本篇将干货~实践一下基于jieba,spacy, pyltp, lac, nltk, foolltk等开源库进行实(调)践(包)! 时间提取属于NLP中的实体命名识别,例如匹配时间,地点,物体,人物等等… 代码(有的代码未删除,功能不仅为单纯匹配时间。): 在实体命名识别中:jieba分词先导入所需库:import jieba.posseg as psg 再通过cut切割出不同标签的元素,然后进行通过标签筛选出想要的例如‘t’表示时间: 举个简单的例子,我们需要从下面的文本中提取时间: 6月28日,杭州市统计局权威公布《2019年5月月报》,杭州市医保参保人数达到1006万,相比于2月份的989万,三个月暴涨16万人参保,傲视新一线城市。 我们可以从文本有提取 接着,我们测试几个例子。 输入文本为: 今天,央行举行了2019年6月份金融统计数据解读吹风会,发布了2019年6月份金融统计数据并就当前的一些热点问题进行了解读和回应。 文本中提取的时间为: 输入文本为: 2006年,上海的国内生产总值达到10296.97亿元,是中国内地第一个GDP突破万亿元的城市。2008年,北京GDP破万亿。两年后,广州GDP超过万亿。2011年,深圳、天津、苏州、重庆4城的GDP也进入了万亿行列。武汉、成都在2014年跻身“万亿俱乐部”,杭州、南京和青岛、无锡和长沙的GDP依次在2015年、2016年和2017年过万亿。宁波和郑州则成为2018年万亿俱乐部的新成员。 文本中提取的时间为: 输入文本为: 此后,6月28日、7月9日和7月11日下午,武威市政协、市人大、市政府分别召开坚决全面彻底肃清火荣贵流毒和影响专题民主生活会。 文本中提取的时间为: 输入文本为: 姜保红出生于1974年4月,她于2016年11月至2018年9月任武威市副市长,履新时,武威市的一把手正是火荣贵。 文本中提取的时间为: 个人认为效果不错!尤其是在时间提取上。 这个Stanford CoreNLP的安装步骤也是挺麻烦的; 安装依赖 1:下载安装JDK 1.8及以上版本。 常用接口 StanfordCoreNLP官网给出了python调用StanfordCoreNLP的接口。 本教程以 使用pip安装 简单使用命令: 如果需要下载其他版本可以:比如:pip install stanfordcorenlp==3.7.0.2;如果不指定就直接下载最新版本;卸载的话:pip uninstall stanfordcorenlp 上代码: 方法跟上面的模型几乎一致,都是调包换参。学习阶段,调包侠嘛。 paddlehub的lac。在模型启动就特别快,除去模型启动时间,评价每秒识别文本8k字左右,相比斯坦福好很多,准确率也很高,我挺喜欢这个模型的,以后有能力将尝试进行二次开发,上代码: spacy现在支持jieba中文分词,后续介绍使用,强大的工具。
一、jieba
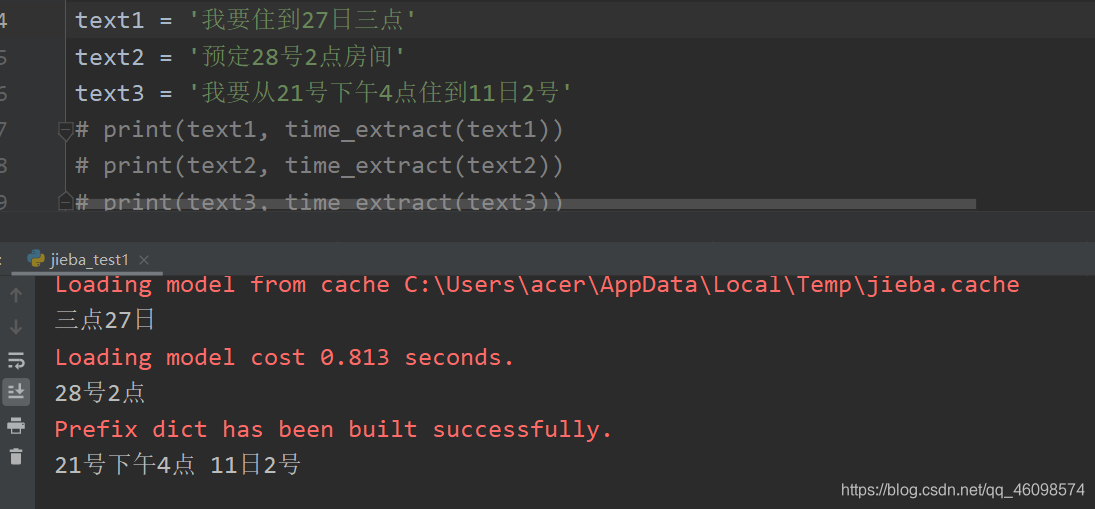
import re from datetime import datetime, timedelta from dateutil.parser import parse import jieba.posseg as psg def time_extract(text): time_res = [] word = '' keyDate = {'今天': 0, '明天': 1, '后天': 2} for k, v in psg.cut(text): if k in keyDate: if word != '': time_res.append(word) word = (datetime.today() + timedelta(days=keyDate.get(k, 0))).strftime('%Y年%m月%d日') elif word != '': if v in ['m', 't']: # print('*', word) word = word + k else: # print('**', word) time_res.append(word) word = '' elif v in ['m', 'k']: word = k if word != '': time_res.append(word) print(' '.join(time_res)) result = list(filter(lambda x: x is not None, [check_time_valid(w) for w in time_res])) final_res = [parse_datetime(w) for w in result] return [x for x in final_res if x is not None] def check_time_valid(word): """ 日期串有效性判断 :param word: :return: """ m = re.match("d+$", word) if m: if len(word) <= 6: return None wordl = re.sub('[号|日]d+$', '日', word) if wordl != word: return check_time_valid(wordl) else: return wordl def parse_datetime(msg): """ 对日期串进行时间转换 :param msg: :return: """ if msg is None or len(msg) == 0: return None try: dt = parse(msg, fuzzy=True) return dt.strftime('%Y-%m-%d %H:%M:%S') except Exception as e: m = re.search( r"([0-9零一二两三四五六七八九十]+年)?([0-9一二两三四五六七八九十]+月)?([0-9一二两三四五六七八九十]+[号日])?([上中下午晚早]+)?([0-9零一二两三四五六七八九十百]+[点:.时])?([0-9零一二三四五六七八九十百]+分?)?([0-9零一二三四五六七八九十百]+秒)?", msg ) if m.group(0) is not None: res = { "year": m.group(1), "month": m.group(2), "day": m.group(3), "hour": m.group(5) if m.group(5) is not None else '00', "minute": m.group(6) if m.group(6) is not None else '00', "second": m.group(7) if m.group(7) is not None else '00', } params = {} # print (res) for name in res: if res[name] is not None and len(res[name]) != 0: tmp = None if name == "year": tmp = year2dig(res[name]) else: tmp = cn2dig(res[name]) if tmp is not None: params[name] = int(tmp) target_data = datetime.today().replace(**params) is_pm = m.group(4) if is_pm is not None: if is_pm == u'下午' or is_pm == u'晚上' or is_pm == u'中午': hour = target_data.time().hour if hour < 12: target_data = target_data.replace(hour=hour+12) return target_data.strftime('%Y-%m-%d %H:%M:%S') else: return None UTIL_CN_NUM = { '零': 0, '一': 1, '二': 2, '三': 3, '四': 4, '五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9 } UTIL_CN_UNIT = {'十': 10, '百': 100, '千': 1000, '万': 10000} def cn2dig(src): """ 解析 :param src: :return: """ if src == "": return None m = re.match("d+", src) if m: return int(m.group(0)) rsl = 0 unit = 1 for item in src[::-1]: if item in UTIL_CN_UNIT.keys(): unit = UTIL_CN_UNIT[item] elif item in UTIL_CN_NUM.keys(): num = UTIL_CN_NUM[item] rsl += num * unit else: return None if rsl < unit: rsl += unit return rsl def year2dig(year): """ 解析年 :param year: :return: """ res = '' for item in year: if item in UTIL_CN_NUM.keys(): res = res + str(UTIL_CN_NUM[item]) else: res = res + item m = re.match("d+", res) if m: if len(m.group(0)) == 2: return int(datetime.today().year/100)*100 + int(m.group(0)) else: return int(m.group(0)) else: return None text1 = '我要住到27日三点' text2 = '预定28号2点房间' text3 = '我要从21号下午4点住到11日2号' # print(text1, time_extract(text1)) # print(text2, time_extract(text2)) # print(text3, time_extract(text3)) time_extract(text1) time_extract(text2) time_extract(text3) def time_extract(text): time_res = [] word = '' keyDate = {'今天': 0, '明天': 1, '后天': 2} for k, v in psg.cut(text): if k in keyDate: if word != '': time_res.append(word) word = (datetime.today() + timedelta(days=keyDate.get(k, 0))).strftime('%Y年%m月%d日') elif word != '': if v in ['m', 't']: # print('*', word) word = word + k else: # print('**', word) time_res.append(word) word = '' elif v in ['m', 'k']: word = k if word != '': time_res.append(word) print(' '.join(time_res)) result = list(filter(lambda x: x is not None, [check_time_valid(w) for w in time_res])) final_res = [parse_datetime(w) for w in result] return [x for x in final_res if x is not None] 2:哈工大pyltp模型
6月28日,2019年5月, 2月份这三个有效时间。
通常情况下,较好的解决思路是利用深度学习模型来识别文本中的时间,通过一定数量的标记文本和合适的模型。本文尝试利用现有的NLP工具来解决如何从文本中提取时间。
使用的工具为哈工大的pyltp,可以在Python的第三方模块中找到,通过pip安装或者通过使用whl安装,另外python3.7建议使用whl安装,实现下载好分词模型cws.model和词性标注pos.model这两个模型文件。
话不多说,我们直接上Python代码,如下:# -*- coding: utf-8 -*- import os from pyltp import Segmentor from pyltp import Postagger class LTP(object): def __init__(self): cws_model_path = os.path.join(os.path.dirname(__file__), 'cws.model') # 分词模型路径,模型名称为`cws.model` pos_model_path = os.path.join(os.path.dirname(__file__), 'pos.model') # 词性标注模型路径,模型名称为`pos.model` self.segmentor = Segmentor() # 初始化实例 self.segmentor.load(cws_model_path) # 加载模型 self.postagger = Postagger() # 初始化实例 self.postagger.load(pos_model_path) # 加载模型 # 分词 def segment(self, text): words = list(self.segmentor.segment(text)) return words # 词性标注 def postag(self, words): postags = list(self.postagger.postag(words)) return postags # 获取文本中的时间 def get_time(self, text): # 开始分词及词性标注 words = self.segment(text) postags = self.postag(words) time_lst = [] i = 0 for tag, word in zip(postags, words): if tag == 'nt': j = i while postags[j] == 'nt' or words[j] in ['至', '到']: j += 1 time_lst.append(''.join(words[i:j])) i += 1 # 去重子字符串的情形 remove_lst = [] for i in time_lst: for j in time_lst: if i != j and i in j: remove_lst.append(i) text_time_lst = [] for item in time_lst: if item not in remove_lst: text_time_lst.append(item) # print(text_time_lst) return text_time_lst # 释放模型 def free_ltp(self): self.segmentor.release() self.postagger.release() if __name__ == '__main__': ltp = LTP() # 输入文本 sent = '6月28日,杭州市统计局权威公布《2019年5月月报》,杭州市医保参保人数达到1006万,相比于2月份的989万,三个月暴涨16万人参保,傲视新一线城市。' time_lst = ltp.get_time(sent) ltp.free_ltp() # 输出文本中提取的时间 print('提取时间: %s' % str(time_lst)) 提取时间: ['今天', '2019年6月份', '2019年6月份', '当前'] 提取时间: ['2006年', '2008年', '2011年', '2014年', '2015年', '2016年', '2018年'] 提取时间: ['此后', '6月28日', '7月9日', '7月11日下午'] 提取时间: ['1974年4月', '2016年11月至2018年9月'] 3: Stanford CoreNLP Python
2:下载Stanford CoreNLP文件,解压。
3:处理中文还需要下载中文的模型jar文件,然后放到stanford-corenlp-full-2018-02-27根目录下即可(注意一定要下载这个文件,否则它默认是按英文来处理的)。使用
stanfordcorenlp接口为例(本文所用版本为Stanford CoreNLP 3.9.1),讲解Python调用StanfordCoreNLP的使用方法。stanfordcorenlp:pip install stanfordcorenlp
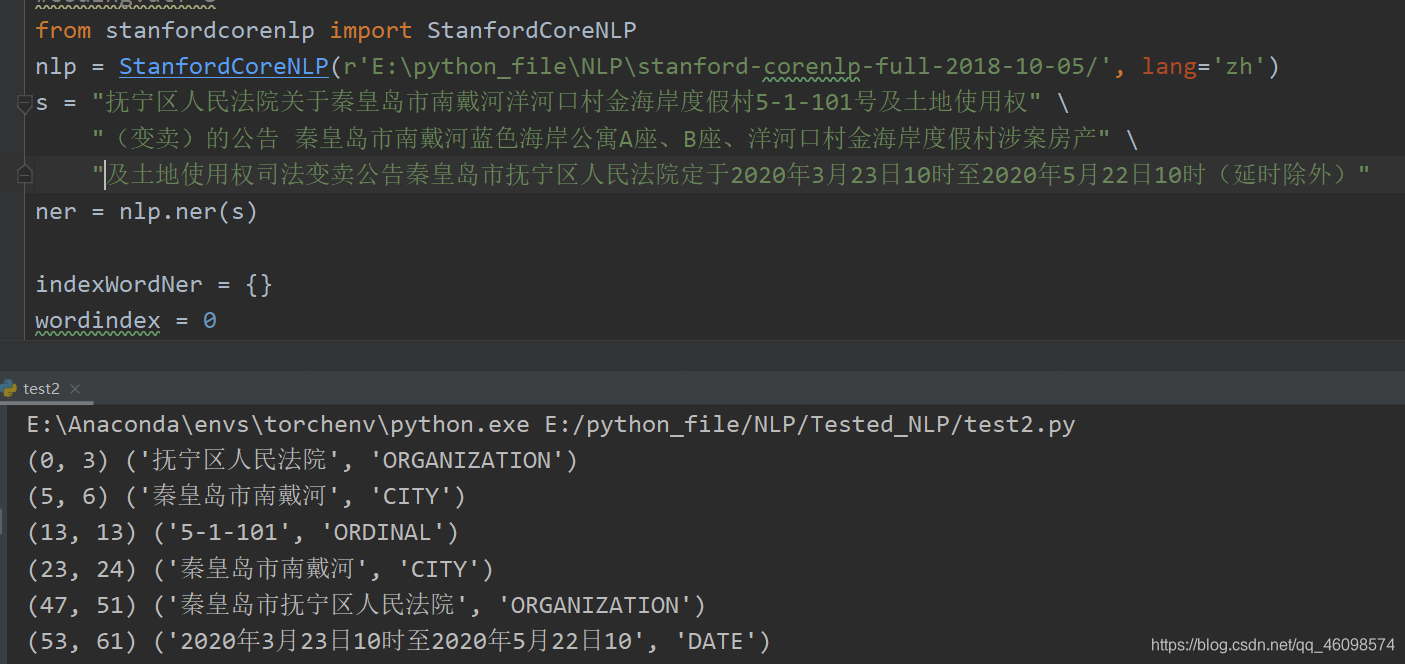
选择USTC镜像安装(安装速度很快,毕竟国内镜像):pip install stanfordcorenlp -i https://pypi.mirrors.ustc.edu.cn/simple/ --trusted-host pypi.mirrors.ustc.edu.cn#coding:utf-8 from stanfordcorenlp import StanfordCoreNLP nlp = StanfordCoreNLP(r'E:python_fileNLPstanford-corenlp-full-2018-10-05/', lang='zh') s = "抚宁区人民法院关于秦皇岛市南戴河洋河口村金海岸度假村5-1-101号及土地使用权" "(变卖)的公告 秦皇岛市南戴河蓝色海岸公寓A座、B座、洋河口村金海岸度假村涉案房产" "及土地使用权司法变卖公告秦皇岛市抚宁区人民法院定于2020年3月23日10时至2020年5月22日10时(延时除外)" ner = nlp.ner(s) indexWordNer = {} wordindex = 0 wordTag = '' for lineIdx, line in enumerate(ner): word = line[0] tag = line[1] if tag != 'O': wordindex += 1 if wordindex == 1: begin = lineIdx wordTag = tag else: if wordindex != 0: key = (begin, lineIdx - 1) wordner = ''.join([i[0] for i in ner[begin:lineIdx]]) value = (wordner, wordTag) indexWordNer[key] = value wordindex = 0 a = [] indexWordNerSorted = sorted(indexWordNer.items(), key=lambda e: e[0][0]) for key, value in indexWordNerSorted: print( key, value) if 'GPE' in value: print(value[0]) a.append(value[0]) print(a) 4:paddlehub

# coding:utf-8 """ Named entity recognition based on Baidu lac __author__: 周小夏 """ import paddlehub as hub import pandas as pd import xlrd import time if __name__ == "__main__": # Load the pre training model named lac time_start = time.time() textlist = list() lac = hub.Module(name="lac") content = xlrd.open_workbook(filename='样本外测试日期地址案例资产系统网站20200423.xlsx', encoding_override='gbk') data = pd.read_excel(content, engine='xlrd') n = 0 set = set() finals = [] for data_one in data['描述和其他']: if data_one.__str__().__len__() <= 20: finals.append('数据为空或地名不常见') continue # try: text = ','.join(data_one.split('二、')[0:-1]).split(',')[0] if text == '': text = data_one test_text = ['土地使用权司法变卖公告秦皇岛市抚宁区人民法院定于2020年3月23日10时至2020年5月22日10时(延时除外)', ''] # Set the input of participle, whose input is a set of sentences inputs = {"text": test_text} final = [] result = '' # Call the model for word segmentation and put the results in results results = lac.lexical_analysis(data=inputs) for abb in results: for a, b in enumerate(abb['tag']): lenght = len(abb['word'][a]) word = abb['word'][a] if b == 'TIME': final.append(word) result += 'n' n += 1 # Show the results l2 = [] [l2.append(i) for i in final if not i in l2] try: if len(l2[0]) <= 2: pass except: finals.append('数据为空或地名不常见') continue finals.append(''.join(l2)) if n >= 1: break print(" Total time spent: {}".format(time.time() - time_start), finals) test = pd.DataFrame(data=finals) # test.to_csv('nerResult1.csv', encoding='utf-8') 5:nltk
import nltk from nltk.tokenize import word_tokenize from nltk.tag import pos_tag nltk.download() ex = 'European authorities fined Google a record $5.1 billion on Wednesday for abusing its power in the mobile phone market and ordered the company to alter its practices in 2020 years' def preprocess(sent): sent = nltk.word_tokenize(sent) sent = nltk.pos_tag(sent) return sent sent = preprocess(ex) print(sent) 6:spacy
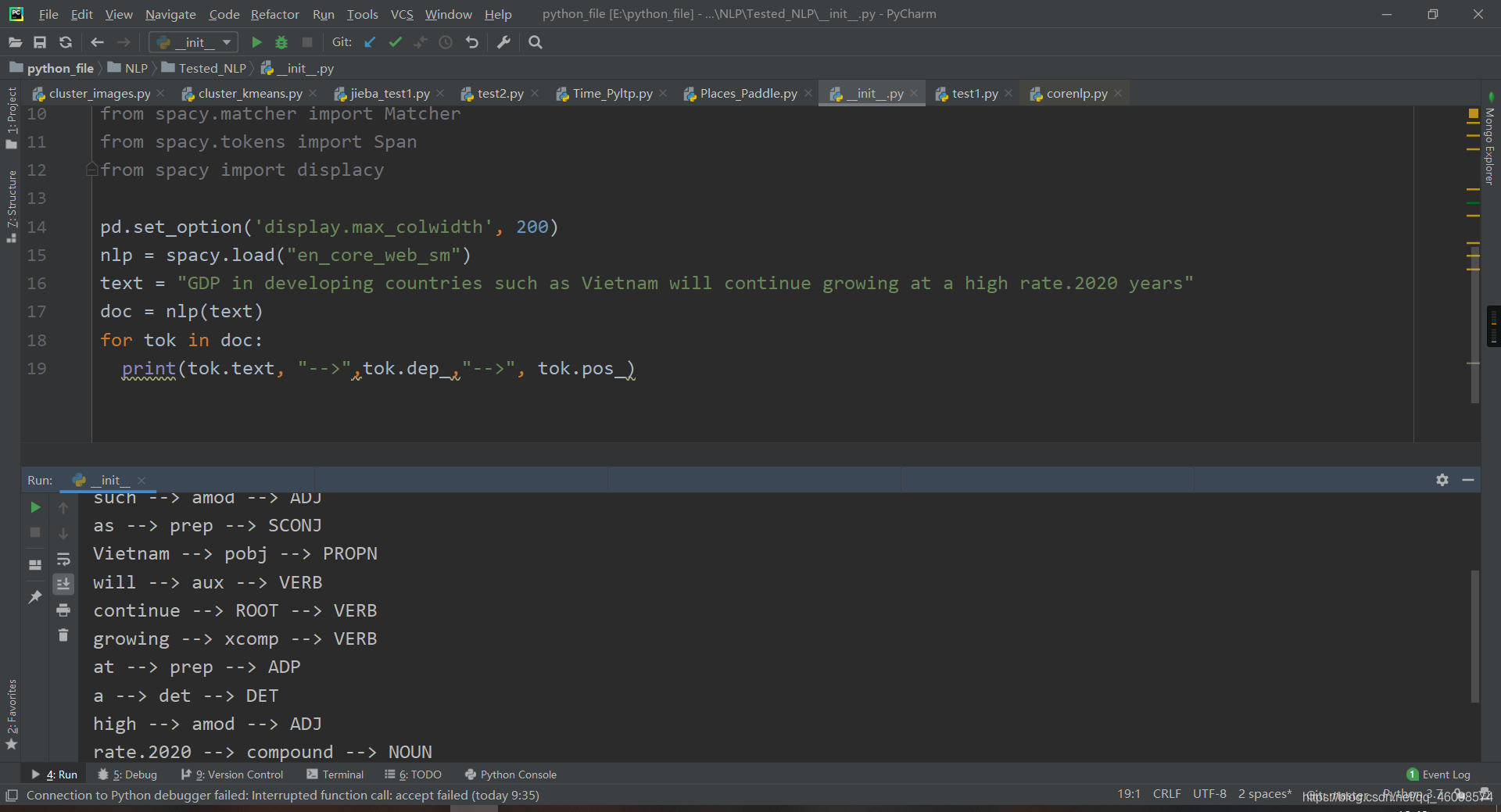
import re import string import nltk import spacy import pandas as pd import numpy as np import math from tqdm import tqdm from spacy.matcher import Matcher from spacy.tokens import Span from spacy import displacy pd.set_option('display.max_colwidth', 200) nlp = spacy.load("en_core_web_sm") text = "GDP in developing countries such as Vietnam will continue growing at a high rate.2020 years" doc = nlp(text) for tok in doc: print(tok.text, "-->",tok.dep_,"-->", tok.pos_)
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









