爬取思路: 首先百度找一张图片: 然后使用页面解析找出图片实际地址: 这里是爬取出来的文件截图
1、找到目标图片,这里以百度图片为例
2、通过页面解析找出图片实际地址
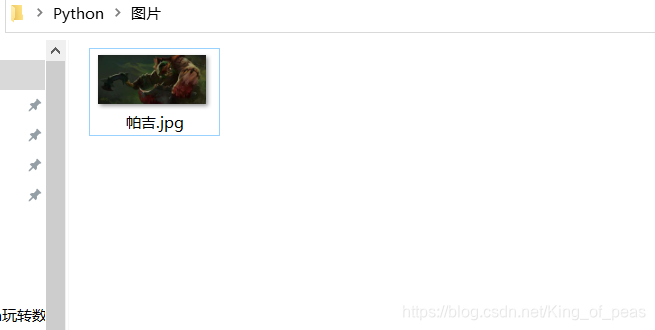
3、通过requests库爬取图片,保存本地
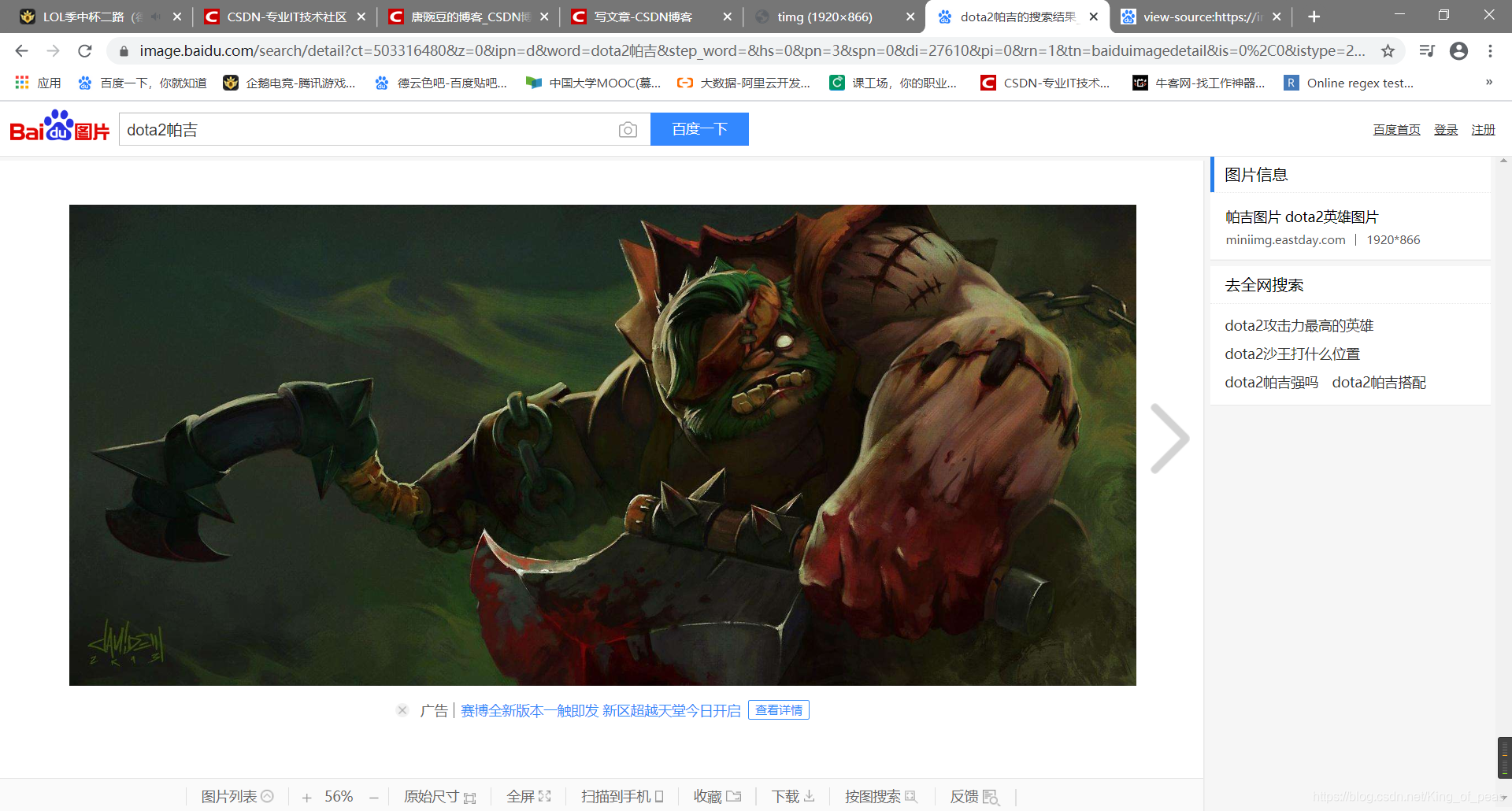
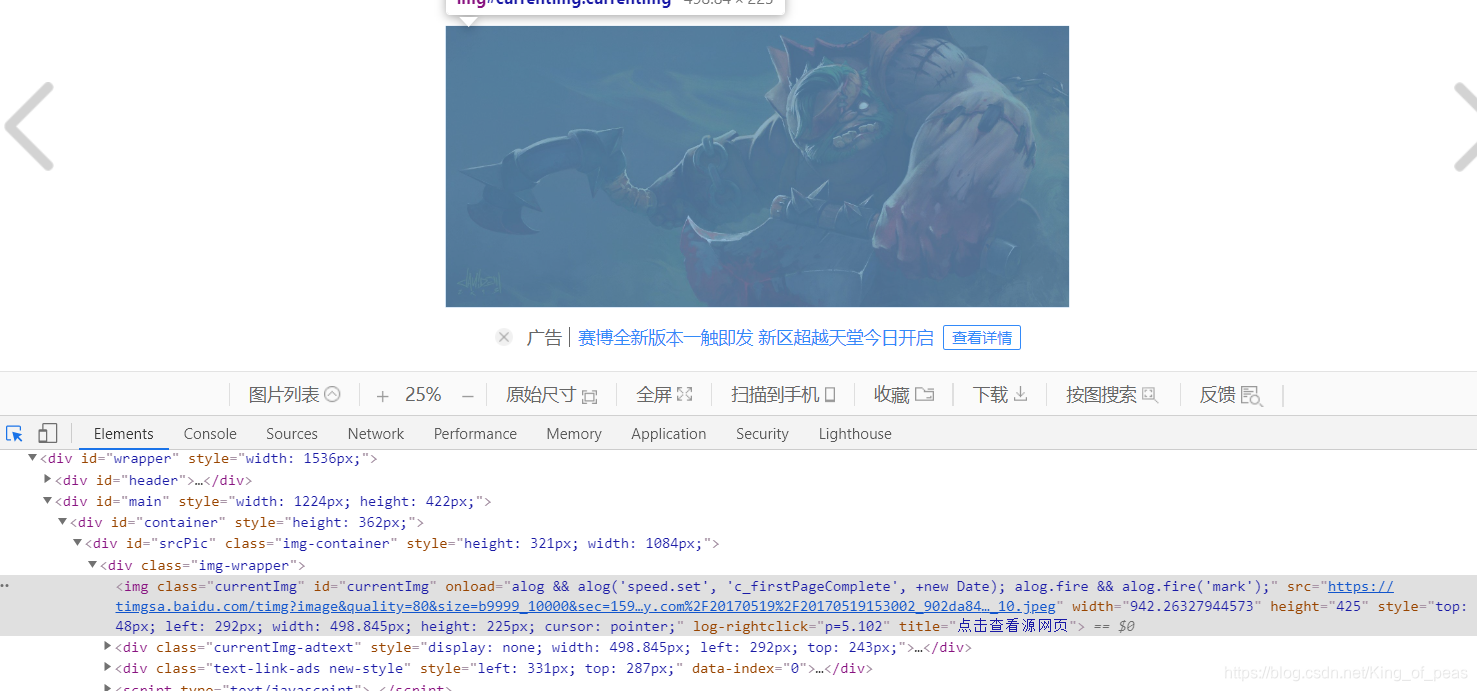
这里需要复制图片地址,确认一下地址是是否正确:
https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1590932049656&di=bf69222ddaff5a2544610717d22138cc&imgtype=0&src=http%3A%2F%2F01.minipic.eastday.com%2F20170519%2F20170519153002_902da84e08dac8d68f189cb6c8ea4626_10.jpeg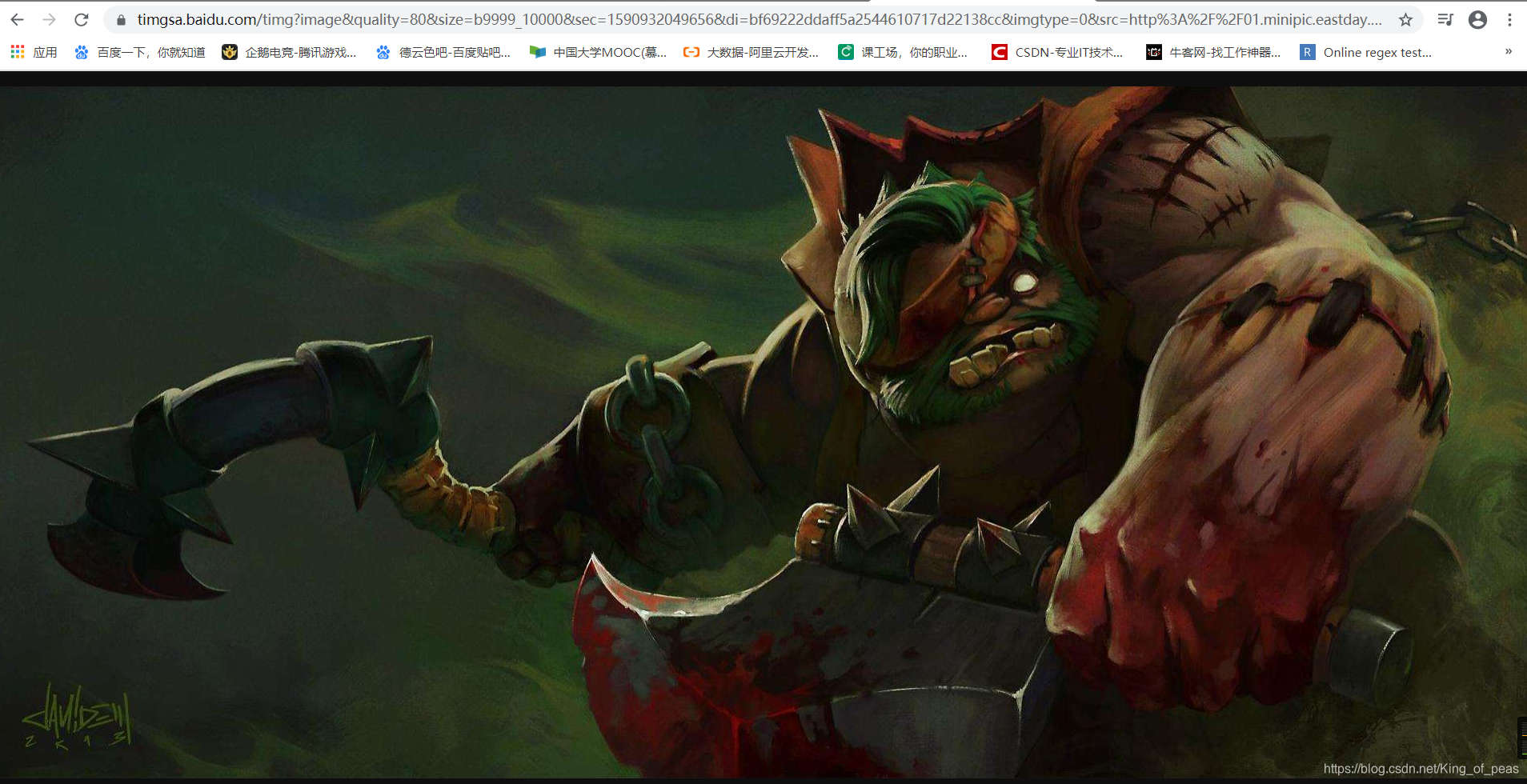
验证完毕,开始爬取,直接上码import requests import os url = "https://timgsa.baidu.com/timg?image&quality=80&size =b9999_10000&sec=1590932049656&di=bf69222ddaff5a2544610717d22138cc& imgtype=0&src=http%3A%2F%2F01.minipic.eastday.com%2F20170519%2F20170 519153002_902da84e08dac8d68f189cb6c8ea4626_10.jpeg" #图片地址 root = "C://Users//99779//Desktop//Python//图片//" #存放图片路径 path = root + '帕吉.jpg' #设置图片名称及其格式 try: #try···except结构,返回链接错误类型 headers = {'user-agent':'Mozilla/5.0'} #请求头模拟 #使用库os的方法确认文件路径是否存在,若不存在则创建 if not os.path.exists(root): os.mkdir(root) #若不存在则创建 if not os.path.exists(path): r = requests.get(url, headers=headers) with open (path, 'wb') as f:#"wb'表示对二进制文件的写入 f.write(r.content) #r.content表示返回内容的二进制形式 f.close()#with··· as 语句会自动关闭句柄,可不写close() print("文件保存成功") else: print('文件已经存在') except ConnectionError as err: print(err)
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









