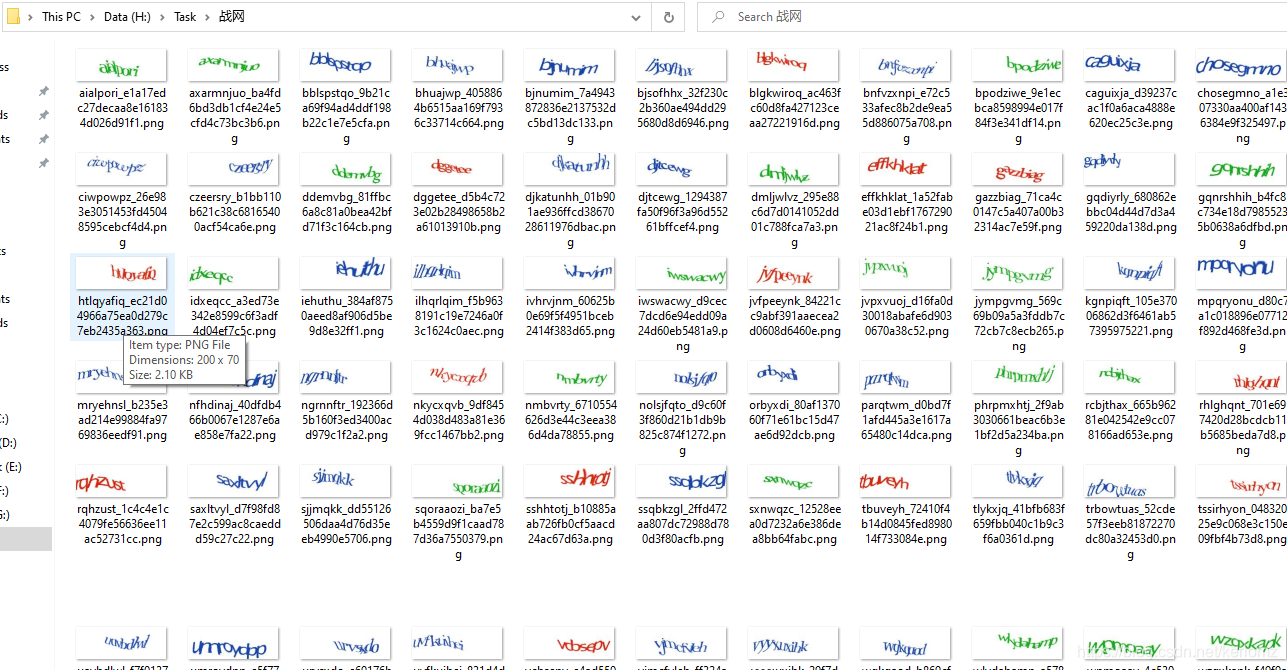
首先当然是采集图片了,对接通用模型上怼样本就是了。 采集代码有所省略,如下图所示,采集到正确标注的样本。 打开训练工具 部署项目:https://github.com/kerlomz/captcha_platform 对接官网测试结果: https://github.com/kerlomz/captcha_platform/releases 顺便宣传一波麻瓜OCR识别 喜欢的各位可以加QQ群:857149419
1. 样本采集
for i in range(100000): sess.headers = { "User-Agent": ua.random } sess.proxies = get_proxy() # print(get_proxy()) before_url = "https://www.battlenet.com.cn/login/zh/" before_resp = sess.get(before_url) before_html = Selector(before_resp.text) csrf_token = before_html.xpath('//input[@name="csrftoken"]/@value').extract_first() session_timeout = before_html.xpath('//input[@name="sessionTimeout"]/@value').extract_first() captcha_url = "https://www.battlenet.com.cn/login/captcha.jpg" captcha_resp = sess.get(captcha_url) captcha_bytes = captcha_resp.content print(captcha_bytes) captcha_text = requests.post("https://127.0.0.1:19952/captcha/v3", data=captcha_bytes).json()['message'] payload = { "accountName": "00000", "password": ".", "srpEnabled": "true", "upgradeVerifier": "", "useSrp": "true", "publicA": public_a, "clientEvidenceM1": client_evidence_m1, "persistLogin": "on", "captchaInput": captcha_text, "csrftoken": csrf_token, "sessionTimeout": session_timeout } resp_submit = sess.post(before_url, data=payload) if "找不到该暴雪游戏通行证" in resp_submit.text: tag = hashlib.md5(captcha_bytes).hexdigest() name = "{}_{}.png".format(captcha_text, tag) print('正确') true_count += 1 with open(os.path.join(target_dir, name), "wb") as f: f.write(captcha_bytes) else: print('错误') false_count += 1 # print(before_resp.text) print(true_count+false_count, captcha_text, true_count / (true_count+false_count))
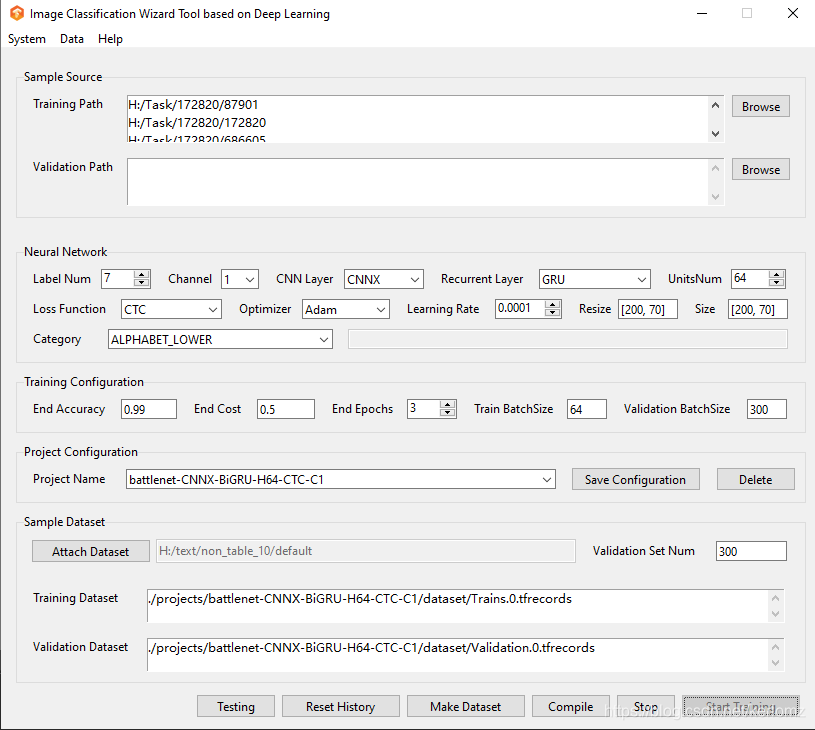
2. 训练
(地址:https://github.com/kerlomz/captcha_trainer)
具体教程可参考:https://www.jianshu.com/p/80ef04b16efc



验证码使用
编译版(一键部署):https://github.com/kerlomz/captcha_platform/releases
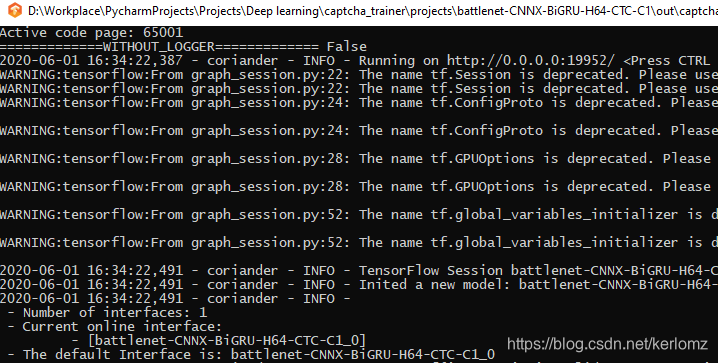
启动成功如图:
调用如图:
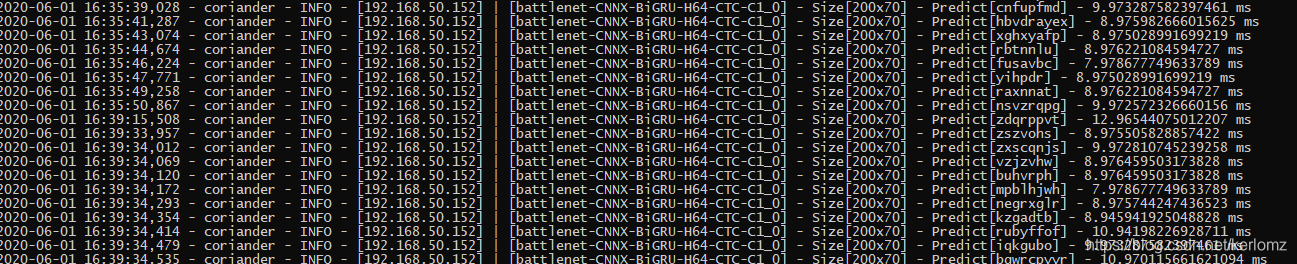
如图可见,单次识别速度在10ms以内,平均8ms,属业内领先水准。
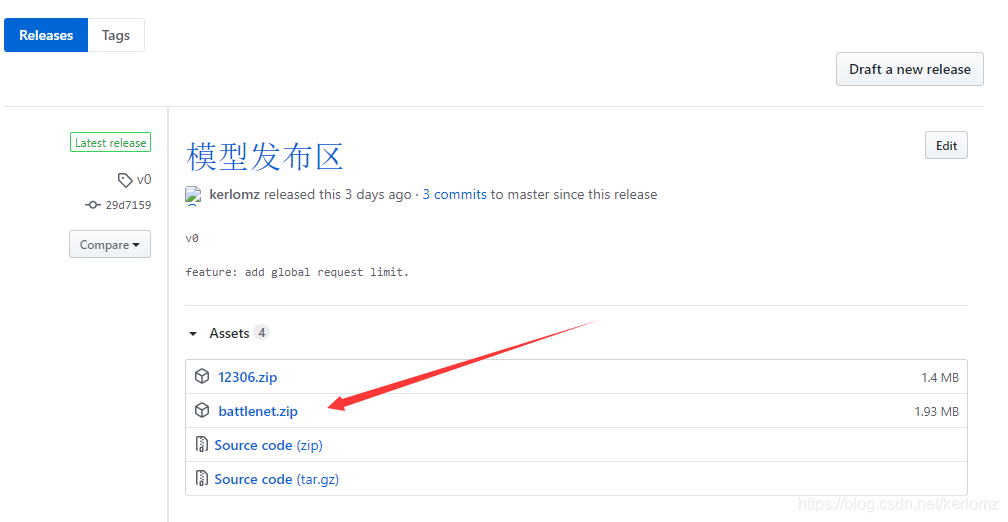
测了13次全对,识别率想必差不了。模型下载
后记
https://pypi.org/project/muggle-ocr/1.0/
这是一个OCR和验证码皆可识别的本地识别模块,使用简单,pip安装,三行代码即可调用。import time # 第一步:导入包 import muggle_ocr # 第二步:初始化;model_type 包含了 ModelType.OCR/ModelType.Captcha 两种 sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.OCR) # ModelType.Captcha 可识别光学印刷文本 with open(r"test1.png", "rb") as f: b = f.read() for i in range(5): st = time.time() # 第三步: 调用(识别普通OCR) text = sdk.predict(image_bytes=b) print(text, time.time() - st) # ModelType.Captcha 可识别4-6位验证码 sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha) with open(r"test2.jpg", "rb") as f: b = f.read() for i in range(5): st = time.time() # 第三步: 调用(识别验证码) text = sdk.predict(image_bytes=b) print(text, time.time() - st)
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









