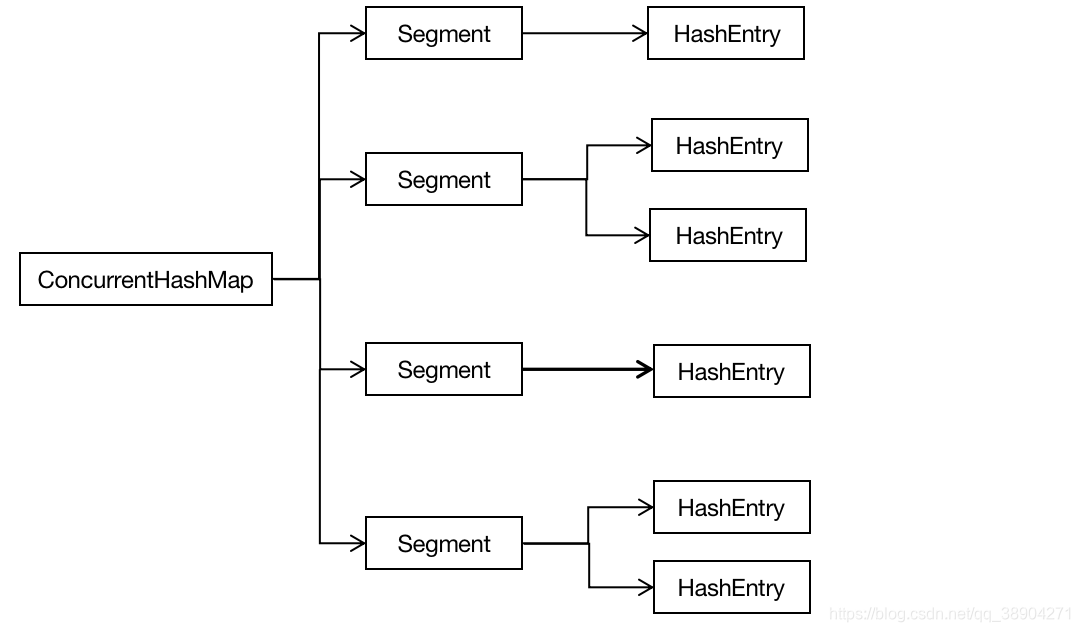
ConcurrentHashMap是并发工具包的集合不同于HashMap,HashMap它是一个线程不安全的集合而ConcurrentHashMap是一个线程安全的集合。 Hashtable跟HashMap在源代码的实现上是差不多一样的,但它是线程安全的因为HashTable的每一个方法都上锁了。HashTable锁了方法导致HashTable只有一把锁而这把锁就是HashTable的对象,所以HashTable的并发量低。 为了实现线程安全以及高并发的需求就有了ConcurrentHashMap,ConcurrentHashMap主要思想是分段锁也就是一个ConcurrentHashMap拥有多个锁。每一把锁锁一段数据,这样在多线程访问时不同段的数据时,就不会存在锁竞争提高了程序并发量。 JDK1.7及以前:数组+链表+分段锁+Segment JDK1.8:参考了JDK1.8 HashMap的实现,使用了数组+链表+红黑树内部使用CAS操作。(详情:HashMap源代码分析及相关问题) 既然JDK1.8 ConcurrentHashMap的实现是参考了JDK 1.8 HashMap的所以我们就不多说了点击上面的链接就可以查看HashMap的相关内容。 接下来我们主要来介绍一下JDK1.7 ConcurrentHashMap的实现。 从结构图中可以知道ConcurrentHashMap维护着多个Segment,而每个Segment则至少维护一个HashEntry。 从源代码上看,Segment 继承了 ReentrantLock,它是一种可重入锁。在对ConcurrentHashMap进行put等操作时会对key进行hash再hash,第一次hash则确定键值对将由哪一把锁进行管理第二次hash则确定键值对将存放在HashEntry的哪个槽点。所以在并发环境下,对于不同 Segment 的数据进行操作是不用考虑锁竞争的。就按默认的 ConcurrentLevel 为 16 来讲,理论上就允许 16 个线程并发执行。 get操作是ConcurrentHashMap中最高效的,因为get的过程并不需要争夺锁除非读到的值为空才会加锁重新读取。 为了让get到的数据被及时感知使用了volatile来增加可见性。 进行put操作时会对key进行hash再hash,第一次hash则确定键值对将由哪一把锁进行管理第二次hash则确定键值对将存放在HashEntry的哪个槽点。如果占据的槽点到达阀值HashEntry将会进行扩容,扩容扩成原来的两倍。 每个Segment都有一个是volatile的count变量,获取整个ConcurrentHashMap的大小时有可能某个Segemnt进行了操作导致count发生了变化从而得到的大小不准确。
ConcurrentHashMap实现:
ConcurrentHashMap结构图:
ConcurrentHashMap的操作:
get操作
put操作
size操作

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









