如果觉得文章写得好,如果你想要获取本文的所有数据,请关注公众号:【数据分析与统计学之美】,添加作者【个人微信】,进群和作者交流! 1、selenium模块的安装与chromedriver驱动的配置 检验是否安装成功: 配置chromedriver驱动,一定要注意“驱动”和“谷歌浏览器”版本一定是要相匹配,否则不能使用。 这里首先提供一个详细的地址供大家查看: 这里再次提供一个详细的地址,供大家选择各种版本驱动程序: 解压上述下载好的文件,并将其中的的chromedriver.exe文件,需要放到python的安装路径下(和python.exe放在一起)。 使用如下两行代码,如果谷歌浏览器成功被驱动打开,证明上述安装和配置没问题。 结果如下: 这个章节主要讲述的是我的整个爬虫思路。会的人就挑重点看看,不会的人就仔细看看。 你想要获取笔记本电脑的数据信息。就必须要利用selenium自动化测试工具,自动输入“笔记本电脑”,然后点击“搜索”,获取我们想要的页面。 注意:在自动点击“搜索框”后,系统会提示“需要登陆信息”。登陆方式很多,我推荐的是使用“二维码登录”的方式,因为其他方式很复杂,也不建议你们尝试,除非你想研究爬虫。 这个操作是为我们后来的“翻页”操作做准备的。对于淘宝页面来说,进行翻页操作,有如下两种方式,下面我们一一进行说明,我们先看下图。 定位“总页面”,我们可以看一下图中的定位信息,这里的总页面信息是一个文本“共100页”,我们需要利用“正则表达式”提取数字100,代码如上。 我们要获取商品信息,首先要找到商品信息的具体定位信息。老生常谈的话,怎么定位?这里就不详细说明了,下图中可以看出:整个笔记本的信息都存在于div[@class=“items”]下。 保存数据我们使用的是csv模块,我们先保存第一页的数据,后面采用追加的方式,将每一页的数据,一次次保存进行。 注意:在使用csv保存数据的时候,一定要将数据编码设置为“utf-8-sig”形式,不要问为什么,因为我以前碰到过保存为“utf8”格式,仍然出现乱码的情况。只有保存成这个编码还没有遇见任何问题。 我们想要知道怎么翻页,就必须了解每个页面的“url”是怎么变化的,下图我截取了第2,3,4页的url信息,进行分析。 效果如下: 结果如下:
目录
1)安装selenium库
2)chromedriver驱动的配置
① 检查谷歌浏览器的版本
② 下载chromedriver驱动
③ chromedriver驱动的配置
3)检验selenium是否可用
4)一个小案例展示selenium的操作效果
2、爬虫思路的完整叙述
1)定位输入框、搜索框
2)获取“总页数”信息
3)获取商品信息(第一页的信息)
4)保存数据(第一页的数据)
5)翻页操作获取整个数据(完整代码)
3、可视化展示
1)买电脑最关注哪些参数?
2)不同电脑品牌的销量信息
3)电脑需求量最大的前十个城市
4)店铺销售量最好的前十个城市
5)价格最贵的电脑到底是啥样的?1、selenium模块的安装与chromedriver驱动的配置
1)安装selenium库
pip install selenium
2)chromedriver驱动的配置
① 检查谷歌浏览器的版本
https://jingyan.baidu.com/article/95c9d20d74a1e8ec4f756149.html
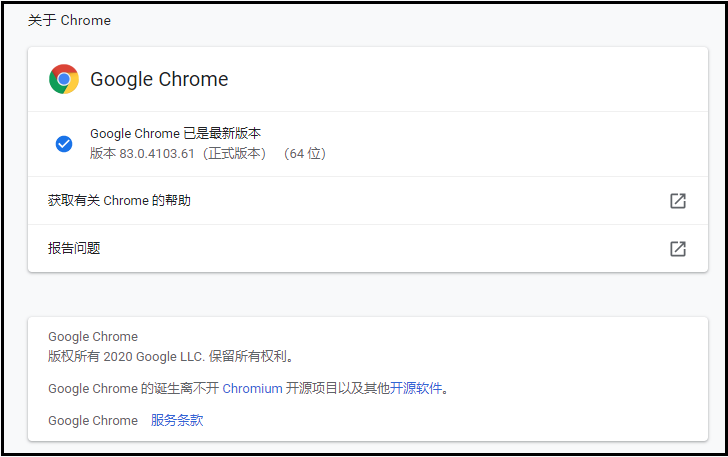
点击“右上角三个点” –> 点击“设置” –> 点击 “关于chrome”,出现如下界面。
② 下载chromedriver驱动
https://chromedriver.storage.googleapis.com/index.html
从上面的图中可以看出,谷歌浏览器的版本是【81.0.4044.138】,这里我们选择的chromedriver驱动,如下图所示。
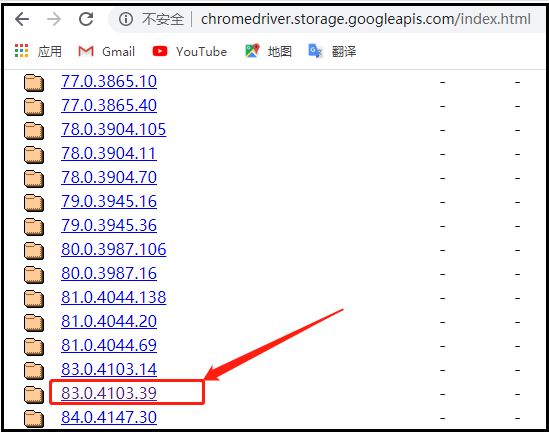
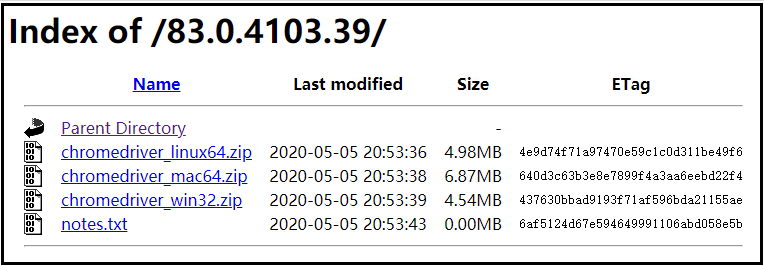
点进该文件后,可以根据我们的操作系统,选择对应的驱动。
③ chromedriver驱动的配置
首先,你可以查看你的python解释器安装在哪里!
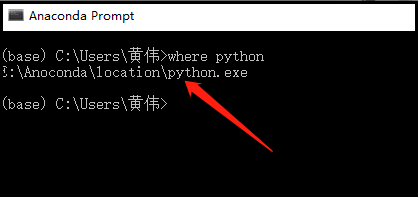
然后,将chromedriver.exe放置和python.exe在一起。
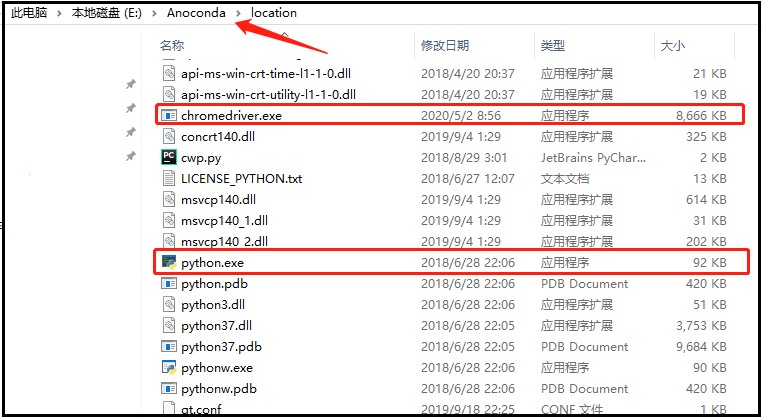
3)检验selenium是否可用
from selenium import webdriver browser = webdriver.Chrome()
4)一个小案例展示selenium的操作效果
from selenium import webdriver import time # 创建浏览器对象,该操作会自动帮我们打开Google浏览器窗口 browser = webdriver.Chrome() # 调用浏览器对象,向服务器发送请求。该操作会打开Google浏览器,并跳转到“百度”首页 browser.get("https://www.baidu.com/") # 最大化窗口 browser.maximize_window() # 定位“抗击肺炎”链接内容 element = browser.find_element_by_link_text("抗击肺炎") # 为了更好的展示这个效果,我们等待3秒钟 time.sleep(3) # 点击上述链接 element.click() # 我们再让浏览器停留3秒钟后,再关闭浏览器 time.sleep(3) # 操作会自动关闭浏览器 browser.close() """ 效果这里就不展示了,大家自行下去尝试! """ 2、爬虫思路的完整叙述
1)定位输入框、搜索框
下图展示的是“输入框”的定位信息:
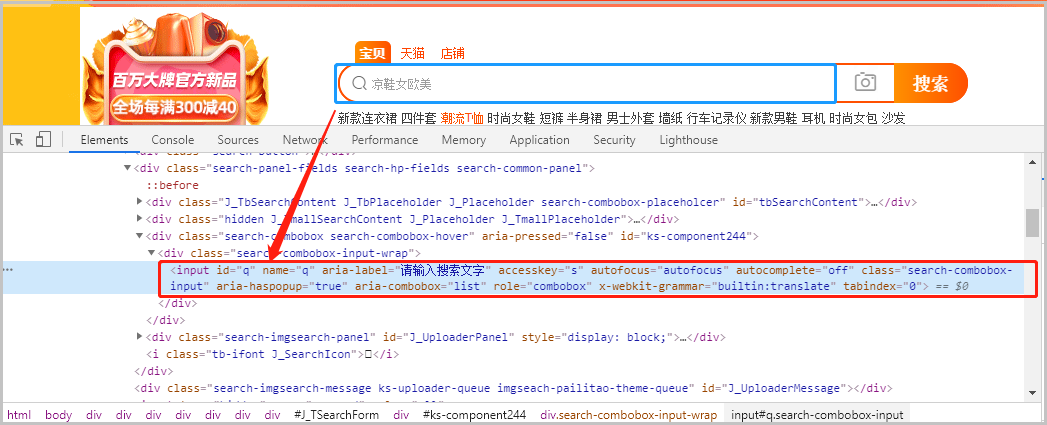
下图展示的是“搜索框”的定位信息:
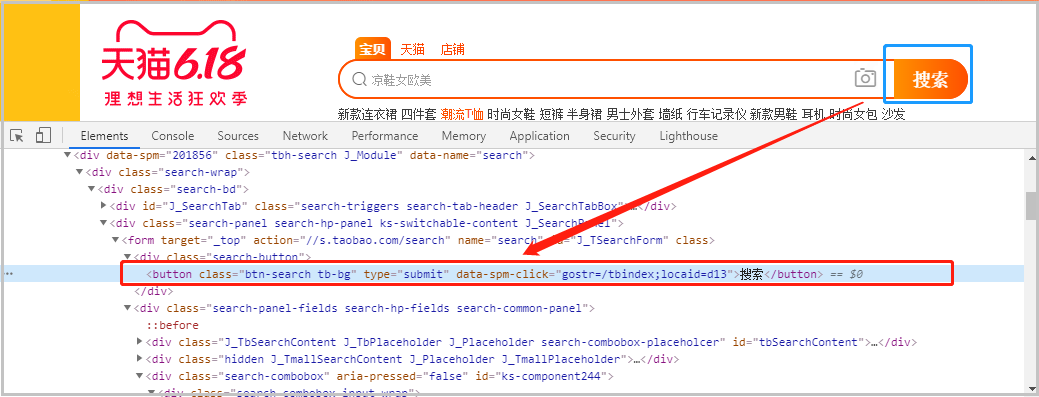
第一次测试代码如下:from selenium import webdriver import time # 搜索商品 def search_product(key_word): # 定位输入框 browser.find_element_by_id("q").send_keys(key_word) # 定义点击按钮,并点击 browser.find_element_by_class_name('btn-search').click() # 最大化窗口:为了方便我们扫码 browser.maximize_window() # 等待15秒,给足时间我们扫码 time.sleep(15) # 获取数据 def get_data(): pass def main(): browser.get('https://www.taobao.com/') search_product(key_word) if __name__ == '__main__': key_word = input("请输入你要搜索的商品:") browser = webdriver.Chrome() main() 2)获取“总页数”信息

思路一:从第一页开始,一直点击下一页;
思路二:获取总页码,进行url的拼接后,进行翻页操作;
这里我们选择的是“第二种思路”。因为不同的商品页码不同(有的可能没有100页),因此为了便于代码的书写,我们选择了第二种。from selenium import webdriver import time # 搜索商品,获取商品页码 def search_product(key_word): # 定位输入框 browser.find_element_by_id("q").send_keys(key_word) # 定义点击按钮,并点击 browser.find_element_by_class_name('btn-search').click() # 最大化窗口:为了方便我们扫码 browser.maximize_window() # 等待15秒,给足时间我们扫码 time.sleep(15) # 定位这个“页码”,获取“共100页这个文本” page_info = browser.find_element_by_xpath('//div[@class="total"]').text # 需要注意的是:findall()返回的是一个列表,虽然此时只有一个元素它也是一个列表。 page = re.findall("(d+)",page_info)[0] return page # 获取数据 def get_data(): pass def main(): browser.get('https://www.taobao.com/') page = search_product(key_word) print(type(page)) print(page) if __name__ == '__main__': key_word = input("请输入你要搜索的商品:") browser = webdriver.Chrome() main()
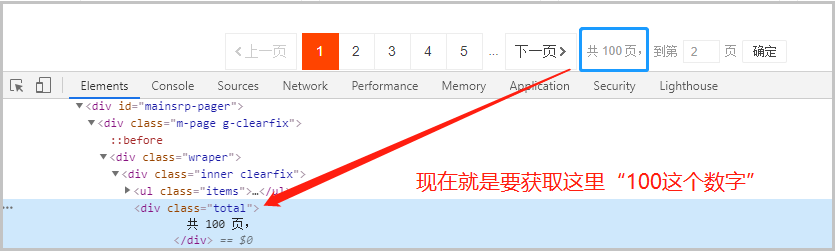
3)获取商品信息(第一页的信息)
其次,获取具体各部分的信息,我们使用的是xpath语法,这一直是我最喜欢使用的一个获取数据的方式。
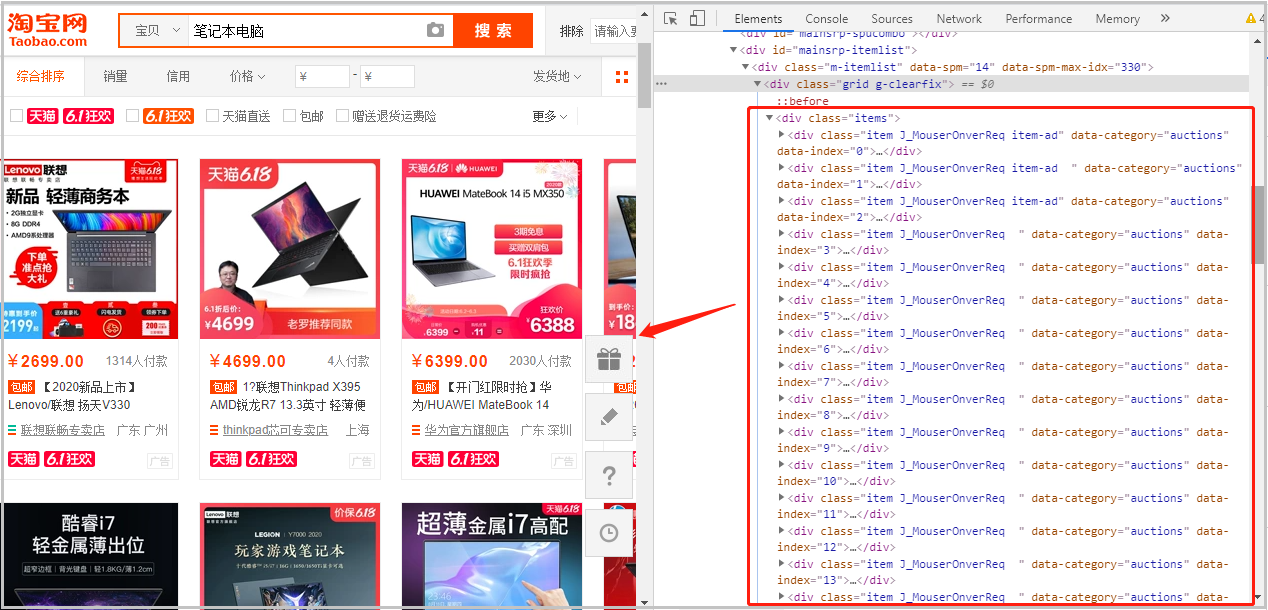
代码如下:from selenium import webdriver import time # 搜索商品,获取商品页码 def search_product(key_word): # 定位输入框 browser.find_element_by_id("q").send_keys(key_word) # 定义点击按钮,并点击 browser.find_element_by_class_name('btn-search').click() # 最大化窗口:为了方便我们扫码 browser.maximize_window() # 等待15秒,给足时间我们扫码 time.sleep(15) # 定位这个“页码”,获取“共100页这个文本” page_info = browser.find_element_by_xpath('//div[@class="total"]').text # 需要注意的是:findall()返回的是一个列表,虽然此时只有一个元素它也是一个列表。 page = re.findall("(d+)",page_info)[0] return page # 获取数据 def get_data(): # 通过页面分析发现:所有的信息都在items节点下 items = browser.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]') for item in items: # 参数信息 pro_desc = item.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text # 价格 pro_price = item.find_element_by_xpath('.//strong').text # 付款人数 buy_num = item.find_element_by_xpath('.//div[@class="deal-cnt"]').text # 旗舰店 shop = item.find_element_by_xpath('.//div[@class="shop"]/a').text # 发货地 address = item.find_element_by_xpath('.//div[@class="location"]').text print(pro_desc, pro_price, buy_num, shop, address) def main(): browser.get('https://www.taobao.com/') page = search_product(key_word) print(page) get_data() if __name__ == '__main__': key_word = input("请输入你要搜索的商品:") browser = webdriver.Chrome() main() 4)保存数据(第一页的数据)
from selenium import webdriver import time import csv # 搜索商品,获取商品页码 def search_product(key_word): # 定位输入框 browser.find_element_by_id("q").send_keys(key_word) # 定义点击按钮,并点击 browser.find_element_by_class_name('btn-search').click() # 最大化窗口:为了方便我们扫码 browser.maximize_window() # 等待15秒,给足时间我们扫码 time.sleep(15) # 定位这个“页码”,获取“共100页这个文本” page_info = browser.find_element_by_xpath('//div[@class="total"]').text # 需要注意的是:findall()返回的是一个列表,虽然此时只有一个元素它也是一个列表。 page = re.findall("(d+)",page_info)[0] return page # 获取数据 def get_data(): # 通过页面分析发现:所有的信息都在items节点下 items = browser.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]') for item in items: # 参数信息 pro_desc = item.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text # 价格 pro_price = item.find_element_by_xpath('.//strong').text # 付款人数 buy_num = item.find_element_by_xpath('.//div[@class="deal-cnt"]').text # 旗舰店 shop = item.find_element_by_xpath('.//div[@class="shop"]/a').text # 发货地 address = item.find_element_by_xpath('.//div[@class="location"]').text #print(pro_desc, pro_price, buy_num, shop, address) with open('{}.csv'.format(key_word), mode='a', newline='', encoding='utf-8-sig') as f: csv_writer = csv.writer(f, delimiter=',') csv_writer.writerow([pro_desc, pro_price, buy_num, shop, address]) def main(): browser.get('https://www.taobao.com/') page = search_product(key_word) print(page) get_data() if __name__ == '__main__': key_word = input("请输入你要搜索的商品:") browser = webdriver.Chrome() main() 5)翻页操作获取整个数据(完整代码)
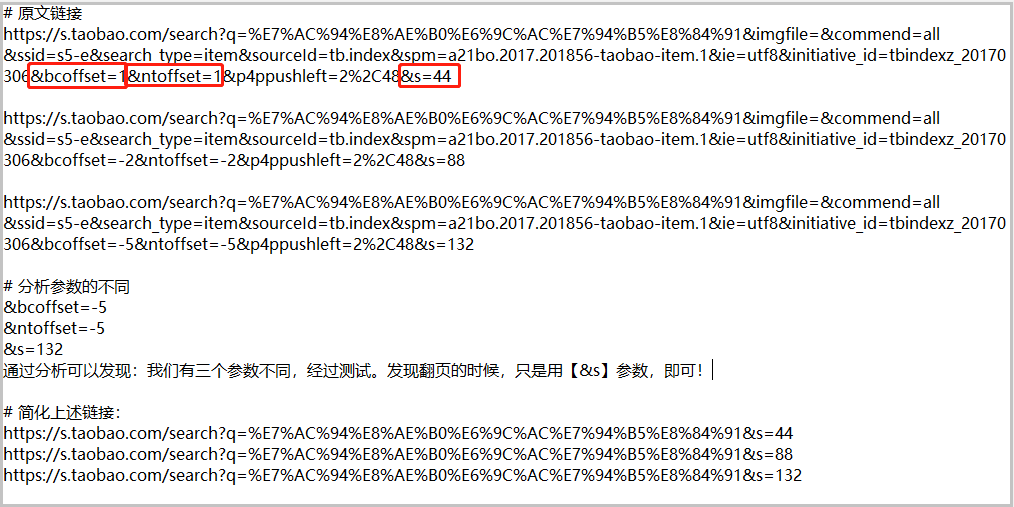
由于整个代码太长,这里就不提供了,详细代码可以参见文末的“获取方式”。3、可视化展示
1)买电脑最关注哪些参数?
add_word = ['联想','惠普','酷睿','苹果','三星','华硕','索尼','宏碁','戴尔','海尔','长城','海尔','神舟','清华同方','方正','明基'] for i in add_word: jieba.add_word(i) df["切分后的描述信息"] = df["描述信息"].apply(lambda x:jieba.lcut(x)) # 读取停用词 with open("stoplist.txt", encoding="utf8") as f: stop = f.read() stop = stop.split() stop = [" ","笔记本电脑"] + stop stop[:10] # 去掉停用词 df["切分后的描述信息"] = df["切分后的描述信息"].apply(lambda x: [i for i in x if i not in stop]) # 词频统计 all_words = [] for i in df["切分后的描述信息"]: for j in i: all_words.extend(i) word_count = pd.Series(all_words).value_counts() # 绘制词云图 # 1、读取背景图片 back_picture = imread("aixin.jpg") # 2、设置词云参数 wc = WordCloud(font_path="G:\6Tipdm\wordcloud\simhei.ttf", background_color="white", max_words=2000, mask=back_picture, max_font_size=200, random_state=42 ) wc2 = wc.fit_words(word_count) # 3、绘制词云图 plt.figure(figsize=(16,8)) plt.imshow(wc2) plt.axis("off") plt.show() wc.to_file("电脑.png")

从上图可以看出:“轻薄”、“游戏”、“学生”、“商务”这三个词被提及的次数最多。其次大家关注最多的是“办公”、“便携”、“英寸”。从电脑牌子可以看出 , “酷睿”和“联想”的销量最大,“华硕”的其次。从性能参数来看,“i7”牌子的电脑,销量高于“i5”牌子的电脑,想当年我买电脑的时候,还是“i5”刚刚普及的时候。2)不同电脑品牌的销量信息
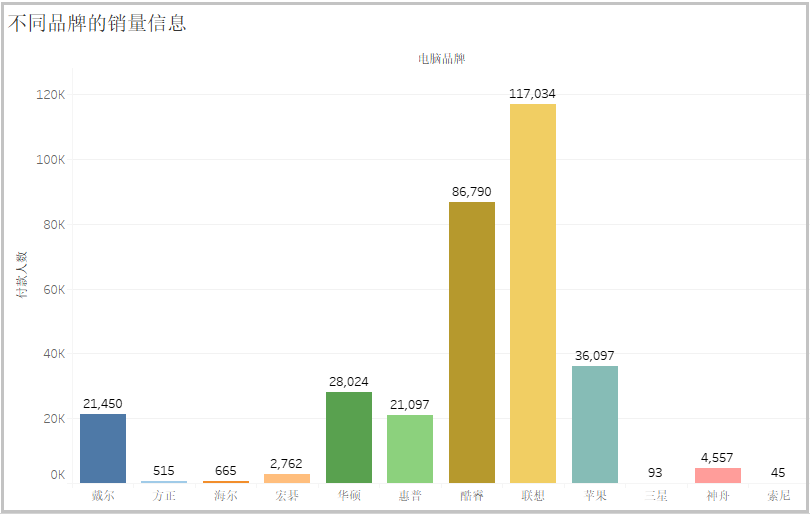
从上图可以看出:销售量排名前3的电脑分别是“联想”、“酷睿”、“苹果”,其次是“华硕”、“戴尔”、“惠普”。3)电脑需求量最大的前十个城市
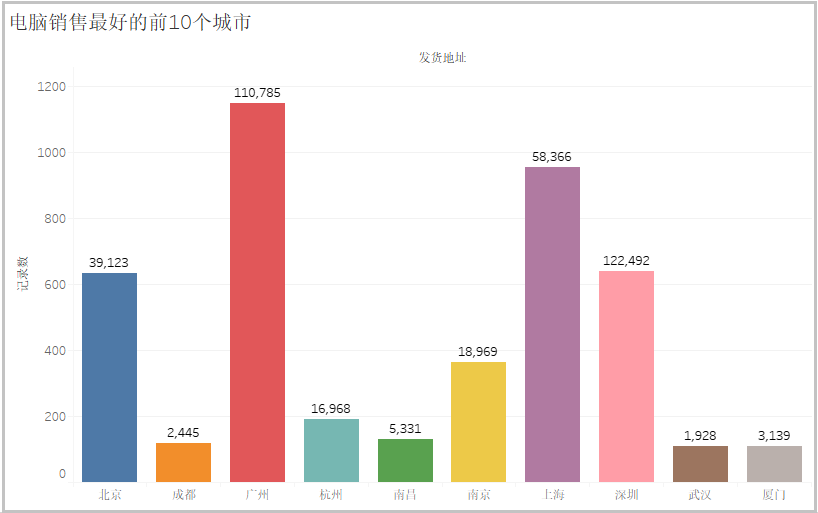
从图中可以看出:四个一线城市“北京”、“上海”、“广州”、“深圳”对于电脑的需求量肯定是最大的。其次“南京”、“杭州”对于电脑的需求较大。4)电脑销售量最好的前十个店铺
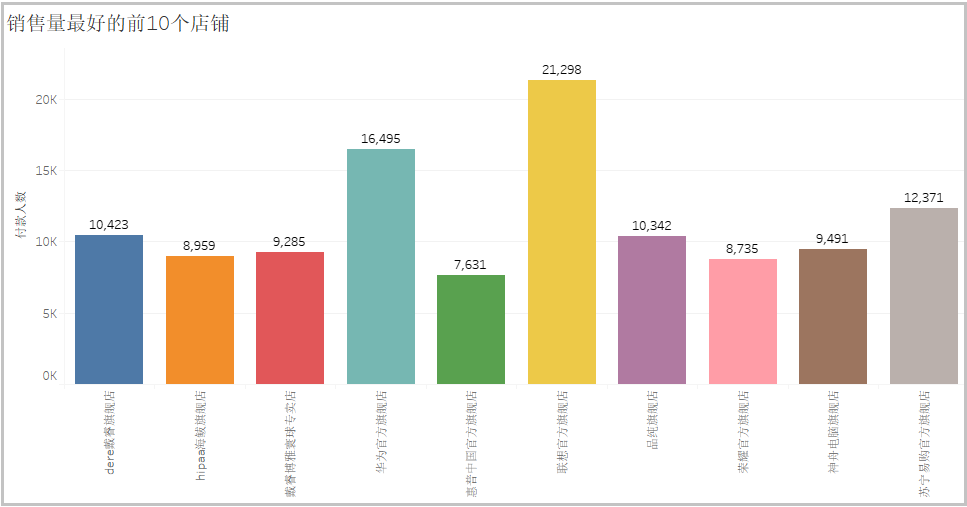
从图中可以看出:“联想官方旗舰店”的电脑卖的是最好的,其次是“华为官方旗舰店”。相信大家看了这个分析以后,就知道自己应该怎么选择店铺,去选购自己的电脑了。5)价格最贵的电脑到底是啥样的?
# 将数据按照价格,降序排序 df1 = df.sort_values(by="价格", axis=0, ascending=False) df1 = df1.iloc[:10,:] df1.to_excel("价格 排名前10的数据.xlsx",encoding="utf-8-sig",index=None)
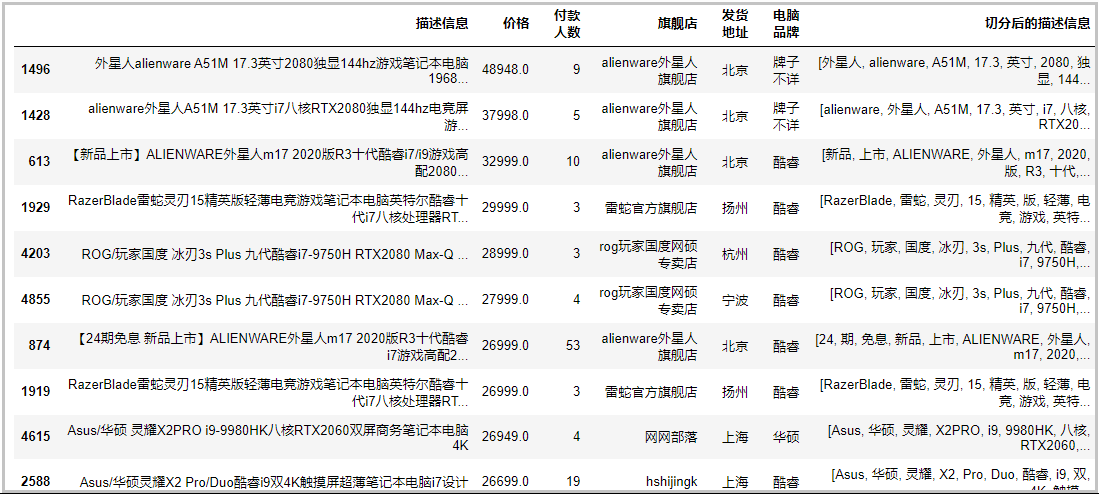
根据上表展示的数据中可以看出:电脑最贵的电脑达到了48948元,不知道你见过没有,反正我是没有见过。该电脑的宣传视频,见文章最开始,具体信息是怎么样子的,你可以自己下去查看。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 1321
1321