如果将龙格库塔迭代的曲线拟合与深度学习中的RNN循环神经网络的曲线拟合做一个对比,会出现什么意想不到的效果?答案当然是小批量和边界条件足够充分的情况下,龙格库塔迭代效果更好,可以说杀鸡焉用牛刀?但是,在某些特殊情况下,比如我们很难对函数求导或者函数的导数值不存在的时候,我们该如何对原方程进行拟合呢?或者说在我们不知道某些特殊求解算法这时候,比如我们不了解龙格库塔算法,我们该如何让计算机自己去拟合我们的目标曲线呢?这个时候,深度学习就派上用场了。本文将针对两种不同的算法,以正弦函数为例,给出代码,在求解过程中感受并对比两种方法的不同之处。 首先介绍一下龙格库塔迭代法(Runge-Kutta method): y′=f(x,y),y(x0)=y0 则方程的迭代计算公式如下: y(x+Δx)=y(x)+16×(k1+2×k2+2×k3+k4)+O(Δx4) k1=f(y,x)×Δx k2=f(y+0.5×k1,x+0.5×Δx)×Δx k3=f(y+0.5×k2,x+0.5×Δx)×Δx k4=f(y+k3,x+Δx)×Δx 其中: k2是时间段中点的斜率; k3同k2一样是时间段中点的斜率; k4是时间段终点的斜率,其y值用k3决定。 当四个斜率取平均时,中点的斜率有更大的权值: 终点斜率为:(k1+2×k2+2×k3+k4)/6 本次用例为正弦函数sin(x) 四阶龙格库塔迭代函数: 给出初始x和y的值,因为sin过原点,以原点为初始值,y_ls和x_ls分别存储每次计算后的y的返回值和x. 定义导函数: 循环,记录每次迭代后的结果和真值结果: 误差计算: 最后出图: 总的代码如下: 最后的打印结果为:max_error:0.00228,已经取了迭代过程中最大的误差,可见误差非常小,另外从曲线图中可以看出拟合过程中误差曲线基本为一条直线,整个过程龙格库塔迭代将误差控制得非常好,而且算法复杂度较小。 然后介绍RNN循环神经网络算法: 为了计算方便,首先定义超参数: 然后搭建一个RNN循环神经网络: 优化器和误差函数的选取: 初始化记忆包: 构造函数并将数据代入神经网络训练,我们用cos函数为初始函数,将其训练成sin 函数,训练100次,计算每次训练后的值prediction和真值y的误差: 最后出图 总的代码如下: 动态图效果 谢谢,欢迎交流! 参考:莫烦大佬的机器学习教程:https://morvanzhou.github.io/
一、龙格库塔迭代是数值分析中接触过的也是用途十分广泛的高精度单步算法,是求解非线性常微分方程的利器,也是数值仿真中常用的算法,其计算误差可以小到10^-5以下。
我们常用的是四阶龙格库塔法,已知导数和初始值:
k1是时间段开始时的斜率;
根据四阶龙格库塔迭代方程,依次写出4个斜率计算公式,返回迭代结果,需要四个变量,自变量x,因变量y的值,导函数f,自变量每次的递增值也就是步长为dx.def runge_kutta(x,y,f,dx):#4阶龙格库塔迭代式 k1 = f(y,x)*dx k2 = f(y+0.5*k1,x+0.5*dx)*dx k3 = f(y+0.5*k2,x+0.5*dx)*dx k4 = f(y+k3,x+dx)*dx return y +(k1+2*k2+2*k3+k4)/6 x = 0#初始化x = 0 y = 0#初始化y = sin(x) = sin(0) = 0 dx = np.pi*0.5#步长定义为pi/2 y_ls = [] x_ls = [] def func(y,x):定义求导函数,sin函数导数为cos... return math.cos(x) while x<=50*np.pi:#迭代100步 y = runge_kutta(x,y,func,dx) y_ls.append(y) x += dx x_ls.append(x) true = [math.sin(x) for x in x_ls] error = np.array(y_ls) - np.array(true) plt.plot(x_ls,y_ls,label = 'runge_kutta')#可视化迭代值 plt.plot(x_ls,true,label = 'true')#可视化真实值 plt.plot(x_ls,error,label = 'error')#可视化误差 print('max_error:{:.5f}'.format(max(error))) plt.legend() plt.show() """ Created on Tue May 25 23:20:24 2020 @author: ScramJet """ import math import matplotlib.pyplot as plt import numpy as np def runge_kutta(x,y,f,dx):#4阶龙格库塔迭代式 k1 = f(y,x)*dx k2 = f(y+0.5*k1,x+0.5*dx)*dx k3 = f(y+0.5*k2,x+0.5*dx)*dx k4 = f(y+k3,x+dx)*dx return y +(k1+2*k2+2*k3+k4)/6 x = 0#初始化x = 0 y = 0#初始化y = sin(x) = sin(0) = 0 dx = np.pi*0.5#步长定义为pi/2 y_ls = [] x_ls = [] def func(y,x):定义求导函数,sin函数导数为cos... return math.cos(x) while x<=50*np.pi:#迭代100步 y = runge_kutta(x,y,func,dx) y_ls.append(y) x += dx x_ls.append(x) true = [math.sin(x) for x in x_ls] error = np.array(y_ls) - np.array(true)#求出迭代值与真实值的差,即误差 #可视化 plt.plot(x_ls,y_ls,label = 'runge_kutta')#可视化迭代值 plt.plot(x_ls,true,label = 'true')#可视化真实值 plt.plot(x_ls,error,label = 'error')#可视化误差 print('max_error:{:.5f}'.format(max(error))) plt.legend() plt.show() 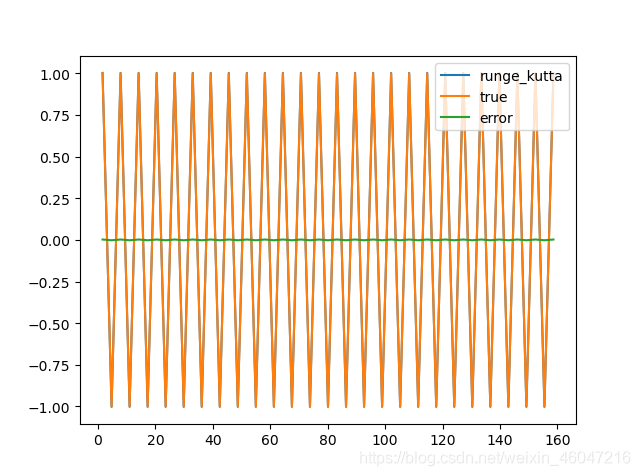
二、基于pytorch搭建一个RNN循环神经网络,RNN相对于CNN多了一个存储的记忆块(hidden state),它可以把每次学习的内容打包放在一起,作为下一次学习的依据。它包含一个输入层,一个隐藏层,一个输出层。由于我的计算机硬件限制,没有使用GPU加速,另外考虑到与龙格库塔迭代进行对比,所以依然采用sin进行拟合,计算量很小,不需要GPU加速,本次采用CPU计算。
下面逐步给出代码:INPUT_SIZE = 1#初始参数尺寸,也就是输入层尺寸,或者说输入层数据量 TIME_STEP = 10#时间步长 LR = 0.02#学习效率 #搭建RNN神经网络 class RNN(torch.nn.Module): def __init__(self):#定义初始函数 super(RNN,self).__init__()#将类和初始函数联系在一起 self.rnn = torch.nn.RNN( #此处直接使用RNN不使用LSTM就可以达到很好的效果,注意RNN参数定义和LSTM一致 input_size = INPUT_SIZE, #输入层数据量 hidden_size = 32,#注意TIME_STEP并不是RNN中的参数,TIME_STEP是后续数据处理时使用的 num_layers = 1,#注意是num_layers为隐藏层数量 batch_first = True, #此时x为(batch_size,time_step,input_size)三个维度的参数,batch_size优先,位于第一位 ) self.output = torch.nn.Linear(32,1)#作为输出层,接受隐藏层的32个数据,并整合为1个数据 def forward(self,x,h_state): r_out,h_state = self.rnn(x,h_state)#RNN返回的值包含x本身的值(batch_size,time_step,input_size),和每次叠加的学习内容h_state,也就是hidden state,学习记忆包。。。 outs = []#把每个时间步长计算得到的r_out都收集起来 for time_step in range(r_out.size(1)):#r_out.size(1)是返回的x中时间步长的个数 outs.append(self.output(r_out[:,time_step,:]))#将r_out中每个时间步长对应的值加入列表outs中 return torch.stack(outs,dim=1),h_state#将列表打包成张量返回,并且返回h_state rnn = RNN()
我们使用Adam函数,误差函数采用常用的 MSELoss:optimizer = torch.optim.Adam(rnn.parameters(),lr = LR) loss_func =torch.nn.MSELoss()#定义误差函数 h_state = None for step in range(100): start,end = step*np.pi,(step+1)*np.pi steps = np.linspace(start,end,TIME_STEP, dtype=np.float32, endpoint=False) x_np = np.sin(steps) y_np = np.cos(steps) x = torch.from_numpy(x_np[np.newaxis,:,np.newaxis])#将x_np从一维数据变为(batch_size,time_step,input_size)三维形式 y = torch.from_numpy(y_np[np.newaxis,:,np.newaxis])#将y_np从一维数据变为(batch_size,time_step,input_size)三维形式 prediction,h_state = rnn(x,h_state)#初始h_state设置为None h_state = h_state.data loss = loss_func(prediction,y) optimizer.zero_grad() loss.backward() optimizer.step() accuracy = prediction - y#误差 plt.plot(steps,y_np.flatten(),label = 'true')#被学习数据 plt.plot(steps,prediction.data.numpy().flatten(),label = 'prediction')#学习后的数据 plt.plot(steps,accuracy.data.numpy().flatten(),label = 'error')#误差 plt.draw() plt.pause(0.05) """ Created on Tue May 26 00:20:24 2020 @author: ScramJet """ import torch import torch.nn.functional from torch.autograd import Variable import torch.utils.data as Data import numpy as np import matplotlib.pyplot as plt #定义超参数 INPUT_SIZE = 1#初始参数尺寸 TIME_STEP = 10#时间步长 LR = 0.02#学习效率 #搭建RNN神经网络 class RNN(torch.nn.Module): def __init__(self): super(RNN,self).__init__() self.rnn = torch.nn.RNN( #此处直接使用RNN不使用LSTM就可以达到很好的效果,注意RNN参数定义和LSTM一致 input_size = INPUT_SIZE, hidden_size = 32,#注意TIME_STEP并不是RNN中的参数,TIME_STEP是后续数据处理时使用的 num_layers = 1,#注意是num_layers batch_first = True, #此时x为(batch_size,time_step,input_size)三个维度的参数,batch_size优先,位于第一位 ) self.output = torch.nn.Linear(32,1) def forward(self,x,h_state): r_out,h_state = self.rnn(x,h_state)#RNN返回的值包含x本身的值(batch_size,time_step,input_size),和每次叠加的学习内容h_state,也就是hidden state,学习记忆包。。。 outs = []#把每个时间步长计算得到的r_out都收集起来 for time_step in range(r_out.size(1)):#r_out.size(1)是返回的x中时间步长的个数 outs.append(self.output(r_out[:,time_step,:]))#将r_out中每个时间步长对应的值加入列表outs中 return torch.stack(outs,dim=1),h_state#将列表打包成张量返回,并且返回h_state rnn = RNN() #选取优化器 optimizer = torch.optim.Adam(rnn.parameters(),lr = LR) loss_func =torch.nn.MSELoss()#定义误差函数 #初始化hidden state h_state = None#设置h_state初始值为None,因为初始时没有任何学习记忆包 #可视化 plt.figure(1,figsize = (12,5)) plt.ion() #开始机器学习 for step in range(100): start,end = step*np.pi,(step+1)*np.pi steps = np.linspace(start,end,TIME_STEP, dtype=np.float32, endpoint=False) x_np = np.sin(steps) y_np = np.cos(steps) x = torch.from_numpy(x_np[np.newaxis,:,np.newaxis])#将x_np从一维数据变为(batch_size,time_step,input_size)三维形式 y = torch.from_numpy(y_np[np.newaxis,:,np.newaxis])#将y_np从一维数据变为(batch_size,time_step,input_size)三维形式 prediction,h_state = rnn(x,h_state)#初始h_state设置为None h_state = h_state.data loss = loss_func(prediction,y) optimizer.zero_grad() loss.backward() optimizer.step() accuracy = prediction - y#误差 #出图 plt.plot(steps,y_np.flatten(),label = 'true')#被学习数据 plt.plot(steps,prediction.data.numpy().flatten(),label = 'prediction')#学习后的数据 plt.plot(steps,accuracy.data.numpy().flatten(),label = 'error')#误差 plt.draw() plt.pause(0.05) plt.ioff() plt.show()

图中明显看得到初始函数cos(x)曲线逐步趋近于sin(x),迭代100步拟合效果也很好,中间部分为误差曲线,开始时误差很大,随着学习的深入,误差逐渐维持在±0.1之间,但是相对于龙格库塔迭代,误差还是较大,占用资源较多,算法复杂度过大。
两种方法分别适合于不同场合,需要考虑诸多方面的问题。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









