(1)解决乱码问题 说明:1.该数据来自搜狗实验室 数据下载地址 这个案例只需要Mapper类和Driver类即可 Driver类 (如何打jar包和上传jar包这里不在赘述) 4个文件的中数据都聚合在了这一个文件里 year ,month ,day 为分区字段 导入语句 数据已经成功的分区 1.本案例总体上比较简单
搜狗用户查询日志分析综合案例
一.MapReduce数据清洗
1.数据清洗要求
(2)过滤少于6个字段的行
(3)统一字段之间的分隔符(统一用逗号)
(3)在每行前添加年,月,日字段。
清洗前的数据
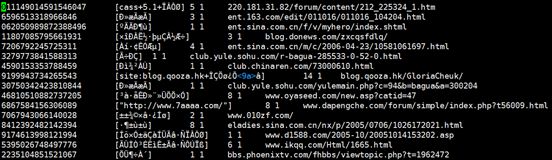
清洗后的数据

2.准备原始数据
2.年月日三个字段在文件名中
3.该数据已经上传到HDFS
3.代码详解
Mapper类package xiexianyouSogouLogClean; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.tracing.SpanReceiverInfo; import java.io.IOException; import java.util.ArrayList; import java.util.regex.Matcher; import java.util.regex.Pattern; public class SogouCleanMapper extends Mapper<LongWritable, Text, Text, NullWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 将value数据转换成bytes数组 byte[] bytes = value.getBytes(); // 获取数组的长度 int length = bytes.length; // 将bytes数组根据gbk编码解码成字符串 // 每次转换一行 String line = new String(bytes, 0, length, "gbk"); //将每行数据根据正则表达式分隔成数组 s+ 代表一个或多个空白符 String[] words = line.split("\s+"); //过滤掉不足6个字段的行 if (words.length != 6) { // return代表直接结束本行操作 return; } //通过上下文对象,获取当前文件名 InputSplit inputSplit = (InputSplit) context.getInputSplit(); String filename = ((FileSplit) inputSplit).getPath().getName(); //根据文件名获取时间,使用正则表达式 Pattern compile = Pattern.compile("\d+"); Matcher matcher = compile.matcher(filename); if (matcher.find()){ //取出文件名中的日期 String time = matcher.group(); //将time转换成 2006,08,04 这种类型 char[] chars = time.toCharArray(); ArrayList<Character> list = new ArrayList<>(); String newString = ""; // 遍历这个char数组,将元素添加到list中 for (int i = 0; i < chars.length; i++) { list.add(chars[i]); switch (i) { case 3 : list.add(','); break; case 5 : list.add(','); break; } } //将list 每个元素拼接成字符串 for (Character character : list) { newString += character; } //将当前时间添加到words数组的第一个位置 String id = words[0]; words[0] = newString + "," + id; } // 将每行的数组根据 , 组合成字符串 // join是String类中的静态方法,可以直接类名.方法调用 String newline = String.join(",", words); //将处理好的数据传输到下一阶段 //new Text(newline)将String转换成hadoop中的数据类型 Text //NullWritable.get()返回该类的单个实例 context.write(new Text(newline), NullWritable.get()); } } package xiexianyouSogouLogClean; import hiveMapReduce.hiveDriver; import hiveMapReduce.hiveMapper; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.io.IOException; public class SogouCleanDriver { public static void main(String[] args) throws Exception { // 创建一个configuration对象 Configuration conf = new Configuration(); // 根据配置文件创建job对象 // 这里需要抛出异常 Job job = Job.getInstance(conf); // SogouCleanDriver.class 表示获取SogouCleanDriver对象 job.setJarByClass(SogouCleanDriver.class); job.setMapperClass(SogouCleanMapper.class); //设置输入格式和输出格式 job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); // 设置输出键值对类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 获取输出路径 Path path=new Path(args[1]); FileSystem fileSystem=path.getFileSystem(conf); // 判断输出路径是否存在,存在则删除 if (fileSystem.exists(path)){ fileSystem.delete(path,true); } // 设置输出路径和输入路径 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); //提交 boolean result = job.waitForCompletion(true); if (result) { System.out.print("牛逼"); } } } 4.打jar包上传到集群运行

5.运行jar包

6.查看结果文件


二.导入数据到hive仓库
1.创建存放数据的临时表
create table sogou2_test( year int, month int, day int, userid string, keyword string, rank int, clickid int, url string, detail string) row format delimited fields terminated by','; 
2.创建动态分区表
create table sogou2( userid string, keyword string, rank int, clickid int, url string, detail string) partitioned by(year int,month int,day int) row format delimited fields terminated by','; 
3.将临时表sogou2_test数据导入sogou2
注意:字段不能用 * 代替,分区字段应该写最后。insert into sogou2 partition(year,month,day) select userid,keyword,rank,clickid,url,detail,year,month,day from sogou2_test; 
4.查看导入情况
文件夹大小不知道为什么显示 0 但是里面的文件中的的确确有数据。




5.查看分区中的数据

三.总结
2.难点在于如何获取到文件名中的日期
3.本题解法不唯一,如果有更好的解法,欢迎大佬到评论区讨论
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









