@本文来源于公众号:csdn2299,喜欢可以关注公众号 程序员学府 datetime以毫秒形式存储日期和时间,datetime.timedelta表示两个datetime对象之间的时间差。 下面我们先简单的了解下python日期和时间数据类型及工具 给datetime对象加上或减去一个或多个timedelta,会产生一个新的对象 datetime模块中的数据类型 日期转换成字符串:利用str 或strftime 字符串转换成日期: pandas通常用于处理成组日期,不管这些日期是DataFrame的轴索引还是列,to_datetime方法可以解析多种不同的日期表示形式。 datetime 格式定义 pandas最基本的时间序列类型就是以时间戳(时间点)(通常以python字符串或datetime对象表示)为索引的Series: pandas不同索引的时间序列之间的算术运算会自动按日期对齐 方法: 2)[一个可以被解析为日期的字符串] 3)对于,较长的时间序列,只需传入‘年’或‘年月’可返回对应的数据切片 4)通过时间范围进行切片索引 1).index.is_unique检查索引日期是否是唯一的 2)对非唯一时间戳的数据进行聚合,通过groupby,并传入level = 0(索引的唯一一层) 1)字符串、日期的转换方法 2)日期和时间的主要python,datetime、timedelta、pandas.to_datetime等 3)以时间为索引的Series和DataFrame的索引、切片 4)带有重复时间索引时的索引,.groupby(level=0)应用 没办法的事,只能后天弥补,于是在编码之外开启了自己的逆袭之路,不断的学习python核心知识,深 入的研习计算机基础知识,整理好了,我放在我们的微信公众号《程序员学府》,如果你也不甘平庸,之外的东西,比如,如何做一个精致的程序员,而不是“屌丝”,程序员本身就是高贵的一种存在啊,难道不是吗?[点击加入]想做你自己想成为高尚人,加油!
python标准库包含于日期(date)和时间(time)数据的数据类型,datetime、time以及calendar模块会被经常用到。rom datetime import datetime from datetime import timedelta now = datetime.now() now datetime.datetime(2017, 6, 27, 15, 56, 56, 167000) datetime参数:datetime(year, month, day[, hour[, minute[, second[, microsecond[,tzinfo]]]]]) delta = now - datetime(2017,6,27,10,10,10,10) delta datetime.timedelta(0, 20806, 166990) delta.days 0 delta.seconds 20806 delta.microseconds 166990 
字符串和datetime的相互转换
1)python标准库函数
datetime.strptime stamp = datetime(2017,6,27) str(stamp) '2017-06-27 00:00:00' stamp.strftime('%y-%m-%d')#%Y是4位年,%y是2位年 '17-06-27' #对多个时间进行解析成字符串 date = ['2017-6-26','2017-6-27'] datetime2 = [datetime.strptime(x,'%Y-%m-%d') for x in date] datetime2 [datetime.datetime(2017, 6, 26, 0, 0), datetime.datetime(2017, 6, 27, 0, 0)] 2)第三方库dateutil.parser的时间解析函数
from dateutil.parser import parse parse('2017-6-27') datetime.datetime(2017, 6, 27, 0, 0) parse('27/6/2017',dayfirst =True) datetime.datetime(2017, 6, 27, 0, 0) 3)pandas处理成组日期
date ['2017-6-26', '2017-6-27'] import pandas as pd pd.to_datetime(date) DatetimeIndex(['2017-06-26', '2017-06-27'], dtype='datetime64[ns]', freq=None) 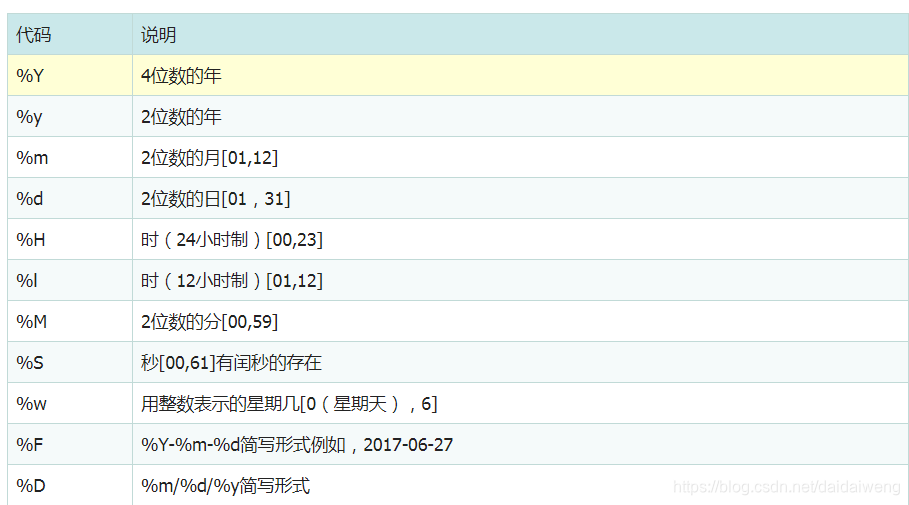
pandas时间序列基础以及时间、日期处理
dates = ['2017-06-20','2017-06-21', '2017-06-22','2017-06-23','2017-06-24','2017-06-25','2017-06-26','2017-06-27'] import numpy as np ts = pd.Series(np.random.randn(8),index = pd.to_datetime(dates)) ts 2017-06-20 0.788811 2017-06-21 0.372555 2017-06-22 0.009967 2017-06-23 -1.024626 2017-06-24 0.981214 2017-06-25 0.314127 2017-06-26 -0.127258 2017-06-27 1.919773 dtype: float64 ts.index DatetimeIndex(['2017-06-20', '2017-06-21', '2017-06-22', '2017-06-23', '2017-06-24', '2017-06-25', '2017-06-26', '2017-06-27'], dtype='datetime64[ns]', freq=None) ts[::2]#从前往后每隔两个取数据 2017-06-20 0.788811 2017-06-22 0.009967 2017-06-24 0.981214 2017-06-26 -0.127258 dtype: float64 ts[::-2]#从后往前逆序每隔两个取数据 2017-06-27 1.919773 2017-06-25 0.314127 2017-06-23 -1.024626 2017-06-21 0.372555 dtype: float64 ts + ts[::2]#自动数据对齐 2017-06-20 1.577621 2017-06-21 NaN 2017-06-22 0.019935 2017-06-23 NaN 2017-06-24 1.962429 2017-06-25 NaN 2017-06-26 -0.254516 2017-06-27 NaN dtype: float64 索引为日期的Series和DataFrame数据的索引、选取以及子集构造
1).index[number_int]ts 2017-06-20 0.788811 2017-06-21 0.372555 2017-06-22 0.009967 2017-06-23 -1.024626 2017-06-24 0.981214 2017-06-25 0.314127 2017-06-26 -0.127258 2017-06-27 1.919773 dtype: float64 ts[ts.index[2]] 0.0099673896063391908 ts['2017-06-21']#传入可以被解析成日期的字符串 0.37255538918121028 ts['21/06/2017'] 0.37255538918121028 ts['20170621'] 0.37255538918121028 ts['2017-06']#传入年或年月 2017-06-20 0.788811 2017-06-21 0.372555 2017-06-22 0.009967 2017-06-23 -1.024626 2017-06-24 0.981214 2017-06-25 0.314127 2017-06-26 -0.127258 2017-06-27 1.919773 dtype: float64 ts['2017-06-20':'2017-06-23']#时间范围进行切片 2017-06-20 0.788811 2017-06-21 0.372555 2017-06-22 0.009967 2017-06-23 -1.024626 dtype: float64 带有重复索引的时间序列
dates = pd.DatetimeIndex(['2017/06/01','2017/06/02','2017/06/02','2017/06/02','2017/06/03']) dates DatetimeIndex(['2017-06-01', '2017-06-02', '2017-06-02', '2017-06-02', '2017-06-03'], dtype='datetime64[ns]', freq=None) dup_ts = pd.Series(np.arange(5),index = dates) dup_ts 2017-06-01 0 2017-06-02 1 2017-06-02 2 2017-06-02 3 2017-06-03 4 dtype: int32 dup_ts.index.is_unique False dup_ts['2017-06-02'] 2017-06-02 1 2017-06-02 2 2017-06-02 3 dtype: int32 grouped = dup_ts.groupby(level=0).mean() grouped 2017-06-01 0 2017-06-02 2 2017-06-03 4 dtype: int32 dup_df = pd.DataFrame(np.arange(10).reshape((5,2)),index = dates ) dup_df 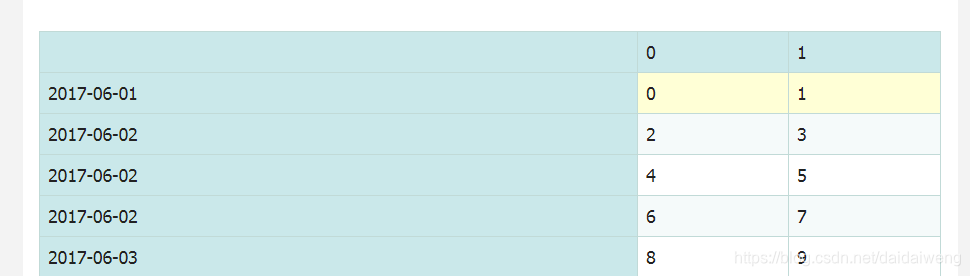
grouped_df = dup_df.groupby(level=0).mean()##针对DataFrame grouped_df 
本文总结了以下4个知识点
非常感谢你的阅读
大学的时候选择了自学python,工作了发现吃了计算机基础不好的亏,学历不行这是
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









