经检查,数据集之间的值没有独自特有的,可以放心使用 数字特征归一化对LR模型没有影响??? 归一化都无效,可能跟实际情况相关;有效无效,得从训练速度+测试结果来衡量。 归一化的价值在于两点:(1)提升训练速度;(2)克服特征淹没问题。 特征淹没,一般存在与线性模型中;树模型,各个特征不同时使用,可能真不存在特征淹没问题
1. 导入工具包
%matplotlib inline import numpy as np import matplotlib.pyplot as plt plt.rcParams['figure.facecolor']=(1,1,1,1) # pycharm 绘图白底,看得清坐标 import pandas as pd import seaborn as sns from sklearn import preprocessing from sklearn.linear_model import LinearRegression as lr from sklearn.ensemble import RandomForestRegressor as rf from sklearn.model_selection import train_test_split,cross_val_score from sklearn.metrics import * from sklearn.preprocessing import OneHotEncoder,LabelEncoder,OrdinalEncoder 2. 读取数据
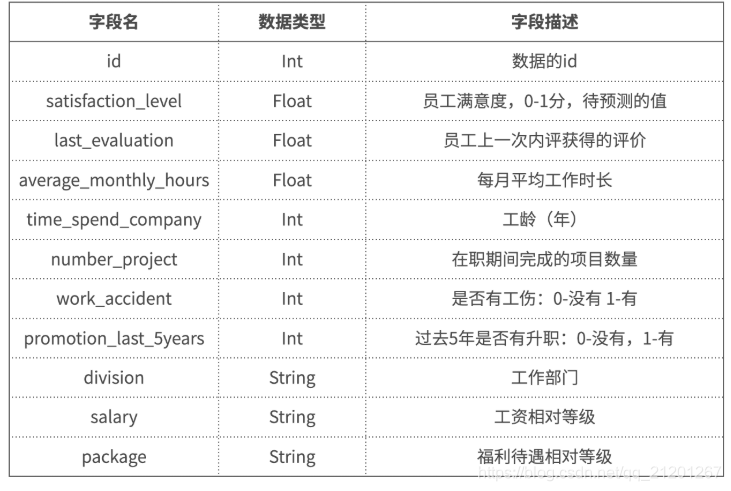
# 读取数据 tr_data = pd.read_csv("train.csv",index_col='id') X_test = pd.read_csv("test.csv",index_col='id') # test不含标签 tr_data.head(10) tr_data.corr() # 相关系数 sns.regplot(x=tr_data.index, y=tr_data['satisfaction_level']) 
可以看出 上一次的评分、有没有工伤、过去5年有没有晋升 跟 满意度 呈正相关系数
可以看出 id 跟满意度,没有特别强的关系,可以不作为特征3. 特征处理
# X丢弃标签 X = tr_data.drop(['satisfaction_level'], axis=1) y = tr_data['satisfaction_level'] # 切分数据 X_train, X_valid, y_train, y_valid = train_test_split(X, y,test_size=0.2,random_state=1) # 特征列名 feature = X_train.columns print(feature) # 查看文字特征列 s = (X_train.dtypes == 'object') object_cols = list(s[s].index) print(object_cols) # 查看标签数据 y_train # 查看标签值,是一系列的浮点数 pd.unique(y_train) 3.1 数字特征归一化
# 数字特征,丢弃文字特征列 num_X_train = X_train.drop(object_cols, axis=1) num_X_valid = X_valid.drop(object_cols, axis=1) num_X_test = X_test.drop(object_cols, axis=1) # 定义归一化转换器 X_scale = preprocessing.StandardScaler() X_scale.fit_transform(num_X_train) # 转化后的数据是 numpy 数组 num_X_train_data = X_scale.fit_transform(num_X_train) num_X_valid_data = X_scale.transform(num_X_valid) num_X_test_data = X_scale.transform(num_X_test) # 转换后的 numpy 数组,转成 pandas 的 DataFrame num_X_train_scale = pd.DataFrame(num_X_train_data) # 特征列名称也要重新填上 num_X_train_scale.columns = num_X_train.columns num_X_valid_scale = pd.DataFrame(num_X_valid_data) num_X_valid_scale.columns = num_X_valid.columns num_X_test_scale = pd.DataFrame(num_X_test_data) num_X_test_scale.columns = num_X_test.columns # index 丢失,重新赋值 num_X_train_scale.index = num_X_train.index num_X_valid_scale.index = num_X_valid.index num_X_test_scale.index = num_X_test.index 3.2 文字特征处理
# 检查是否有列中,数据集之间的值的种类有差异,防止编码transform出错,经检查没有bad good_label_cols = [col for col in object_cols if set(X_train[col]) == set(X_valid[col])] # Problematic columns that will be dropped from the dataset bad_label_cols = list(set(object_cols)-set(good_label_cols)) good_label_cols = [col for col in object_cols if set(X_train[col]) == set(X_test[col])] # Problematic columns that will be dropped from the dataset bad_label_cols = list(set(object_cols)-set(good_label_cols)) # 文字特征 cat_X_train = X_train[good_label_cols] cat_X_valid = X_valid[good_label_cols] cat_X_test = X_test[good_label_cols] # 文字特征转换成数字特征 labEncoder = LabelEncoder() for f in set(good_label_cols): cat_X_train[f] = labEncoder.fit_transform(cat_X_train[f]) cat_X_valid[f] = labEncoder.transform(cat_X_valid[f]) cat_X_test[f] = labEncoder.transform(cat_X_test[f]) 3.3 特征合并
# 同样的,index需要重新赋值,不操作此步,合并后的数据由于index不一样,行数变多 cat_X_train.index = X_train.index X_train_final = pd.concat([num_X_train_scale, cat_X_train], axis=1) cat_X_valid.index = X_valid.index X_valid_final = pd.concat([num_X_valid_scale, cat_X_valid], axis=1) cat_X_test.index = X_test.index X_test_final = pd.concat([num_X_test_scale, cat_X_test], axis=1) 4. 定义模型训练
model1 = rf(n_estimators=100) model1.fit(X_train_final, y_train) # cross_val_score(model1,X_train_final,y_train,cv=10,scoring='neg_mean_squared_error') y_pred_valid = model1.predict(X_valid_final) mean_absolute_error(y_pred_valid, y_valid) # 验证集上的误差 0.1364085458333333 5. 预测
y_pred_test = model1.predict(X_test_final) result = pd.DataFrame() result['id'] = X_test.index result['satisfaction_level'] = y_pred_test result.to_csv('firstsubmit.csv',index=False) 6. 新人赛结果
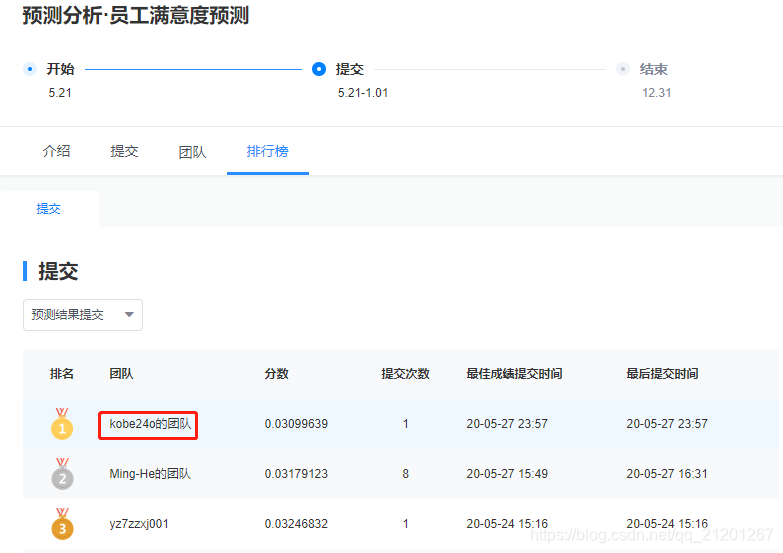
Public分数
版本变化
0.030955617695980337
数字特征无归一化,随机森林n=100
0.03099638771607572
数字特征归一化,随机森林n=100
0.05741940132765499
数字特征无归一化,逻辑斯谛回归
0.05741940132765499
数字特征归一化,逻辑斯谛回归
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 31
31