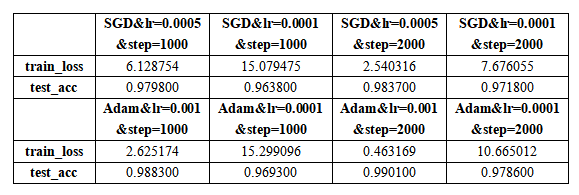
实验环境:tensorflow-1.14, python3.7。 可根据莫烦教程学习相关基础知识。 所有代码和数据集详见:https://gitee.com/lakuite/tensorflow_classfication 官方教程:https://tensorflow.google.cn/install/pip#windows 这个网站是tensorflow官网给的pip安装的方法,它的系统需求是python3.5-3.7,pip19.0版本及以上,windows7版本及以上。 下载地址:https://www.python.org/downloads/release/python-377/ 下载对应的安装包,然后直接双击安装就可以了。 需要注意在安装时勾选“添加环境变量”,不然装完后要手动添加一下。 安装完成后在命令行输入python,出现图中所示信息说明安装成功: 该方法安装的python已经自动安装了pip。 官网教程推荐virtualenv,这个不装也可以,但是为了以后发生版本对应问题,最好还是装一个。 安装virtualenv只要在命令行输入下面2条语句就可以了: 装完后可以输出它的版本以检查是否安装成功: 然后在保存python项目的路径下进入cmd,用下面的命令创建虚拟环境venv,然后激活该环境: 在环境激活状态下升级pip,查看在该环境中安装过的包: 在虚拟环境中执行: 1.14是指定版本,不指定则安装最新版本。 如果下载速度慢的话可以用国内源进行安装。 在C:Users<电脑用户名>pip下新建文档 pip.ini: 再使用pip安装。 测试是否安装成功,在cmd中: 如果出现报错: 可降级numpy为1.16来解决: 共60000张图片作为训练集(其中包含5000张验证集),10000张图片为测试集。 每张图片大小均为28×28的灰度图(即通道数为1)。 每张图片对应一个标签,标签为one-hot格式,即对于图片 [0, 1, 0, 0, 0, 0, 0, 0, 0, 0] 可使用下述代码下载mnist数据集: 下载完后会在当前路径下生成 MNIST_data 的文件夹,里面有相关数据文件: 数据集使用: mnist数据集的每一张图片都表示一个数字,从0到9, 可以构造一个模型得到给定图片代表每个数字的概率。 为了得到一张给定图片属于某个特定数字类的证据(evidence),需要对图片像素值进行加权求和。 同时因为输入往往会带有一些无关的干扰量,也需要加入一个额外的偏置量(bias)。 其中,Wi代表权重,bi代表数字 i 类的偏置量,j代表给定图片x的像素索引用于像素求和。 Softmax会正则化这些权重值,使它们的总和等于1,以此构造一个有效的概率分布。 xs表示输入的图片数据,ys表示每张图片代表的标签。 Weights和biases是训练过程中要学习的权重和偏置。 由2层卷积池化层和2层全连接层组成: 输入图片大小为28x28x1,经过第一层卷积池化[3]后大小变为14x14x32,经过第二层卷积池化后大小变为7x7x64,提取了图片的高维度特征,相当于把图片长宽变小高度变厚了。然后经过2个全连接层,最后使用softmax激活获得一个大小为10的图片预测数字的概率分布。 卷积即为内积,就是根据多个一定的权重(即卷积核kernel),对一个块的像素进行内积运算,其输出就是提取的特征之一。 卷积包含kernel,stride,padding 3个属性。 上图中输入图片为绿色部分,大小为5×5;kernel为黄色部分,大小为3×3。stride=1, padding=VALID。 卷积后的图片大小为3×3(即(5+1)/2),4=1×1+1×0+1×1+0x0+1×1+1×0+0x1+0x0+1×1。 卷积中 strides 表示每次卷积移动的步长,strides=[1,1,1,1] 中,两边的1不可变,中间红色的1表示该卷积的步长为1,。若步长为2,则 strides=[1,2,2,1]。 padding表示卷积方式,VALID为不填充边缘,卷积后图片变小。SAME为填充边缘,卷积后图像大小不变。 如上图,同样输入图片大小为4×4,卷积核大小3×3,步长为1。VALID方式卷积后图像大小变为2×2,SAME方式卷积后图片大小还是4×4。 池化pooling是指将一个矩形区域的像素变成一个像素,下图即将20×20大小的图片经过10×10的池化,变成2×2大小的图片: 常用的 pooling 方法有 max pooling 和 average pooling。max pooling 是将矩形区域最大的值作为结果,average pooling 是将矩形区域的均值作为结果。 上图为最大池化,5=max{5,2,4,1};若为平均池化,则有(5+2+4+1)/4=3。 ksize=[1,2,2,1]表示池化的矩形大小为2×2,strides和卷积一样,表示步长为2。padding定义也和卷积一样。 搭建卷积池化层一: 搭建卷积池化层二: 搭建全连接层一: 搭建输出层(全连接层二): lr=0.0001, step=2000, Adam: 对比结果: (1)在一定范围内,lr越大,每次迭代权重更新的越快,最终acc越高,loss越小; (2)在一定范围内,step越大,学习次数越多,最终acc越高,loss越小; (3)在学习率同为0.0001的情况下,SGD和Adam最后的准确率没有明显区别,loss收敛有些微区别; (4)学习率0.001,step=2000时,Adam下的loss已经降到了一个比较低的数值,测试集上也获得了99%的好结果; (5)学习率0.001时,SGD会出现loss为nan的现象,可能发生了梯度爆炸,因此把lr调成了0.0005。而Adam在0.001下并不会发生该现象,因此,SGD比Adam每次更新的程度更大。 该数据集共400张图片,共40类,每类图片10张,图片大小为56×46的灰度图。 选择每类图片的前9张作为训练集(共360张),最后一张作为测试集(共40张)。并构建one-hot编码的数据集标签。 下载下来的orl数据集,图片数据全部在orl文件夹下,运行下述代码进行图片位置划分: 更多文件处理相关方法可见[4]。 运行后结果,360张图片在train下作为训练集,40张图片在test下作为测试集: 可用下述代码将数组转换为one-hot标签格式: 效果如下: cnn网络和第二个任务一样,为2层卷积池化+2层全连接。 参数设置:lr=0.001,epoch=30,batch_size=40 训练结果: 测试结果: pic后的数表示图片的真实类别,label后的数表示识别错误的图片误识别成的类别。 训练次数可能多了点,有过拟合现象,测试集准确率不够高,82.5%。 训练和测试图片原本就是灰度图,但是没有/255和转为float,应该没有影响。 (1)损失函数 上次任务中最后的输出层为: 损失函数为: 而这次任务中,损失函数为: 已经包含了softmax,故输出层的softmax应去掉,否则会出现y_conv为nan,loss为nan的问题。 (2)学习速率 学习速率设置为0.01时,loss一直在3.7左右波动,即ln(40),没有学习。 原因可能是学习速率过大,导致一开始梯度就到了错误的位置。改为0.001后结果正确。 数据增强(Data Augmentation)是一种通过让有限的数据产生更多的等价数据来人工扩展训练数据集的技术。它是克服训练数据不足的有效手段,目前在深度学习的各个领域中应用广泛。 使用数据增强的原因: (1)增加训练样本的数量以及多样性(噪声数据),提升模型鲁棒性; (2)深度神经网络需要大量数据来避免过拟合。 训练集70张,测试10张,rgb图,每张图大小不同: 上传的数据集已将图片resize为83×57大小的灰度图: 对训练集进行数据增强处理,这里采用旋转和上采样2种方式。处理完后训练集扩增为210张。 数据增强前(lr=0.01, epoch=15, batch_size=10): 数据增强后(lr=0.001, epoch=22, batch_size=30): 训练结果: 测试结果: 原则上来说,数据增强会使准确率有些微或明显提升。 在数据增强前,虽然训练集图片很少,但已取得不错的结果,在测试集上有0.9的准确率。 数据增强后,加大了训练难度,且训练收敛程度具有随机性,虽然数据集增加了,但依然不是很多,在准确率方面并没有明显的提升。因为测试集仅有10张图片,每类一张,数量太少,测试准确率也不能表达一般性。
Windows下tensorflow-1.14,cpu版的安装

1. python3.7

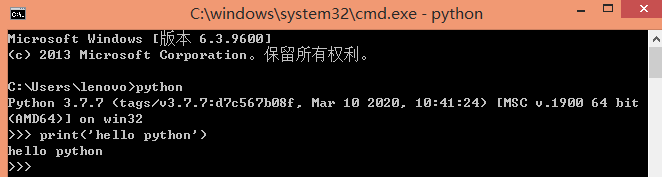
2. 新建虚拟环境(推荐)
python -m pip install --upgrade pip pip install virtualenv
# 创建虚拟环境venv virtualenv --system-site-packages -p python3 ./venv # 激活环境 .venvScriptsactivate # 退出环境 deactivate
pip install --upgrade pip pip list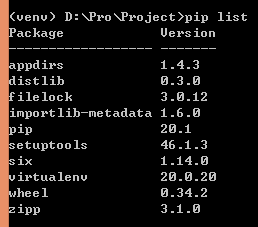
3. 安装tensoeflow-1.14-cpu
pip install tensorflow==1.14
[global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple [install] trusted-host=mirrors.aliyun.com
python import tensorflow as tf print(tf.__version__)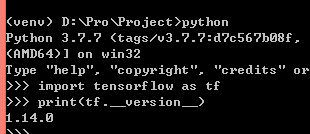
FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecate
pip install numpy==1.16.0一、全连接网络实现手写数字识别[1]
1. MNIST数据集简介

![]() ,其标签为:
,其标签为:
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('MNIST_data', one_hot=True)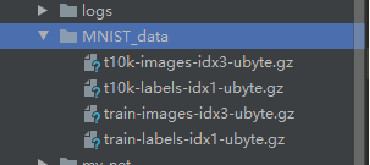

2. 网络结构

3. 模型训练过程

4. 模型评估

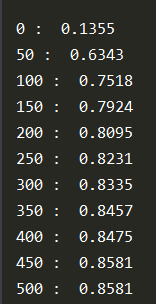
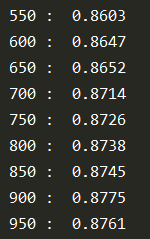
5. 实验结果
二、CNN实现手写数字识别[2]
1. 网络结构

2. 卷积

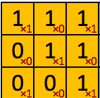 (卷积核)
(卷积核)
# 定义卷积 def conv2d(x, W): return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')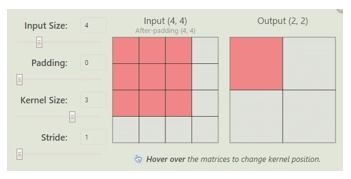
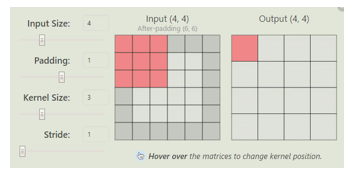
3. 池化

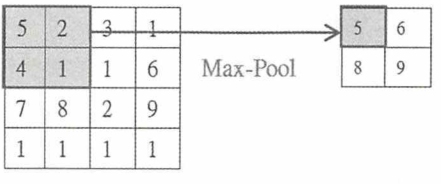
# 定义池化 def max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')4. 网络搭建




5. 实验任务

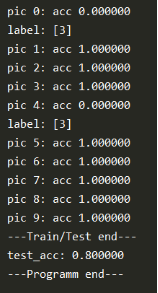
6. 实验结果


三、CNN实现人脸识别(用自己的数据集实现分类任务)
1. orl数据集

2. 数据集预处理与label构建
import os import shutil # 数据集路径,需修改 orl_dir = 'C:/Users/lakuite/Desktop/orl' orl_list = os.listdir(orl_dir) os.mkdir(orl_dir + '/train') os.mkdir(orl_dir + '/test') # 把图片分为train和test for i, img in enumerate(orl_list): img_path = orl_dir + '/' + img if (i+1)%10==0: shutil.copy(img_path, os.path.join(orl_dir, 'test', img)) else: shutil.copy(img_path, os.path.join(orl_dir, 'train', img)) os.remove(img_path)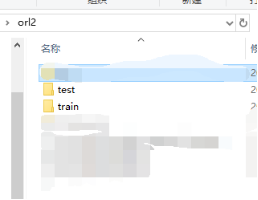
train_label = tf.one_hot(train_label,40)
3. 网络构成


4. 实验任务

5. 实验结果


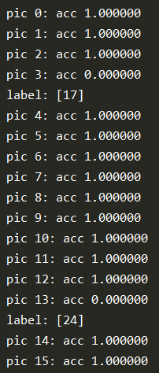
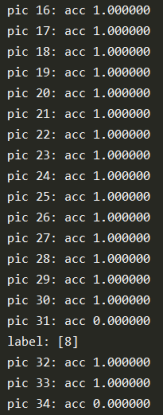
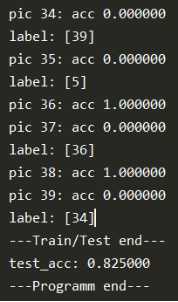
6. 注意事项
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv))
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_,logits=y_conv))四、在人脸识别中使用数据增强
1. 数据增强
2. tf自带相关函数
# 调整大小 resized = tf.image.resize_images(img_data, [300, 300], method=0) # 裁剪填充 croped = tf.image.resize_image_with_crop_or_pad(img_data, 300, 300) # 上下翻转 flipped1 = tf.image.flip_up_down(img_data) # 左右翻转 flipped2 = tf.image.flip_left_right(img_data) # 对角翻转 transposed = tf.image.transpose_image(img_data) # 调整亮度 adjusted = tf.image.adjust_brightness(img_data, 0.5) # 调对比度 adjusted = tf.image.adjust_contrast(img_data, -5) # 调饱和度 adjusted = tf.image.adjust_saturation(img_data, 5) # 图像标准化 adjusted = tf.image.per_image_standardization(img_data) 3. GT数据集


4. 数据集预处理
 (上采样)
(上采样) (旋转)
(旋转)5. 实验任务

6. 实验结果
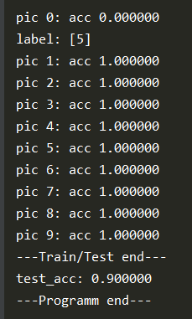

参考文档
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









