项目kaggle链接:https://www.kaggle.com/c/nlp-getting-started/overview 在紧急情况下,Twitter已经成为一个重要的沟通渠道。智能手机的普及使人们能够实时宣布正在观察的紧急情况。正因为如此,越来越多的机构对程序化监控Twitter(即救灾组织和新闻机构)感兴趣。但是,人们并不总是清楚一个人的话是否真的在宣告一场灾难。比如下面的例子: 作者明确地使用了“燃烧”这个词,但它的意思是隐喻性的。这一点对人类来说是显而易见的,特别是在视觉辅助下。但对机器来说就不那么清楚了。 在这场竞争中,你面临着建立一个机器学习模型的挑战,该模型可以预测哪些Tweets是关于真正的灾难的,哪些Tweets不是。 查看标签0和1的分布情况 定义去除所有停用词,语气符号,html符号,表情符号的函数 没有提及真实的灾难的推特的词云: 介绍下Bert预训练模型: 接下来我们使用Bert自带的分词器生成词向量看看效果 接下来我们就要构造Bert模型的输入层 输出层有两个输出 具体设置和预设参数请参考Bert的官方GitHub:https://github.com/google-research/bert 这里我们进行了一个Bert模型输入的简单构造,每一句句子的词向量不够的长度用0补充,由于都是单个句子,所以token type都是0 接下来我们就构造Bert模型,由于二分类任务激活函数是sigmoid,Adam优化器其他没啥好说的 接下来训练 调参过程这里就不详细说了,经过几次提交,得到最好的成绩是accuracy:0.83742
Tweet with Disaster(Kaggle NLP项目实战)
项目介绍(Real or Not? NLP with Disaster Tweets)

EDA
数据预处理部分
1 导入数据
train = pd.read_csv('../input/nlp-getting-started/train.csv') test = pd.read_csv('../input/nlp-getting-started/test.csv') sample_submission = pd.read_csv('../input/nlp-getting-started/sample_submission.csv') # Print the shape of the training data print('{} rows and {} cols in training dataset.'.format(train.shape[0], train.shape[1])) print('{} rows and {} cols in training dataset.'.format(test.shape[0], test.shape[1])) # Inspecting the training data train.head(10) 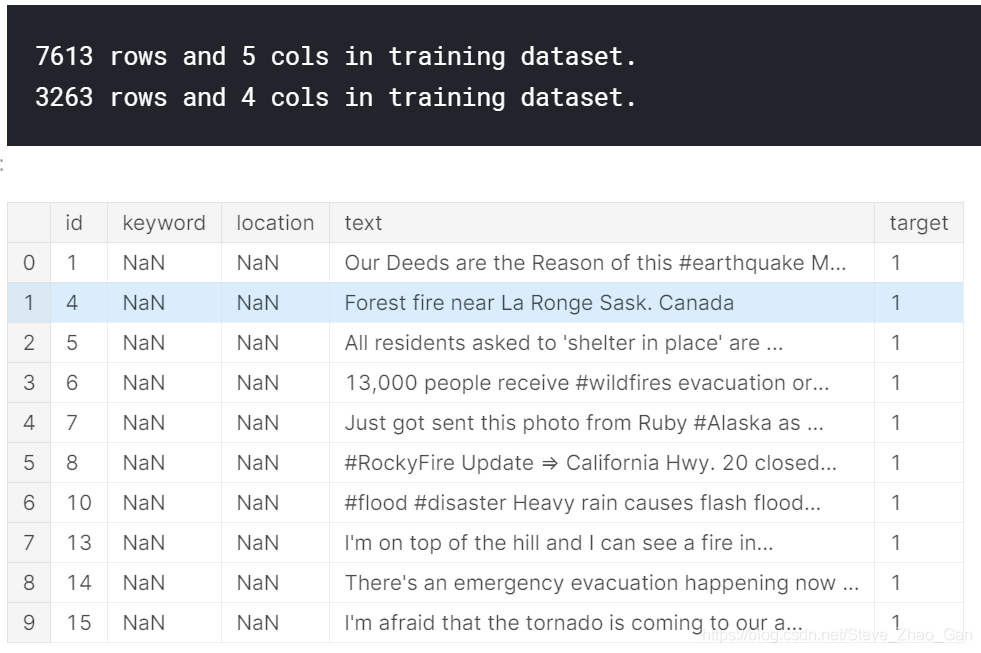
2 描述性分析
# Frequency for taget variable count_table = train.target.value_counts() display(count_table) # Plot class distribution plt.figure(figsize=(6,5)) plt.bar('False',count_table[0],label='False',width=0.6) plt.bar('True', count_table[1],label='True',width=0.6) plt.legend() plt.ylabel('Count of examples') plt.xlabel('Category') plt.title('Class Distribution') plt.ylim([0,4700]) plt.show() 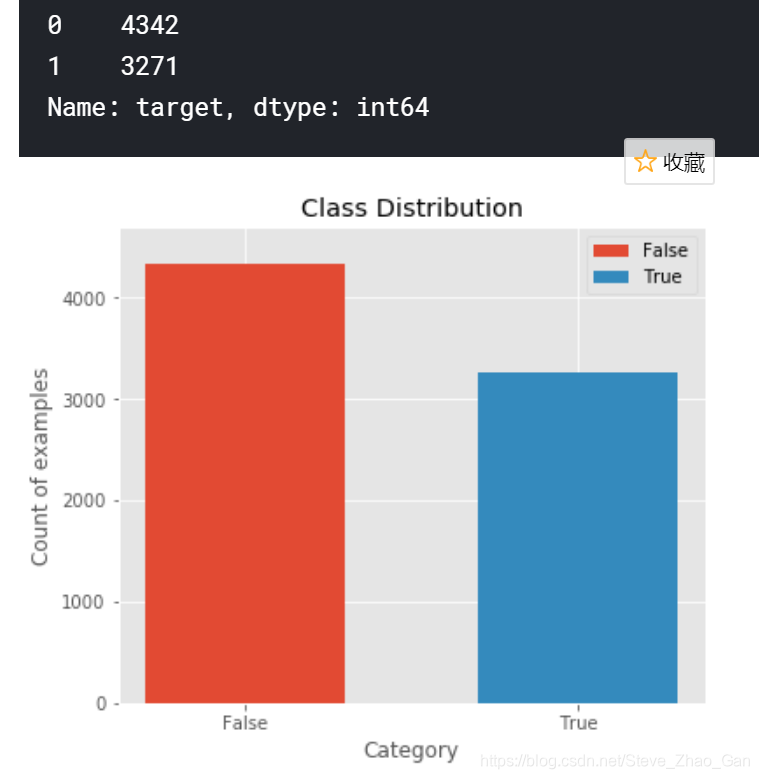
每条推特长度的分布# Plot the frequency of tweets length bins = 150 plt.figure(figsize=(18,5)) plt.hist(train[train['target']==0]['length'], label= 'False',bins=bins,alpha=0.8) plt.hist(train[train['target']==1]['length'], label= 'True', bins=bins,alpha=0.8) plt.xlabel('Length of text (characters)') plt.ylabel('Count') plt.title('Frequency of tweets length') plt.legend(loc='best') plt.show() 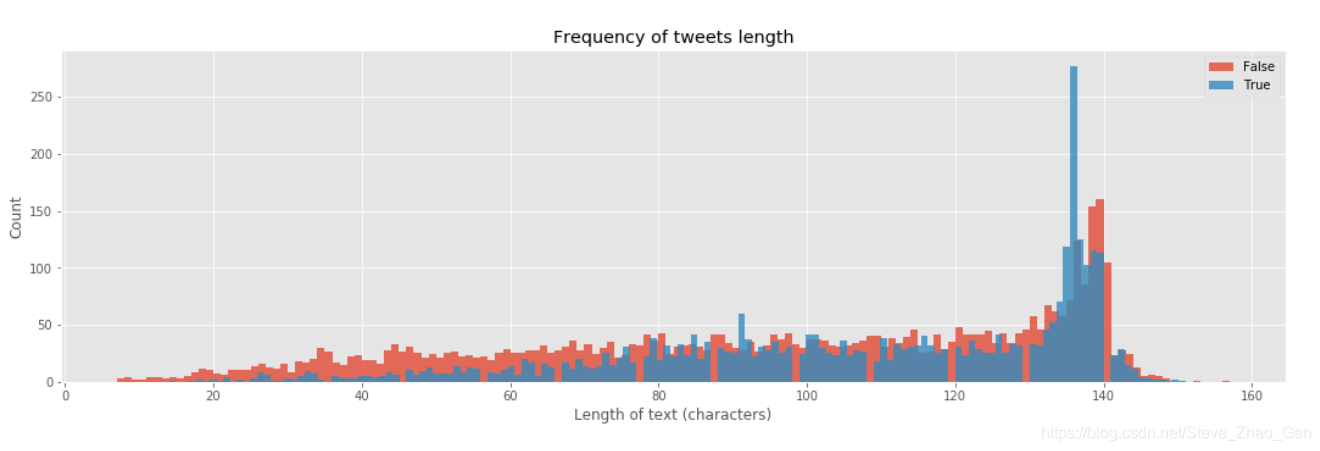
两种推特的长度分布情况对比# Frequency of tweets length in 2 classes fg, (ax1, ax2)=plt.subplots(1,2,figsize=(14,5)) ax1.hist(train[train['target']==0]['length'],color='red') ax1.set_title('Distribution of fake tweets') ax1.set_xlabel('Tweets length (characters)') ax1.set_ylabel('Count') ax2.hist(train[train['target']==1]['length'],color='blue') ax2.set_title('Distribution of true tweets') ax2.set_xlabel('Tweets length (characters)') ax2.set_ylabel('Count') fg.suptitle('Characater in classes') plt.show() 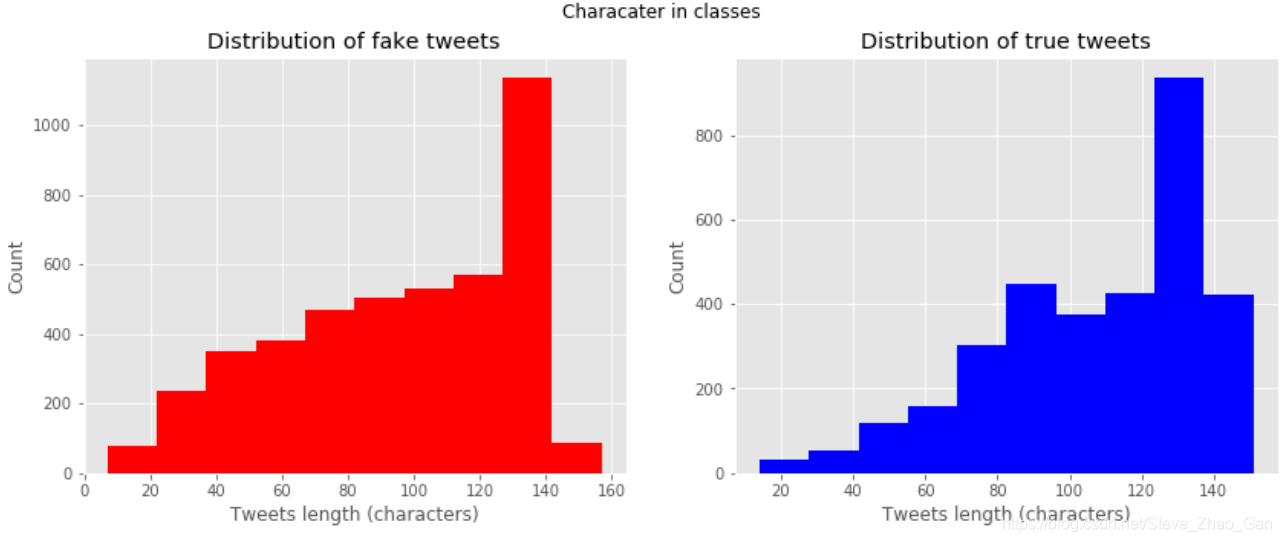
两种推特出现的词的数量分布# Plot the distribution of count of words words_true = train[train['target']==1]['text'].str.split().apply(len) words_false = train[train['target']==0]['text'].str.split().apply(len) plt.figure(figsize=(10,5)) plt.hist(words_false, label='False',alpha=0.8,bins=15) plt.hist(words_true, label='True',alpha=0.6,bins=15) plt.legend(loc='best') plt.title('Count of words in tweets') plt.xlabel('Count of words') plt.ylabel('Count') plt.show() 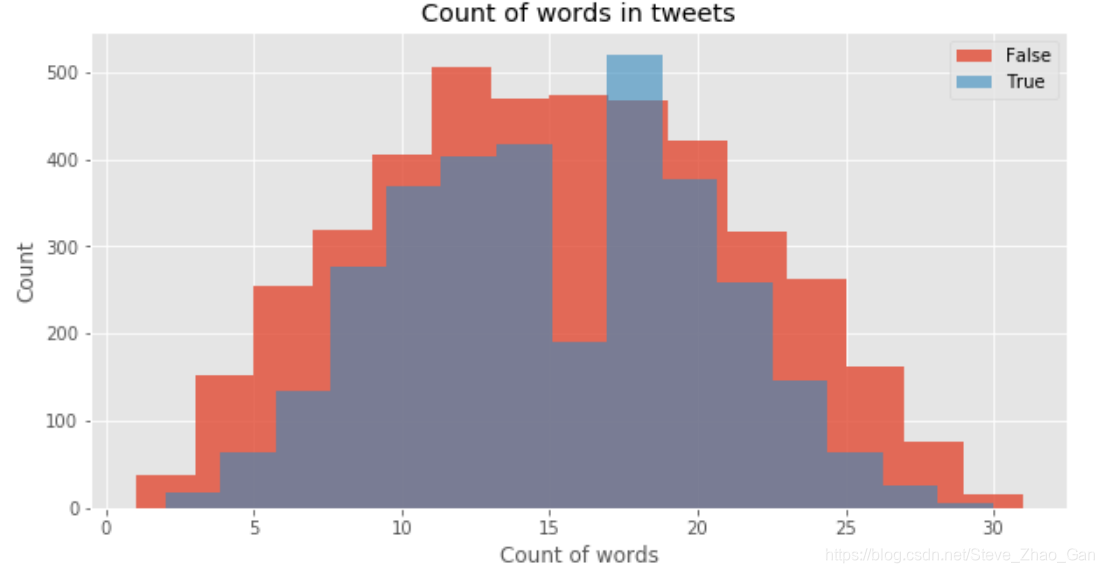
3 数据清洗
# Define a function to remove URL def remove_url(text): url = re.compile(r'https?://S+|www.S+') return url.sub(r'',text) # Test function test = 'Address of this kernel: https://www.kaggle.com/lilstarboy/kernel4d04fe5667/edit' print(remove_url(test)) # Define a function to remove html tag def remove_html(text): html = re.compile(r'<.*?>') return html.sub(r'',text) # Test function test = """<div> <h1>Real or Fake</h1> <p>Kaggle </p> <a href="https://www.kaggle.com/c/nlp-getting-started">getting started</a> </div>""" print(remove_html(test)) # Define a function to remove emojis def remove_emoji(text): emoji_pattern = re.compile("[" u"U0001F600-U0001F64F" # emoticons u"U0001F300-U0001F5FF" # symbols & pictographs u"U0001F680-U0001F6FF" # transport & map symbols u"U0001F1E0-U0001F1FF" # flags (iOS) u"U00002702-U000027B0" u"U000024C2-U0001F251" "]+", flags=re.UNICODE) return emoji_pattern.sub(r'', text) remove_emoji("To test 🚀") # Define a function to remove punctuations def remove_punct(text): table=str.maketrans('','',string.punctuation) return text.translate(table) # Define a function to convert abbreviations to text abbreviations = { "$" : " dollar ", "€" : " euro ", "4ao" : "for adults only", "a.m" : "before midday", "a3" : "anytime anywhere anyplace", "aamof" : "as a matter of fact", "acct" : "account", "adih" : "another day in hell", "afaic" : "as far as i am concerned", "afaict" : "as far as i can tell", "afaik" : "as far as i know", "afair" : "as far as i remember", "afk" : "away from keyboard", "app" : "application", "approx" : "approximately", "apps" : "applications", "asap" : "as soon as possible", "asl" : "age, sex, location", "atk" : "at the keyboard", "ave." : "avenue", "aymm" : "are you my mother", "ayor" : "at your own risk", "b&b" : "bed and breakfast", "b+b" : "bed and breakfast", "b.c" : "before christ", "b2b" : "business to business", "b2c" : "business to customer", "b4" : "before", "b4n" : "bye for now", "b@u" : "back at you", "bae" : "before anyone else", "bak" : "back at keyboard", "bbbg" : "bye bye be good", "bbc" : "british broadcasting corporation", "bbias" : "be back in a second", "bbl" : "be back later", "bbs" : "be back soon", "be4" : "before", "bfn" : "bye for now", "blvd" : "boulevard", "bout" : "about", "brb" : "be right back", "bros" : "brothers", "brt" : "be right there", "bsaaw" : "big smile and a wink", "btw" : "by the way", "bwl" : "bursting with laughter", "c/o" : "care of", "cet" : "central european time", "cf" : "compare", "cia" : "central intelligence agency", "csl" : "can not stop laughing", "cu" : "see you", "cul8r" : "see you later", "cv" : "curriculum vitae", "cwot" : "complete waste of time", "cya" : "see you", "cyt" : "see you tomorrow", "dae" : "does anyone else", "dbmib" : "do not bother me i am busy", "diy" : "do it yourself", "dm" : "direct message", "dwh" : "during work hours", "e123" : "easy as one two three", "eet" : "eastern european time", "eg" : "example", "embm" : "early morning business meeting", "encl" : "enclosed", "encl." : "enclosed", "etc" : "and so on", "faq" : "frequently asked questions", "fawc" : "for anyone who cares", "fb" : "facebook", "fc" : "fingers crossed", "fig" : "figure", "fimh" : "forever in my heart", "ft." : "feet", "ft" : "featuring", "ftl" : "for the loss", "ftw" : "for the win", "fwiw" : "for what it is worth", "fyi" : "for your information", "g9" : "genius", "gahoy" : "get a hold of yourself", "gal" : "get a life", "gcse" : "general certificate of secondary education", "gfn" : "gone for now", "gg" : "good game", "gl" : "good luck", "glhf" : "good luck have fun", "gmt" : "greenwich mean time", "gmta" : "great minds think alike", "gn" : "good night", "g.o.a.t" : "greatest of all time", "goat" : "greatest of all time", "goi" : "get over it", "gps" : "global positioning system", "gr8" : "great", "gratz" : "congratulations", "gyal" : "girl", "h&c" : "hot and cold", "hp" : "horsepower", "hr" : "hour", "hrh" : "his royal highness", "ht" : "height", "ibrb" : "i will be right back", "ic" : "i see", "icq" : "i seek you", "icymi" : "in case you missed it", "idc" : "i do not care", "idgadf" : "i do not give a damn fuck", "idgaf" : "i do not give a fuck", "idk" : "i do not know", "ie" : "that is", "i.e" : "that is", "ifyp" : "i feel your pain", "IG" : "instagram", "iirc" : "if i remember correctly", "ilu" : "i love you", "ily" : "i love you", "imho" : "in my humble opinion", "imo" : "in my opinion", "imu" : "i miss you", "iow" : "in other words", "irl" : "in real life", "j4f" : "just for fun", "jic" : "just in case", "jk" : "just kidding", "jsyk" : "just so you know", "l8r" : "later", "lb" : "pound", "lbs" : "pounds", "ldr" : "long distance relationship", "lmao" : "laugh my ass off", "lmfao" : "laugh my fucking ass off", "lol" : "laughing out loud", "ltd" : "limited", "ltns" : "long time no see", "m8" : "mate", "mf" : "motherfucker", "mfs" : "motherfuckers", "mfw" : "my face when", "mofo" : "motherfucker", "mph" : "miles per hour", "mr" : "mister", "mrw" : "my reaction when", "ms" : "miss", "mte" : "my thoughts exactly", "nagi" : "not a good idea", "nbc" : "national broadcasting company", "nbd" : "not big deal", "nfs" : "not for sale", "ngl" : "not going to lie", "nhs" : "national health service", "nrn" : "no reply necessary", "nsfl" : "not safe for life", "nsfw" : "not safe for work", "nth" : "nice to have", "nvr" : "never", "nyc" : "new york city", "oc" : "original content", "og" : "original", "ohp" : "overhead projector", "oic" : "oh i see", "omdb" : "over my dead body", "omg" : "oh my god", "omw" : "on my way", "p.a" : "per annum", "p.m" : "after midday", "pm" : "prime minister", "poc" : "people of color", "pov" : "point of view", "pp" : "pages", "ppl" : "people", "prw" : "parents are watching", "ps" : "postscript", "pt" : "point", "ptb" : "please text back", "pto" : "please turn over", "qpsa" : "what happens", #"que pasa", "ratchet" : "rude", "rbtl" : "read between the lines", "rlrt" : "real life retweet", "rofl" : "rolling on the floor laughing", "roflol" : "rolling on the floor laughing out loud", "rotflmao" : "rolling on the floor laughing my ass off", "rt" : "retweet", "ruok" : "are you ok", "sfw" : "safe for work", "sk8" : "skate", "smh" : "shake my head", "sq" : "square", "srsly" : "seriously", "ssdd" : "same stuff different day", "tbh" : "to be honest", "tbs" : "tablespooful", "tbsp" : "tablespooful", "tfw" : "that feeling when", "thks" : "thank you", "tho" : "though", "thx" : "thank you", "tia" : "thanks in advance", "til" : "today i learned", "tl;dr" : "too long i did not read", "tldr" : "too long i did not read", "tmb" : "tweet me back", "tntl" : "trying not to laugh", "ttyl" : "talk to you later", "u" : "you", "u2" : "you too", "u4e" : "yours for ever", "utc" : "coordinated universal time", "w/" : "with", "w/o" : "without", "w8" : "wait", "wassup" : "what is up", "wb" : "welcome back", "wtf" : "what the fuck", "wtg" : "way to go", "wtpa" : "where the party at", "wuf" : "where are you from", "wuzup" : "what is up", "wywh" : "wish you were here", "yd" : "yard", "ygtr" : "you got that right", "ynk" : "you never know", "zzz" : "sleeping bored and tired" } def convert_abbrev(word): return abbreviations[word.lower()] if word.lower() in abbreviations.keys() else word def convert_abbrev_in_text(text): tokens = word_tokenize(text) tokens = [convert_abbrev(word) for word in tokens] text = ' '.join(tokens) return text # Test function test = 'This is very complex!!!!!??' print(remove_punct(test)) 4 用词云进行可视化展示
# Wordcloud for not disaster tweets corpus_all_0 = create_corpus(df, 0) # Plot the wordcloud plt.figure(figsize=(15,8)) word_cloud = WordCloud( background_color='white', max_font_size = 80 ).generate(" ".join(corpus_all_0)) plt.imshow(word_cloud) plt.axis('off') plt.show() # Wordcloud for disaster tweets corpus_all_1 = create_corpus(df, 1) # Plot the wordcloud plt.figure(figsize=(15,8)) word_cloud = WordCloud( background_color='white', max_font_size = 80 ).generate(" ".join(corpus_all_1)) plt.imshow(word_cloud) plt.axis('off') plt.show()
提及真实灾难的推特的词云
导入Bert预训练模型
用Bert进行迁移学习和fine-tuning的原理大家可以参考这篇论文https://arxiv.org/abs/1810.04805
这里用的是Bert-based Uncased模型,是一个12层神经网络,768个hidden layer,110M个参数的小模型(在Bert模型里面确实算小了狗头)# Define hyperparameters MAXLEN = 128 BATCH_SIZE = 32 NUM_EPOCHS = 5 LEARNING_RATE = 3e-6 # Import bert tokenizer, config and model tokenizer = BertTokenizer.from_pretrained("https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt") config = BertConfig.from_pretrained("https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-config.json") bert_model = TFBertModel.from_pretrained("https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-tf_model.h5",config=config) # Convert the first sentence in 'text' column into word vector text = train['text'][0] print(text) input_ids = tokenizer.encode(text,max_length=MAXLEN) print(input_ids) print(tokenizer.convert_ids_to_tokens(input_ids)) 
构造Bert模型输入
这里的Bert预训练模型有三个输入:
# Build input values on the training data train_input_ids = [] train_attension_mask = [] train_token_type_ids = [] for text in train['text']: input_ids = tokenizer.encode(text,max_length=MAXLEN) padding_length = MAXLEN-len(input_ids) train_input_ids.append(input_ids+[0]*padding_length) train_attension_mask.append([1]*len(input_ids)+[0]*padding_length) train_token_type_ids.append([0]*MAXLEN) train_input_ids = np.array(train_input_ids) train_attension_mask = np.array(train_attension_mask) train_token_type_ids = np.array(train_token_type_ids) # Build input values on the testing data test_input_ids = [] test_attension_mask = [] test_token_type_ids = [] for text in test['text']: input_ids = tokenizer.encode(text,max_length=MAXLEN) padding_length = MAXLEN-len(input_ids) test_input_ids.append(input_ids+[0]*padding_length) test_attension_mask.append([1]*len(input_ids)+[0]*padding_length) test_token_type_ids.append([0]*MAXLEN) test_input_ids = np.array(test_input_ids) test_attension_mask = np.array(test_attension_mask) test_token_type_ids = np.array(test_token_type_ids) y_train = np.array(train['target']) 建立模型并训练
# Build the Bert-base-Uncased model input_ids = keras.layers.Input(shape=(MAXLEN,),dtype='int32') attension_mask = keras.layers.Input(shape=(MAXLEN,),dtype='int32') token_type_ids = keras.layers.Input(shape=(MAXLEN,),dtype='int32') _, x = bert_model([input_ids,attension_mask,token_type_ids]) outputs = keras.layers.Dense(1,activation='sigmoid')(x) model = keras.models.Model(inputs=[input_ids,attension_mask,token_type_ids],outputs=outputs) model.compile(loss='binary_crossentropy',optimizer=keras.optimizers.Adam(lr=LEARNING_RATE),metrics=['accuracy']) # Fit the Bert-base-Uncased model (train_input_ids,valid_input_ids, train_attension_mask,valid_attension_mask, train_token_type_ids,valid_token_type_ids,y_train,y_valid) = train_test_split(train_input_ids,train_attension_mask, train_token_type_ids,y_train,test_size=0.1, stratify=y_train, random_state=0) early_stopping = keras.callbacks.EarlyStopping(patience=3,restore_best_weights=True) model.fit([train_input_ids,train_attension_mask,train_token_type_ids],y_train, validation_data=([valid_input_ids,valid_attension_mask,valid_token_type_ids],y_valid), batch_size = BATCH_SIZE,epochs=NUM_EPOCHS,callbacks=[early_stopping]) 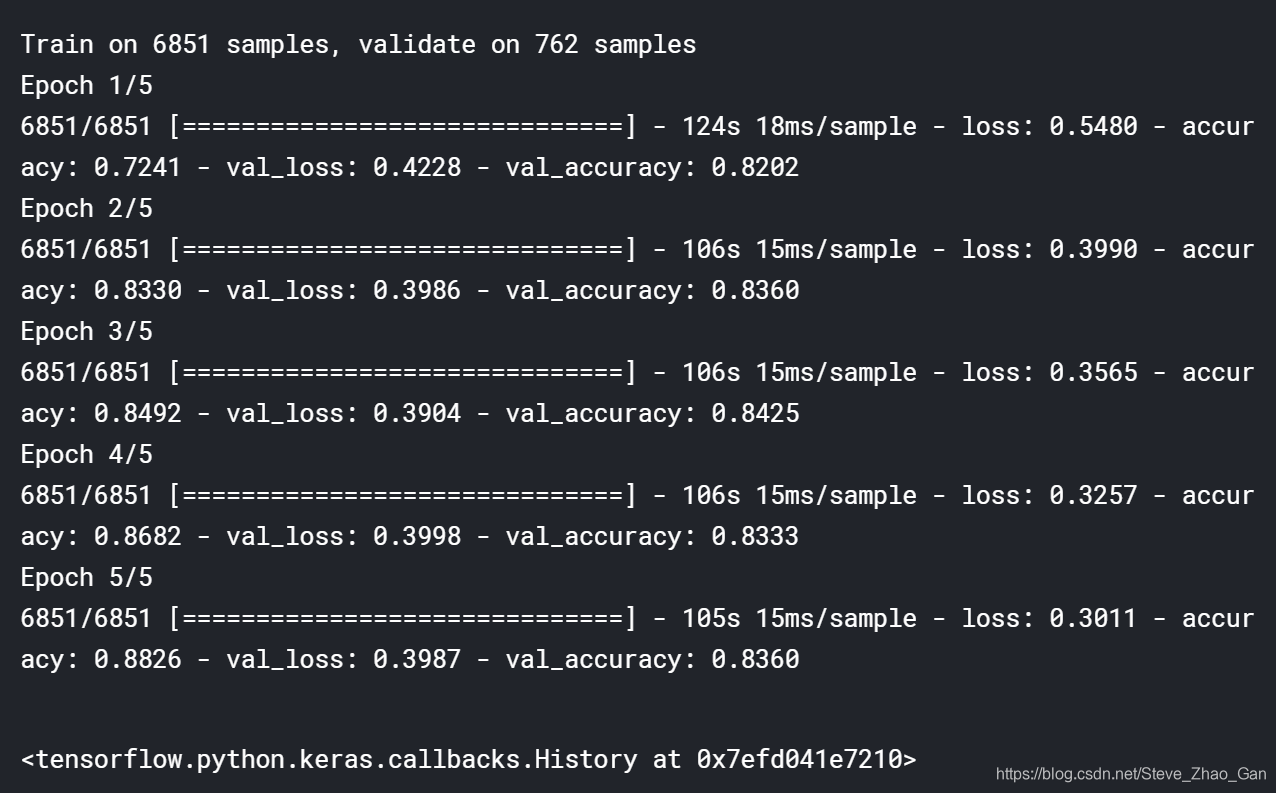
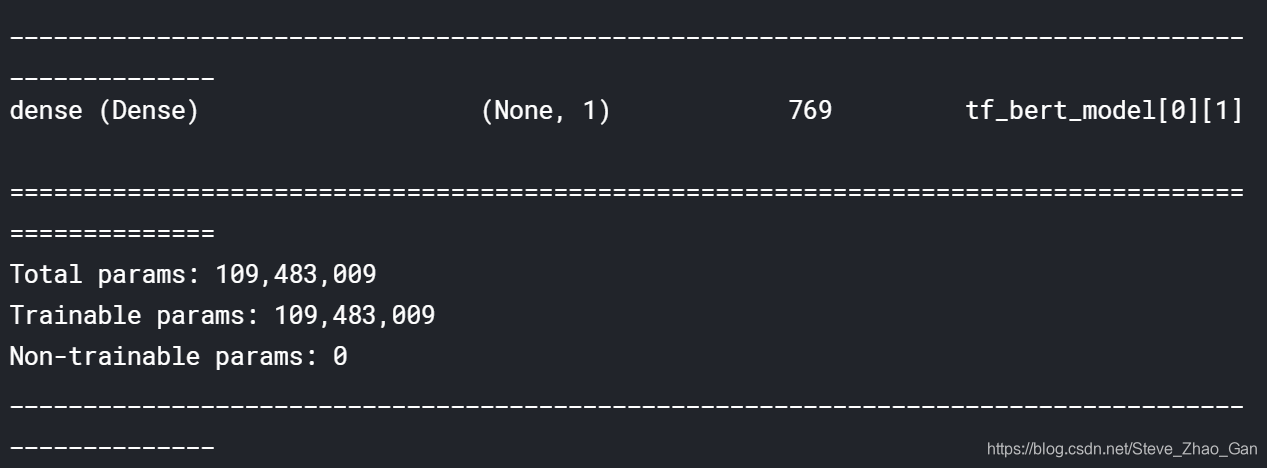
看看summarymodel.summary() 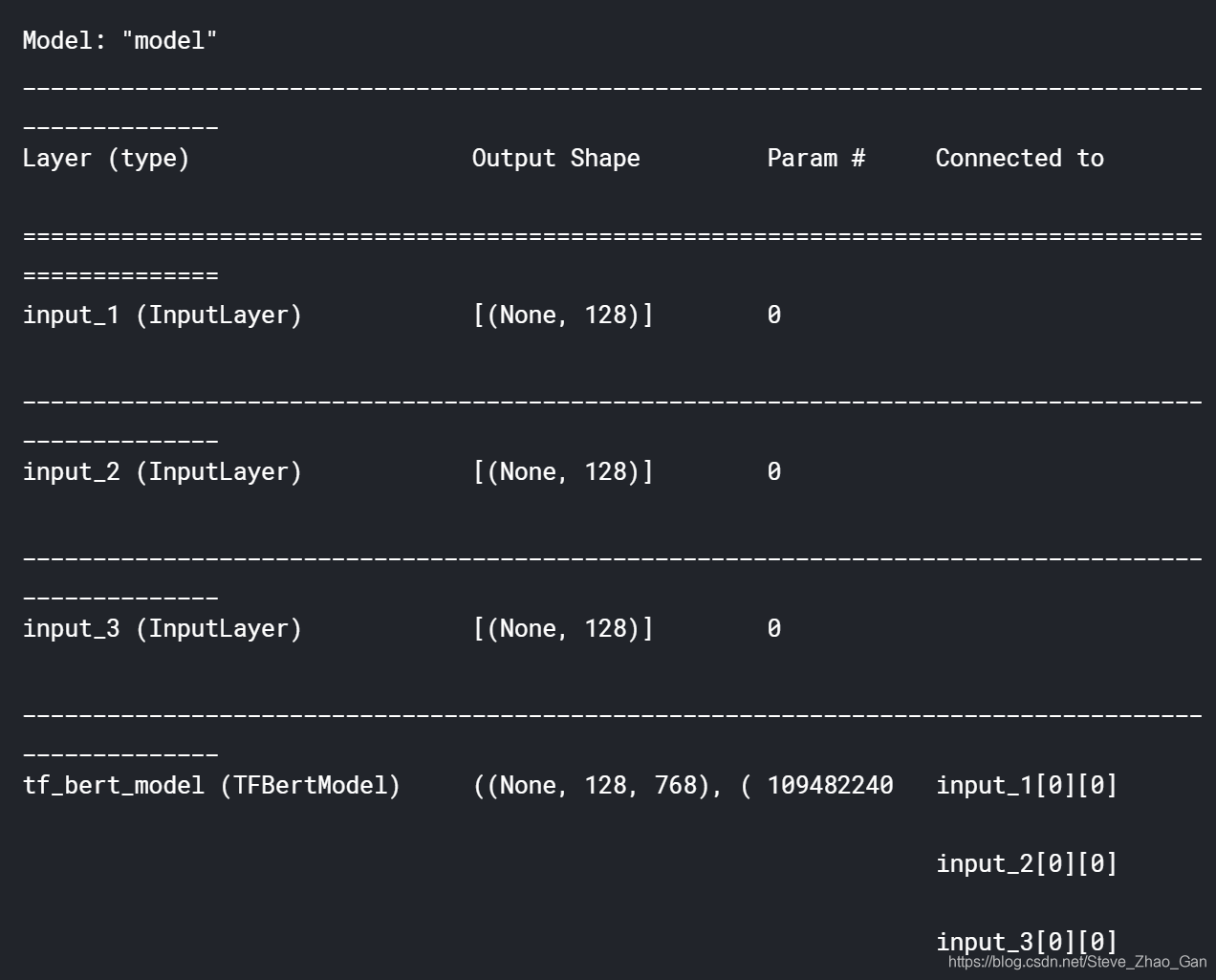
提交结果
# Use the model to do prediction y_pred = model.predict([test_input_ids,test_attension_mask,test_token_type_ids],batch_size=BATCH_SIZE,verbose=1).ravel() y_pred = (y_pred>=0.5).astype(int) # Export to submission submission = pd.read_csv("../input/nlp-getting-started/sample_submission.csv") submission['target'] = y_pred submission.to_csv('nlp_prediction.csv',index=False)

具体流程可以参阅我们的kaggle网页https://www.kaggle.com/lilstarboy/pig-budt758b-project-notebook?scriptVersionId=33280711
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









