语义分割对图像进行分割是基于像素点对其进行分类的,所以我今天要说的分割,用的除了公共数据集之外,我是按照cityscapes数据集的格式进行数据集的制作用于训练。所以,要制作cityscapes格式数据集的话,务必对cityscapes公共数据集进行了解,并且熟知用于训练的图像数据格式,主要强调的是原图像对应的灰度图,这个也是制作数据集的关键。 标注类别读取结果如下: 首先,标注用的是labele工具,具体可参考:https://github.com/wkentaro/labelme 简单标注如下图所示,左边是标注的边缘框架,右边是命名的类别,标注自己想要的类别进行保存即可。 json文件进行转换的时候,可以直接在cmd用单个命令直接转,也可以自己写个批量转换的脚本,这个网上也一大堆,在此不做重复。下面这个代码里面对labelme所在文件位置的json_to_dataset.py进行了改进,对标注的类进行了初始化。(记得在代码所在目录建一个文件夹,我的命名是before) 转换后的_json文件夹输出到output文件夹,其中包含五个文件,如下: 这里是最关键也是最重要的一环,我们需要将图像里面标注的类别进行一个局部到全局的映射.因为cityscapes数据集是为35类,其中用于训练的是19类,其他不参与训练的类别标签将其忽略掉即可(ignore=255)。我自己的类为13+1(background),在before文件夹中新建一个class_name用于存放我们的类,代码如下:(get_png.py) 需要解释的是为了区分用于训练的图,我将原图置为a.jpg格式,mask图为a.png ,然后在before文件夹里传入对应的json文件(上一步已传)和.jpg图像 对应好后,在转训练的png的时候,按照制作好的标签顺序,进行mask的png的制作,运行代码get_png.py,输出图保存到png文件夹中。 得到的图是24bit的图,需要将其转换为8bit的灰度图用于训练,转换代码如下:(get_gray.py) 最后,为了证实我们的制作结果,进行类别的验证,还是用最开始的简单方式进行测试,结果如下: 以上训练的灰度图就算是制作成功了,然后制作好参与训练需要的文本列表(train.lst,val.lst,testval.lst,test.lst)。制作图像数据集需要大把时间,战线较长,需要耐心。然后hrnet网络相关的内容网上很多,就不多做介绍了,可以直接github找star最多的跑就可以了,暂时就先写这些,以上内容,仅供大家参考 [1]https://www.bilibili.com/video/BV1qJ411S7Pn?p=10
自制多分类cityscapes格式数据集用于HRNet网络进行语义分割
!说在前面(原创小文,如有需要请标明转载出处)
1. 查看cityscapes格式
import numpy as np from PIL import Image img = Image.open(‘***.png’) #图像所在位置 img = np.array(img) np.unique(img)

2. 数据集制作
2.1 数据集的标注
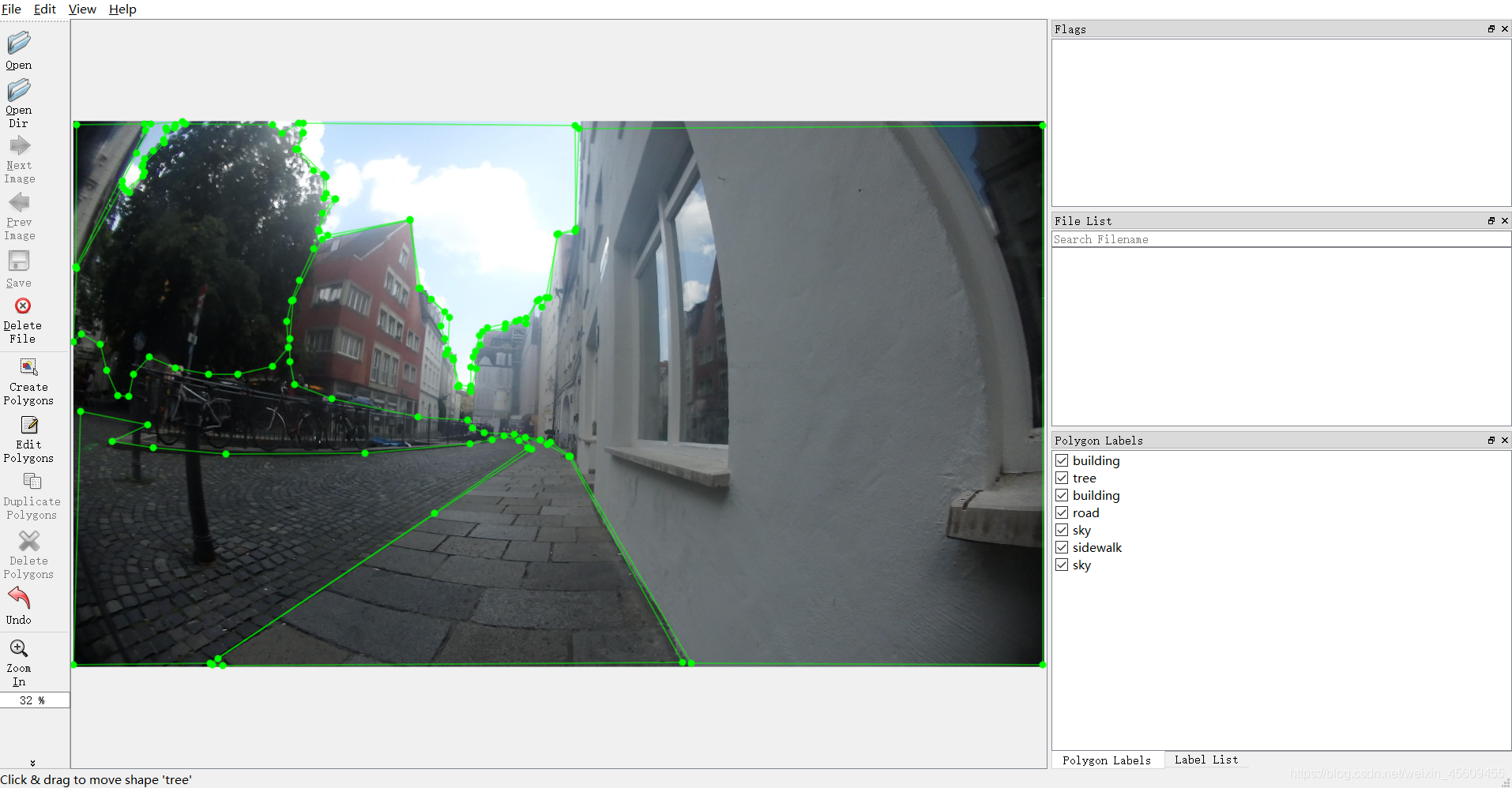
2.2 json文件的转换
import argparse import json import os import os.path as osp import warnings import PIL.Image import yaml from labelme import utils import base64 def main(): count = os.listdir("./before/") for i in range(0, len(count)): path = os.path.join("./before", count[i]) if os.path.isfile(path) and path.endswith('json'): data = json.load(open(path)) if data['imageData']: imageData = data['imageData'] else: imagePath = os.path.join(os.path.dirname(path), data['imagePath']) with open(imagePath, 'rb') as f: imageData = f.read() imageData = base64.b64encode(imageData).decode('utf-8') img = utils.img_b64_to_arr(imageData) label_name_to_value = {'_background_': 0} for shape in data['shapes']: label_name = shape['label'] if label_name in label_name_to_value: label_value = label_name_to_value[label_name] else: label_value = len(label_name_to_value) label_name_to_value[label_name] = label_value # label_values must be dense label_values, label_names = [], [] for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]): label_values.append(lv) label_names.append(ln) assert label_values == list(range(len(label_values))) lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value) captions = ['{}: {}'.format(lv, ln) for ln, lv in label_name_to_value.items()] lbl_viz = utils.draw_label(lbl, img, captions) out_dir = osp.basename(count[i]).replace('.', '_') out_dir = osp.join(osp.dirname(count[i]), out_dir) out_dir = osp.join("output", out_dir) if not osp.exists(out_dir): os.mkdir(out_dir) PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png')) utils.lblsave(osp.join(out_dir, 'label.png'), lbl) PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png')) with open(osp.join(out_dir, 'label_names.txt'), 'w') as f: for lbl_name in label_names: f.write(lbl_name + 'n') warnings.warn('info.yaml is being replaced by label_names.txt') info = dict(label_names=label_names) with open(osp.join(out_dir, 'info.yaml'), 'w') as f: yaml.safe_dump(info, f, default_flow_style=False) print('Saved to: %s' % out_dir) if __name__ == '__main__': main()
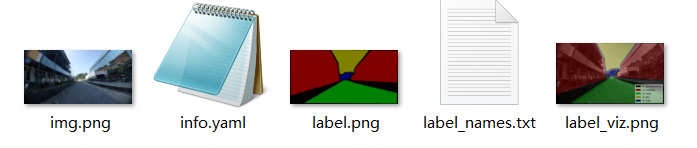
这里需要解释的是,我们后期用于训练的是原图(img.png)和标签图(label.png),其中,label.png是8bit图,但并不能直接用于训练,还得继续作转换,要将其转为8bit的灰度图(下一步为具体实现)2.3 从转换后的_json文件夹中获取mask图
import os from PIL import Image import numpy as np def main(): # 读取原文件夹 count = os.listdir("./before/") for i in range(0, len(count)): # 如果里的文件以jpg结尾 # 则寻找它对应的png if count[i].endswith("jpg"): path = os.path.join("./before", count[i]) img = Image.open(path) img.save(os.path.join("./jpg", count[i])) # 找到对应的png path = "./output/" + count[i].split(".")[0] + "_json/label.png" img = Image.open(path) # 找到全局的类 class_txt = open("./before/class_name", "r") class_name = class_txt.read().splitlines() # ["_background_","a","b"] # 打开json文件里面存在的类,称其为局部类 with open("./output/" + count[i].split(".")[0] + "_json/label_names.txt", "r") as f: names = f.read().splitlines() # ["_background_","b"] new = Image.new("RGB", [np.shape(img)[1], np.shape(img)[0]]) # print('new:',new) for name in names: index_json = names.index(name) index_all = class_name.index(name) # 将局部类转换成为全局类 new = new + np.expand_dims(index_all * (np.array(img) == index_json), -1) new = Image.fromarray(np.uint8(new)) print('new:',new) new.save(os.path.join("./png", count[i].replace("jpg", "png"))) print(np.max(new), np.min(new)) if __name__ == '__main__': main()
这里我们需要将cityscapes数据集的标签和我们自己的标签进行类比做出来,这里我们直接上图来说明,下面两幅图中,上面的image_4.png 是cityscapes数据集类的对应标签的列表,下面的image_5.png是自己类的标签列表
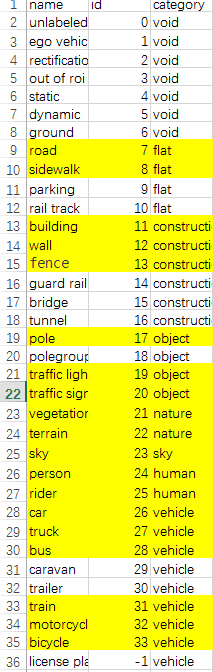
图image_4.png

图image_5.png
这里补充一下大家很多都踩得坑,那就是如下这幅图中涉及的内容:实际参与训练的是trainid,并非id
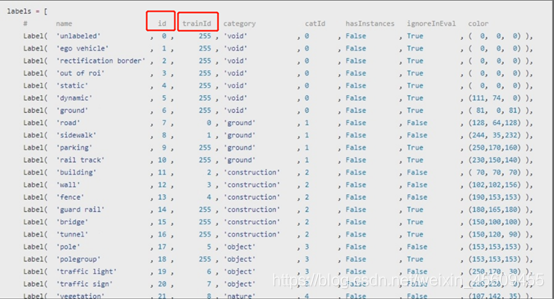
2.4 转灰度图
import cv2 import os input_dir = './png' #上一步保存.png图像文件夹 out_dir = 'F:/regular walks/2048X1024_2' a = os.listdir(input_dir) for i in a: img = cv2.imread(input_dir+'/'+i) gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) cv2.imencode('.png', gray)[1].tofile(out_dir+'/'+i) 2.5 查证灰度图的类别标签
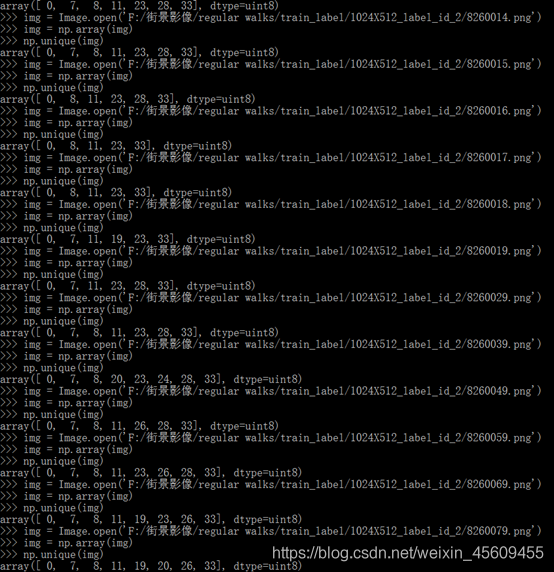
3.总结
参考
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









