k近邻法时一种分类与回归方法。本文只探讨分类问题中的k近邻法。k近邻法实际上利用训练数据集对特征向量空间进行划分,不具有显示的学习过程。 给定一个训练集 k近邻算法的特殊情况是 k近邻法使用的模型实际上对应于特征空间的划分。模型由三个基本要素——距离度量、k值选择和分类决策规则决定。 当三个基本要素确定后,对于任一新的实例,它所属的类也唯一确定。这相当于根据上述要素将特征空间划分为一些子空间,确定子空间里的每个点所属的类。 特征空间中,对每个训练实例点 下图是二维特征空间划分的一个例子。 特征空间中两个实例点的距离是两个实例点相似程度的反映。一般使用欧氏距离,也可以使用其他距离,如 设特征空间 当 当 k值的选择会对k近邻法的结果产生重大影响。 如果选择较小的k值,预测结果会对近邻的实例点非常敏感。如果邻近的实例点恰好是噪声,预测就会出错。k值的减小意味着整体模型变得复杂,容易发生过拟合。 如果选择教大的k值,与输入实例较远的不相似的训练实例也会对预测起作用,使预测发生错误。k值增大就意味着整体的模型变得简单,容易发生欠拟合。 在应用中,k值一般取一个比较小的数值。通常采用交叉验证法来选取最优的k 值。 通常是多数表决,由输入实例的k个近邻的训练实例中的多数类决定输入实例的类。 如果分类的损失函数为0-1损失函数,分类函数为: 那么误分类的概率为: 对于给定的实例 下面用iris数据集进测试: 实现k近邻算法时,当特征空间的维数很大或者数据量很大时,主要考虑的问题是如何快速地进行k近邻搜索。 上面实现k近邻的方法需要计算输入实例与每个训练样本的距离,当训练集很大时,非常耗时。 为了提高k近邻搜索效率,可以考虑使用特殊的结构存储训练数据,比如kd树。 kd树是二叉树,表示对k维空间的一个划分。构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域。 kd 树是每个节点均为k维数值点的二叉树,其上的每个节点代表一个超平面,该超平面垂直于当前划分维度的坐标轴,并在该维度上将空间划分为两部分,一部分在其左子树,另一部分在其右子树。即若当前节点的划分维度为d,其左子树上所有点在d维的坐标值均小于当前值,右子树上所有点在d维的坐标值均大于等于当前值,本定义对其任意子节点均成立。 以书上的例子为例,假设有6个二维数据点 k-d树算法就是要确定图中这些分割空间的分割线(多维空间即为分割平面,一般为超平面)。下面就要通过一步步展示k-d树是如何确定这些分割线的。 由于数据维度只有2维,所以可以简单地给x,y两个方向轴编号为0,1,也即split={0,1}。 首先split取0,也就是x轴方向; 确定分割点的值。根据x轴方向对数据进行排序得到 确定左子空间和右子空间。这样分割超平面 如算法所述,k-d树的构建是一个递归的过程。然后对左子空间和右子空间内的数据重复根节点的过程,但此时split取1,也就是y轴方向, 就可以得到下一级子节点 接下来跑下上面的例子: 上面的描述看不懂的话没关系,我们通过简单的例子来掌握它的思想。 以一个简单的实例来描述最邻近查找的基本思路: 星号表示要查询的点 而找到的叶子节点并不一定就是最邻近的,最邻近肯定距离查询点更近,应该位于以查询点为圆心且通过叶子节点的圆域内。 为了找到真正的最近邻,还需要进行’回溯’操作:算法沿搜索路径反向查找是否有距离查询点更近的数据点。 此例中先从 下面再来一个复杂点的例子。例子如查找点为 可见该圆和 回溯至 这也是kd树的完整代码,这里通过超平面距离判断是否相交。 下面我们测试下上面的两种情况。 下面用更多的数据来测试一下吧: 运行测试: 输出为: 从输出可以看到,只搜索了54次就找到了最近邻的3个节点。不过耗时35秒,其实这里的耗时主要是在构建的时候,搜索的时候是很快的,不信可以试下。 下面我们用sklearn提供的KDTree来试一下同样的数据,看我们实现的kd树查询结果是否正确。 调用 输出: 对比二者的输出结果,可以看到结果是一样的。sklearn的 有时间可以研究下如何优化构造代码。
引言
k近邻算法
,对于新的实例,在训练集中找到与该实例最邻近的k个实例,这k个实例的多数(多数表决)属于某个类,则该新实例就分为这个类。
中找出与
最邻近的
个点,涵盖这个
个点的
的邻域记作
;
中根据分类决策规则(如多数表决)决定
的类别
:
的情形,称为最近邻算法。k近邻模型
模型
,该点附近的所有点组成一个区域,叫做单元(cell)。每个训练实例点拥有一个单元,所有训练实例点的单元构成对特征空间的一个划分。 最近邻法将实例
的类
作为其单元中所有点的类标记。
距离度量
距离或Minkowski距离。
是
维实数向量空间
,
,
的
距离定义为
,当
时,称为欧氏距离(Euclidean distance)
时,称为曼哈顿距离(Manhattan distance)
时,它是各个坐标距离的最大值,即
# 同时计算单个样本x和X中所有样本的距离 def L(x, X, p=2): if len(X.shape) == 1: X = X.reshape(-1,X.shape[0]) sum = np.sum(np.power(np.abs(x - X),p),axis=1) #先求和 return np.power(sum,1/p) #再开方 k值的选择
分类决策规则
(1-分类正确的概率)
,其最近邻的
个训练实例点的集合为
。如果涵盖
的区域的类别是
,那么误分类率是
是指数函数,要使误分类率最小即经验风险最小,就要使得
最大,所以多数表决规则等价于经验风险最小化。knn代码实现
import numpy as np from collections import Counter # 同时计算单个样本x和X中所有样本的距离 def L(x, X, p=2): if len(X.shape) == 1: X = X.reshape(-1,X.shape[0]) sum = np.sum(np.power(np.abs(x - X),p),axis=1) #先求和 return np.power(sum,1/p) #再开方 class KNN: def __init__(self,n_neighbors=3, p=2): """ parameter: n_neighbors 临近点个数 parameter: p 距离度量 """ self.k = n_neighbors self.p = p self.X_train = None self.y_train = None def fit(self,X_train, y_train): self.X_train = X_train self.y_train = y_train def predict(self,X): return np.array([self._predict(x) for x in X]) def _predict(self,x): # 找到距离最近的k个点 top_k_indexes = np.argsort(L(x,self.X_train,self.p))[:self.k] #得到最近k个点的索引 top_k = self.y_train[top_k_indexes] return Counter(top_k).most_common(1)[0][0] def score(self,X_test,y_test): y_predict = self.predict(X_test) return np.sum(y_predict == y_test) / len(X_test) import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from collections import Counter # data iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['label'] = iris.target df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label'] # data = np.array(df.iloc[:100, [0, 1, -1]]) data = np.array(df.iloc[:100, [0, 1, -1]]) X, y = data[:,:-1], data[:,-1] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) knn = KNN() knn.fit(X_train,y_train) knn.score(X_test,y_test) 
准确率很高,因为每次都需要比较目标与所有训练样本点的距离,但是如果数据量很大的时候会非常耗时。kd树
构造kd树
,数据点位于二维空间内,如下图黑点所示: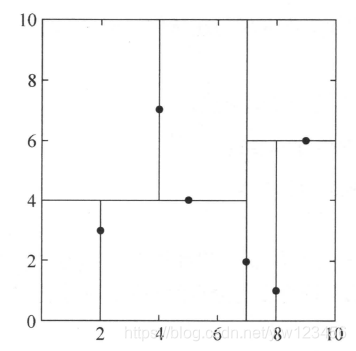
(此时只看第0维),从中选出中位数为
,得到分割节点的值为
。该节点的分割超平面就是通过
并垂直于split = 0(x轴)的直线
;
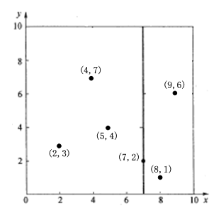
将整个空间分为两部分,如上图所示。
的部分为左子空间,包含3个节点
;另一部分为右子空间,包含2个节点
;
和
,同时将空间和数据集进一步细分。如此反复直到空间中只包含一个数据点,最后生成的k-d树如下图所示: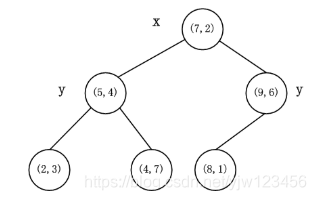
构造kd树代码
# KD-Tree的节点 class Node: def __init__(self, data=None, split=0, left=None, right=None): self.data = data self.left = left self.right = right self.split = split # 当前节点的划分维度 def __repr__(self): return "data:%s (split:%d)" % (self.data, self.split) class KdTree: def __init__(self, data): k = data.shape[1] # 数据的维度 # 同时保存数据的值和索引信息 data_with_indexes = list(zip(data, range(data.shape[0]))) def create_node(data_set, split): if len(data_set) == 0: return None # 根据划分维度进行排序, data_set_sorted = sorted(data_set, key=lambda x: x[0][split]) # 传入排序后的传入就是排序后的数组 mid = len(data_set_sorted) // 2 # 找到中位数 mid_data = data_set_sorted[mid] # 找到中位数对应的元素 # print('mid_data: %s for axis = %d' %(mid_data,split)) next_split = (split + 1) % k # 下个维度 # 左子树的所有点在split维的值都小于当前mid_data值 # 右子树都大于mid_data值 return Node(mid_data, split, create_node(data_set_sorted[:mid], split=next_split), create_node(data_set_sorted[mid + 1:], split=next_split), ) self.root = create_node(data_with_indexes, 0) def preorder(self, node): if node: print(node.data) if node.left: self.preorder(node.left) if node.right: self.preorder(node.right) data_set = np.array([[2, 3], [5, 4], [9, 6], [4, 7], [8, 1], [7, 2]]) tree = KdTree(data_set) tree.preorder(tree.root) 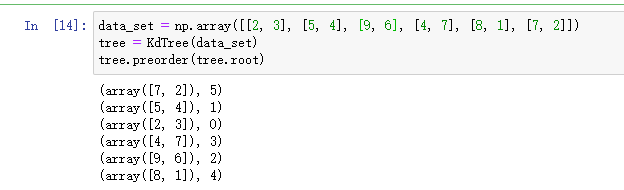
用先序遍历打印出结果如上,这里维护了数据的索引信息,方便后面通过这些索引找到标签进行投票。搜索kd树
。通过二叉搜索,顺着搜索路径很快就能找到最邻近的近似点,也就是叶子节点
。
点开始进行二叉查找,然后到达
,最后到达
,此时搜索路径中的节点为
。
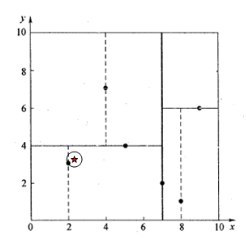
首先以
作为当前最近邻点,计算其到查询点
的距离为0.1414,然后回溯到其父节点
,并判断在该父节点的其他子节点空间中是否有距离查询点更近的数据点。以
为圆心,以0.1414为半径画圆,如下图所示。发现该圆并不和超平面
交割,因此不用进入
节点右子空间中去搜索。
再回溯到
,以
为圆心,以0.1414为半径的圆不会与
超平面交割,因此不用进入
右子空间进行查找。至此,搜索路径中的节点已经全部回溯完,结束整个搜索,返回最近邻点
,最近距离为0.1414。
。同样先进行二叉查找,先从
查找到
节点,在进行查找时是由
为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到
,形成搜索路径
。
取
为当前最近邻点,计算其与目标查找点的距离为3.202。然后回溯到
,计算其与查找点之间的距离为3.041。以
为圆心,以3.041为半径作圆,如图所示。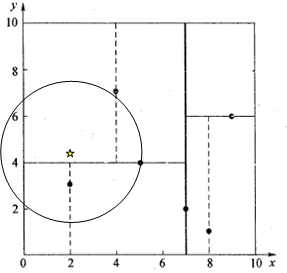
超平面交割,所以需要进入
左子空间进行查找。此时需将
节点加入搜索路径中得
。回溯至
叶子节点,
距离
比
要近,所以最近邻点更新为
,最近距离更新为1.5。
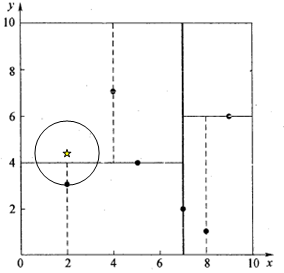
,以
为圆心1.5为半径作圆,并不和
分割超平面交割,如图所示。
至此,搜索路径回溯完。返回最近邻点
,最近距离1.5。搜索kd树代码
import numpy as np import heapq # 优先队列 np.set_printoptions(suppress=True)#防止科学技术法输出,输出带e的数字 # KD-Tree的节点 class Node: def __init__(self, data=None, split=0, left=None, right=None): self.data = data self.left = left self.right = right self.split = split # 当前节点的划分维度 def __repr__(self): return "data:%s (split:%d)" % (self.data, self.split) class KdTree: def __init__(self, data): k = data.shape[1] # 数据的维度 # 同时保存数据的值和索引信息 data_with_indexes = list(zip(data, range(data.shape[0]))) def create_node(data_set, split): if len(data_set) == 0: return None # 根据划分维度进行排序, data_set_sorted = sorted(data_set, key=lambda x: x[0][split]) # 传入排序后的传入就是排序后的数组 mid = len(data_set_sorted) // 2 # 找到中位数 mid_data = data_set_sorted[mid] # 找到中位数对应的元素 # print('mid_data: %s for axis = %d' %(mid_data,split)) next_split = (split + 1) % k # 下个维度 # 左子树的所有点在split维的值都小于当前mid_data值 # 右子树都大于mid_data值 return Node(mid_data, split, create_node(data_set_sorted[:mid], split=next_split), create_node(data_set_sorted[mid + 1:], split=next_split), ) self.root = create_node(data_with_indexes, 0) def preorder(self, node): if node: print(node.data) if node.left: self.preorder(node.left) if node.right: self.preorder(node.right) def query(self, x, k=3, p=2): # 因为python里面只有小顶堆,所以乘以-1变成大顶堆(最大的值乘以-1就变成了最小的) # 先初始化这个小顶堆,全部初始化为负无穷大 # [(距离的负数,索引)] nearest = [(-np.inf, -1)] * k self.times = 0 def search(node): if node: # 如果目标点x当前维的坐标小于切分点的坐标 split = node.split # 进行分割的维度 dis = x[split] - node.data[0][split] # 同时也是超平面距离 self.times = self.times + 1 # 递归地访问子节点 search(node.left if dis < 0 else node.right) # 如果该递归函数返回,我们得到当前最近点。 上面搜索过程中第2步 # 计算目标点与当前点node的距离 cur_dis = np.linalg.norm(x - node.data[0], p) # 如果当前距离 小于 nearest中最远的距离,则替换最远的距离 if cur_dis < -nearest[0][0]: heapq.heapreplace(nearest, (-cur_dis, node.data[1])) # 继续查找另外一边,如果另一边可能存在比nearest最远的距离要小的距离 # 比较目标点和分离超平面的距离dis 和当前nearest最远的距离 # 因为我们要查询最近的k个 if -(nearest[0][0]) > abs(dis): # 如果相交,可能在另一个子节点对应的区域内存在距目标点更近的点,移动到另一个子节点。 search(node.right if dis < 0 else node.left) search(self.root) top_k = [e for e in heapq.nlargest(k, nearest)] distances = [-e[0] for e in top_k] indexes = [e[1] for e in top_k] print('search times :%d' % self.times) return distances, indexes 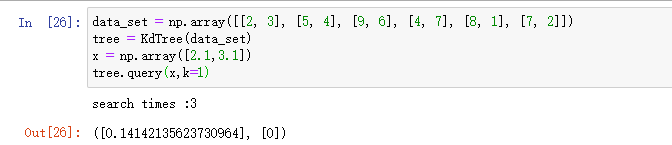
首先是查询距离点
最近的点,得到最近的距离为0.1414,最近点的索引为0,我们就知道了最近点为
。
查询
的结果也和上面分析的一致。def test0(): np.random.seed(666) ndata = 1000000 ndim = 2 data = np.random.rand(ndata * ndim).reshape((-1, ndim)) kdtree = KdTree(data) target = np.array([0.5, 0.2]) print(kdtree.query(target)) import datetime start = datetime.datetime.now() test0() end = datetime.datetime.now() print(end - start) search times :54 ([0.0005330975668433067, 0.000596530184194294, 0.0006526855405323105], [11345, 731231, 761132]) 0:00:35.145470 def test1(): from sklearn.neighbors import KDTree np.random.seed(666) ndata = 1000000 ndim = 2 data = np.random.rand(ndata * ndim).reshape((-1, ndim)) tree = KDTree(data, metric='euclidean', leaf_size=2) target = np.array([[0.5, 0.2]]) print(tree.query(target, k=3)) test1()进行测试:import datetime start = datetime.datetime.now() test1() end = datetime.datetime.now() print(end - start) (array([[0.0005331 , 0.00059653, 0.00065269]]), array([[ 11345, 731231, 761132]], dtype=int64)) 0:00:03.885332 KDTree还是高效很多啊。参考
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 563
563