设置headers,“伪装”成浏览器进行爬取 有了请求头和构造出来的url,我们就可以写个方法进行网页源码的捕捉。 有了源码,我们就可以对其进行解析。 通过观察源代码,发现用正则表达式可以轻易获取到我们想要的信息。 现在有了内容,我们就应该考虑存储的问题了。 为了方便查看,我们这里将其写入本地的txt文本。 提示: 以为到这里就完了,是不是还忘了点啥😜 对啊,我们还要下载每部电影对应的图片,但现在都已经获取到了每部电影的信息,下载图片那还不是轻轻松松。 我们拿到图片的url,进行request访问,然后将返回的内容写入到本地目录下就ok了 最后我们再完善一下我们的main函数。对上述所写的功能方法进行调用,并在本地创建文件夹covers用来存储结果数据。 然后就可以运行程序了,可以看到用了多线程之后,速度快了很多。 ok啦,看到类似上述的效果图,说明我们就成功啦~ 受益或对爬虫感兴趣的朋友记得点个赞支持一下~
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:https://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!

虽然不是python专业的学子,但凭着对爬虫莫名的热爱,让我逐渐找回了曾经的自己。
本篇博客博主为大家带来关于使用Python爬虫获取猫眼电影Top100的信息和…作为一名图片党,所必不可少的每部电影的封面图😎
详细操作
https://maoyan.com/board/4进入到猫眼的Top100榜单首页
通过观察其他页网址url的一个变化关系,我们可以尝试发现网址的变化规律https://maoyan.com/board/4?offset=10https://maoyan.com/board/4?offset=20https://maoyan.com/board/4?offset=90 urls = ['https://maoyan.com/board/4?offset={}'.format(i * 10) for i in range(10)] if __name__ == '__main__': # 对每一页信息进行爬取 pool = Pool() pool.map(main, [i * 10 for i in range(10)]) pool.close() pool.join() # 猫眼电影网站有反爬虫措施,设置headers后可以爬取 headers = { 'Content-Type': 'text/plain; charset=UTF-8', 'Origin': 'https://maoyan.com', 'Referer': 'https://maoyan.com/board/4', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } # 爬取网页源代码 def get_one_page(url, headers): try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text return None except RequestException: return None

于是可以用正则表达式进行信息的提取,将其返回的数据存放至一个字典里# 正则表达式提取信息 def parse_one_page(html): pattern = re.compile('<dd>.*?board-index.*?>(d+)</i>.*?data-src="(.*?)".*?name"><a' + '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S) items = re.findall(pattern, html) for item in items: yield { 'index': item[0], 'image': item[1], 'title': item[2], 'actor': item[3].strip()[3:], 'time': item[4].strip()[5:], 'score': item[5] + item[6] } # 猫眼TOP100所有信息写入文件 def write_to_file(content): # encoding ='utf-8',ensure_ascii =False,使写入文件的代码显示为中文 with open('result.txt', 'a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) + 'n') f.close()
这里使用dumps是将dict转化成str格式。另外json.dumps 序列化时对中文默认使用的ascii编码。因此想输出真正的中文需要指定ensure_ascii=False

# 下载电影封面 def save_image_file(url, path): jd = requests.get(url) if jd.status_code == 200: with open(path, 'wb') as f: f.write(jd.content) f.close() def main(offset): url = "https://maoyan.com/board/4?offset=" + str(offset) html = get_one_page(url, headers) if not os.path.exists('covers'): os.mkdir('covers') for item in parse_one_page(html): print(item) write_to_file(item) save_image_file(item['image'], 'covers/' + item['title'] + '.jpg')
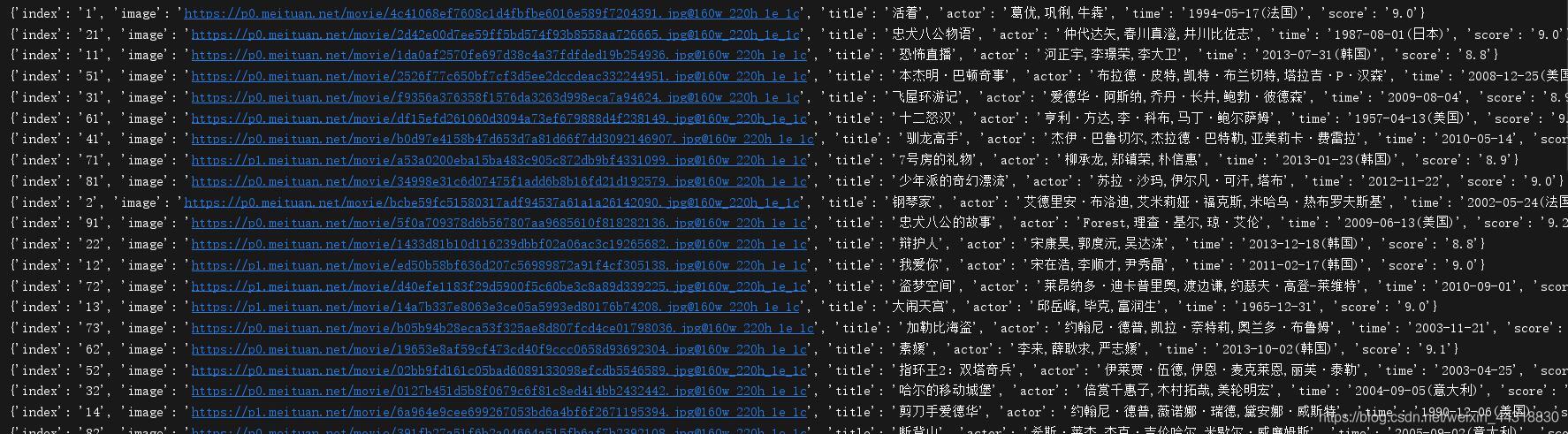
待到程序运行完毕,我们打开同级目录下生成的result.txt文件

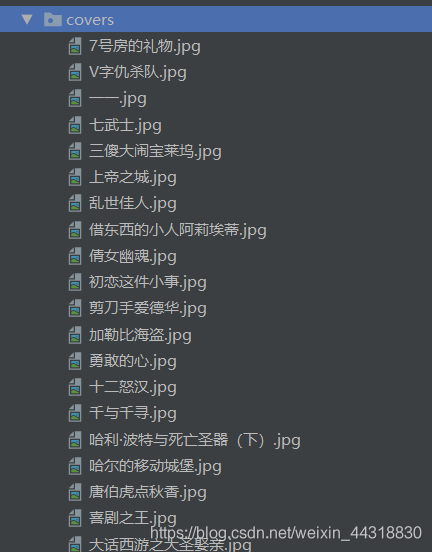
打开由程序创建的covers目录
我们任意点开一张图片,例如菌哥很喜欢的千与千寻

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









