前一阵闲的冒泡开了个淘宝店,因为改价格等各种原因麻烦的不得了,这不就心思爬个虫懒得一页页翻了么! 话不多说直接教程(以下教程没开店的人员可能看不懂): 开源库文档地址: 源代码(修改 search_url 的网址为自己的店铺):
淘宝卖家必备程序
如果你没开过淘宝店或者非得自己亲眼看网页价格,那么这篇咱们就没啥缘分了,我们以后随缘再见~
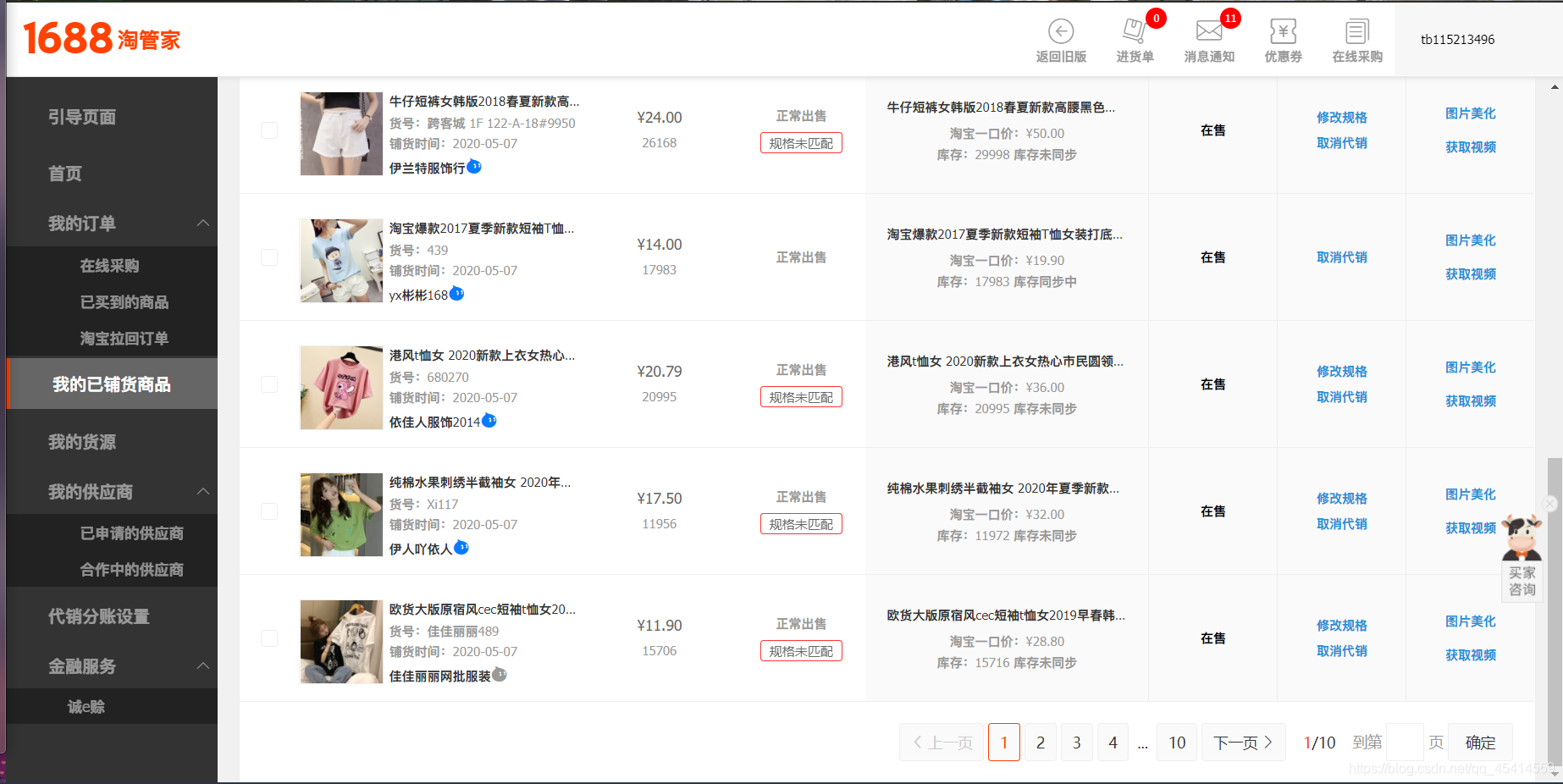
首先介绍一下这是我的店铺,我们能发现这里存在买价和卖价,并且还需要翻页才能查看到你所有的店铺信息。在这里我首先想拿到的就是衣服名字、买价、卖价以及这部分的差价。均提取出来保存到 csv 文件中。
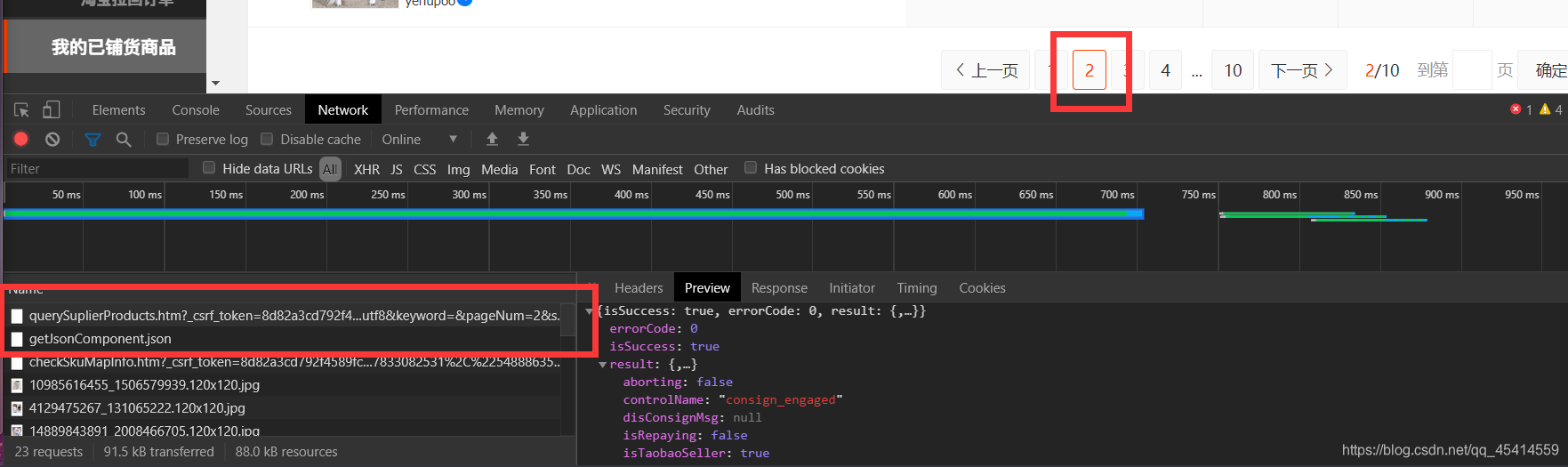
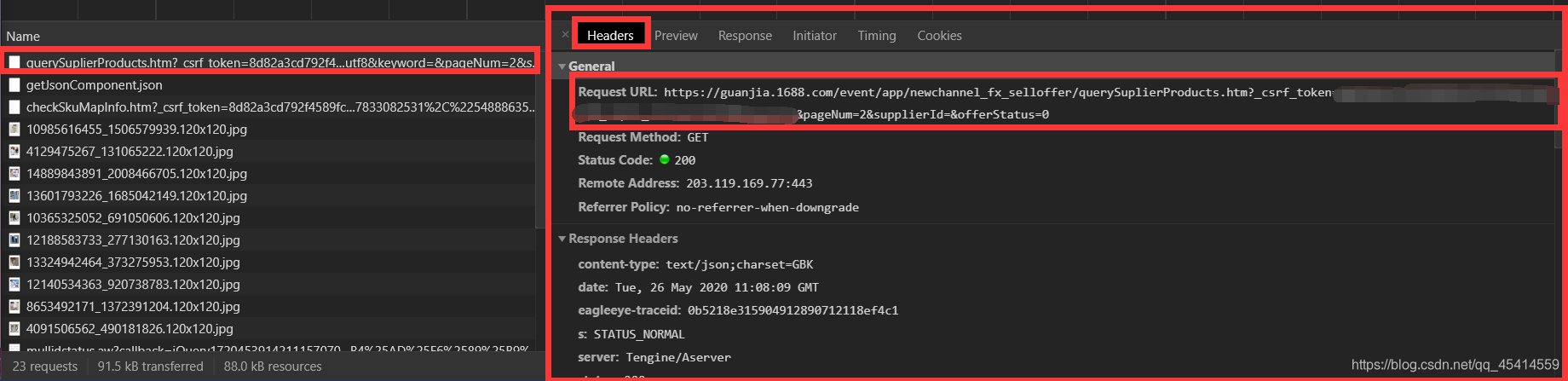
传说有一个大佬他叫皮卡丘,曾经开源了第三方库名为 DecryptLogin ,这个库能帮我们做到很多很多登陆的问题,有大佬不用愁!再次感谢大佬开源
https://httpsgithubcomcharlespikachudecryptlogin.readthedocs.io/zh/latest/

import os,pickle,csv,sys from tkinter import messagebox from lxml import etree from DecryptLogin import login class TBCrawler(): def __init__(self, **kwargs): self.clothes = {} if os.path.isfile('session.pkl'): self.session = pickle.load(open('session.pkl', 'rb')) else: self.session = TBCrawler.login() f = open('session.pkl', 'wb') pickle.dump(self.session, f) f.close() self.run("1") self.save() def run(self,page): # 把这里改成自己的信息,如果xxx之外的地方出现较大问题,则可能就是获取错了 # 改xxxxx位置就好了,其他不要动。 search_url = "https://guanjia.1688.com/event/app/newchannel_fx_selloffer/querySuplierProducts.htm?_csrf_token=Xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxd&_input_charset=utf8&keyword=&pageNum={}&supplierId=&offerStatus=0".format(page) response = self.session.get(search_url) # 因为读取pkl登陆信息cookie容易过期,则需要判断一些这里应不应该结束程序 try:result = response.json()["result"] except: messagebox.showinfo("warning","登陆过期,请删除pkl信息重新运行") sys.exit(0) pageList = result["pageList"] for dicts in pageList: name,bug,sell = dicts["itemTitle"],dicts["maxPurchasePrice"],dicts["maxTbSellPrice"] interest = float(sell) - float(bug) self.clothes[name] = [bug,sell,interest] # 在这里输出一下信息, 别因为页数多爬取好久一点信息没有都不知道爬到哪了。 print(self.clothes) all_page = int(result["pageCount"]) if int(page) < all_page: self.run(int(page)+1) def save(self): with open("clothes.csv", 'w', newline='', encoding='utf_8_sig') as f: csv_writer = csv.writer(f) csv_writer.writerow(["衣服名","买价","卖价","利益"]) for key in self.clothes.keys(): value = self.clothes[key] csv_writer.writerow([key,value[0],value[1],value[2]]) @staticmethod def login(): lg = login.Login() _, session = lg.taobao() return session if __name__ == '__main__': crawler = TBCrawler()
最后还是希望你们能给我点一波小小的关注。
奉上自己诚挚的爱心💖
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









