入口页面地址 https://pvp.qq.com/web201605/herolist.shtml 第一步获取所有英雄的列表 可以看到英雄列表是在源码中可以被找到的 第二步 获取英雄的各种信息 英雄的基本信息放在一个class = “cover”的div中 我们主要采集 技能部分都在 创建工程 创建爬虫 修改配置 修改初始页面 创建爬取列表方法(测试) 运行爬虫 成功返回结果 爬取所有英雄链接方法 需要修改 ITEM_PIPELINES 配置 加入这个处理类 运行爬虫 结果 wzry_spider.py items.py pipelines.py
【scrapy框架】王者荣耀英雄信息爬取 python爬虫
分析


英雄的名称 和 技能介绍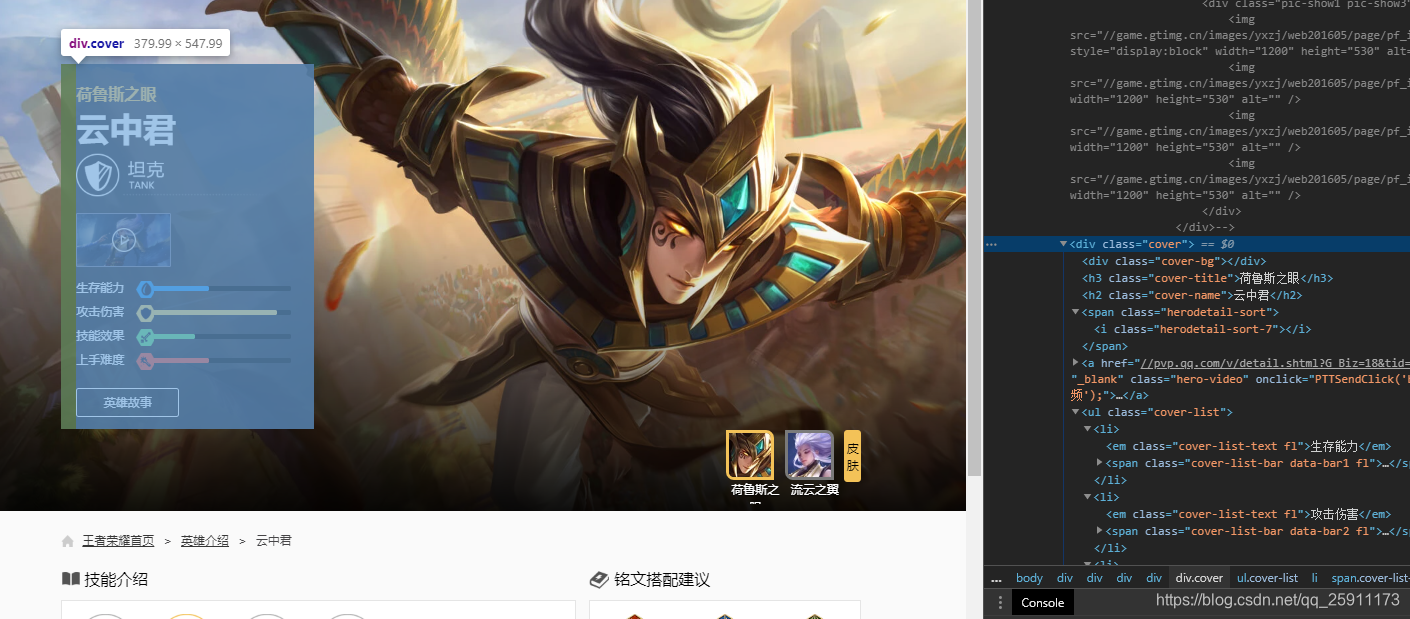
class=" zk-con3 zk-con" 中 中的 ul中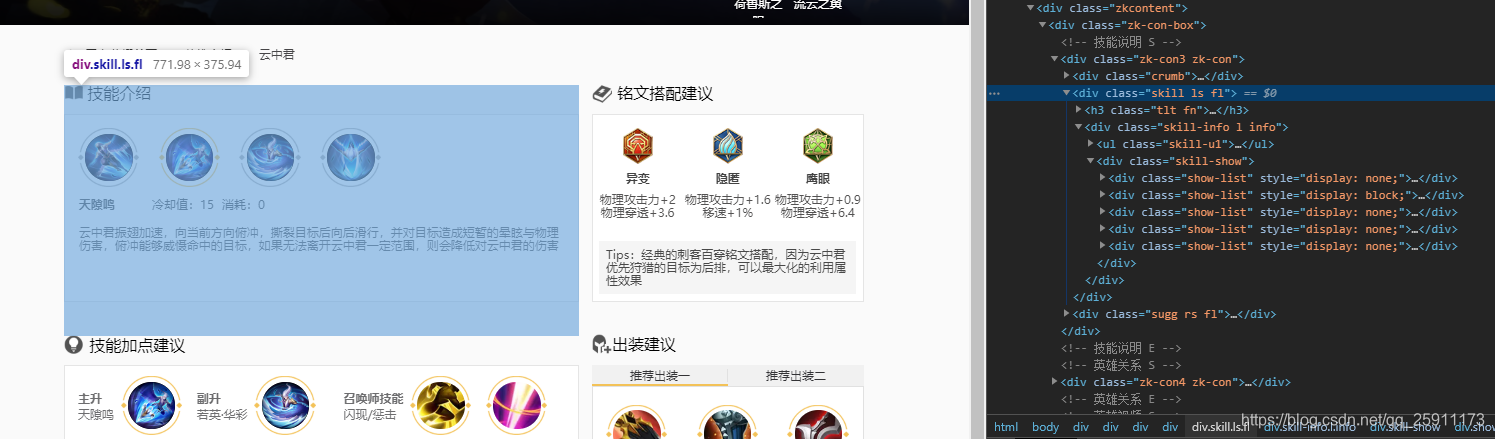
爬取英雄列表
scrapy startproject wzry cd wzry scrapy genspider wzry_spider pvp.qq.com # 不遵循robots协议 因为站点没有这个文件 爬虫会直接略过 ROBOTSTXT_OBEY = False # 添加请求头 DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } # 下载延迟 DOWNLOAD_DELAY = 1 start_urls = ['https://pvp.qq.com/web201605/herolist.shtml'] def parse(self, response): print("=" * 50) print(response) print("=" * 50) scrapy crawl wzry_spider 2020-05-25 11:08:53 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023 2020-05-25 11:08:54 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://pvp.qq.com/web201605/herolist.shtml> (referer: None) ================================================== <200 https://pvp.qq.com/web201605/herolist.shtml> ================================================== 2020-05-25 11:08:54 [scrapy.core.engine] INFO: Closing spider (finished) 2020-05-25 11:08:54 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 315, class WzrySpiderSpider(scrapy.Spider): name = 'wzry_spider' allowed_domains = ['pvp.qq.com'] start_urls = ['https://pvp.qq.com/web201605/herolist.shtml'] # 起始url base_url = "https://pvp.qq.com/web201605/" # url 前缀 def parse(self, response): print("=" * 50) # print(response.body) hero_list = response.xpath("//ul[@class='herolist clearfix']//li") for hero in hero_list: url = self.base_url + hero.xpath("./a/@href").get() print(url) # yield scrapy.Request(url) print("=" * 50) https://pvp.qq.com/web201605/herodetail/114.shtml https://pvp.qq.com/web201605/herodetail/113.shtml https://pvp.qq.com/web201605/herodetail/112.shtml https://pvp.qq.com/web201605/herodetail/111.shtml https://pvp.qq.com/web201605/herodetail/110.shtml https://pvp.qq.com/web201605/herodetail/109.shtml https://pvp.qq.com/web201605/herodetail/108.shtml https://pvp.qq.com/web201605/herodetail/107.shtml https://pvp.qq.com/web201605/herodetail/106.shtml https://pvp.qq.com/web201605/herodetail/105.shtml ================================================== 爬取英雄详情页面
# 基本信息块 hero_info = response.xpath("//div[@class='cover']") hero_name = hero_info.xpath(".//h2[@class='cover-name']/text()").get() print(hero_name) # 分类 sort_num = hero_info.xpath(".//span[@class='herodetail-sort']/i/@class").get()[-1:] print(sort_num) # 生存能力 viability = hero_info.xpath(".//ul/li[1]/span/i/@style").get()[6:] print("生存能力:" + viability) # 伤害 aggressivity = hero_info.xpath(".//ul/li[2]/span/i/@style").get()[6:] print("攻击能力:" + aggressivity) effect = hero_info.xpath(".//ul/li[3]/span/i/@style").get()[6:] print("技能影响" + effect) difficulty = hero_info.xpath(".//ul/li[4]/span/i/@style").get()[6:] print("上手难度:" + difficulty)
skill_list = response.xpath("//div[@class='skill-show']/div[@class='show-list']") for skill in skill_list: skill_name = skill.xpath("./p[@class='skill-name']/b/text()").get() if not skill_name: continue # 冷却时间 cooling = skill.xpath("./p[@class='skill-name']/span[1]/text()").get().split(":")[1].strip().split('/') # 消耗 consume = skill.xpath("./p[@class='skill-name']/span[1]/text()").get().split(":")[1].strip().split('/') # "".strip() # 如果这个技能是空的就 continue # 技能介绍 skill_desc = skill.xpath("./p[@class='skill-desc']/text()").get() new_skill = { "name": skill_name, "cooling": cooling, "consume": consume, "desc": skill_desc } new_hero = HeroInfo(name=hero_name, sort_num=sort_num, viability=viability, aggressivity=aggressivity, effect=effect, difficulty=difficulty, skills_list=new_skill) yield new_hero
class HeroInfo(scrapy.Item): # 存字符串 name = scrapy.Field() sort_num = scrapy.Field() viability = scrapy.Field() aggressivity = scrapy.Field() effect = scrapy.Field() difficulty = scrapy.Field() # 存字典 skills_list = scrapy.Field()
# -*- coding: utf-8 -*- from scrapy.exporters import JsonItemExporter class WzryPipeline: def __init__(self): # 打开文件并实例化JsonItemExporter self.fp = open('result.json', 'wb') self.save_json = JsonItemExporter(self.fp, encoding="utf-8", ensure_ascii=False, indent=4) # 开始写入 self.save_json.start_exporting() def open_spider(self, spider): pass def close_spider(self, spider): # 结束写入 self.save_json.finish_exporting() # 关闭文件 self.fp.close() def process_item(self, item, spider): # 写入item self.save_json.export_item(item) return item scrapy crawl wzry_spider 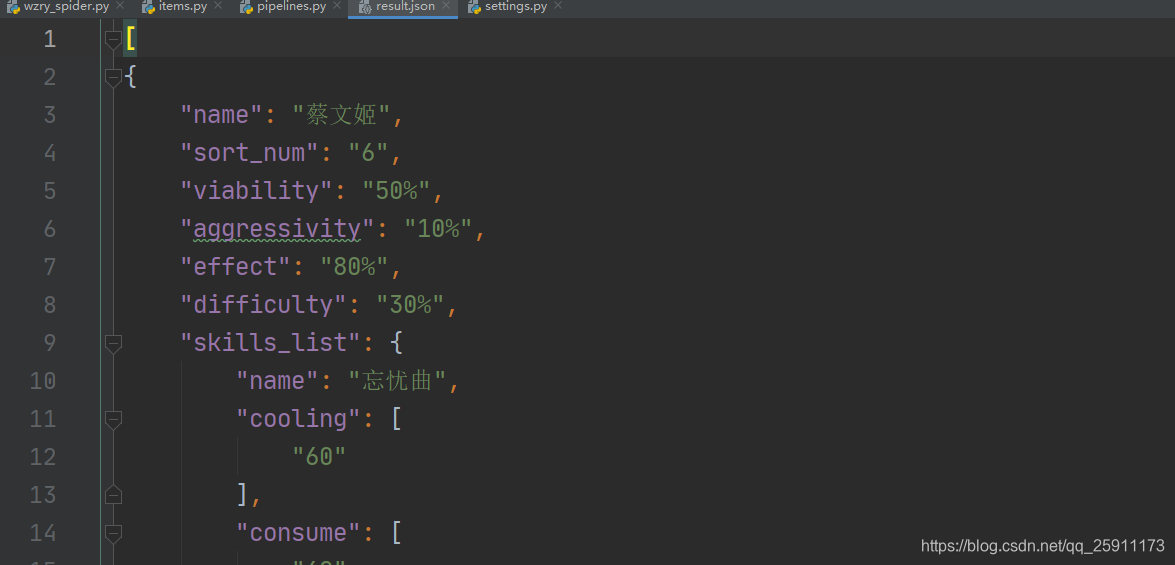
全部代码
# -*- coding: utf-8 -*- import scrapy from wzry.items import HeroInfo class WzrySpiderSpider(scrapy.Spider): name = 'wzry_spider' allowed_domains = ['pvp.qq.com'] start_urls = ['https://pvp.qq.com/web201605/herolist.shtml'] # 起始url base_url = "https://pvp.qq.com/web201605/" # url 前缀 def parse(self, response): # print(response.body) hero_list = response.xpath("//ul[@class='herolist clearfix']//li") for hero in hero_list: url = self.base_url + hero.xpath("./a/@href").get() yield scrapy.Request(url, callback=self.get_hero_info) def get_hero_info(self, response): # 基本信息块 global new_skill hero_info = response.xpath("//div[@class='cover']") hero_name = hero_info.xpath(".//h2[@class='cover-name']/text()").get() # 分类 sort_num = hero_info.xpath(".//span[@class='herodetail-sort']/i/@class").get()[-1:] # 生存能力 viability = hero_info.xpath(".//ul/li[1]/span/i/@style").get()[6:] # 伤害 aggressivity = hero_info.xpath(".//ul/li[2]/span/i/@style").get()[6:] effect = hero_info.xpath(".//ul/li[3]/span/i/@style").get()[6:] difficulty = hero_info.xpath(".//ul/li[4]/span/i/@style").get()[6:] # 技能列表 skill_list = response.xpath("//div[@class='skill-show']/div[@class='show-list']") for skill in skill_list: skill_name = skill.xpath("./p[@class='skill-name']/b/text()").get() if not skill_name: continue # 冷却时间 cooling = skill.xpath("./p[@class='skill-name']/span[1]/text()").get().split(":" "")[1].strip().split('/') # 消耗 consume = skill.xpath("./p[@class='skill-name']/span[1]/text()").get().split(":" "")[1].strip().split('/') # "".strip() # 如果这个技能是空的就 continue # 技能介绍 skill_desc = skill.xpath("./p[@class='skill-desc']/text()").get() new_skill = { "name": skill_name, "cooling": cooling, "consume": consume, "desc": skill_desc } new_hero = HeroInfo(name=hero_name, sort_num=sort_num, viability=viability, aggressivity=aggressivity, effect=effect, difficulty=difficulty, skills_list=new_skill) yield new_hero # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class WzryItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass class HeroInfo(scrapy.Item): # 存字符串 name = scrapy.Field() sort_num = scrapy.Field() viability = scrapy.Field() aggressivity = scrapy.Field() effect = scrapy.Field() difficulty = scrapy.Field() # 存字典 skills_list = scrapy.Field() # -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html from scrapy.exporters import JsonItemExporter class WzryPipeline: def __init__(self): self.fp = open('result.json', 'wb') self.save_json = JsonItemExporter(self.fp, encoding="utf-8", ensure_ascii=False, indent=4) self.save_json.start_exporting() def open_spider(self, spider): pass def close_spider(self, spider): self.save_json.finish_exporting() self.fp.close() def process_item(self, item, spider): self.save_json.export_item(item) return item
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









