Linux/Window 10 + Scrapy 1.7.4 借助scrapy框架采集数据时,采集完第一条数据后,卡住不动,6,7分钟之后才开始采集下一条,如下图。 针对单个脚本进行配置: 如此设置之后,本该若是请求时间超过60秒,就会报异常,异常机制是会再次发起请求的,但是卡住不动,异常也无法获取。 上面的设置都不起作用,没法,又去翻了一遍scrapy文档 转载请注明转自:https://leejason.blog.csdn.net/article/details/106380324
1.运行环境:
2.问题描述:

还有间隔10几分钟的,没截到图,就放了这张图意思意思。若是一直这样超时不报异常,无法触发异常机制再次发起请求,就会导致采集效率太低了。
其实按道理在settings.py中设置:DOWNLOAD_TIMEOUT = 60 custom_settings = { 'DOWNLOAD_TIMEOUT': 60, } 3.解决方法:
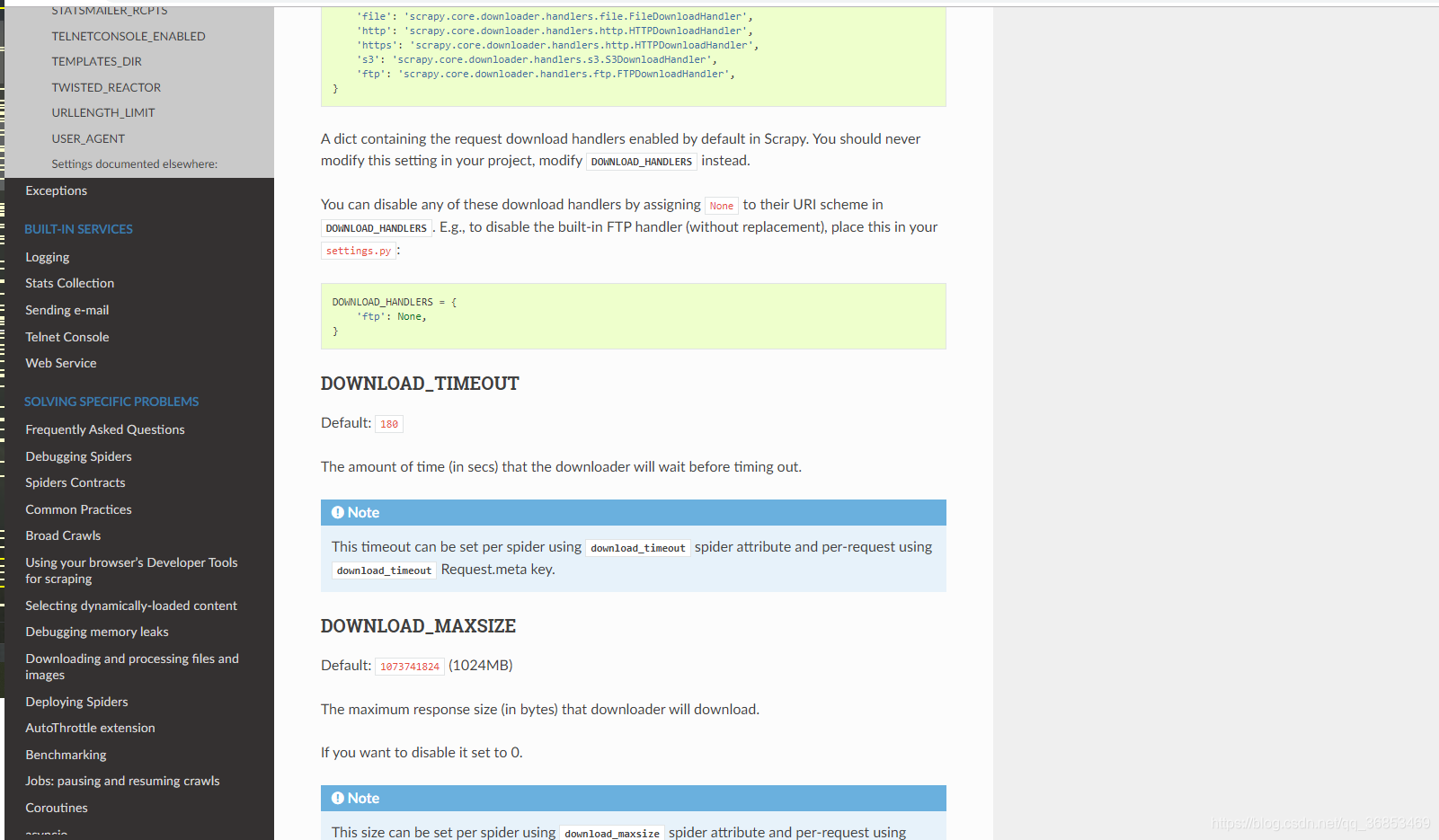
然而

走投无路之下尝试用meta携带download_timeout到相应请求中,结果惊讶的发现,起作用了。超时之后成功触发异常,这…

是的,就是下面这行代码,解决了这个问题:meta={'download_timeout': 60}  就很纳闷,为什么明明设置了全局超时控制,却不起作用,还得另外单独设置。。。
就很纳闷,为什么明明设置了全局超时控制,却不起作用,还得另外单独设置。。。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









