一、实验概述: 【实验目的】 【实验要求】 【实施环境】(使用的材料、设备、软件) 二、实验内容 第1题 Spark计算环境搭建 【实验结果】(步骤、记录、数据、程序等) 回答: 1).搭建spark计算环境 第2题 Spark环境下的Pi值计算 【实验结果】(步骤、记录、数据、程序等) 回答: 第3题 Spark环境下的WordCount计算实验 【实验结果】(步骤、记录、数据、程序等) 回答: 第4题 Spark SQL计算实验 【实验结果】(步骤、记录、数据、程序等) 回答: 2.1 启动spark shell 2.2 创建dataFrame 第5题 Spark Streaming计算实验 【实验结果】(步骤、记录、数据、程序等) 回答: 第6题 Spark的基本机器学习计算实验(选做) 【实验内容】 结合课程讲授视频和其它相关资料,调用SparkMLLib库相应的API,实现KMeans的聚类计算。 【实验结果】(步骤、记录、数据、程序等) 回答:
Linux操作系统环境,VirtualBox虚拟机,Hadoop、Spark等程序。
【实验内容】
(1) 参考课程实验教材和Spark官网资料,在Linux系统中搭建Spark计算环境;
(2) 选择Scala或Python语言,搭建编程环境。
请提供相应界面截图证明。
1.进入spark官网,下载安装包
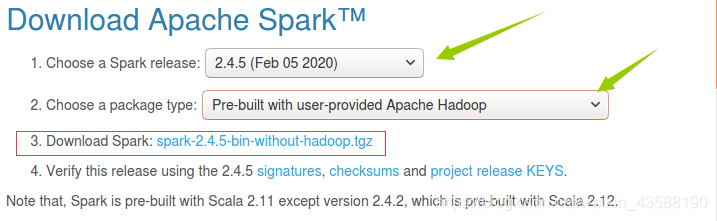
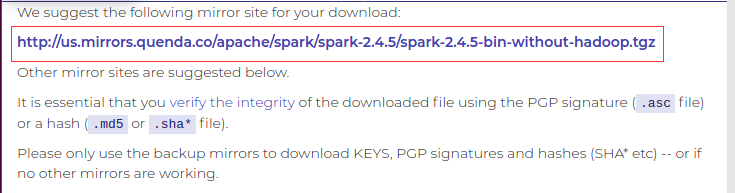
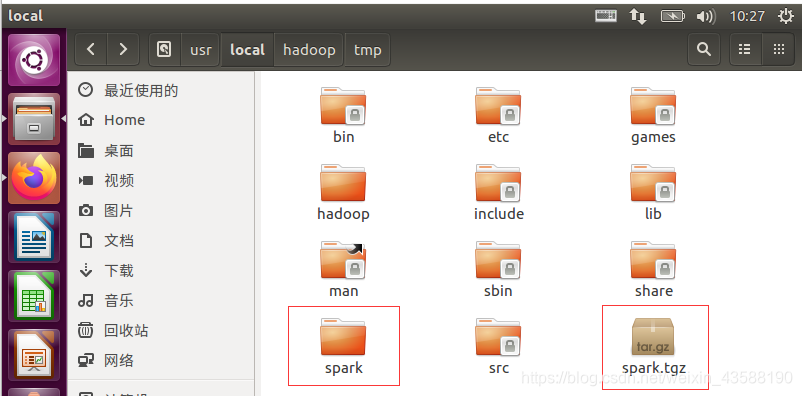
2.将解压后的文件夹重命名为spark,并授权,保存配置备份文件



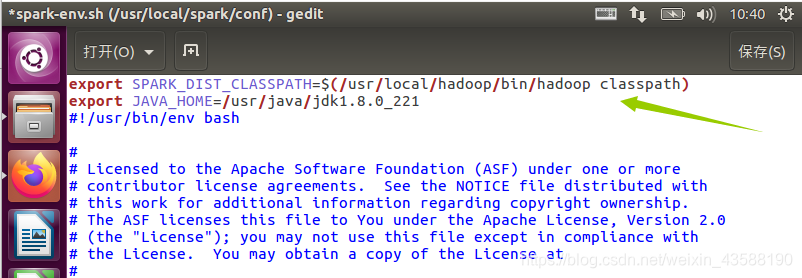
3.修改配置文件

4.验证是否安装成功

通过grep命令过滤筛选信息

启动spark shell

5.测试并退出
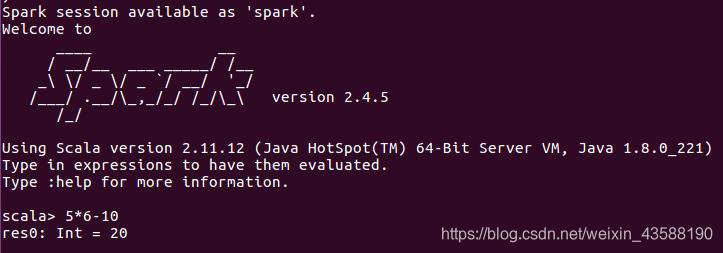

【实验内容】
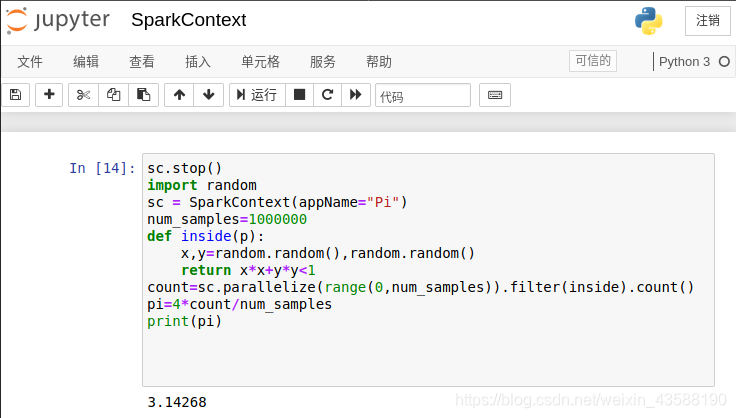
(1) 使用Spark shell的自带示例程序SparkPi,计算圆周率;
(2) 使用Scala或Python语言,编程实现圆周率Pi的计算。
请提供相应Shell界面、程序代码和运行效果截图证明。
1).安装python及jupyter
①安装aptitude

②安装python3及第三方工具


③python安装成功

④安装jupyter及findspark


⑤启动jupyter

2).使用shell命令计算

3).使用python计算
在jupyter notebook中桌面目录下新建python3程序
【实验内容】
使用使用Scala或Python语言,读取Linux系统中的任意文本文件,编程实现Spark环境下的WordCount计算。
请提供相应程序代码和运行效果截图证明。
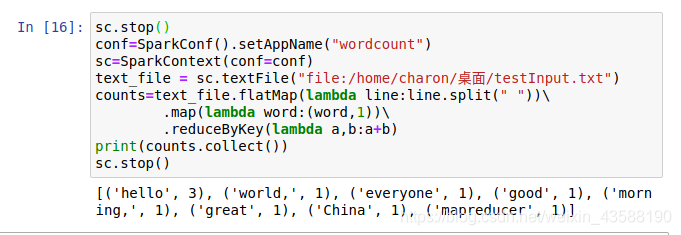
【实验内容】
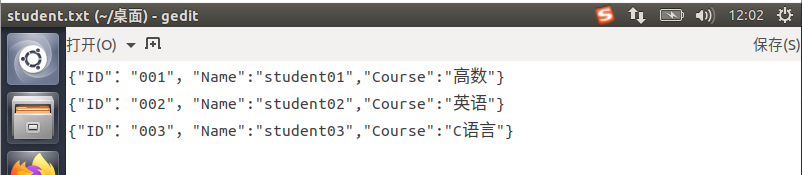
(1) 在Linux环境下建立包含“学号(ID)”、“姓名(Name)”、“课程(Course)”的JSON文件,并录入相应数据;
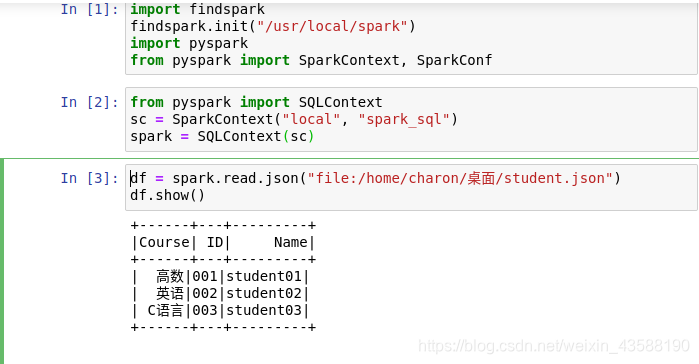
(2) 使用Spark SQL编程读取上述JSON文件,并显示其中内容;
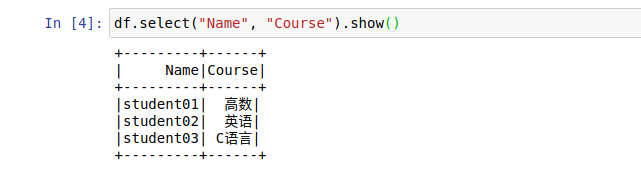
(3) 使用SparkSQL编程实现从上述JSON文件中选择并显示“姓名”和“课程”相应信息;
(4) 使用SparkSQL编程实现从上述JSON文件中按“姓名”的groupBy操作;
(5) 使用Spark SQL将上述JSON文件中内容封装为临时视图,并调用SQL语句执行数据检索,返回所有的数据。
请提供相应程序界面截图证明。
1 在桌面新建student.txt,在录入相关数据后将后缀名改为.json
2.启动jupyter notebook,在桌面新建python3程序,命名为experiment05
显示姓名和课程
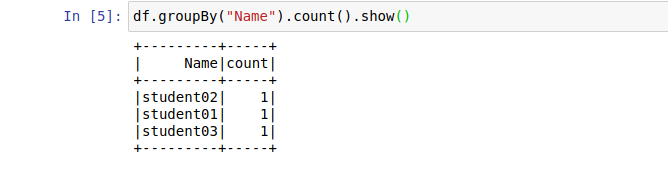
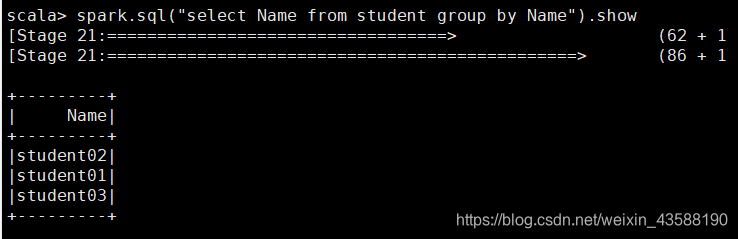
按姓名的groupBy操作
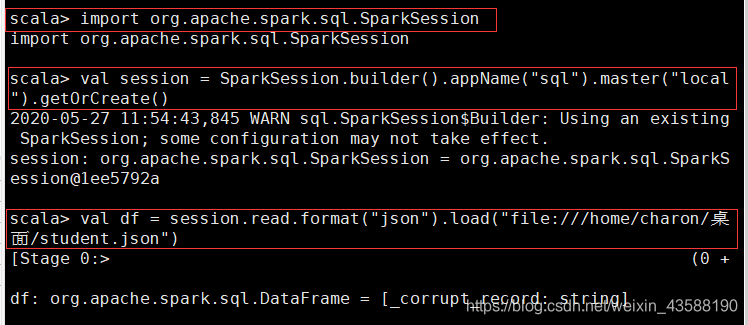
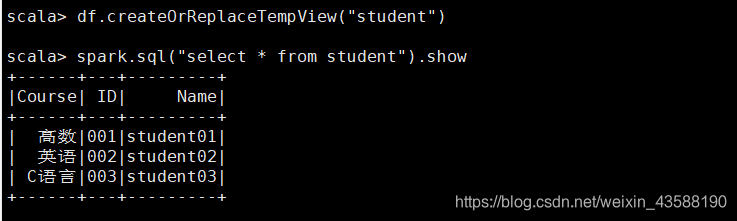
设置临时视图
以下为scala实现
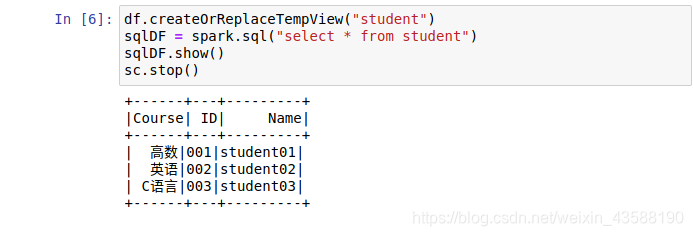
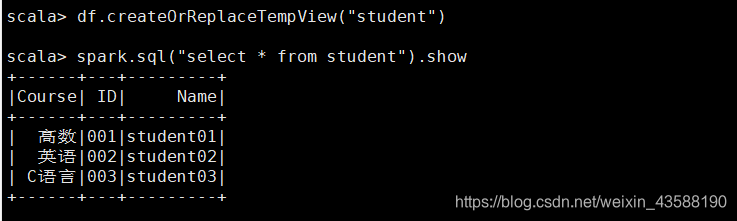
2.3 定义一个临时表student并查询所有数据
3 显示名称和科目
4 根据名称排序
【实验内容】
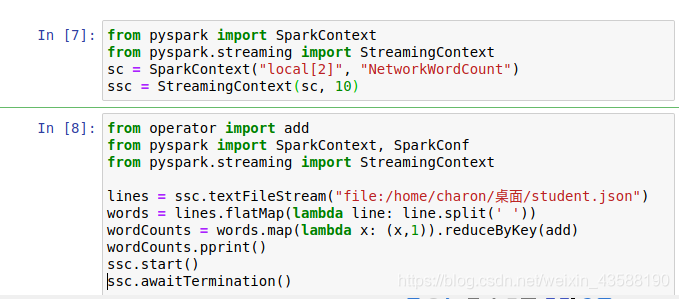
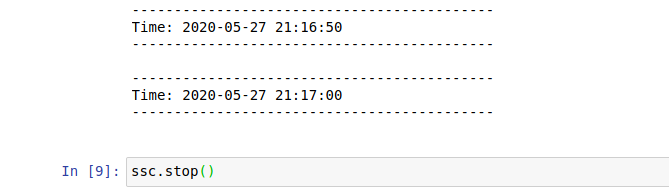
使用Spark Streaming,编程实现针对Linux某一目录下文件流的WordCount计算。
请提供相应程序和运行界面截图证明。
请提供相应代码和运行界面截图证明。
1.在桌面新建txt文档

2.安装numpy

3.
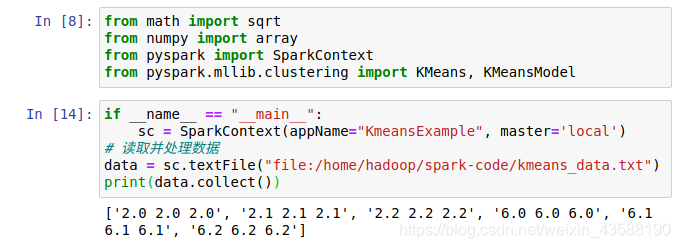
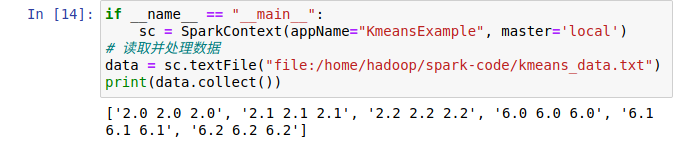
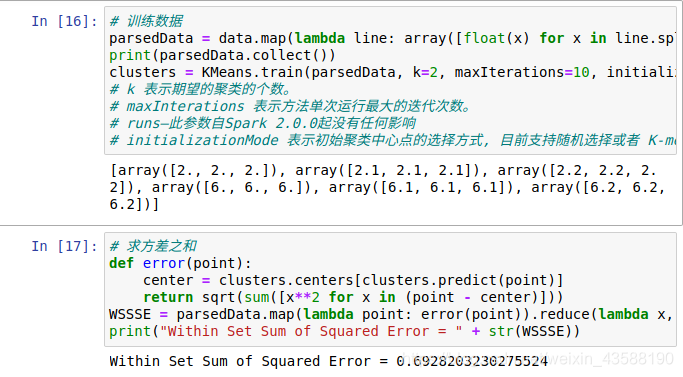
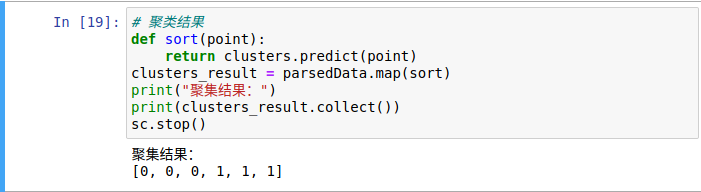
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









