explain命令可以查看SQL语句的执行计划。当explain于SQL语句一起使用时, MySQL将显示来自优化器的有关语句执行计划的信息。 首先创建3张表并插入数据 students表中的数据: studying_student表中的数据: 结果: 跟据id的值出现的情况不同,操作表的顺序或者执行select字句的顺序也会有所不同 所以上图中的例子先执行查询序号为2,table为students的select语句,然后是查询序号为2,table为studying_student的语句,接着是执行table为achievement和table为 subquery2语句 select_type:查询的类型(来源于Mysql5.7文档) 上图中出现的MATERIALIZED:物化子查询 什么是物化策略? 如果子查询执行一次即可以得到结果,即子查询的结果是稳定的,则这样的子查询可以被缓存起来,多次使用。缓存即是物化。缓存到内存中,如果内存中放不下,则会写外存。在MySQL中,这个缓存对应的是临时表(即:物化利用了临时表的机制)。(参考自: MySQL子查询优化—详解–2.) table:显示当前的一行数据是关于哪一个表的 如果查询使用了别名,那么这里显示的是别名,如果不涉及对数据表的操作,那么这显示为null,如果显示为尖括号括起来的就表示这个是临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生。如果是尖括号括起来的<union M,N>,与类似,也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集。如果是尖括号括起来的,这个表示子查询结果被物化,之后子查询结果可以被复用(参考自: Mysql优化之explain详解.) select_type: 因此上例中的MATERIALIZED意思就是被物化的子查询 type: ● If the index is a covering index for the queries and can be used to satisfy all data required from the table, only the index tree is scanned. In this case, the Extracolumn says Using index. An index-only scan usually is faster than ALL because the size of the index usually is smaller than the table data.● A full table scan is performed using reads from the index to look up data rows in index order. Uses index does not appear in the Extra column. 以上说的是索引扫描的两种情况,一种是查询使用了覆盖索引,那么它只需要扫描索引就可以获得数据,这个效率要比全表扫描要快,因为索引通常比数据表小,而且还能避免二次查询。在extra中显示Using index,反之,如果在索引上进行全表扫描,没有Using index的提示。 可以看到上例中的type全部都是all, 原因是字段都没有建立索引(id除外) 给三张表的学号列个建立一个唯一索引,继续用上面的explain语句查询 possible_keys key key_len ref rows extra If you want to make your queries as fast as possible, look out for Extra column values of Using filesort and Using temporary, or, in JSON-formatted EXPLAINoutput, for using_filesort and using_temporary_table properties equal to true. 大概的意思就是说,如果你想要优化你的查询,那就要注意extra辅助信息中的using filesort和using temporary,这两项非常消耗性能,需要注意。 这个列可以显示的信息非常多,有几十种,常用的有: 除了这些之外,还有很多查询数据字典库,执行计划过程中就发现不可能存在结果的一些提示信息 filtered (参考自: Mysql优化之explain详解.)
1.explain的作用
2.实例
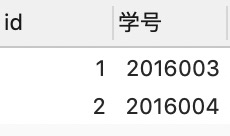
DROP TABLE IF EXISTS students; CREATE TABLE students ( id INT ( 10 ) UNSIGNED NOT NULL AUTO_INCREMENT, 学号 INT ( 7 ) UNSIGNED NOT NULL, 姓名 VARCHAR ( 20 ) NOT NULL, PRIMARY KEY ( `id` ) ); DROP TABLE IF EXISTS achievement; CREATE TABLE achievement ( id INT ( 10 ) UNSIGNED NOT NULL AUTO_INCREMENT, 课程 VARCHAR ( 20 ) NOT NULL, 学号 INT ( 7 ) UNSIGNED NOT NULL, 分数 INT ( 3 ) NOT NULL, PRIMARY KEY ( `id` ) ); DROP TABLE IF EXISTS studying_student; CREATE TABLE studying_student ( id INT (10) UNSIGNED NOT NULL AUTO_INCREMENT, 学号 INT (7) NOT NULL, PRIMARY KEY (`id`) ) INSERT INTO students ( 学号, 姓名 ) VALUES ( 2016001, '张三' ), ( 2016002, '李四' ), ( 2016003, '王五' ), ( 2016004, '吴六' ); INSERT INTO achievement ( 课程, 学号, 分数 ) VALUES ( '计算机', 2016001, 99 ), ( '计算机', 2016002, 89 ), ( '计算机', 2016003, 79 ), ( '计算机', 2016005, 69 ); INSERT INTO studying_student ( 学号 ) VALUES ( 2016003 ), ( 2016004 )
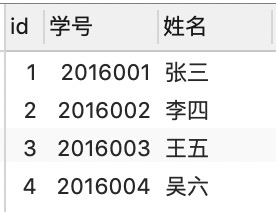
studying_student表中的数据:

然后执行:EXPLAIN SELECT * FROM achievement WHERE `学号` IN ( SELECT students.`学号` FROM students LEFT JOIN studying_student ON students.`学号` = studying_student.`学号` );

id:操作表的顺序
id值出现的情况
执行的顺序
id值相同的时候
由上之下执行
id值不同的时候
id值越大越是先执行
id值有相同也有不同的时候
id值越大的先执行,id值相同的由上之下执行
Value
JSON Name
Meaning
SIMPLE
None
简单查询(不适用union和子查询的)
PRIMARY
None
最外层的查询
UNION
None
UNION中的第二个或者后面的SELECT语句
DEPENDENT UNION
dependent (true)
UNION中的第二个或者后面的SELECT语句,依赖于外部查询
UNION RESULT
union_result
UNION结果
SUBQUERY
None
子查询中的第一个SELECT语句
DEPENDENT SUBQUERY
dependent (true)
子查询中的第一个SELECT语句,依赖于外部查询
DERIVED
None
派生表的SELECT(FROM子句的子查询)
MATERIALIZED
materialized_from_subquery
物化子查询
UNCACHEABLE SUBQUERY
cacheable (false)
对于该结果不能被缓存,必须重新评估外部查询的每一行子查询
UNCACHEABLE UNION
cacheable (false)
UNION中的第二个或者后面的SELECT语句属于不可缓存子查询 (see UNCACHEABLE SUBQUERY)
先了解一下什么是物化子查询
即上图的两个MATERIALIZED是把查询结果进行了缓存供外部查询使用
select_type Value
JSON Name
Meaning
SIMPLE
None
Simple SELECT (not using UNION or subqueries) [表示不需要union操作或者不包含子查询的简单select查询。有连接查询时,外层的查询为simple,且只有一个]
PRIMARY
None
Outermost SELECT [一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary。且只有一个]
UNION
None
Second or later SELECT statement in a UNION [union连接的select查询,除了第一个表外,第二个及以后的表select_type都是union]
DEPENDENT UNION
dependent (true)
Second or later SELECT statement in a UNION, dependent on outer query [与union一样,出现在union 或union all语句中,但是这个查询要受到外部查询的影响]
UNION RESULT
union_result
Result of a UNION. [包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null]
SUBQUERY
None
First SELECT in subquery [除了from字句中包含的子查询外,其他地方出现的子查询都可能是subquery]
DEPENDENT SUBQUERY
dependent (true)
First SELECT in subquery, dependent on outer query [与dependent union类似,表示这个subquery的查询要受到外部表查询的影响]
DERIVED
None
Derived table SELECT (subquery in FROM clause) [from字句中出现的子查询]
MATERIALIZED
materialized_from_subquer
Materialized subquery [被物化的子查询]
UNCACHEABLE SUBQUERY
cacheable (false)
A subquery for which the result cannot be cached and must be re-evaluated for each row of the outer query [对于外层的主表,子查询不可被物化,每次都需要计算(耗时操作]
UNCACHEABLE UNION
cacheable (false)
The second or later select in a UNION that belongs to an uncacheable subquery (see UNCACHEABLE SUBQUERY) [UNION操作中,内层的不可被物化的子查询(类似于UNCACHEABLE SUBQUERY]
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引
type
解释
system
表中只有一行数据或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index
const
使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做唯一索引扫描
eq_reft
出现在要连接过个表的查询计划中,驱动表只返回一行数据,且这行数据是第二个表的主键或者唯一索引,且必须为not null,唯一索引和主键是多列时,只有所有的列都用作比较时才会出现eq_ref
reft
不像eq_ref那样要求连接顺序,也没有主键和唯一索引的要求,只要使用相等条件检索时就可能出现,常见与辅助索引的等值查找。或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现。
fulltextt
全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
ref_or_nullt
与ref方法类似,只是增加了null值的比较。实际用的不多。例如:SELECT * FROM ref_table WHERE key_column=expr OR key_column IS NULL;
index_merget
表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取所个索引,性能可能大部分时间都不如range
unique_subqueryt
用于where中的in形式子查询,子查询返回不重复值唯一值
index_subqueryt
用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
ranget
索引范围扫描,常见于使用 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN()或者like等运算符的查询中。
index
索引全表扫描,把索引从头到尾扫一遍,常见于使用索引列就可以处理不需要读取数据文件的查询、可以使用索引排序或者分组的查询。按照官方文档的说法:
all
这个就是全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录。
我们尝试给学号建立索引,由于学号是唯一的,因此我们可以建立唯一索引CREATE INDEX stu_num_index ON students (`学号` ASC); CREATE INDEX stu_num_index ON achievement (`学号` ASC); CREATE INDEX stu_num_index ON studying_student (`学号` ASC);
结果:

对比上面没有建立索引的结果:

可以发现查询少了一行, 第三步执行消失,这说明主查询的where语句括号内的执行结果没有被物化。
possible_keys 三行都是新建立的索引stu_num_index。
查询可能使用到的索引都会在这里列出来
可以看到第1、第3行都是我们刚刚给两张表通过学号列建立的索引,
第2行<auto_key>是临时表 subquery2 生成的索引
查询真正使用到的索引,select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。
用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到所有的列了。要注意,mysql的ICP特性使用到的索引不会计入其中。另外,key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
这里是执行计划中估算的扫描行数,不是精确值
对于extra列,官网上有这样一段话:
extra
解释
distinct
在select部分使用了distinc关键字
no tables used
不带from字句的查询或者From dual查询。使用not in()形式子查询或not exists运算符的连接查询,这种叫做反连接。即,一般连接查询是先查询内表,再查询外表,反连接就是先查询外表,再查询内表。
using filesort
排序时无法使用到索引时,就会出现这个。常见于order by和group by语句中
using index
查询时不需要回表查询,直接通过索引就可以获取查询的数据。
using join buffer(block nested loop),using join buffer(batched key accss)
5.6.x之后的版本优化关联查询的BNL,BKA特性。主要是减少内表的循环数量以及比较顺序地扫描查询。
using sort_union,using_union,using intersect,using sort_intersection using intersect
表示使用and的各个索引的条件时,该信息表示是从处理结果获取交集
using union
表示使用or连接各个使用索引的条件时,该信息表示从处理结果获取并集
using sort_union和using sort_intersection
与前面两个对应的类似,只是他们是出现在用and和or查询信息量大时,先查询主键,然后进行排序合并后,才能读取记录并返回。
using temporary
表示使用了临时表存储中间结果。临时表可以是内存临时表和磁盘临时表,执行计划中看不出来,需要查看status变量,used_tmp_table,used_tmp_disk_table才能看出来。
using where
表示存储引擎返回的记录并不是所有的都满足查询条件,需要在server层进行过滤。查询条件中分为限制条件和检查条件,5.6之前,存储引擎只能根据限制条件扫描数据并返回,然后server层根据检查条件进行过滤再返回真正符合查询的数据。5.6.x之后支持ICP特性,可以把检查条件也下推到存储引擎层,不符合检查条件和限制条件的数据,直接不读取,这样就大大减少了存储引擎扫描的记录数量。extra列显示using index condition
firstmatch(tb_name)
5.6.x开始引入的优化子查询的新特性之一,常见于where字句含有in()类型的子查询。如果内表的数据量比较大,就可能出现这个
loosescan(m…n)
5.6.x之后引入的优化子查询的新特性之一,在in()类型的子查询中,子查询返回的可能有重复记录时,就可能出现这个
使用explain extended时会出现这个列,5.7之后的版本默认就有这个字段,不需要使用explain extended了。这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









